现在还有什么领域没有AI的概念?自从ChatGPT大火,大模型之战就拉开了序幕,这次的战火,也延续到了树莓派领域。前阵子,树莓派正式上市,虽然没有引发很多人关注,但也说明树莓派一直很受开发者欢迎。过去,很多人都把树莓派这个SBC当作开发的“小玩具”,也有人用工业树莓派,作为生产力。而现在,GPT来了,它也彻底改变树莓派了。 把GPT放在树莓派上
把GPT放在树莓派上 
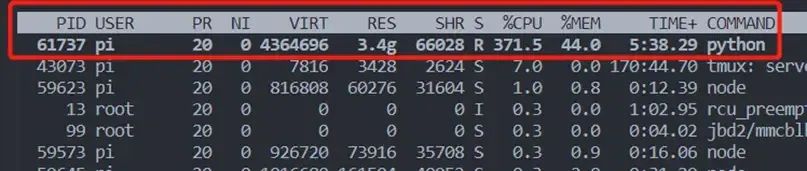
2023年3月,就有人开始尝试把GPT放在树莓派上。一位名叫Georgi Gerganov的软件开发人员开发出了一款名为“llama.cpp”的工具,它不但可以在Mac笔记本电脑上本地运行Meta新的GPT-3级AI大型语言模型LLaMA。还有人把它在Raspberry Pi上成功运行了,尽管运行速度非常慢。那时候,斯坦福大学也有人专门研究这项技术。斯坦福开源项目Alpaca分享了实现原理:通过 ChatGPT API 接口调用 text-davinci-003 模型生成了 52000个 训练语料数据,基于 LLaMA 7B 模型使用这52K个语料数据 Fine-tune,8块A100显卡不到3小时完成,最终接近达到了与 OpenAI text-davinci-003 的效果,总共花费还不到600美元。2024年2月,创客发起项目,尝试将LLM本地端化。该项目名为World’s Easiest GPT-like Voice Assistant,即世界上最简单的类GPT语音助理,以此实现完全在本机端执行的GPT语音服务,不需要任何网络联机。具体方式是:利用树莓派,比如RPi 4,装上麦克风和喇叭,成为语音互动对话的输入输出,而后安装Whisper这套软件,将麦克风接收到的语音转成文字,文字喂给LLM。LLM接收输入后进行推论处理,处理后的结果以文字输出,输出的文字则透过另一个安装软件进行转化,即eSpeak,把文字转成语音后,再透过喇叭发声回复。最近, 北京邮电大学万物有灵团队也官宣在树莓派上跑GPT实验成功。把类GPT-3大模型经过量化缩小后,成功装进树莓派中,好比“大象装冰箱”!对于包含70亿个参数的LLaMA-7B,运行的最低内存要求为8GB或12GB。这对于弱计算能力设备仍是不小的负担,他们内存容量往往只有8G甚至4G,光加载模型这一步就将他们拦在GPT的大门外,更别说还需存储模型执行的中间结果。借助于模型量化手段,将模型权重进行压缩。如果想使用更大的模型,或者设备的内存进一步受限,那么模型量化的手段也不足以完全支撑模型的部署。这时,可以进一步将模型分割,并迁移到一个设备集群上执行,让多个模型来均摊巨大的内存开销。随着在模型初始化以及权重逐步加载,一个具备认知能力的最小智能体就诞生了。向它询问是否了解北邮,经过短暂的思考, 它开始逐字逐句地介绍起北京邮电大学。虽然响应缓慢,但还是成功的完成了整个计算推理流程。
超炫酷的漫游者机器人
一个名为Floyd的树莓派漫游者机器人,它因为集成了ChatGPT而变得非常健谈。
