现代社会的各个方面都需要先进的人工智能(AI)来处理,例如对周围环境的识别、行动决策和运动控制,这包括工厂、物流、医疗、城市中的服务机器人以及安全摄像头等应用场景。然而,要在边缘端实现人工智能,我们需要克服两大挑战:功耗和灵活性。
在云端,我们可以配备足够的电源和冷却机制来支持复杂的AI模型,但边缘端的设备往往限制了功耗,这可能导致运行时间的缩短和成本的增加。此外,随着AI模型不断发展,专用的AI加速硬件很快就会过时,这意味着我们需要一种更灵活的解决方案来支持新开发的AI模型。因此,嵌入式端的AI加速成为一个重要的解决方案,它可以在边缘设备上实现AI任务的高效执行,并为新的AI模型提供灵活性和支持。
为了满足市场需求,瑞萨自主研发了用于AI加速的处理器DRP-AI(Dynamically Reconfigurable Processor for AI人工智能动态可配置处理器),该处理器集成与RZ/V系列芯片中。
DRP-AI处理器具备边缘端设备所需的低功耗和灵活性,经过多年技术迭代已发展到第三代,实现了比上一代高约10倍的能效。DRP-AI3(集成与RZ/V2H)能够适应AI的进一步发展和高性能机器人等应用的复杂要求。
DRP-AI3解决了低功耗挑战,并实现了高实时处理。它为具有AI能力的产品提供了更高性能和更低功耗。接下来,我们将深入了解DRP-AI3是如何实现这些目标的。
1
软、硬结合系统性地实现AI模型的高速和低功耗
量化
从传统的16位浮点运算更改为8位整数运算(INT8)。该方法也是现在比较流行的一种运算处理方式。
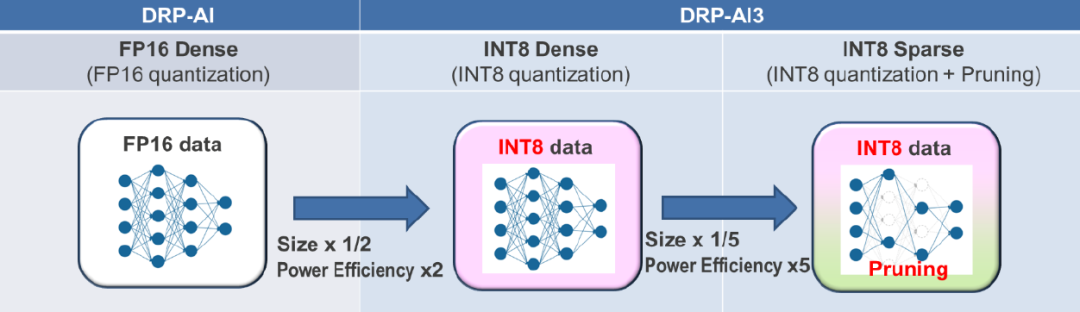
修剪
采用灵活的N:M修剪方法
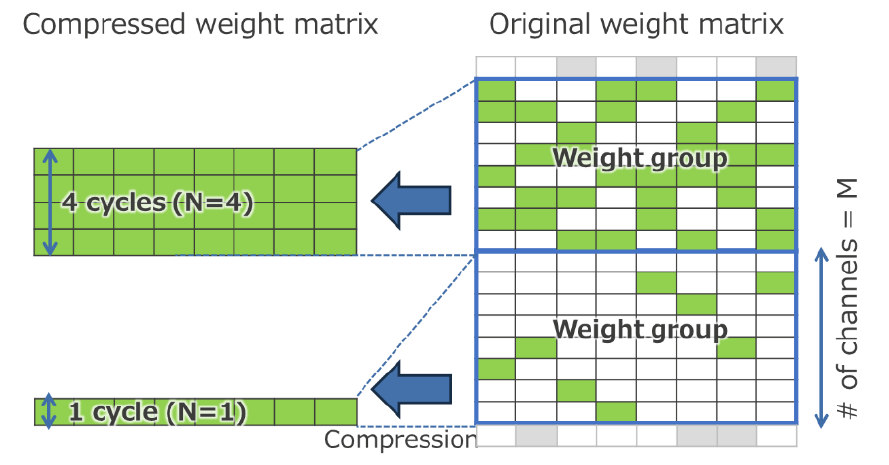
