


分享嘉宾|唐建法 钛铂数据 创始人&CEO
内容已做精简,如需获取专家完整版视频实录和课件,请扫码领取。

为企业使用数据提供方便易用的工具,随时简单用到新鲜数据是团队的愿景,我们希望把企业的数据用水管连接起来,变成基础架构,想用的时候数据就能过来。我们的使命也是解决企业数据孤岛问题。
从统计来看,大型企业平均业务系统有 315 套,中型企业平均 52 套。最近十几年,有很多企业在做数字化举措,涉及到洞察,对业务、客户、生产过程的理解,提高效率。近几年, AI 赛道火热,大家通过新技术为企业赋能,提高竞争力,但意识到离不开企业核心的数据资产,而这些数据目前都存在。二三十年前设计的架构,单体式架构封装在孤岛式的系统之内,导致获取数据困难,这对新的业务创新、洞察带来非常大的挑战。
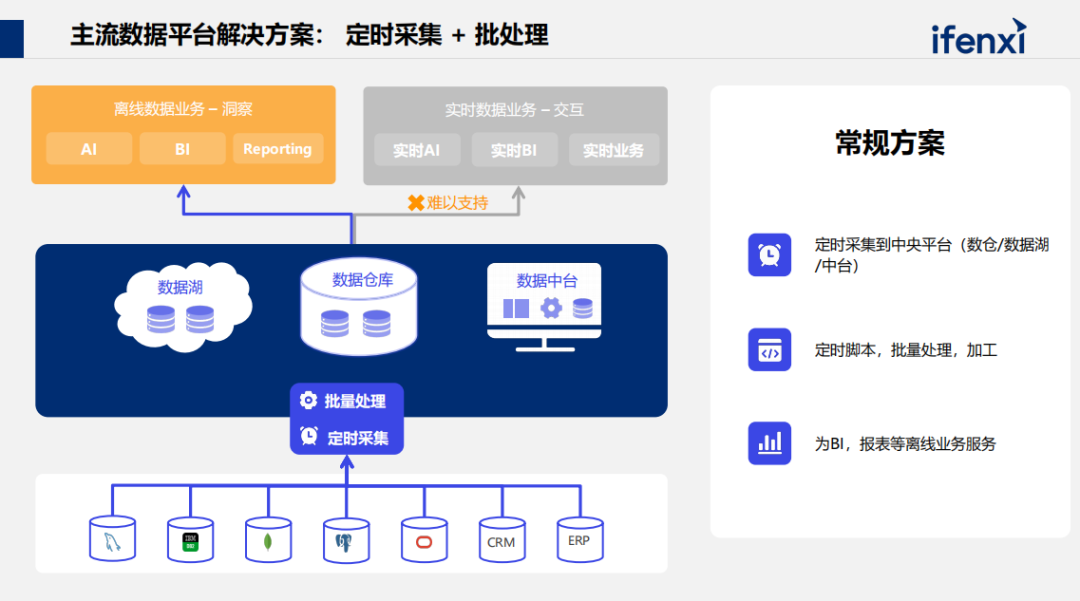

其中的核心点是把数据从各个源系统中采集过来,进行加工处理,形成模型。核心技术是定时采集和批量处理。数据中台为什么不能做到很好的业务支撑。一是组织架构的问题,二是技术工具的不匹配度。数据中台号称支撑业务,但它采用了市面上常规的批量业务或定时采集能力,导致数据并不新鲜,无法为实时要求较高的业务场景,比如实时BI、实时Dashboard,或者交互式、跟客户、状态、订单相关的场景就不能起到支持作用。
