


InfiniBand作为一种先进的内网计算平台,已成为驱动高性能计算(HPC)、人工智能(AI)以及超大规模云基础设施演进的核心力量,其展现出无可比拟的性能优势。专为满足服务器级连接需求而设计,InfiniBand在服务器间的高速通信、存储设备与网络设施之间的高效互联中扮演着至关重要的角色。这一技术凭借其卓越性能和可靠表现,不仅被InfiniBand行业协会广泛接纳并积极推广,更是在全球超级计算机500强榜单(TOP500 list)中占据了主导地位,成为首选互连解决方案。
值得注意的是,在TOP500系统列表中,有44.4%的系统采用了InfiniBand作为关键的互连技术手段,远超过采用以太网技术的40.4%份额。接下来,我们将深入剖析InfiniBand相较于以太网的独特之处及其在高性能网络环境中的差异化应用价值。
AI算力研究:英伟达B200再创算力奇迹,液冷、光模块持续革新
英伟达发布新一代GPU架构,NVLink连接技术迭代升级
大模型语言模型:从理论到实践
技术展望2024:AI拐点,重塑人类潜力
英伟达GTC专题:新一代GPU、具身智能和AI应用
AI算力研究:英伟达B200再创算力奇迹,液冷、光模块持续革新
GPU深度报告:英伟达GB200 NVL72全互联技术,铜缆方案或将成为未来趋势?
人工智能系列专题报告:CoWoS技术引领先进封装,国内OSAT有望受益
软硬件融合:从DPU到超异构计算
《大模型技术能力测评合集》
1、大模型时代,智算网络性能评测挑战
2、AIGC通用大模型产品测评篇(2023)
3、人工智能大模型工业应用准确性测评
4、甲子星空坐标系:AIGC通用大模型产品测评篇
5、AIGC通用大模型产品测评篇(2023)
6、2023年中国大模型行研能力评测
1、新型智算中心算力池化技术白皮书 2、智算中心网络架构白皮书 3、面向AI大模型的智算中心网络演进白皮书 4、智算赋能算网新应用白皮书
14份半导体“AI的iPhone时刻”深度系列报告合集
12份走进“芯”时代系列深度报告合集
作为一种由InfiniBand贸易协会(IBTA)指导制定的标准化通信规范,InfiniBand专注于设计一种适用于数据中心内部服务器、通讯基础设施设备、存储解决方案以及嵌入式系统之间互连的交换结构体系。其对标准化的高度关注确保了在高性能计算网络环境中各组件间实现无缝集成和高效信息传递。
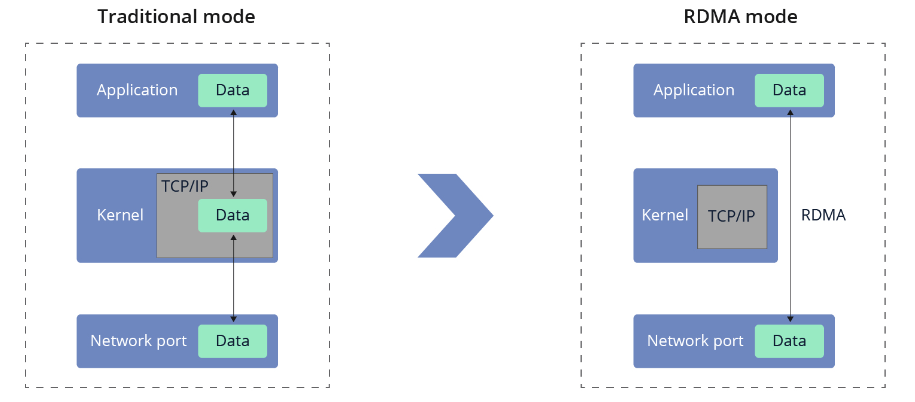
InfiniBand凭借其显著的高带宽及低延迟特性而闻名遐迩,目前支持诸如FDR 56Gbps、EDR 100Gbps、HDR 200Gbps乃至NDR 400Gbps/800Gbps(通过4x链路宽度连接时的数据传输速率),并有望在未来进一步提升速度阈值。此外,InfiniBand具备出色的可扩展性,可在单个子网内轻松支持数万个节点,因此成为高性能计算(HPC)环境的理想选择。同时,借助服务质量(QoS)和故障转移功能,InfiniBand成为了非易失性内存快速结构化接口(NVMe-oF)存储协议以及包括以太网、光纤通道(FC)和TCP/IP在内的多种网络架构中的关键组件。对于追求卓越性能与极致扩展性的数据中心而言,采用InfiniBand无疑是明智之举。
