



倚天 710 是基于 ARM 架构的服务器芯片,所以在介绍倚天 710 之前,先为大家介绍一下 ARM 服务器芯片的发展历程。
2023年液冷服务器词条报告
《数据中心液冷技术合集(2023)》
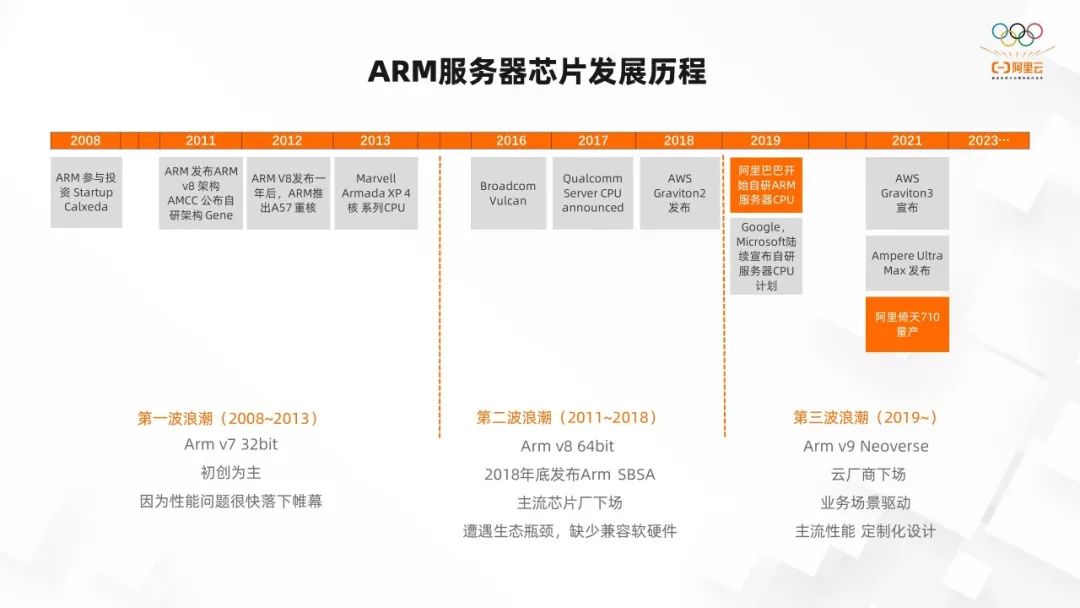
第一波浪潮(2008-2013),ARM 开始考虑做服务器芯片最早可以追溯到 2008 年从投资 startup calxeda 公司开始,当时还是 ARM V7 架构,32 位处理器。后面ARM 发布 v8 架构,在手机移动处理器上所向披靡,但相比于服务器上的多核高性能,ARM 在服务器领域因为性能不足没有什么竞争力,所以很快就落下帷幕,基本上没有开始就结束了。
第二波浪潮(2011-2018)有三个标志性的时间点。第一个是 2016 年 Broadcom,Vulcan 说要开始做服务器芯片,这也是 ARM 联合一些合作厂商做出的一个尝试。第二个是 2018 年底发布了 ARM SBSA,它是服务器的一个标准的加工模板,相当于给 ARM 服务器打了一个很好的基础。
第三个是 2018 年 AWS Graviton2 发布。在此之前 CPU 厂商、芯片厂商做 ARM 的芯片基本都已经宣告失败了,直到 2018 年 AWS Graviton2 发布,开启了 ARM 处理器在服务器领域成功的先河,它给 ARM 芯片在服务器领域成功指明了道路。云厂商基于 ARM 架构会有一定的优势,它可以通过自身 iaas 和 paas 这些云的标准服务,给用户提供的是一套 ARM 的解决方案,而不是一个单纯的芯片。因为如果只是 ARM 芯片,它在生态和软件上会导致用户的使用成本比较高。
第三波浪潮(2019~至今),2019 年阿里巴巴开始自研 ARM 服务器芯片。此外,Google、Microsoft 也都是陆续宣布要开始自研服务器芯片的开发。2021 年,倚天 710 经过两年的研发终于进行了量产,目前已经在阿里巴巴集团、阿里云都实现了规模化使用。