Floyd是YouTube博主Larry的杰作,使用树莓派4B 作为主控板。它部分由一个HAT(Hardware Attached on Top,顶部硬件附加)辅助,用于处理一些外部组件,比如用于操作轮子和手臂的舵机。机器人的身体似乎是用金属制成的,硬件完全暴露并安装在外面。就ChatGPT机器人而言,Floyd拥有相当多的身体部件可以操控。它能够通过一组轮子移动,甚至有一个可以移动的手臂。然而,得益于ChatGPT的集成,Floyd被赋予了说话的能力。通过麦克风和扬声器,Floyd可以进行语音到文本和文本到语音的交互并即时地给出定制化的回应。
再做一个桌面机器人
国外创客 David Packman 也制作了一款基于树莓派的机器人 MBO-AI,它的外观设计灵感来自动漫 Adventure Time 中的机器人 MBO,具有强大的交互功能,可实现脱机唤醒词检测、调用 ChatGPT 3.5 进行聊天、机器视觉对图像进行分析和说明等众多功能。BMO-AI 利用运行 Raspbian Bullseye 的 Raspberry PI 3B + 和 Adafruit CRICKIT Hat 进行伺服电机控制和来自其按钮阵列的信号输入。它有四个关节点和一个 5 英寸的显示屏,用于使用 Pygame 库显示面部表情和图像。BMO 还使用其他几个库来实现以下 AI 功能:- 语音转文本和文本转语音,使用 Azure 语音服务进行脱机唤醒词检测。
- 使用 OpenAI ChatGPT 3.5 Turbo 完成单轮问答文本。
- 使用 OpenAI ChatGPT 3.5 Turbo 聊天完成的多转和上下文感知聊天。
- 使用 Azure 计算机视觉服务进行图像分析和说明。
- 新的绘画模式使用稳定扩散根据您的口语描述绘制图片。
- 来自 ChatGPT 3.5 描述模式的新 DALL-E 映像,它将根据 ChatGPT 生成的描述创建映像。
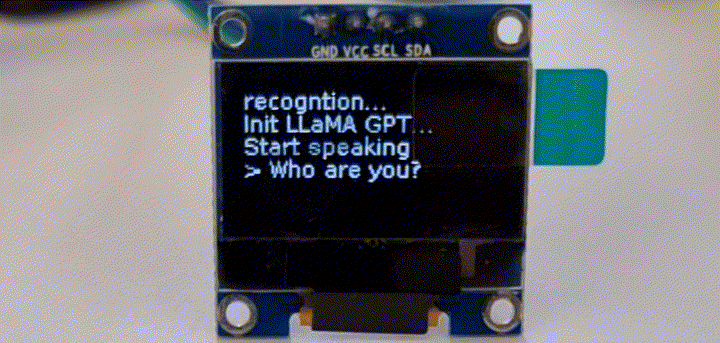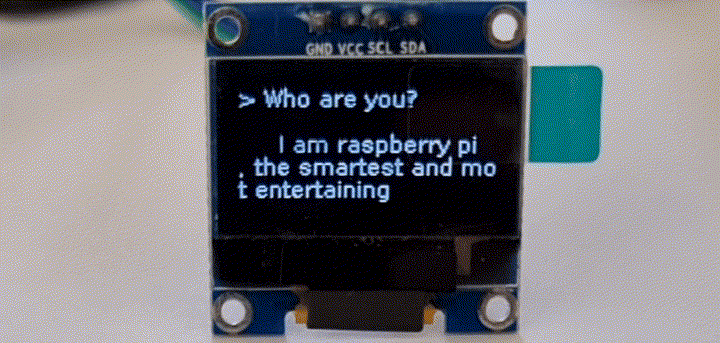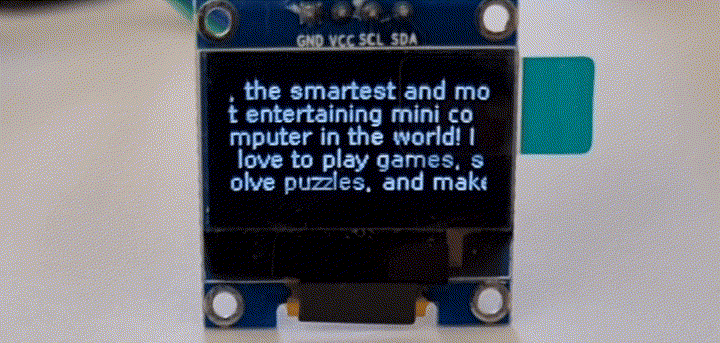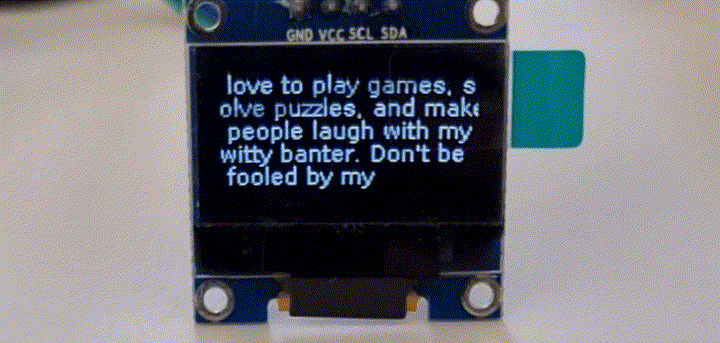
在树莓派上语音识别
目前,绝大多数大模型运行在云端服务器,终端设备通过调用api的方式获得回复。再过几年,万一项目组被关停,API接口被关闭,用户花大价钱购买的智能硬件可能会成为一块砖头。因此,如何完全离线运行一直是用户最关心的事情。国外网友利用Raspberry Pi 4和一块128x64 I2C的单色OLED显示屏,在树莓派上成功运行了语音识别和LLama-2 GPT。其中显示屏无需焊接,在 Raspberry Pi 设置中启用 I2C 接口即可。pip3 install llama-cpp-pythonpip3 install huggingface-hub sentence-transformers langchain
在使用LLM之前,需要下载它。使用huggingface-cli工具:
huggingface-cli download TheBloke/Llama-2-7b-Chat-GGUF llama-2-7b-chat.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks FalseORhuggingface-cli download TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