源自施乐公司、英特尔公司和DEC共同构思的以太网标准,已经成为全球范围内使用最为广泛的局域网(LAN)数据传输通信协议。自20世纪70年代起,以太网作为一种有线通信技术被开创出来,用于连接各种局域网(LAN)或广域网(WAN)内的设备。得益于其极高的适应性,无论是打印机还是笔记本电脑等不同类型的设备都能够通过以太网实现相互连接,应用场景广泛覆盖建筑楼宇、居民住宅乃至小型社区。用户友好的配置方式使得只需通过路由器和以太网连线即可简便构建LAN网络,进而整合各类如交换机、路由器和个人计算机等设备。
尽管无线网络在许多场合得到广泛应用,但以太网仍凭借其卓越的可靠性和抗干扰能力,在有线网络领域保持着首选地位。历经多年的发展与修订,以太网不断提升和完善自身功能。如今,IEEE旗下802.3标准组织已经发布了包括100GE、200GE、400GE和800GE在内的多个以太网接口标准,这体现了业界持续推动和优化以太网技术的决心与努力。
InfiniBand技术最初旨在解决高性能计算环境中集群间数据传输的瓶颈问题,随着时间推移,已逐渐演变为一种广泛应用的互连标准,并成功适应了现代多样化的需求。相较于以太网,InfiniBand在带宽、延迟、网络可靠性和网络架构等方面表现出显著差异。
InfiniBand的发展速度较快,尤其体现在其对高性能计算场景的高度优化和降低CPU处理负载的能力上。而以太网尽管广泛应用于各类终端设备间的连接,但在高带宽需求层面并不像InfiniBand那样迫切。
InfiniBand采用Cut-Through交换技术,在转发数据时能将延时降至100纳秒以内,大大提升了网络响应速度。相比之下,以太网由于在其交换机中引入了诸如IP、MPLS、QinQ等服务所带来的额外处理流程,导致转发延时相对较高。
InfiniBand凭借明确的第1层至第4层协议格式设计以及端到端流控制机制,确保了无损网络通信,为高性能计算领域提供了卓越的可靠性保障。而以太网则缺乏类似的基于调度的流控制机制,依赖于芯片更大的缓存区域临时存储消息,这不仅增加了成本,还加剧了功耗。
InfiniBand借鉴了软件定义网络(SDN)理念,使其网络架构更为简洁高效。每个第二层网络内部都配备了一个子网管理器,用于配置节点并智能计算转发路径信息。与此相反,以太网需要依赖MAC地址条目、IP协议以及ARP协议等多个层次实现网络互联,从而增加了网络管理的复杂性。此外,以太网依靠定期发送更新包来维护路由表,并通过VLAN机制划分虚拟网络边界,限制网络规模;然而这种机制可能导致环路等问题出现,因此通常还需要STP等额外协议来进行环路避免。
对比分析表明,相较于以太网,InfiniBand网络在高性能计算领域展现出了无可比拟的优势。对于计划在高级数据中心部署InfiniBand交换机的用户而言,有必要深入了解其详细性能特点和迭代历程。历经多年快速发展,InfiniBand标准已从最初的SDR 10Gbps、DDR 20Gbps、QDR 40Gbps,逐步演进到FDR 56Gbps、EDR 100Gbps,并进一步发展为HDR 200Gbps及NDR 400Gbps/800Gbps等更高速率规格,这些重大突破得益于RDMA(远程直接内存访问)技术的集成应用。
飞速(FS)为此提供了一系列先进InfiniBand解决方案,其中包括NVIDIA Quantum™-2 NDR InfiniBand 400G数据中心交换机以及NVIDIA Quantum™ HDR InfiniBand 200G数据中心交换机,这两款产品均支持管理型和非管理型两种配置模式,以满足不同客户对灵活性的需求。此外,为了确保全方位服务支持,针对400G交换机,飞速(FS)还提供了为期一年、三年或五年的服务选项,旨在帮助用户实现高效稳定的数据中心运行环境。


