扫描关注一起学嵌入式,一起学习,一起成长

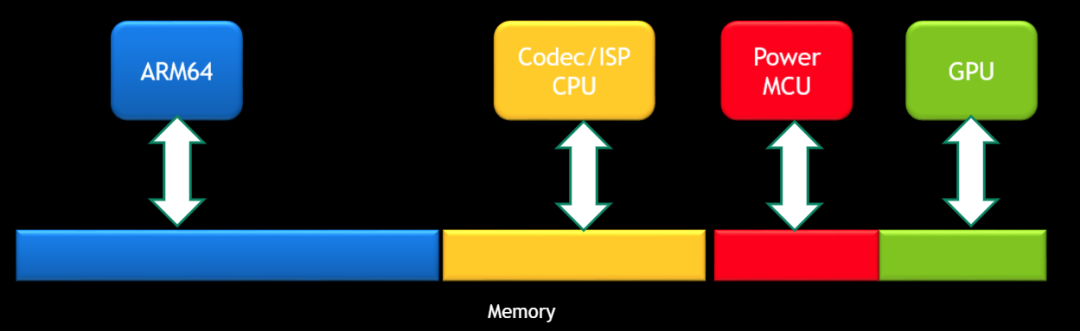
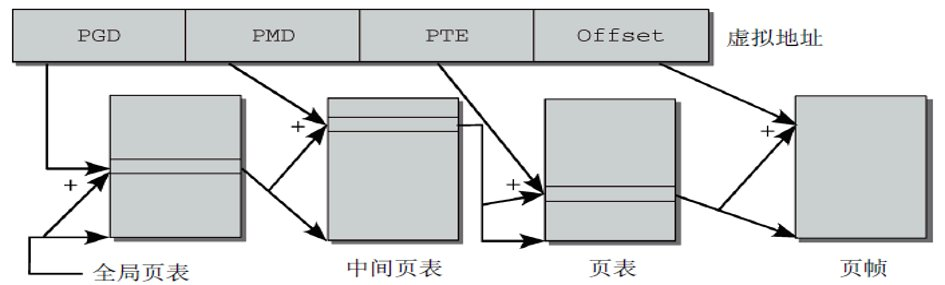
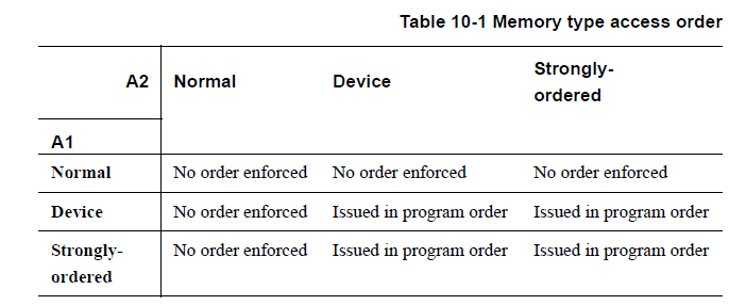
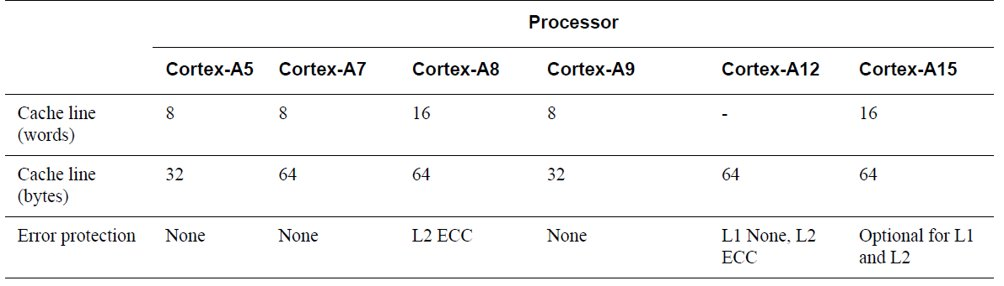
CPU体系结构和MMU的要求


对原子操作的影响
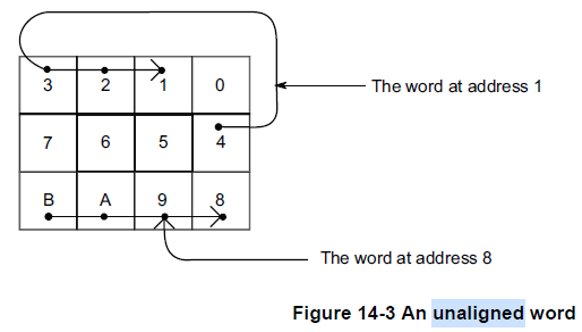
ARM NEON的要求
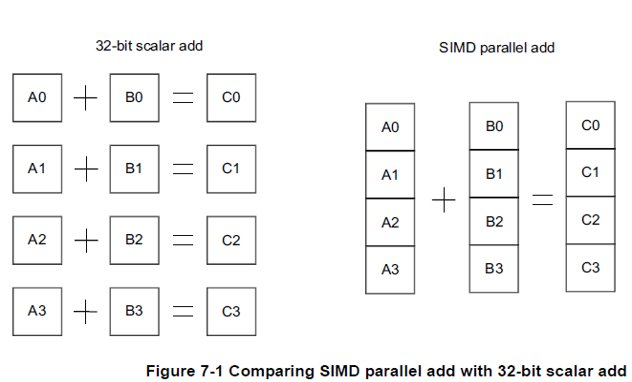
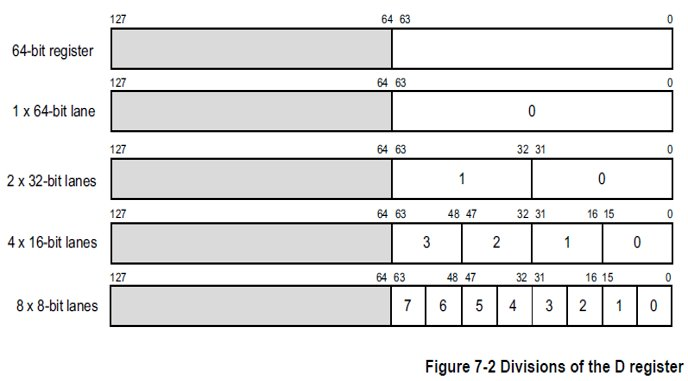
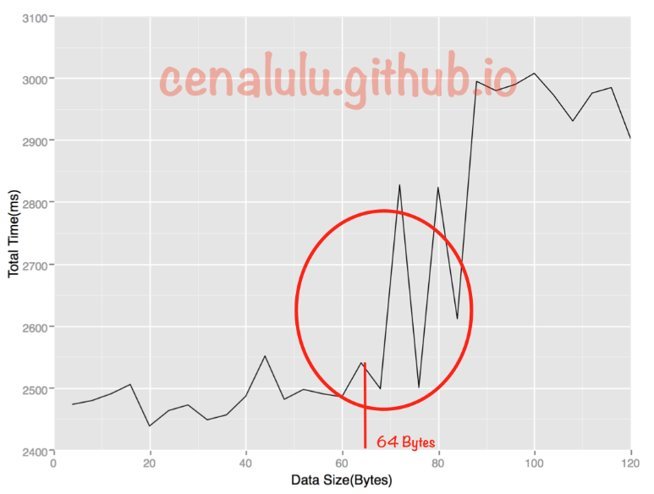
对性能perf的影响
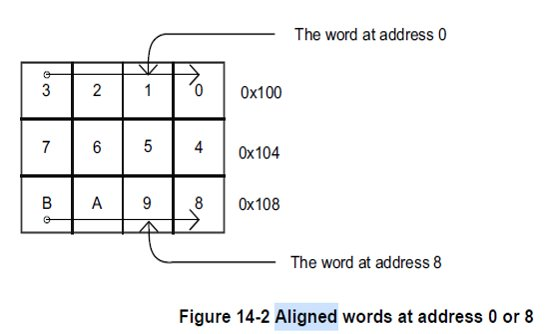
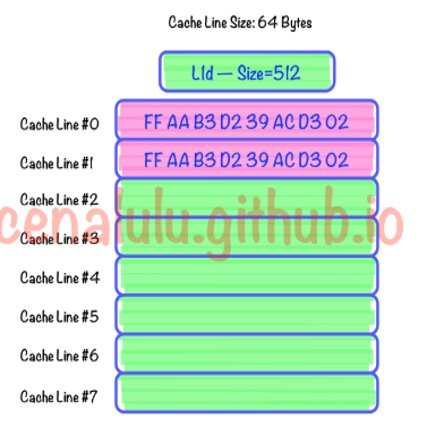
cache line 对齐
#include 'stdio.h'
#include
#include
long timediff(clock_t t1, clock_t t2) {
long elapsed;
elapsed = ((double)t2 - t1) / CLOCKS_PER_SEC * 1000;
return elapsed;
}
int main(int argc, char *argv[])
#*******
{
int array_size=atoi(argv[1]);
int repeat_times = 1000000000;
long array[array_size];
for(int i=0; i array[i] = 0;
}
int j=0;
int k=0;
int c=0;
clock_t start=clock();
while(j++ if(k==array_size){
k=0;
}
c = array[k++];