 倚天 710 芯片规格
倚天 710 芯片规格
接下来介绍一下倚天 710 这款芯片的主要规格。双DIE 结构,每个 DIE 360 毫米 2。两个 DIE 600 亿晶体管、业界首次使用 ARM V9 架构和 CPU 核– Perseus。主频:3GHz、8 Channel DDR5 x4800。96 Lane PCIe 5.0。Max Power: 300 W。
倚天 710 的主要特点
 倚天 710:云原生高性价比 CPU
倚天 710:云原生高性价比 CPU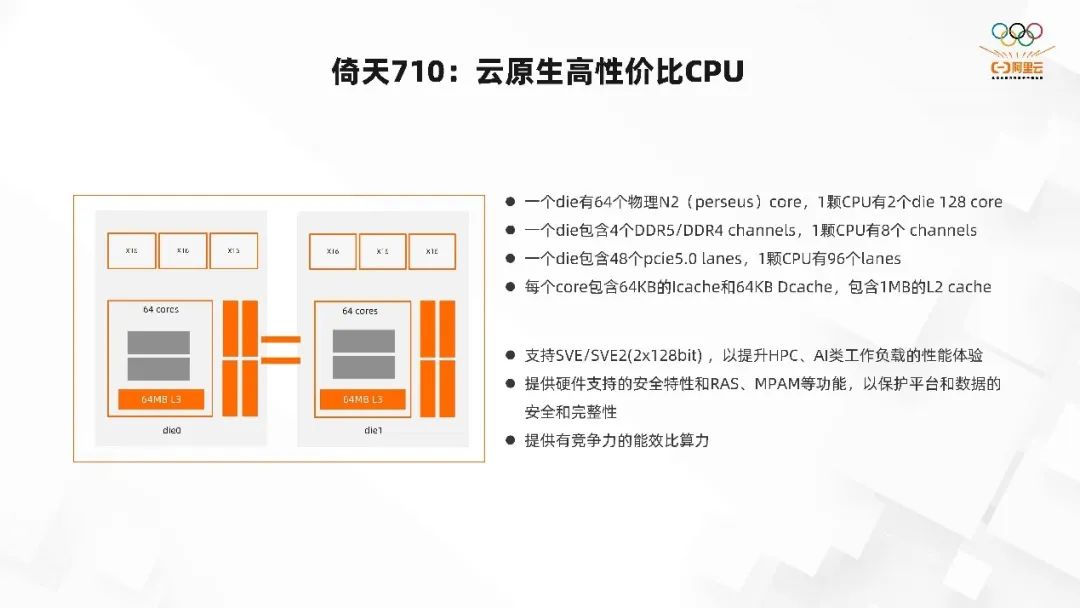
倚天 710 芯片,我们叫它云原生高性价比的 CPU,上图是这个 CPU 的架构,可以看到有两个 die,die0 和 die1,两个 die 是完全一样的。
每一个 die 有 64 个物理 N2(perseus)core,1 颗 CPU 有 2 个 die 128 core。
每一个 die 包含 4个DDR5/DDR4 channels,1 颗 CPU 有 8 个 channels。
每一个 die 包含 48 个 pcie5.0 lanes,1 颗 CPU 有 96 个 lanes。
每一个 core 包含 64KB 的 Icache 和 64KB Dcache,包含 1MB 的 L2 cache。
支持 SVE/SVE2(2x128bit) ,以提升 HPC、AI、视频解码类工作负载的性能体验。
提供硬件支持的安全特性和 RAS、MPAM 等功能,以保护平台和数据的安全和完整性。
提供有竞争力的能效比算力。
倚天 CPU N2 core 架构优势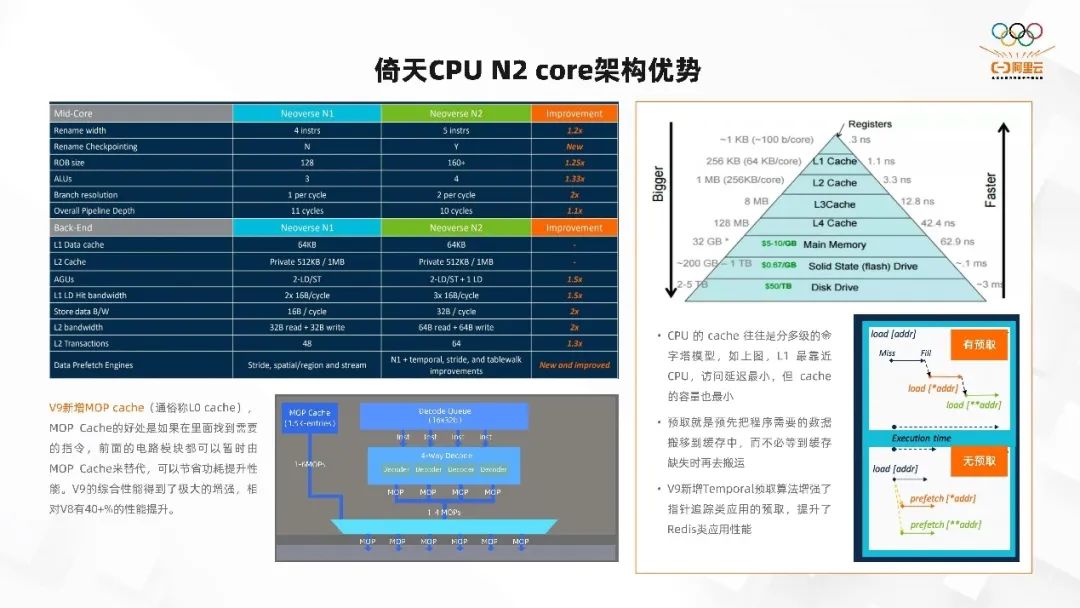
CPU 的 cache 往往是分多级的金字塔模型。如上图所示,L1 最靠近 CPU,它的访问延时最小,但 cache 容量也最小。也就是离 CPU 越近,cache 容量越小,但访问越快;离 CPU 越远,访问越慢,但容量越大。所以我们将离 CPU 近的 L1、L2、L3 都配置了较大的 cache 容量,这也是我们以前 CPU 性能得到保障的一个重要因素。