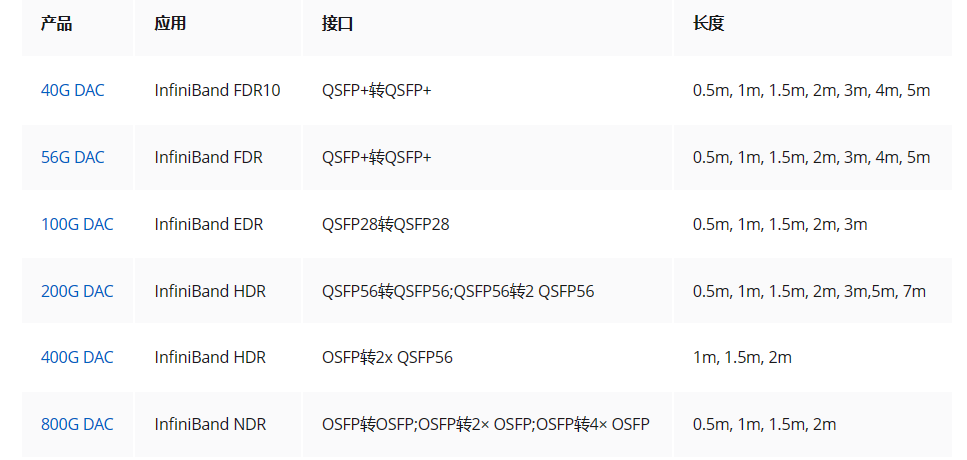
InfiniBand NDR系列包括了适用于400Gbase/800Gbase传输速率的光收发器与直连铜缆(DAC),旨在兼容Mellanox NDR 400Gb交换机,如MQM9700/MQM9790系列。这些组件在GPU加速计算场景中提供了高性能连接,并有望节省高达50%的成本。它们特别适合于高性能计算(HPC)、云计算、模型渲染和基于InfiniBand 400Gb/800Gb网络的存储应用。
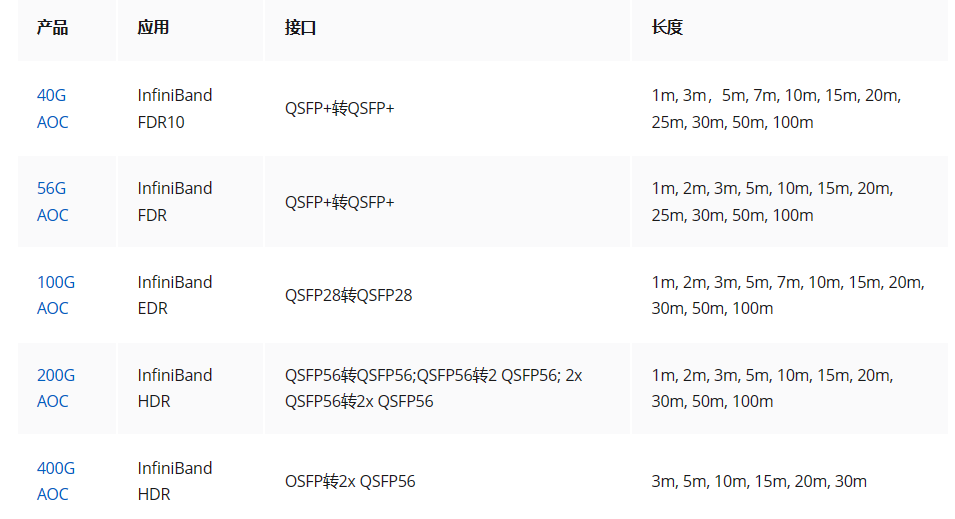
飞速(FS)推出的InfiniBand HDR产品线涵盖了多样化的高速互联产品,例如200Gb/s和400Gb/s QSFP56 IB HDR多模光纤(MMF)有源/无源光缆(AOC)、有源/无源直连铜缆(DAC)、光学收发器路由器以及200G交换机等。这些模块和电缆能够无缝衔接MQM8700/MQM8790等交换机与NVIDIA GPU(如A100/H100/A30)和CPU服务器,以及ConnectX-5/6/7 VPI等存储网络适配器。此类解决方案不仅可实现最高达50%的成本节约,而且在涉及GPU加速的高性能计算(HPC)集群应用——包括模型渲染、人工智能(AI)、深度学习(DL)以及InfiniBand HDR环境下的NVIDIA应用网络通信时表现出卓越性能。
InfiniBand EDR产品系列提供了一系列100Gbase QSFP28 EDR AOC、EDR DAC、AOC及光收发器,专为GPU加速计算设计,具有成本效益高且性能优越的特点。
InfiniBand FDR产品范围包括了40Gbase QSFP+ FDR10 AOC、DAC及光收发器,以及56Gbase QSFP+ FDR DAC和AOC。所有这些产品均可无缝整合到Mellanox EDR交换机之中。
随着数据通信、互联网技术和可视化展现需求的不断提升,对计算能力、存储容量以及网络效率的需求也随之增长。在此背景下,InfiniBand网络凭借其提供的高带宽服务、低延迟特性以及将协议处理和数据移动从CPU转移到互连层以减少计算资源消耗的独特优势,成为了高性能计算数据中心的理想选择。此技术广泛应用于Web 2.0、云计算、大数据处理、金融服务、虚拟化数据中心以及存储应用等领域,带来了显著的性能提升效果。
速度方面,InfiniBand已超越100G以太网,目前支持从100G/200G到400G/800G不等的InfiniBand交换机配置,完美契合HPC架构的高性能要求。InfiniBand交换机通过高带宽、高速度与低延迟的有效结合,有力提升了服务器效能和应用运行效率。
扩展性是InfiniBand另一项突出优点,单个子网能够在网络层2上支持多达48,000个节点,相比以太网,它减少了对ARP广播机制的依赖,有效避免了广播风暴并减轻了额外带宽浪费。此外,多个子网可以灵活地关联至交换机,进一步增强了网络的灵活性。
飞速(FS)深刻认识到高性能计算的重要性,因此提供了一系列基于Quantum InfiniBand交换设备构建的InfiniBand产品。这些产品支持高达16Tb/s的无阻塞带宽,并拥有低于130ns的端口间延迟,确保为HPC数据中心提供高可用性和多服务支持。尽管以太网网络通过跨多个设备分配工作负载仍不失为有效的数据传输选项,但FS同样供应一系列多速率以太网交换机,协助客户构建既灵活又高效的网络环境。
