用于 AI 和 HPC 应用的现代 GPU 内置了有限数量的高带宽内存 (HBM),限制了它们在 AI 和其他工作负载中的性能。然而,新技术将允许GPU通过与连接到PCIe总线的设备插入更多内存来扩展GPU内存容量,而不是局限于GPU内置的内存 - 它甚至允许使用SSD进行内存容量扩展。Panmnesia 是一家由韩国著名的 KAIST 研究所支持的公司,它开发了一种低延迟的 CXL IP,可用于使用 CXL 内存扩展器扩展 GPU 内存。

用于 AI 训练的更高级数据集的内存需求正在迅速增长,这意味着 AI 公司要么必须购买新的 GPU,要么使用不太复杂的数据集,要么以牺牲性能为代价使用 CPU 内存。尽管 CXL 是一种正式工作在 PCIe 链路之上的协议,从而使用户能够通过 PCIe 总线将更多内存连接到系统,但该技术必须得到 ASIC 及其子系统的认可,因此仅添加 CXL 控制器不足以使该技术正常工作,尤其是在 GPU 上。
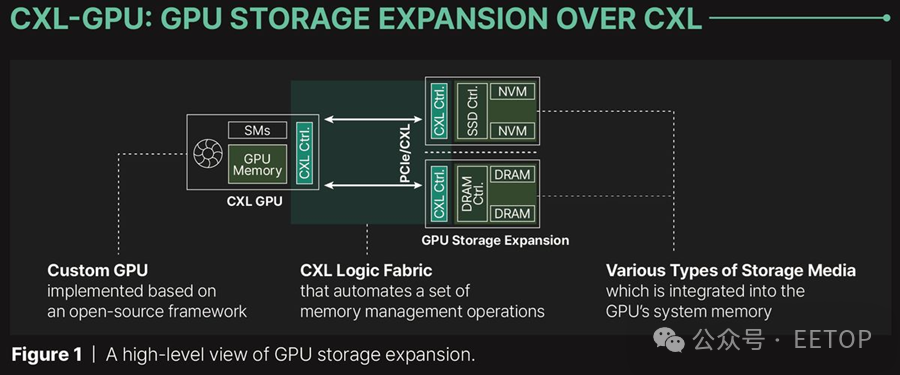
为了解决这个问题,Panmnesia 开发了一个符合 CXL 3.1 标准的根复合体(RC),配备多个根端口(RP),支持通过 PCIe 外部内存,并且具有带有主机管理设备内存(HDM)解码器的主桥,该解码器连接到 GPU 的系统总线。HDM 解码器负责管理系统内存的地址范围,使 GPU 的内存子系统“认为”它在处理系统内存,但实际上该子系统使用的是通过 PCIe 连接的 DRAM 或 NAND。这意味着可以使用 DDR5 或 SSD 来扩展 GPU 内存池。
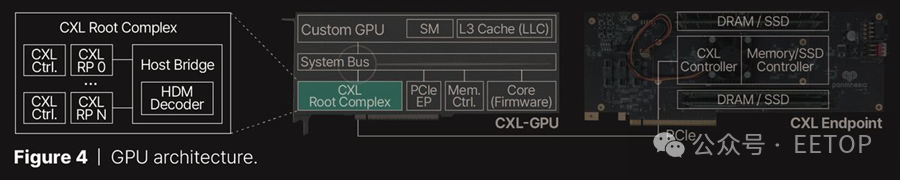
根据 Panmnesia 的说法,这种基于定制 GPU 并标记为 CXL-Opt 的解决方案经过了广泛测试,显示出两位数纳秒的往返延迟(相比之下,三星和 Meta 开发的CXL-Proto,在下图中显示为 250 纳秒),包括标准内存操作和 CXL flit 传输之间协议转换所需的时间。它已经成功集成到硬件 RTL 中的内存扩展器和 GPU/CPU 原型中,证明其与各种计算硬件的兼容性。
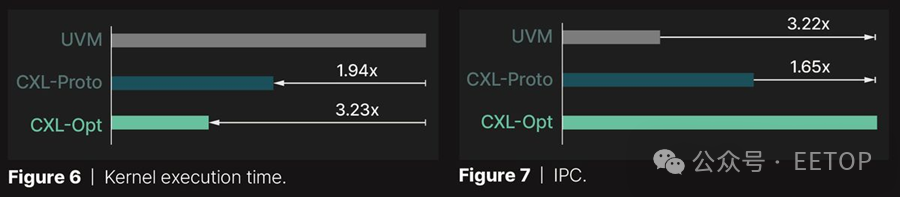
根据 Panmnesia 的测试,UVM(统一虚拟内存)在所有测试的 GPU 内核中表现最差,这是由于在页面错误期间主机运行时干预的开销以及在页面级别传输数据,这往往超过了 GPU 的需求。相比之下,CXL 允许通过加载/存储指令直接访问扩展存储,从而消除了这些问题。
因此,CXL-Proto 的执行时间比 UVM 短 1.94 倍。Panmnesia 的 CXL-Opt 进一步将执行时间减少了 1.66 倍,其优化控制器实现了两位数纳秒的延迟,并将读/写延迟最小化。这一模式在另一张图表中也有所体现,图表显示了 GPU 内核执行期间记录的 IPC 值。数据显示,Panmnesia 的 CXL-Opt 分别比 UVM 和 CXL-Proto 的性能速度快 3.22 倍和 1.65 倍。
总体而言,CXL 支持可以为 AI/HPC GPU 带来很多好处,但性能是一个大问题。此外,AMD 和 Nvidia 等公司是否会为其 GPU 添加 CXL 支持还有待观察。如果将PCIe连接内存用于GPU的方法确实得到了发展,那么只有时间才能证明行业重量级人物是否会使用Panmnesia等公司的IP块,或者只是开发自己的技术。
芯片精品课程推荐

(本课提供在线答疑,购课后课添加微信:ssywtt 拉你入群)