使用了 Llama-2–7b-Chat-GGUF和 TinyLlama-1–1B-Chat-v1-0-GGUF模型。较小的模型运行速度更快,但较大的模型可能会提供更好的结果。
from langchain.llms import LlamaCppfrom langchain.callbacks.manager import CallbackManagerfrom langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandlerfrom langchain.prompts import PromptTemplatefrom langchain.schema.output_parser import StrOutputParser
llm: Optional[LlamaCpp] = Nonecallback_manager: Any = None
model_file = "tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf" # OR "llama-2-7b-chat.Q4_K_M.gguf"template_tiny = """<|system|>You are a smart mini computer named Raspberry Pi.Write a short but funny answer.<|user|>{question}<|assistant|>"""template_llama = """[INST] <>You are a smart mini computer named Raspberry Pi.Write a short but funny answer.>{question} [/INST]"""template = template_tiny
def llm_init():""" Load large language model """global llm, callback_manager
callback_manager = CallbackManager([StreamingCustomCallbackHandler()])llm = LlamaCpp(model_path=model_file,temperature=0.1,n_gpu_layers=0,n_batch=256,callback_manager=callback_manager,verbose=True,)
def llm_start(question: str):""" Ask LLM a question """global llm, template
prompt = PromptTemplate(template=template, input_variables=["question"])chain = prompt | llm | StrOutputParser()chain.invoke({"question": question}, config={})
使用该模型很简单,但接下来:需要在 OLED 屏幕上流式地显示答案。为此,将使用自定义回调,每当 LLM 生成新令牌时都会执行该回调:class StreamingCustomCallbackHandler(StreamingStdOutCallbackHandler):""" Callback handler for LLM streaming """