在选择合适的网络技术时,InfiniBand与以太网各自在不同应用场景中展现出独特优势。当聚焦于显著提升数据传输速率、优化网络资源利用率并有效减轻CPU在网络数据处理方面的负担时,InfiniBand网络凭借其核心技术优势,在高性能计算领域脱颖而出,成为关键的解决方案。
然而,在数据中心环境中,若节点间通信延迟并非首要考量因素,且更加重视网络接入的灵活性与扩展性,则以太网网络能够提供一种长期稳定且适应性强的基础设施支持。
InfiniBand网络凭借其卓越性能和创新架构设计,为HPC数据中心用户带来了前所未有的业务效能优化潜力。通过消除多层级结构所导致的延迟问题,并确保关键计算节点能无缝升级接入带宽,InfiniBand技术对于整体运营效率的提升起到了决定性作用。随着其应用范围不断扩大和技术认可度持续攀升,预计未来InfiniBand网络将在更多复杂且要求严苛的应用场景中得到广泛应用和部署。
InfiniBand,撼动不了以太网?
英伟达Quantum-2 Infiniband平台技术A&Q
一颗Jericho3-AI芯片,用来替代InfiniBand?
RoCE技术在HPC中的应用分析
《RDMA技术参考文献汇总》
《RDMA技术合集(下)》
1、总线级数据中心网络技术白皮书.pdf
2、RDMA提高数据传输效率.pdf
3、配置 InfiniBand 和 RDMA 网络.pdf
4、华为RDMA.pdf
5、面向AI智能无损数据中心网络.pdf
6、面向分布式 AI智能网卡低延迟Fabric技术.pdf
7、NVMe存储SPDK 加速前后端 IO.pdf
8、基于RDMA多播机制的分布式持久性内存文件系统.pdf
9、云环境下分布式存储性能优化实践.pdf
《RDMA技术合集(上)》
1、智能网卡低延迟Fabric技术.pdf
2、RDMA参数选择.pdf
3、RDMA在数据中心中的应用研究.pdf
4、RDMA系统的挑战.pdf
5、RDMA网络人工智能训练重要硬件
6、RDMA技术白皮书(中文版)
7、RDMA技术调研
8、RDMA在数据中心中的应用研究
《NVIDIA InfiniBand网络技术新特性(2023)》
1、NVIDIA InfiniBand-NDR Q&A
2、NVIDIA Infiniband Networking Update 2023
《OFA Workshop 2023合集》
《NVIDIA Jetson机器软件栈更新合集》
1、NVIDIA Jetson自主机器软件栈更新
2、NVIDIA Jetson赋能新一代自主机器
《集成电路及芯片知识汇总(2)》
《集成电路及芯片知识汇总(1)》
OrionX GPU AI算力资源池化技术白皮书
HPDA/AI市场表现Update浅析(附报告)
HPC市场份额剖析和全球超算计划(附报告)
Hyperion Research:SC22 HPC Market Update(2022.11)
Hyperion Research:ISC22 Market Update(2022.5)
Intersect360全球HPC-AI市场报告(2022—2026)
Intersect360 AMD CPU和GPU调研白皮书
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