什么类型的业务是实时业务场景,跟传统的业务系统有什么区别。我们说的业务,涉及到已有系统之外,利用企业的数据做新的事情,比如说实时驾驶舱等都在企业内常见的,便于让管理层第一时间了解企业情况。实时数据的获取和使用对此非常重要。
另一个典型场景是金融反欺诈,常见的信用卡,比如获取贷款,或刷信用卡。现在在金融行业,当一笔卡刷下去,会马上调取该卡号发生了什么交易,时间、地理区域,当发现不正常现象,马上停止交易,这就是实时数据引导的支持反欺诈行为的业务场景。
在产线上当生产设备出现问题时,不及时发现,它会导致今日生产都是瑕疵品。如果有实时的预警,可以马上停止,降低损失。
在服务行业、金融、保险等行业,以前的客户画像是静态的,现在要求知道客户现在在做什么?下过什么类型的订单?对什么产品感兴趣?这样能增强客户的消费体验,同时提高对客户的实日数据进行采集要求。
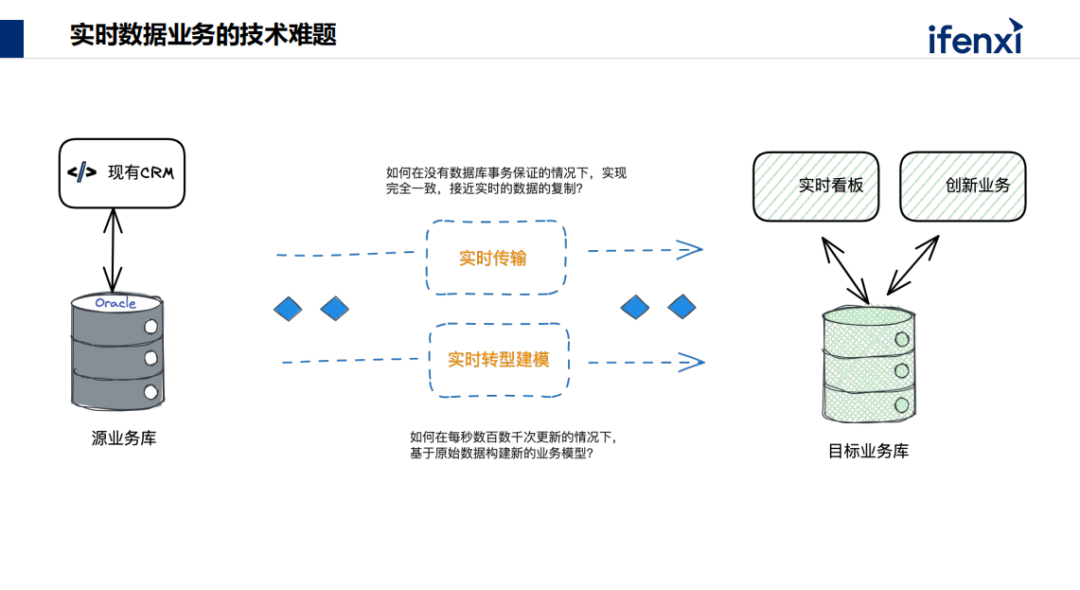
以上场景都需要数据的产生和使用,一个是源头,另一个是在新的场景使用,不是在源系统上做,要在新的地方做新业务,问题难点在于怎样从一套已经多年运行的系统,在不轻易改变的基础上要做创新,涉及到数据要从已有的业务系统中实时传输到新库里,客户交互业务,要确保数据是是准确的、一致的。但是因为异构分库是两套系统,在没有数据库事务的保证基础上达到数据准确是非常困难的事。新业务使用的模型要通过预计算的方式才能真正有效。这涉及到对数据在变化、采集时,实时地把它建成想要的业务模型。这两项技术在近几年都在尝试解决,但还没有前沿的解决方案,因为技术上确实比较困难。