预取就是预先把程序需要的数据搬移到缓存中,而不必等到缓存缺失时再去搬运。一般 CPU 都有预取,但我们在 ARM V9 架构上新增了一个指针追踪类应用的预取。也就是说你不仅能取一个地址里的数据,还能对它周边的数据进行预取。如果你取的这个地址,它的指针指向了另外一个地址,这个地址你也可以进行预取。
和 N1 core 相比,N2 core 在 Rename width、Rename Checkpointing、ROB size、ALUs 等等方面都得到了一个较大的提升。此外,V9 架构还新增了微指令的cache,V9 的综合性能得到了极大的增强,相对 V8 架构的 N1 core 有 40+% 的性能提升。
倚天 CPU 核特点:SVE2 加速引擎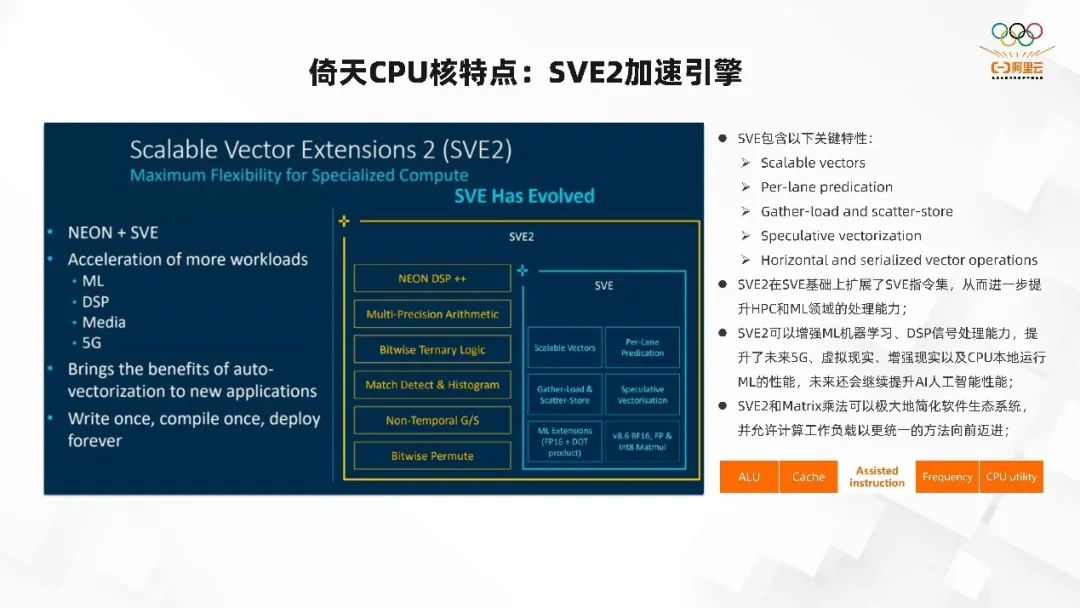
SVE2 加速引擎是 Scalable vectors。比如之前用 ABS256 或者 ABS512 进行编程,当它的位宽发生变化的时候,软件就要重新编写了,因为位宽变化导致指令,接口可能发生了变化。但对 SVE2 来说,它是一个向量化的扩展指令集,一次编程后无论你是在 128 的处理器,还是 256、512,甚至 1024 的处理器,都不需要重新编译,因为它就是一个可扩展的向量指令集,可在运行时根据实际位宽来运行程序。
此外,SVE2 还支持 Per-lane predication、Gather-load and scatter-store 等等,极大的提升了数据访问的带宽。SVE2 可以增强 ML 机器学习、DSP 信号处理能力,提升了未来 5G、虚拟现实、增强现实以及 CPU 本地运行 ML 的性能。还支持了矩阵算法,对 AI 的负载、influence 都有非常好的算力支撑。