}
clock_t end =clock();
printf('%lu\n', timediff(start,end));
return 0;
} 
没有对齐到同一个cache line中的变量,在多核SMP系统中,cross cache line操作是非原子操作,存在篡改的风险。该例子引用自kongfy) 测试代码如下, 程序大意是,系统cpu的cache line是64字节,一个68字节的结构体struct data, 其中前面填充60字节的pad[15]数组,最后一个8字节的变量v, 这样结构体大小超过了64字节,最后一个变量v的前后部分可定不在同一个cache line中,整个结构体没法根据cache line对齐。
全局变量value.v初始值是0, 程序开多线程,对全局变量value.v进行多次~位取反操作,直觉上最后结果value.v的位结果不是全0就是全1,但是最后value.v的位结果居然是一半1一半0, 这就是由于cross cache line 操作是非原子性的,导致一个线程对value.v前半部分取反的时候,另外的线程对后半部分在另一个cache line同时取反,然后前一个线程再对另一个cache line的value.v后半部分取反,导致和直觉不一致。
#include
#include
#include
#include
using namespace std;
static const int64_t MAX_THREAD_NUM = 128;
static int64_t n = 0;
static int64_t loop_count = 0;
#pragma pack (1)
struct data
{
int32_t pad[15];
int64_t v;
};
#pragma pack ()
static data value __attribute__((aligned(64)));
static int64_t counter[MAX_THREAD_NUM];
void worker(int *cnt)
{