对于实时业务场景的常见方案能否解决这些问题,几种主流实时数据流通企业级解决方案。
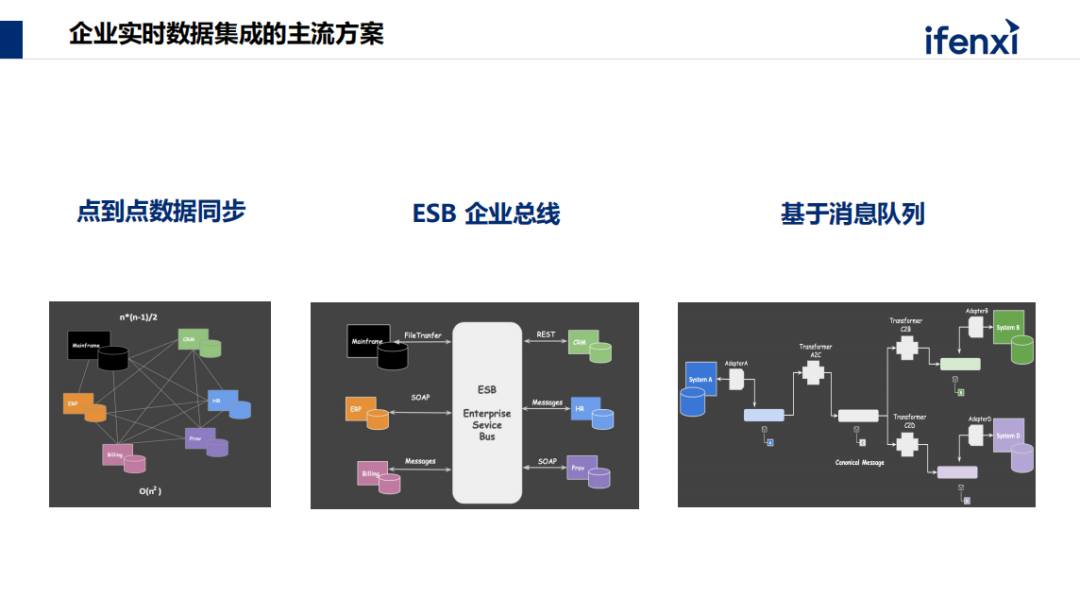
1、数据点到点的同步,告诉取数系统,无论是 ERP、CRM 也好,从源头打通端口,通过工具抓取数据。
2、通过企业总线链接所有系统。
3、基于 MQ 消息队列架构。
列举几种架构的特点。第一种点到点是最传统的,特点在于最简单直接,容易理解、实施。不足点在于重复劳动,往往一个业务需要 10 - 20 条链路,且链路都是临时拉的,没人管理它就会断裂,出了问题后也无法追溯源头,会引起非常多的管理问题,且存在相互依赖,会变得混乱,我们称为像意大利面情况,点到点集成非常常见的,特别是对大型企业来说,这是它的一个比较不好的点。
ESB 企业总线是中央化架构,跟点对点区别在于可复用,企业所有数据集中到Hub 上,所有人对接的链路条数跟系统数量是线性关系。线路数量会比较干净、清晰、合理。而且可在基础上按照统一标准的 API 接口、规范接口后不断的将新业务持续接入。听上去很理想,但这套解决方案在最近十来年逐渐地被弃用了。有几大问题,一是 SOAP/ XML 的接口方式,开发、对接成本非常大,因为它非常繁琐,机制非常细致,导致会直接影响性能。在互联网时代还没爆发时还在使用。但在数据量爆发后,完全没法跟上时代,这些原因导致了它慢慢退场。