倚天架构特点:高密计算更稳定不降频倚天的架构 CPU 有非常高算力性能并且能够稳定高负载运行。和 X86 相比,倚天是是固定主频的,不会进行超频,也不会产生降频的情况。因为超频的时候实际上只是部分 core 超频,另外一部分 core 可能会降频,等到全部 core 都重负载的时候,就需要降频去控制功耗,但在倚天上就不会有这种情况。
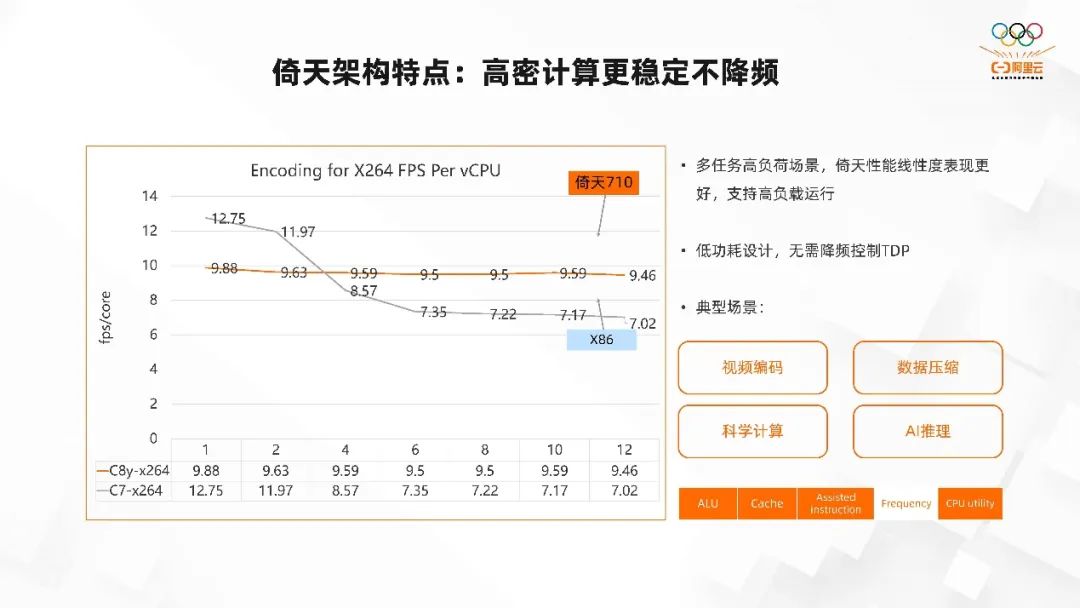
我们以 Encoding for X264 FPS Per vCPU 为例。从上图可以看到一个 core 的时候单 core 的编码能力,倚天 C8y-x264 的这个实例是 9.88,C7-x264 是 12.75,但当这个 core 逐渐增多,达到 12 个的时候,平均下来倚天的单 core 能力由 9.88 减弱到 9.46。
减弱的非常的小,这个和我们的内存访问带宽,cache 共享有一些关系,所以整体的线性度是非常好的。但 X86 的架构,由于降频因素的影响,一个 core 和多个 core 运行的时候,单 core 的平均的算力下降了非常多,由 12.75 降到了 7。
可以看出这也是我们的一个很大的优势,因为基频相对较为稳定,所以在高负载情况下,性能的线性度保持的是比较好的。所以倚天就特别适合应用在视频编码、数据压缩、科学计算、AI 推理等重计算的场景。
倚天架构特点:独享物理 core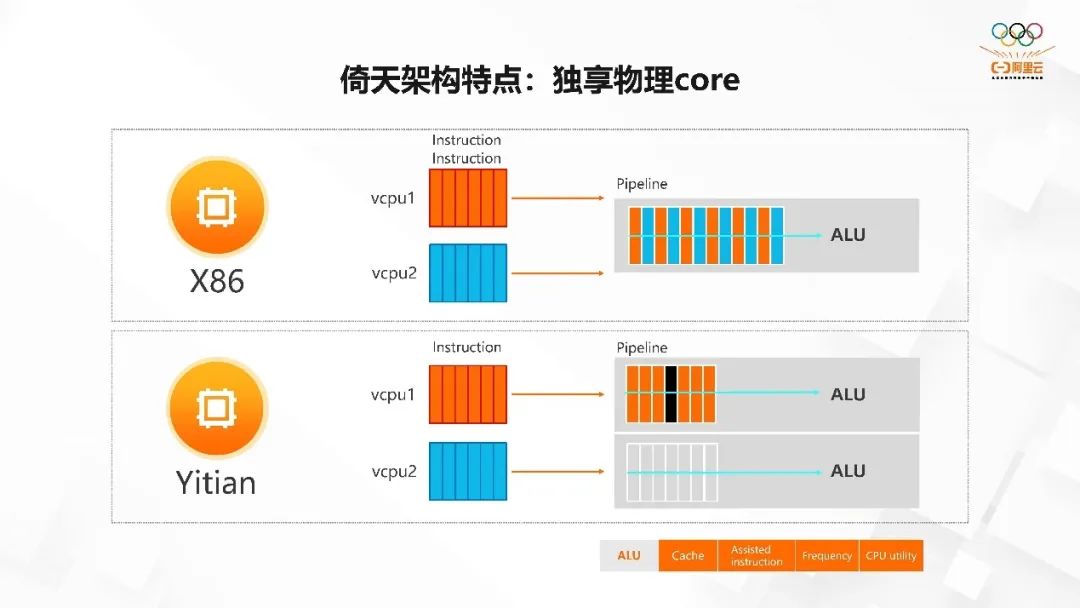
独享物理 core 和非独享物理 core 有什么差别呢?我们还是用 X86 的来举例。
比如用户从云上购买了一个 2c 4G 或者 2c 8G 的实例。这两个 c 实际上是两个 vcpu,vcpu1 和 vcpu2。但这两个 vcpu 实际上共用了一个 ALU 计算单元,也就是说这两个 vcpu 对应到了 X86 上物理 core 的两个逻辑 core,每一个 vcpu 代表一个逻辑 core,但它的物理计算单元是同一个。因此你的算力是一个 core 的算力,只不过通过多线程的方式可以把这个物理 core 的算力发挥的更极致一点。