def on_llm_start(self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any) -> None:""" Run when LLM starts running """print("")
def on_llm_end(self, response: Any, **kwargs: Any) -> None:""" Run when LLM ends running """print("")
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:""" Run on new LLM token. Only available when streaming is enabled """print(f"{token}", end="")add_display_tokens(token)
if __name__ == "__main__":add_display_line("Init automatic speech recogntion...")asr_init()
add_display_line("Init LLaMA GPT...")llm_init()
while True:# Q-A loop:add_display_line("Start speaking")add_display_line("")question = transcribe_mic(chunk_length_s=5.0)if len(question) > 0:add_display_tokens(f"> {question}")add_display_line("")
llm_start(question)
这里,Raspberry Pi 在 5 秒内录制音频,然后语音识别模型将音频转换为文本;最后,将识别出的文本发送给LLM。结束后,重复该过程。这种方法可以改进,例如,通过使用自动音频电平阈值,但对于一个weekend demo来说,它已经足够好了。 GPT+树莓派实现的AI拍立得
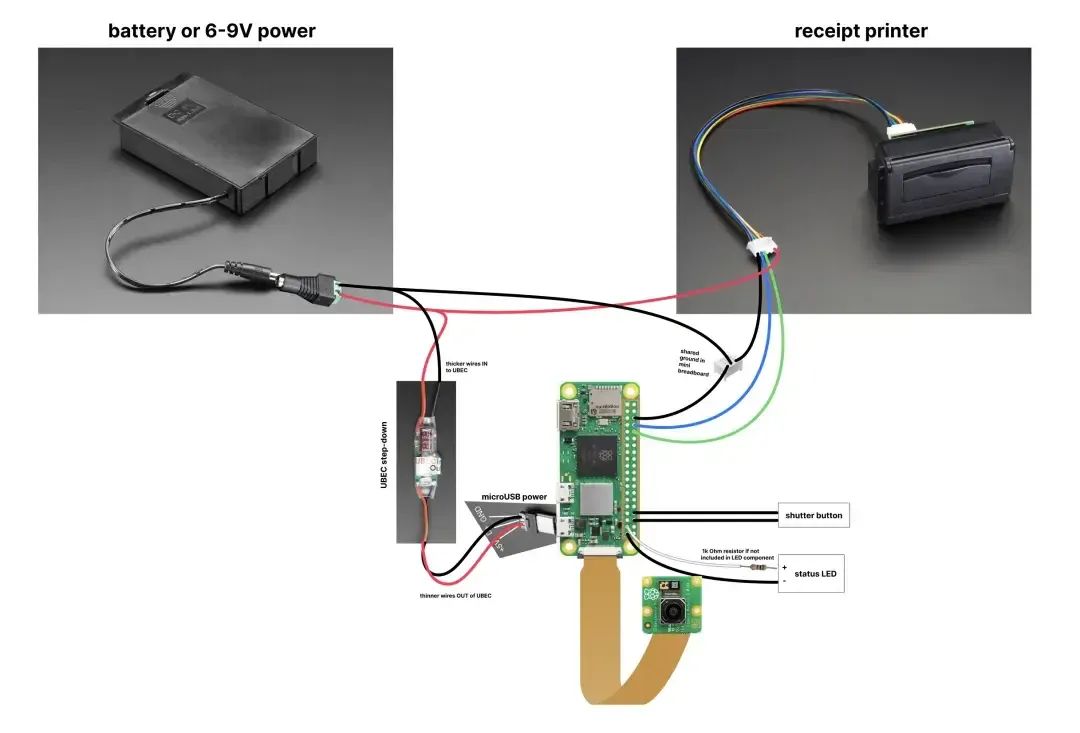
两位设计师 Kelin 和 Ryan 创造了一款 AI 新物种 Poetry Camera 诗歌相机。一块树莓派 Raspberry Pi Zero 2 W,一颗 1200 万像素树莓派 Camera Module 3 摄像头,一个热敏打印机,以及一些电池、线缆、存储卡配件。Kelin 和 Ryan 还将搭建 Poetry Camera 的软硬件"说明书",详细地公布在开源平台 GitHub 上。这也意味着,只要配齐素材,每个人都能创作出属于自己的 Poetry Camera。Poetry Camera 使用起来,与一般相机无异,按下「快门」即可。但不一般的是,Poetry Camera 只能生成诗歌,不能拍摄记录照片。对此,我们先看看 Poetry Camera 的技术逻辑:当按下"快门"按钮时,Poetry Camera 会将相机拍摄的照片传输给 ChatGPT,由 ChatGPT 识别照片,如其中色彩、形状、物体等关键信息,进而根据视觉数据,自动生成诗歌。来源:Marilyn Hue / Instagram诗歌生成后,再传送给 Poetry Camera,由热敏打印机将其打印出来。最后用户收到的是一条如超市购物单般印有诗歌的纸带。至于为什么不记录照片,Ryan 给出的答案是:简化功能会更易于我们创作这款产品,其次考虑的是隐私问题。 做一个支持ChatGPT的手表
