


芝能智芯出品
近日,AMD、博通(Broadcom)、思科(Cisco)、谷歌(Google)、惠普企业(HPE)、英特尔(Intel)、Meta和微软(Microsoft)八家公司宣布了一个新的技术标准——Ultra Accelerator Link(UALink)。
这一开放标准旨在打破NVIDIA在人工智能(AI)数据中心网络中的垄断地位。
NVIDIA的现状与挑战

GPU被设计用于加速计算机图形的渲染,但很快被高性能计算(HPC)领域的从业者发现其在大规模并行计算中的巨大潜力。随着生成式人工智能(GenAI)的兴起,GPU的需求量激增,甚至引发了所谓的“GPU紧缺”现象。
GPU连接的三种方法:
● PCI总线
标准服务器通常可以通过PCI总线支持4-8个GPU,使用GigaIO FabreX内存结构等技术,这个数字可以增加到32个。虽然CXL技术也表现出了一定的潜力,但Nvidia对此的支持较少。对于许多应用来说,这些可组合的GPU域是替代GPU间直接扩展的方法。
● 服务器间互连
以太网或InfiniBand技术可以连接包含GPU的服务器,形成大型计算网络。以太网长期以来一直是计 算机网络的主力,而英特尔的Gaudi-2 AI处理器在芯片上集成了24个100Gb以太网连接。相比之下,Nvidia通过收购Mellanox独占了高性能InfiniBand互连市场。
● GPU到GPU互连
Nvidia开发了NVLink技术,实现GPU间每秒1.8TB的数据传输,并通过NVLink交换机在无阻塞计算架构中支持多达576个GPU。NVLink连接的GPU被称为“pod”,具有独立的数据和计算域。
NVIDIA目前在AI芯片市场上处于领导地位,不仅仅依靠其GPU芯片,还通过一系列技术巩固其市场地位。例如,NVLink是NVIDIA用于在多GPU系统中提供高速连接的技术。还利用Infiniband和以太网进行更大范围的系统连接。
NVLink是NVIDIA开发的一种高速GPU互连技术。相比传统的PCI-E解决方案,NVLink在速度上有显著提升,能够实现GPU之间每秒1.8TB的数据传输。
此外,NVLink还支持多达576个完全连接的GPU,形成无阻塞的计算结构。NVLink 最初是一种将 Nvidia GPU 卡上的内存组合在一起的方法,最终 Nvidia Research 实现了一个交换机来驱动这些端口,允许 Nvidia 以杠铃拓扑(barbell topology)连接两个以上的 GPU,或以十字交叉方形拓扑(crisscrossed square topology)连接四个 GPU,这种拓扑几十年来通常用于创建基于 CPU 的双插槽和四插槽服务器。通过 NVLink 连接的 GPU 称为“pod”,表示它们有自己的数据和计算域。
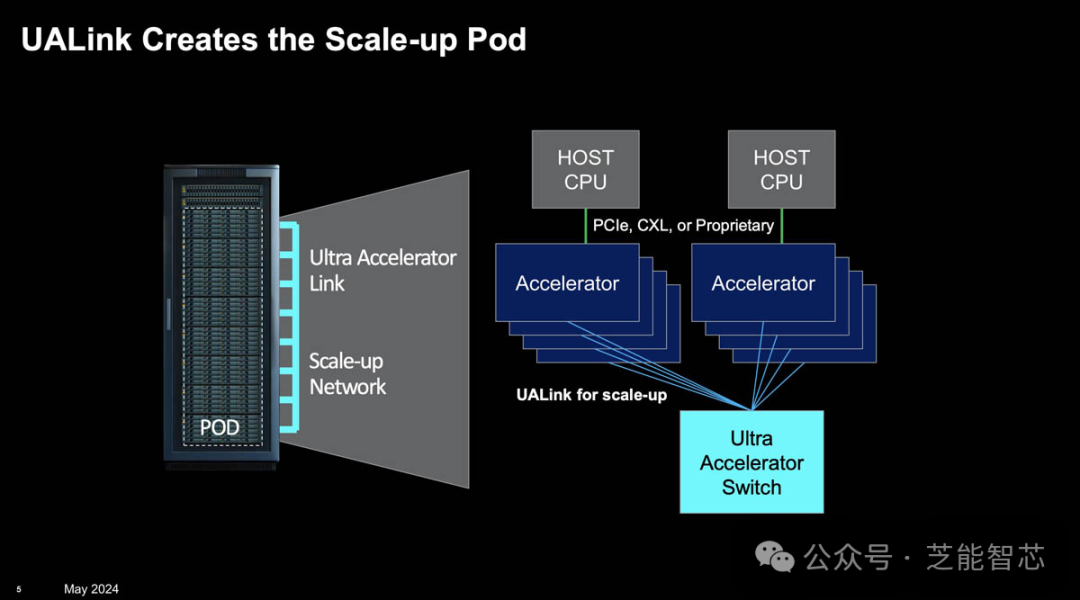
UALink的诞生

UALink是一种可提高新一代AI/ML集群性能的高速加速器互连技术。八家发起厂商成立了一个开放行业标准机构,制定相关技术规范,以促进新使用模式所需的突破性性能,同时支持数据中心加速器用开放生态系统的发展。
UALink 将通过以下方式提高性能:
● 低延迟和高带宽:通过 Infinity Fabric 协议,UALink 将实现低延迟和高带宽的互连,适用于AI和ML集群中的高性能计算需求。
● 大规模扩展:UALink 1.0版规范将允许在AI容器组中连接不超过1,024个加速器,支持在容器组中挂载到加速器(例如GPU)的内存之间进行直接加载和存储。
● 开放性和兼容性:UALink联盟旨在创建一个开放的行业标准,允许多家公司为整个生态系统增加价值,从而避免技术垄断。

预计到2024年第三季度,UALink的1.0版规范将正式推出,并向联盟公司开放。此外,1.1版规范将在2024年第四季度发布,进一步提高规模和性能。这些规范将支持多种传输,包括PCI-Express和以太网。
CXL(Compute Express Link)仍然是一个值得关注的传输协议,提供了CPU和GPU之间的内存共享功能。未来,CXL可能会成为CPU共享内存的标准方式。
小结
UALink的出现为打破NVIDIA在AI数据中心网络中的垄断提供了新的可能。随着这一标准的逐步推进,行业内的竞争将更加激烈,各家公司将有机会在这一领域取得新的突破。对于用户而言,这意味着将有更多高性能、低成本的选择可供使用。