对于倚天来说,vcpu1 和 vcpu2都是单独的物理 core,所以在 ALU 这个计算单元上也是两个完全独立的 ALU 计算单元。实际上用的就是两个物理 core 的算力,且它们之间也不会有任何干扰。那么物理 core 和逻辑 core 之间的差别,除了 ALU 计算单元的共享之外,像 L1 cache、L2 cache 在 X86 上都是属于共享的。
当在运行高负载的情况下,它对 L1 和 L2 的增强是比较大的。整体的算力和原来一个 vcpu 的算力相比高不了多少,一般在 25%-30% 左右。但对于倚天来说,物理 core、cache 都是分开的,所以如果一个 CPU 的算力是 10,那么两个 CPU 差不多可以达到 20。
倚天重新定义安全水位—效率提升 40%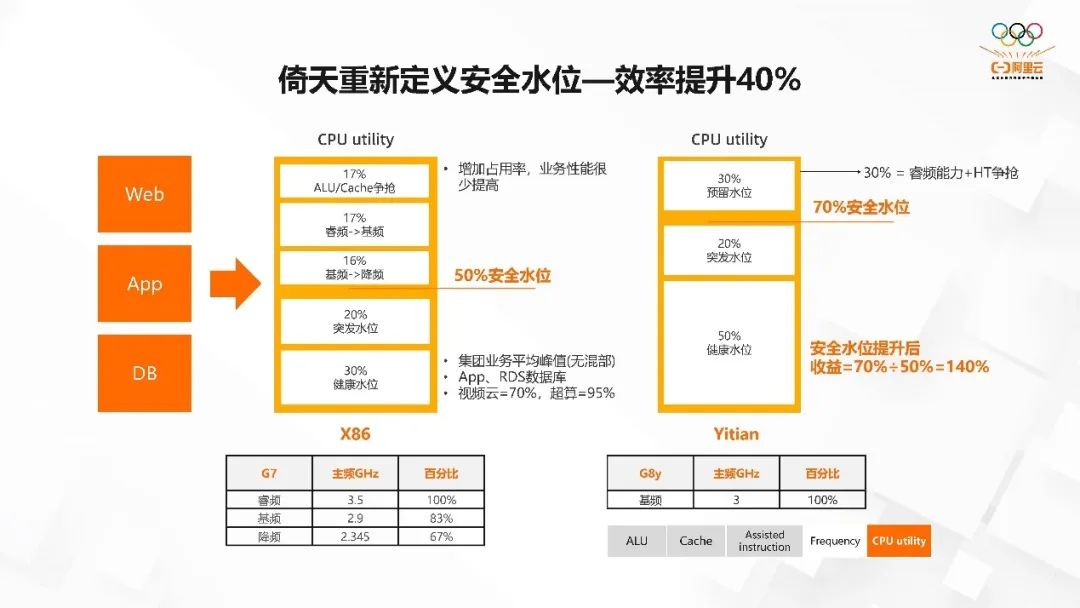
和原来传统意义上 X86 core 架构相比,倚天采用的物理 core 架构,会给用户带来怎样不同的体验呢?
在 X86 上,我们会有一个安全水位的概念,因为大家发现当 CPU 处在 50% 的水位以下的时候,应用算力会随着 CPU 的升高而升高。无论是 QPS、TPS,还是计算的时间,都是和 CPU 完全关联的。当 CPU 超过 50% 的时候,这个应用的执行效率和服务时间就会变得比较差,导致我不能把 CPU 水位提的很高。造成这个的主要原因有两个,一个是降频,另外一个是两个逻辑 core 相互之间的争抢。
而在倚天上,因为我们是物理 core,它们之间是完全独立的单元,所以我们的安全水位就可以比 X86 高,可以达到 70%-80%,而且它的算力的线性度是非常平的。不会因为降频、ALU 争抢,导致 CPU 高了之后应用的服务能力下降的情况。
倚天 710 精简的架构和先进的工艺降低云数据中心 TCO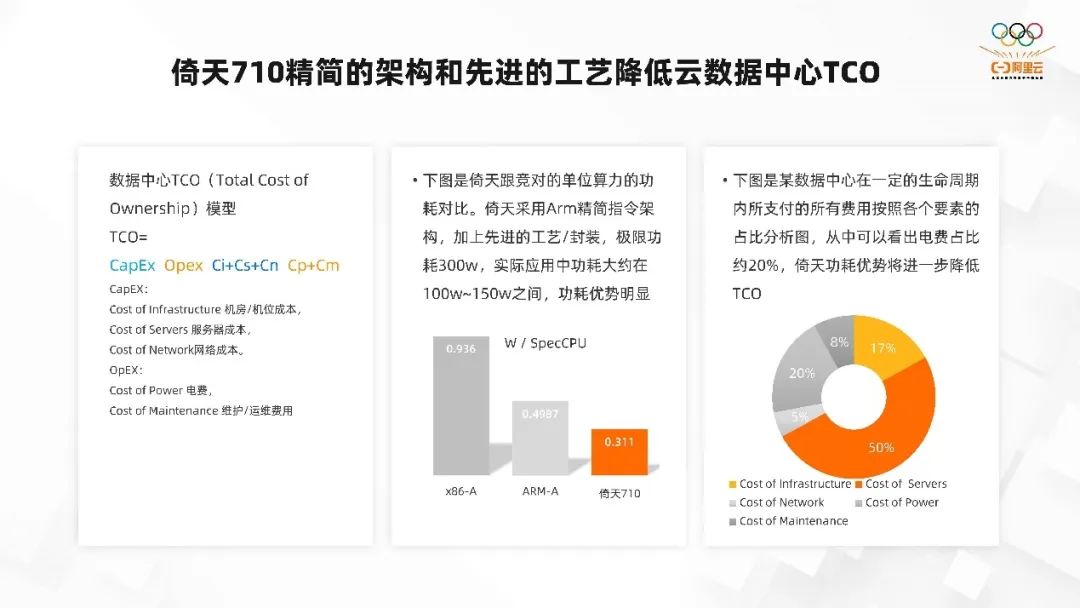