YouTube博主MayLabs演示了一款用树莓派制作支持ChatGPT的智能手表,这款智能手表无需手机或PC支持,可以在任何地方使用,还可以通过ChatGPT回答用户的语音问题。该手表为一位化名为“Frumtha Fewchure”的制造商开发,它使用 Raspberry Pi 4B 进行处理。手表部分配有显示麦克风启用的LED 灯、几个按钮、一个 0.96 英寸的双色 OLED 屏幕和两个 Apple Watch 表带的支架。这些按钮为 6 x 6 x 4.3 毫米触觉按钮。此外,该手表还有一个LED用作红外线发射器,因此手表可以在最终更新中用作通用遥控器。手表上有三个按钮,通过Pi来识别你按了哪一个,通过这些按钮,您可以获得一些 CPU 统计信息或表盘,但最有趣的是连接到ChatGPT以提问的按钮。答案在显示屏上显示为文本,如果您连接了耳机(有线或蓝牙),也会通过音频显示,因为没有任何扬声器。虽然这款智能手表无需手机或PC支持,但想要与ChatGPT互动还需要互联网连接支持,因此您可以连接到家庭网络上的 Wi-Fi,视频创作者表示,他在咖啡店测试手表时,会将设备连接到智能手机的热点。随着人工智能技术的不断进步,树莓派已经成为了实现创新AI项目的热门平台。从能够离线运行的语音识别系统到集成了ChatGPT的健谈漫游者机器人Floyd,再到具有交互功能的桌面机器人MBO-AI,以及支持ChatGPT的智能手表,这些项目展示了树莓派在AI领域的广泛应用潜力。树莓派与AI的结合,不仅为技术爱好者和开发者提供了一个实验和创造的平台,也为我们打开了一扇通往智能世界的大门。
[1]https://mp.weixin.qq.com/s/zsWEtc6Ylc1BLZHSVYAI2Q[2]https://mp.weixin.qq.com/s/hZBIIn4pnrfLk-bHOL-TYw[3]https://mp.weixin.qq.com/s/OOh-U1--OoehAB8Dg72h-Q[4]https://mp.weixin.qq.com/s/moGb5Jtdniz7_HhRwdNhug[5]https://www.tomshardware.com/raspberry-pi/this-raspberry-pi-rover-bot-is-named-floyd-and-is-super-sassy-thanks-to-chat-gpt[6]https://mp.weixin.qq.com/s/Jpvlmh-C8Zjka2BG_AWagQ[7]https://mp.weixin.qq.com/s/rh9t7Wt7DVHL3P7xqwG3HQ[8]https://mp.weixin.qq.com/s/pwhr-wNG_amkIk52lYeIxA[9]https://mp.weixin.qq.com/s/z_xf-y7Ifhutq0FgxhtJaw