最近几年比较流行的是 Message Queue 方式, Kafka 是主流代表,特点是新一代的分布式架构,解决了性能问题。另一个非常重要的原因是开源,因为引入成本较低,在开始尝试时,不需要额外成本。弊端在于对代码对接要求比较高,架构维护成本高。
在了解到企业客户的痛点后,第一个出发点是简单易用,核心关键要让数据像在水管里流动一样,在这个基础之上,关键考虑希望用户容易使用,开源实时数据平台特点是具有多架构,支持低代码开发。技术架构所有的能力,都是围绕着这个链路开展。
平台多架构只是简单的场景,先做点对点的实时的数据流通。当进一步意识到更多的需求时。我们提供一个中央化的架构,叫实时数据服务。通过该方式把数据中央化,再用 API 的方式给到下游业务,另外一种场景就是用来做数仓的准备、做分析、做报表。分析场景里的实时分析是我们的特别关注,出发点是解决关键型的业务场景。
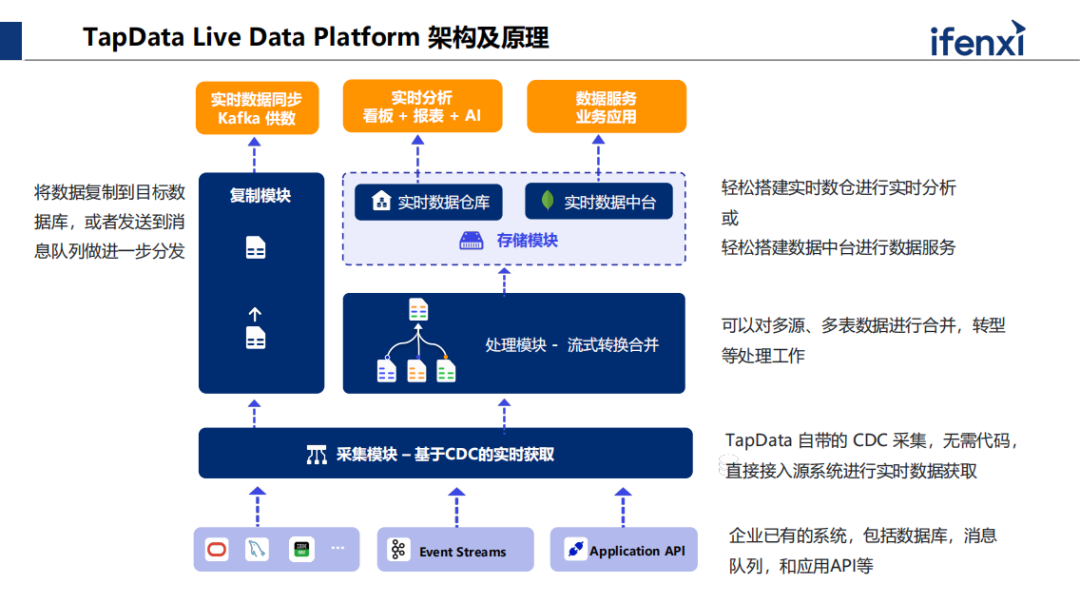
上图为TapDate架构。首先最下层是企业已有的业务系统,左边是这些数据库,其中包括数据流。也有一些数据来自于业务系统,没法直接从数据层面对接,但会提供API,这些都是企业已有的数据源的存在。
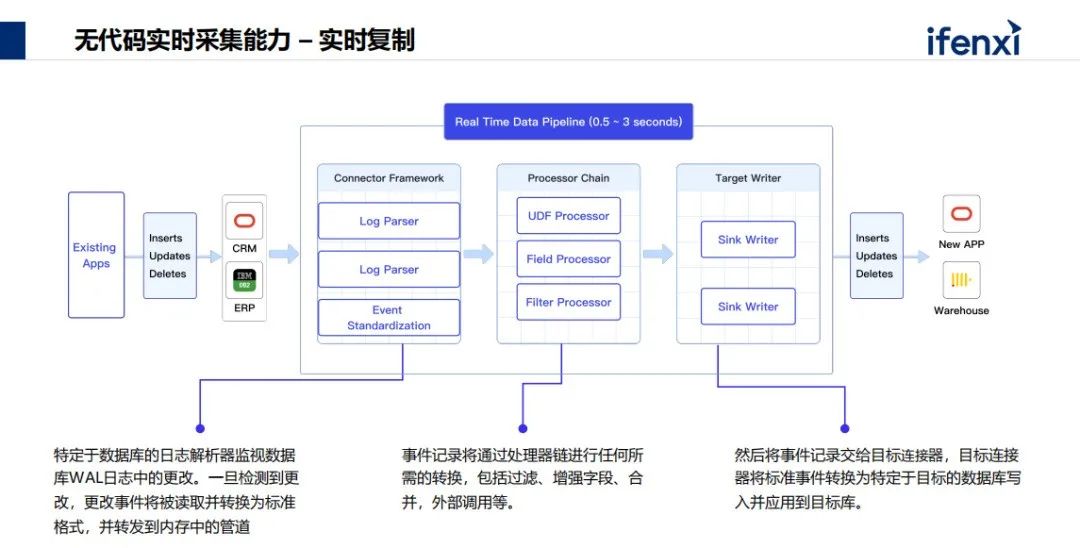