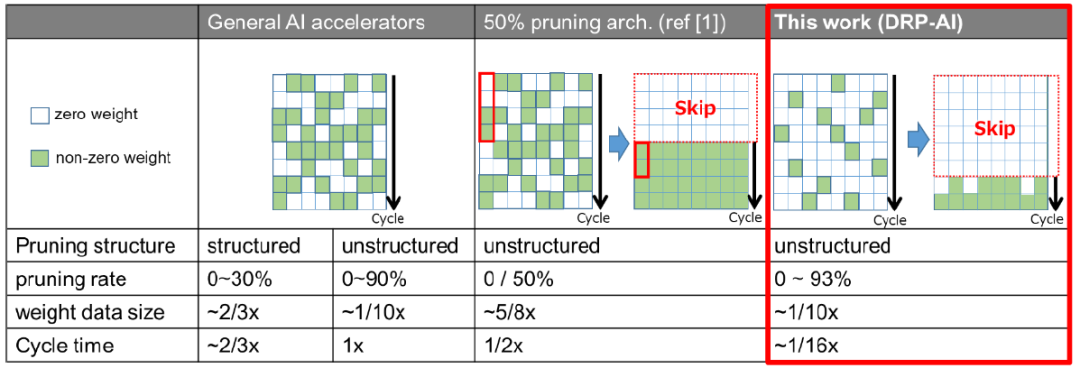
N:M技术的基本概念是将原始权重矩阵划分为M行的权重矩阵组,并将其重构为较小的N行权重矩阵组。在每组中,只提取有效权重,然后对新的权重矩阵组进行并行运算。DRP-AI3引入了一个新功能,它可以通过自由切换每个权重矩阵组的N值来调整运算周期的数量,从而可以在实际的AI模型中对局部变化的修剪率执行最优的运算处理。这种精细改变N的能力还允许详细设置整个权重矩阵的修剪率,根据用户对功耗、操作速度和识别精度的要求进行最佳的修剪处理。
2
AI系统架构实现高功效
通过数据重用技术减少外部存储器通信
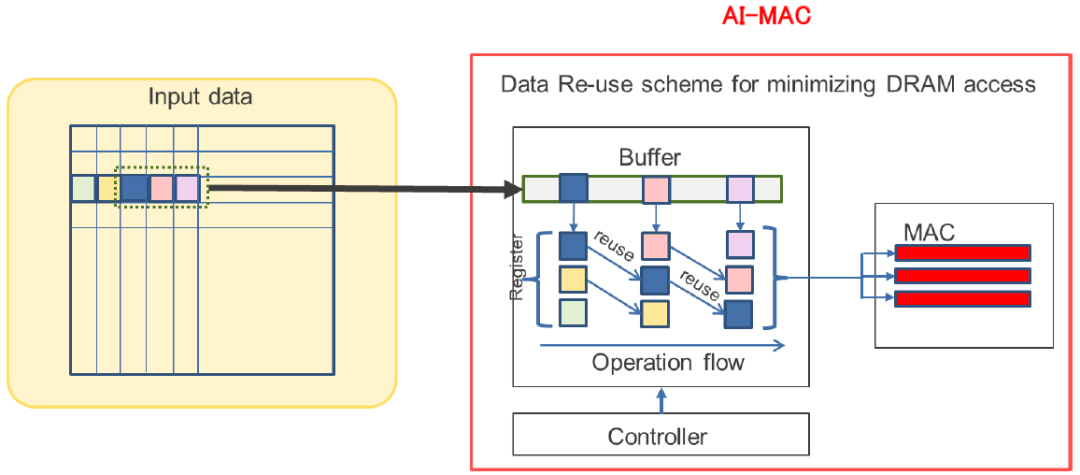
DRP-AI采用了一种有效地重用一次输入到AI-MAC的技术。例如,在3x3滤波器的卷积运算中,一个数据像素用于九个滤波器运算。im2col被广泛用作GPU中的高度并行运算方法,它以矩阵运算的顺序扩展所有图像数据作为输入到GPU的预处理步骤。然而,这会导致一个像素的数据信息出现九次,数据的数量增加了九倍,进而增加了功耗和通信带宽的消耗。相比之下,AI-MAC可以通过将取入与MAC算术单元相对应的寄存器中的数据移位到相邻寄存器来重用数据,从而避免了重复存储和传输数据,减少了功耗和通信带宽的消耗。
通过采用如下图所示的配置,与GPU相比,从外部存储器和内部缓冲器到AI-MAC的数据加载的数量可以减少多达九倍。这种优化方案显著降低了数据移动所需的功率和通信带宽消耗。此外,AI-MAC不仅可以对输入数据进行重用,还可以对输出和权重信息进行重用,从而将对外部存储器的访问减少了一个数量级以上。
使用输入的零数据控制功耗