我们都说 ARM 的架构是属于精简指令集,那么倚天710就属于ARM精简的指令架构,再加上非常先进的生产工艺,这两块加起来最终就降低了云数据中心的TCO。云数据中心的TCO的模型主要包含CapEx(机房/机位成本、服务器成本、网络成本)、Opex(电费、维护/运维费用)。
而倚天在最开始就是基于云数据中心对于处理器的要求设计的,所以我们采用了 ARM 架构再加上先进的工艺,这样我们的极限功耗就只有 300w。实际应用过程中的功耗差不多在 100w-150w 之间,只有在完全使用浮点、向量化计算等指令疯狂去跑的情况,才有可能接近 300w。
如果拿倚天和 X86 的 CPU 去比,我们的能效比是非常好的。如上图所示,单位算力下的功耗,英特尔在 X86 的处理器差不多到 0.936w,在 ARM 的一个友商处理器可以到 0.49;在倚天 710 可以到 0.3,能耗比是非常优秀的。
上图是某数据中心在一定的生命周期内所支付的所有费用按照各个要素的占比分析图,可以看出电费占所有支出的 20% 左右。而倚天因为能效比非常高,功耗控制的比较好,所以它的电费会比较少,这些构成了倚天 TCO 非常大的性价比优势。
所以我们 CPU 在云上售卖的时候,无论是 X86 还是其他 ARM 厂商,在同等算力的情况下,甚至整体性能优于 x86 的情况下,我们的价格定位仍然是比较低的,真正实现云上普惠算力。
云原生 CPU: 基于 CIPU 的倚天 ECS 硬件架构为什么说倚天是一个云原生的 CPU?因为现在很多芯片厂商在设计 CPU 的时候都会设计一个两路的架构,也就是一个服务器的板子上放两个 CPU。因为这样核的密度会更高,那么在云上售卖的话,就可以卖更多的实例出去。
但在倚天设计的时候,我们用的是阿里云 CIPU+倚天的双单路的设计模式,即 CIPU 接了两颗倚天的 CPU。这两个 CPU 是完全隔离的,它们之间没有进行互联去保持 cache 一致性。
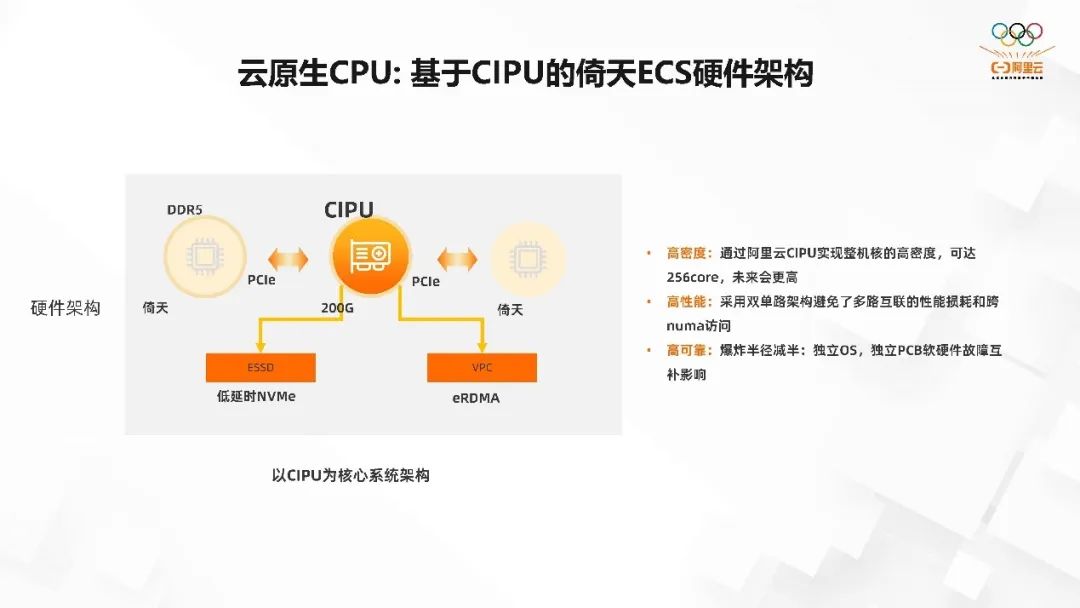
那么这样设计有什么好处呢?