第一个出发点是提供流式采集模块,基于 CDC 机制,核心是流包表或者表包流本,把数据库的表转化成流,记录了源端不断发生的事件。如增加、修改、删除、更新状态,我们把它转化成这个流的事件,转化成流标准化,可以通过平台里面的复制模块,直接推送到下游的各样实时数据库。
最难是采集,对于更成熟度高的客户,希望更优化的方式,比如对数据进行加工处理合并,我们提供的处理模块可做流式转化合并。主要能为两大类的业务场景提供支撑,分析类与业务类。分析类,TapDate 数据平台可以配合数据仓库存储关系型用来做分析型场景。另外一大类是业务场景,业务场景指网页应用、手机应用、交互式应用、客户应用,需要核心数据,这是中台概念,我们把经过处理后的数据落地到存储里,直接实现轻量化的实时数据中台,马上为提供实时的数据服务。
第一步采集了数据以后核心点可以支撑三大类的业务场景。
1、点到下游的数据库Kafka。
2、分析类的场景,例如实时湖仓、数据仓库或者数据湖。
3、提供企业级的核心主数据服务,这也是最为核心。
平台内有三大核心技术点,1、无代码实时采集,2、实时的物化视图能力,3、实时数据一致性保障。
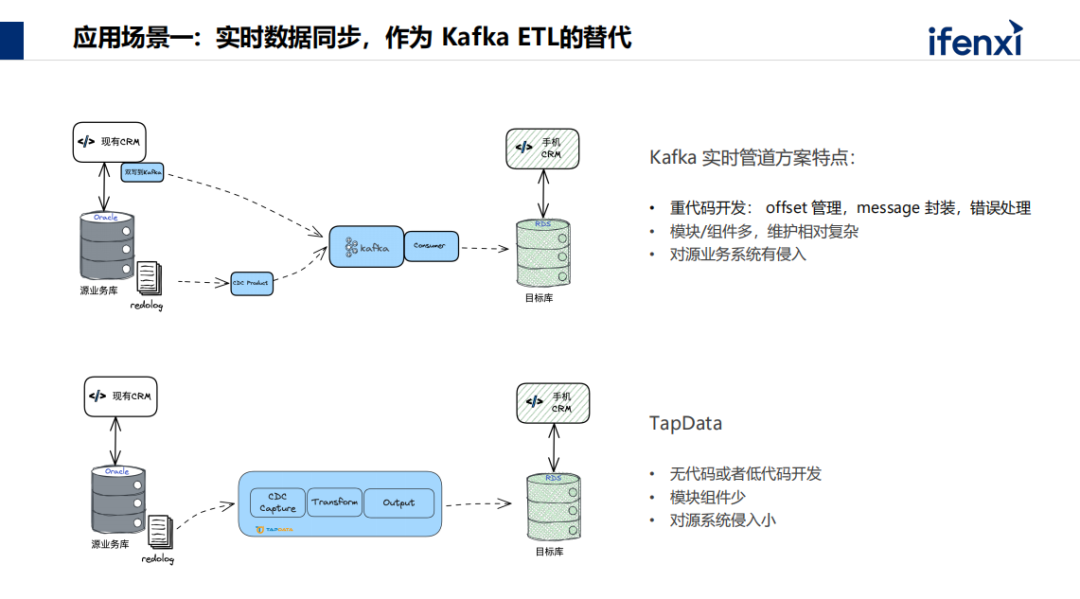
主流的数据同步,现在多用 Kafka ETL ,用来做数据管道。用 Kafka 会涉及到几个模块,改写源端的业务应用,写 consumer 代码,采用 CDC 工具,要两三个方案合在一起才能解决问题,是个非常重开发的业务方案,对源系统也会侵入。TapData 方案是透明的,从已有的库里面把增量日志采集,直接放到想要的地方,完成点对点。