for (int64_t i = 0; i < loop_count; ++i) {
const int64_t t = value.v;
if (t != 0L && t != ~0L) {
*cnt += 1;
}
value.v = ~t;
asm volatile('' ::: 'memory');
}
}
int main(int argc, char *argv[])
{
pthread_t threads[MAX_THREAD_NUM];
/* Check arguments to program*/
if(argc != 3) {
fprintf(stderr, 'USAGE: %s \n' , argv[0]);
exit(1);
}
/* Parse argument */
n = min(atol(argv[1]), MAX_THREAD_NUM);
loop_count = atol(argv[2]); /* Don't bother with format checking */
/* Start the threads */
for (int64_t i = 0L; i < n; ++i) {
pthread_create(&threads[i], NULL, (void* (*)(void*))worker, &counter[i]);
}
int64_t count = 0L;
for (int64_t i = 0L; i < n; ++i) {
pthread_join(threads[i], NULL);
count += counter[i];
}
printf('data size: %lu\n', sizeof(value));
printf('data addr: %lX\n', (unsigned long)&value.v);
printf('final: %016lX\n', value.v);
return 0;
}文章来源于网络,版权归原作者所有,如有侵权,请联系删除。

关注【一起学嵌入式】,回复“加群”进技术交流群。
觉得文章不错,点击“分享”、“赞”、“在看” 呗!