高密度:通过阿里云 CIPU 实现整机核的高密度,可达 256 个物理 core,未来会更高。
高能效:采用双单路架构避免了多路互联的性能损耗和跨 numa 访问。
高可靠:爆炸半径减半:独立 OS,独立 PCB 软硬件故障互补影响。
倚天 710 应用落地介绍
倚天 CPU 全栈技术优化我们知道倚天是基于 ARM 架构的,ARM 架构相较于 X86 比较晚,所以它在软件生态这一部分存在一些问题。基于此,我们以客户体验为中心,打通基于阿里云CIPU(云基础设施专用处理器)+ 倚天 CPU 的全栈生态链,针对用户的应用进行端到端优化。
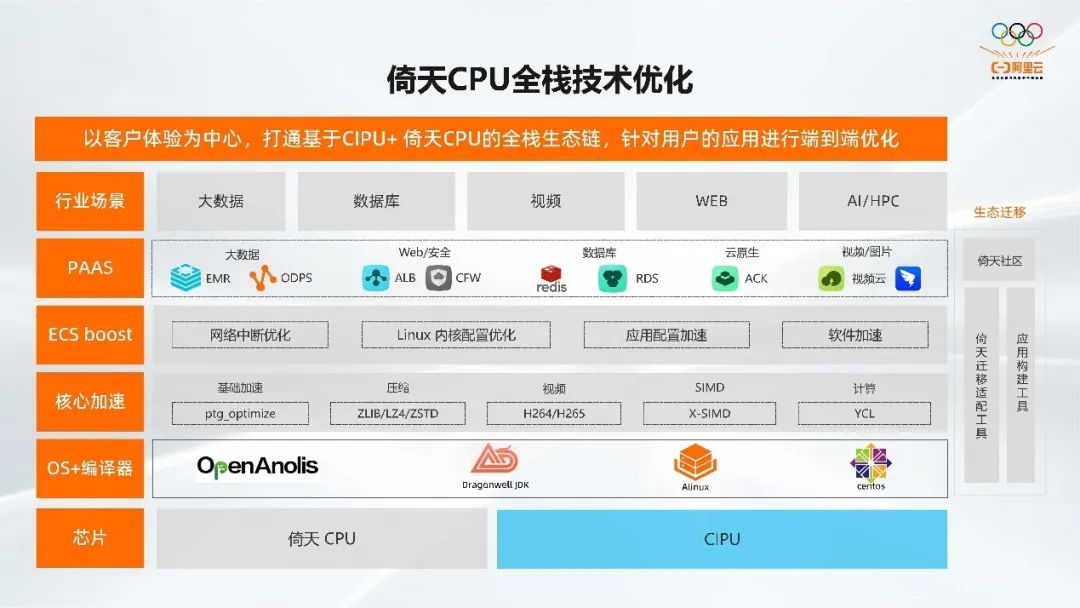
如果我只有一个高性能的 CPU 和 CIPU 的话,对于用户来说不一定能感受到完全的性价比优势。因为 X86 毕竟是已经做了这么多年了,很多软件都对它进行了非常极致的优化,所以它更能发挥硬件的能力。而倚天的 CPU ARM 架构在软件生态上相对就弱一点,因此我们会在芯片的基础上,提供更多的软件能力去发挥倚天 CPU 的能力。
在 OS 侧,我们适配了 OpenAnolis、Dragonwell JDK、Alinux、centos。另外,在此之上我们做了一些核心的软件加速库。
基础加速,比如 ptg_optimize,主要针对一些比较通用的计算接口,比如内存拷贝、CRC、加密指令、string等操作,都相比原来有 30%-50% 的提升。
压缩,我们针对 ZLIB、LZ4、ZSTD 都进行了核心的加速。这样和开源相比都会有 50% 以上的性能优势。
视频编解码,我们也做了倚天基于开源的一些加速,相比开源有 15% 到 30% 的优势。
SIMD,我们还做了一个 X-SIMD,它相当于 X86 到 ARM 的一个桥梁。我们之前在英特尔上可能用的是 AVX512 的编程,如果在用 ARM 处理器的时候,还需要对 ARM 做向量化的编程,这样的话我们的研发成本就很高了。所以我们做了 X-SIMD 这个软件库,主要和 X86 的接口保持兼容,不用改任何代码,就可以实现在倚天上的 SVE 的向量化指令使用。
计算,我们提供了一个 YCL 的 AI 数学计算库、提供了在高性能计算 HPC 以及 AI 场景的高性能应用。
无论是在操作系统或者编译器上做的一些针对倚天的加速,还是在 CPU 硬件算法以及软件加速,我们最终都把它做成了一键使能,开箱即用,通过 ECS boost 的方式为云上的用户提供服务。
因为如果每个特性、每个库都让用户自己去集成,这个研发成本就会比较高。所以在你购买 ECS 产品的时候,只要勾选相应的加速特性,就会把我们在这之上做的一些系统加速和硬件特性的加速全包含在里面,让你一站式的体验到我们对倚天 CPU 所做的加速能力。
再往上是我们的 PaaS 产品,目前阿里云很多 PaaS 产品都已经适配了倚天,比如 EMR、ODPS、ALB、CFW、Redis、RDS、ACK 等等。也就是说你可以基于之前在阿里云上使用的 PaaS 产品,都可以用到 ECS 倚天实例。我们主要聚焦的也是数据中心里比较大的一些场景,包括大数据、数据库、视频,WEB、AI/HPC。
此外,我们还做了生态迁移,我们在阿里云的官网上构建了一个倚天的开发者社区。我们会把阿里巴巴内部各个业务做的应用从 X86 迁移到倚天 ECS,以及把我们使用倚天 ECS 的经验分享到倚天技术社区。