某头部的内容平台。最开始使用 Kafka ETL, 虽然目前还保留使用,但发现开发成本、维护成本都很高。当意识到很多业务用这种方案时,打算做小工具,帮助企业内部数据的流转,从已有业务系统搬迁到新业务系统,使用客户数据、会员数据、教客户行动数据等等。考虑找实时数据的解决方案。经评估, TapData 使用后一年之内上线了大概接近 200 条数据链路,基本上节省了 70%- 75% 的成本增加,交给业务、开发团队,想要数据时,自助找源头,在获得权限的情况下把数据给接过来。
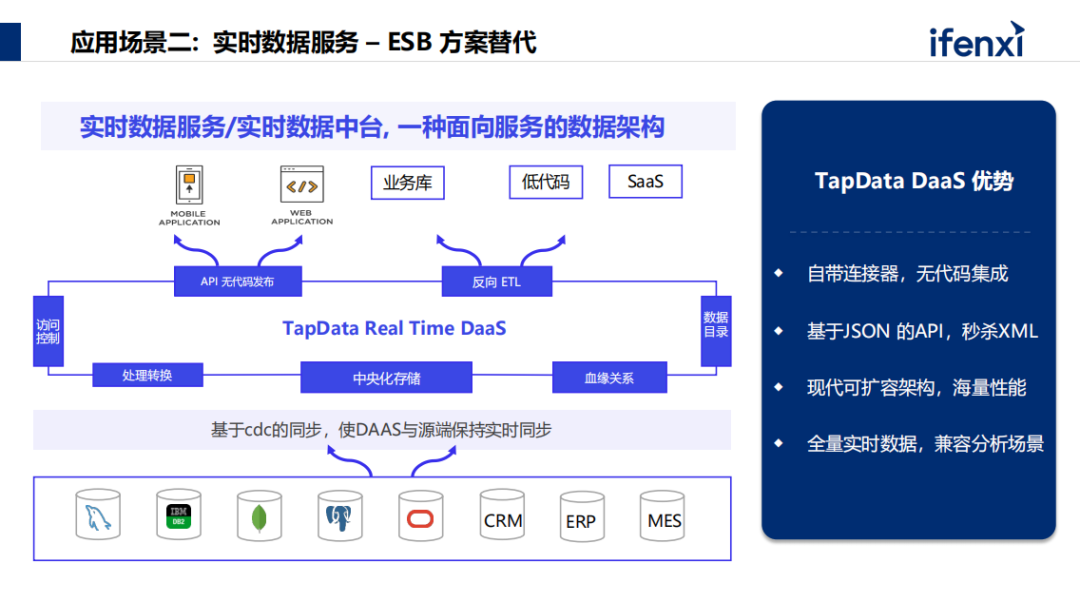
第二种场景是做中央化架构,作为 ESB 方案的替代,把数据从源头利用 CDC 机制中央化到分布式存储里。分布式数据库存储数据能达到高性能扩展。可为多个业务同时支撑,且数据足够新鲜,完全可以支撑交互式的手机应用或者网页应用。使用便捷,成本非常低。
另外用到表包流和流表概念,不仅能取到流的数据,也可以在平台里取到表的数据, Kafka 大部分只能取到流的数据。TapData解决方案提供两种可能性,根据业务场景的不同,按需选择。
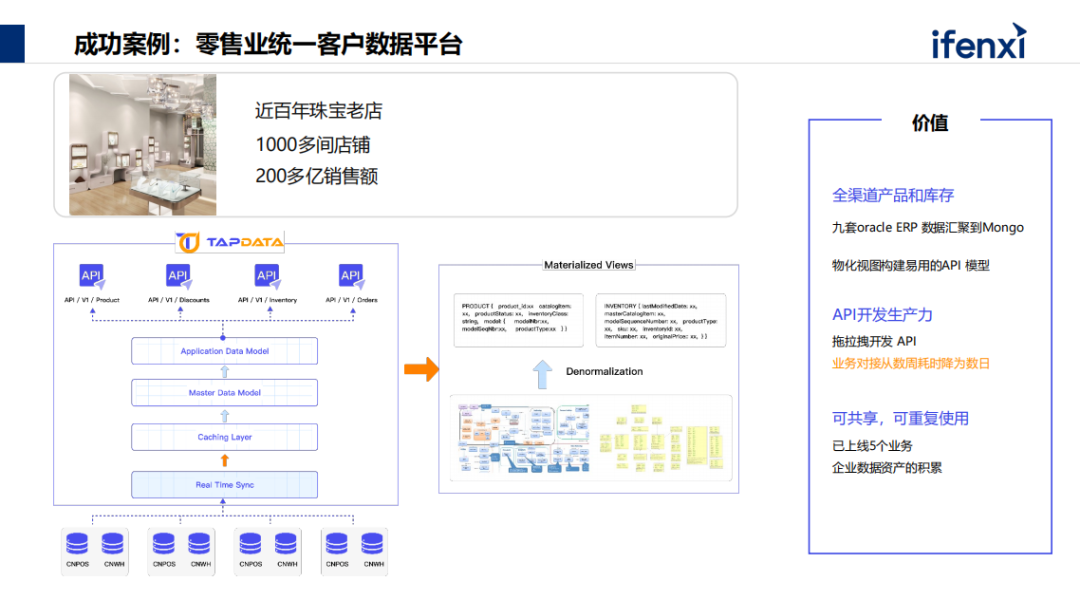
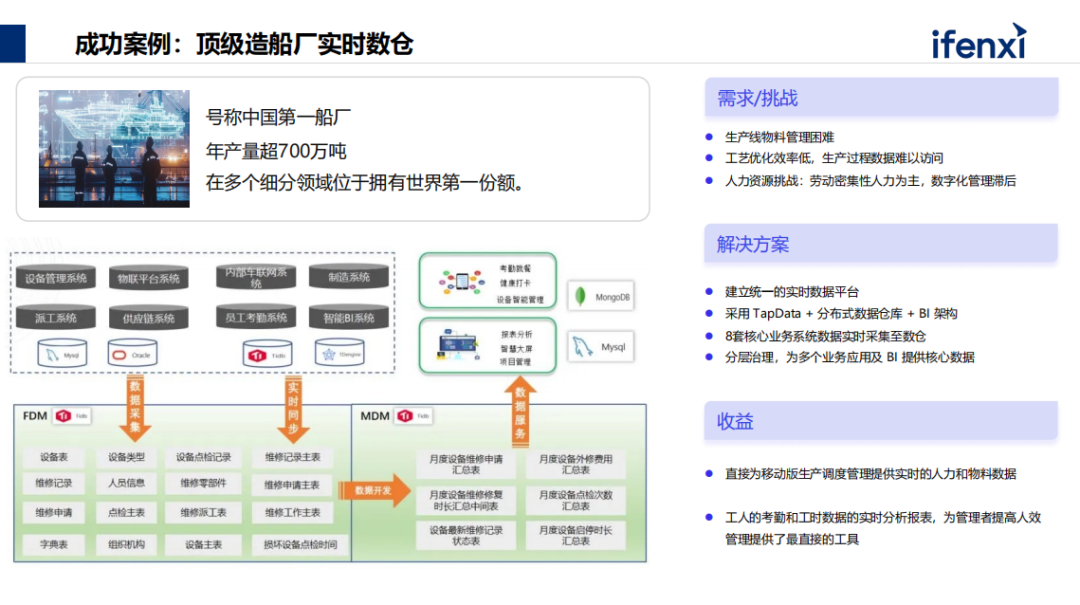