人工智能模型计算的一个特点是每一层的权重数据和输入/输出数据中“零”值的比例很高,这被称为稀疏化。例如,在图像识别模型中,所有层50%以上的输入和输出数据平均为零值。这主要是因为许多人工智能模型使用激活函数(如ReLU),该函数会将乘积和运算的所有负结果替换为零。在DRP-AI中,通过引入切换技术来减少不必要的计算能力。该切换技术预先检测何时在操作的每个元素输入中输入零,并防止不必要的操作。
操作调度流程
除了数据重用技术之外,优化外部数据访问或MAC处理等操作的顺序和定时对于有效的AI执行至关重要。换句话说,调度操作流程可以最大化DRP-AI的性能。
例如,通过调度外部存储器访问定时,可以在AI-MAC操作期间提前读取下一操作的权重信息并将其存储在缓冲器中,从而防止和减少外部存储器访问延迟。这种方式也可应用于内部存储器访问和任何内部算术处理的定时中,调度可以避免每个处理之间不必要的等待时间和功耗的产生。由于DRP-AI工具自动生成这种优化的调度,用户能够轻松应对。
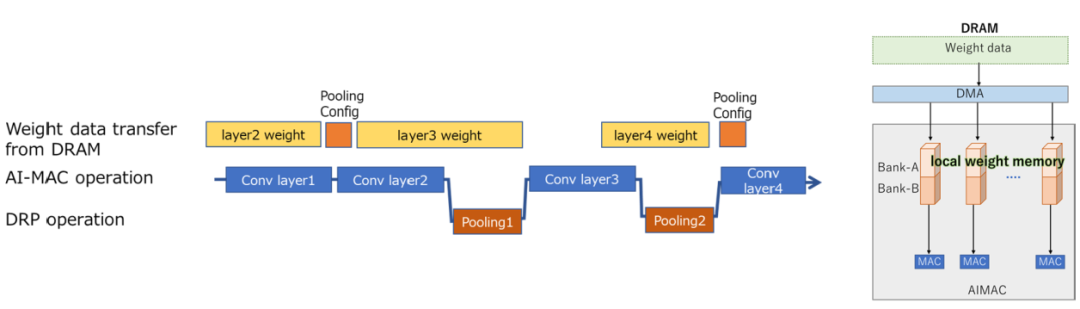
瑞萨开发的DRP-AI3(人工智能动态可重构处理器)是一种独特的AI加速器。它将嵌入式端所需的低功耗和灵活性与人工智能模型轻量级的处理能力相结合,相较于以前的模型,DRP-AI3的能效提高了10倍(10 TOPS/W)。
瑞萨将继续扩大研发RZ/V系列,以提供更多配备这种卓越AI加速器的MPU产品。更多相关信息,您可点击文末阅读原文访问查看。
1
END
1
推荐阅读
DRP-AI和GPU之间的性能基准
RZ/V2H MPU提高了机器人和自主应用中的AI性能和实时控制
新品详解 | 新一代视觉AI MPU处理器RZ/V2H 高算力、低功耗、实时性