为了让大家更好的从 X86 的生态迁移到我们倚天的生态,我们也开发了一些相应的工具,倚天迁移适配工具。在从 X86 迁移到倚天 ECS 的时候,你可以用这个工具进行扫描,扫描出哪些可以直接迁移到倚天 ECS 上,哪些要经过一些小的改动,还会给你一些建议等等。
此外,我们还会提供一些应用构建工具,比如云原生的镜像构建、镜像部署、k8s 调度等实践。很好的屏蔽了倚天 ECS 和 X86 的一些差异,让用户更好的从 X86 迁移到倚天 ECS,无需太多的开发和改变,让迁移更平滑。
倚天 CPU 业务应用情况基于前面提到的特性以及我们在软件方面的努力,倚天 CPU 无论是在阿里云的 PaaS 产品,还是阿里巴巴集团的业务(电商、蚂蚁、ODS、存储)都已经大规模的进行了落地,一些外部的客户也在倚天 ECS 上落地了很多。
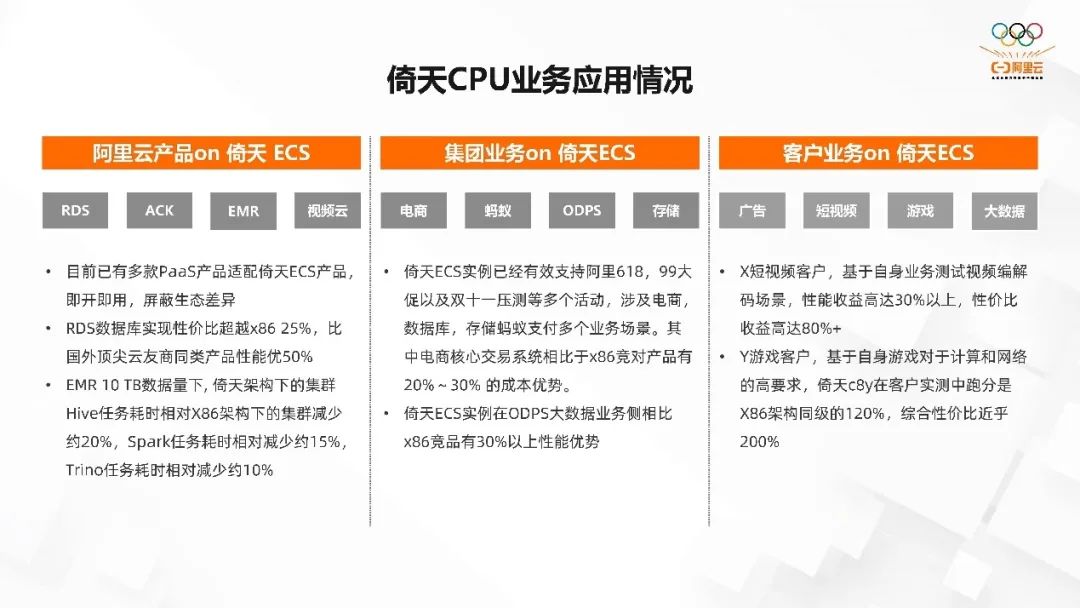
在阿里云产品方面,无论是 PaaS 产品还是集团电商,在使用基于倚天 710 的 ECS 实例之后,相较于 X86 架构下的集群都得到了比较好的性价比。比如 EMR 10 TB 数据量下, 倚天架构下的集群 Hive 任务耗时相对 X86 架构下的集群减少约 20%,Spark 任务耗时相对减少约 15%,Trino 任务耗时相对减少约 10%。
大数据是我们非常重要的一个领域,因为它是一个重负载的计算场景,对于倚天这种高性能的 CPU 来说是非常适合的场景。在集团业务方面,倚天 ECS 实例已经有效支持阿里 618、99 大促以及双十一压测等多个活动,涉及电商、数据库、存储蚂蚁支付多个业务场景。其中电商核心交易系统相比于 X86 竞对产品有 20%-30% 的成本优势。
倚天 ECS 实例在 ODPS 大数据业务侧相比 X86 竞品有 30% 以上性能优势。ODS 也是我们非常重要的一个大数据的 PaaS 场景。
在阿里云外部客户方面,X 短视频客户,基于自身业务测试视频编解码场景,性能收益高达 30% 以上,性价比收益高达 80%+。Y 游戏客户,基于自身游戏对于计算和网络的高要求,倚天 c8y 在客户实测中跑分是 X86 架构同级的 120%,综合性价比近乎 200%。目前基于倚天 710 的 ECS 实例已经成为了外部客户降本增效的利器。
倚天的持续优化和演进最后来介绍一下倚天持续优化和演进的趋势。
我们一直在追求更极致的芯片优化和整机性能。比如我们提高了 CPU 核心主频以及 DDR5 的内存频率,最开始 128 core 的核心主频是 2.75 GHz,我们通过硬件上的一些优化和服务器上的一些联合创新,把主频已经提到了目前的 3GHz,DDR5 也达到了 4800 的频率。

在软件优化上,我们会去做内核里的 Kernel、JVM 都做了非常多的优化,而且也会持续做下去。
2023电信AI产业发展白皮书
大模型安全解决方案白皮书
《华为AI盘古大模型合集》
1、华为AI盘古大模型研究框架(2023)
2、华为昇腾服务器研究框架(2023)
3、华为盘古预训练大模型
2023年机架式服务器行业词条报告
《AI算力技术研究合集》
1、AI算力研究框架(2023)
2、AI兴起,智能算力浪潮来袭
3、深度拆解AI算力模型
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