最后一个案例是搭建实时数仓。某造船厂是人力密集型的企业,有几万员工,造船工序繁琐,管理难度非常大,内部很多系统投入运行,但相对孤立,没法串通做整体效率的提升。
所以他们试图做数据工作,但批量方式没法满足业务对实施性的要求,最后决定建立统一的数据平台。把业务系统集中到数仓后,有两大类的场景,一类是实时BI,此场景非常关注实质性,因为要看效率分配情况,及时调配产线上的工人,所以只有实时数据有意义。拟数式分析更偏向经营性业务,所以对数据的时效性要求非常高的。
TapData架构能为多种实时相关的企业的各种业务场景提供支持。架构跟当前平台方案本质上没什么区别,最大的核心区分点是实时基础平台,可以为做升级的企业服务。升级后,除了已有的离线业务,可进一步地为企业的关键型业务提供实时数据的业务支撑。
以上就是本次分享,如需获取专家完整版视频实录和课件可扫码领取。
⩓

2019年回国创立深圳钛铂数据有限公司,曾任MongoDB大中华区技术总监(2014年)、联邦快递亚太区研发中心首席架构师(2010年)及奥普斯维尔创始工程师(2002年)。实时流数据处理技术专家,国家信息标准委员会流数据标准工作组成员,非关系性数据库理论及实践专家,著名MongoDB进阶课程讲师。主导开发JS网络驱动SDK,提高开发效率五倍,并设计开发国际领先的CDC实时数据平台,实现毫秒级低延迟。
注:点击左下角“阅读原文”,领取专家完整版实录和分享课件。



