
当前,超万卡集群的建设仍处于起步阶段,主要依赖英伟达GPU及配套设备实现。英伟达作为全球领先的GPU供应商,其产品在大模型训练上有较大优势。得益于政策加持和应用驱动,国产AI芯片在这两年取得长足进步,但在整体性能和生态构建方面仍存在一定差距。构建一个基于国产生态体系、技术领先的超万卡集群仍面临诸多挑战。
随着大模型从千亿参数的自然语言模型向万亿参数的多模态模型升级演进,超万卡集群亟需全面提升底层计算能力。具体而言,包括增强单芯片能力、提升超节点计算能力、基于DPU实现多计算能力融合以及追求极致算力能效比,具体参阅文章“超万卡训练集群互联关键技术”。
1、超万卡集群核心设计原则
在大算力结合大数据生成大模型的发展路径下,超万卡集群的搭建不是简简单单的算力堆叠,要让数万张GPU卡像一台“超级计算机”一样高效运转,超万卡集群的总体设计应遵循以下五大原则:
●坚持打造极致集群算力:基于Scale-up互联打造单节点算力峰值,基于Scale-out互联将单集群规模推高至万卡以上,两者叠加构建超万卡集群的大算力基座;
●坚持构建协同调优系统:依托超大规模的算力集群,通过DP/PP/TP/EP等各种分布式并行训练策略,持续提升有效算力,实现极致的计算通信比,最大化模型开发效率;
●坚持实现长稳可靠训练:具备自动检测和修复软硬件故障的能力,面向千万器件满负荷运行系统,持续提升MTBF和降低MTTR并实现自动断点续训能力,支持千亿稠密、万亿稀疏大模型百天长稳训练,保证系统稳定性和鲁棒性;
●坚持提供灵活算力供给:支持集群算力调度,提供灵活弹性的算力供给和隔离手段,实现训练和推理资源的按需调配,保持单集群大作业和多租户多任务并行训练性能持平;
●坚持推进绿色低碳发展:持续推进全套液冷解决方案在超万卡集群的应用,追求极致绿色算力能效比(FLOPs/W)和极低液冷PUE至1.10以下。
2、超万卡集群整体架构设计
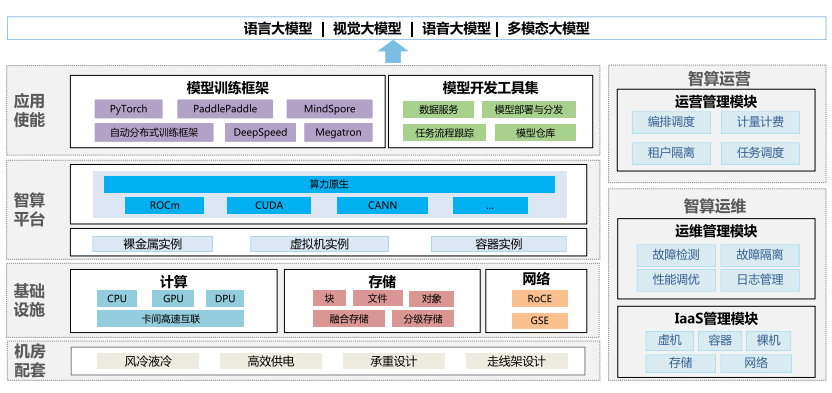
超万卡集群的总体架构由四层一域构成(如图1),四层分别是机房配套、基础设施、智算平台和应用使能,一域是智算运营和运维域。
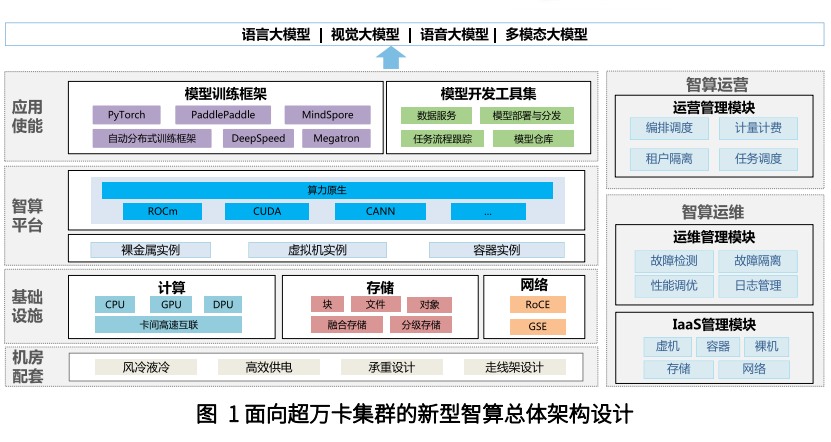
●机房配套层:匹配超万卡集群高密集约的建设模式,机房配套设施需重点考虑高效供电、制冷设计、楼板承重和走线架设计等。
●基础设施层:算、网、存三大硬件资源有机配合,达成集群算力最优。面向算力,CPU、GPU、DPU三大芯片协同,最大化发挥集群计算能力;面向网络,参数面、数据面、业务面、管理面独立组网,参数面/数据面采用大带宽RoCE交换和二层无阻塞CLOS组网满足大象流,支持参数面负载均衡和多租安全隔离;面向存储,引入融合存储和分级存储支持无阻塞数据并发访问。
●智算平台层:采用K8s,对上提供以裸金属和容器为主的集群资源。在对集群资源进行纳管的基础上,进一步实现大规模集群的自动化精准故障管理,以达成高效训练、长稳运行的目标。面向未来,考虑集群中引入异厂家GPU芯片,为避免智算碎片化问题,引入算力原生,实现应用跨架构迁移和异构混训等平台能力。
●应用使能层:包括模型训练框架和开发工具集两个模块,一方面基于现有开源框架能力,进行分布式训练调优,面向未来开展自动分布式训练框架设计,积累经验,实现对通信和计算重叠的优化、算子融合以及网络性能的高效调优;另一方面,研发沉淀数据服务、模型部署开发等工具集,逐步实现由人工处理到基于工具对外提供自动化模型研发能力的转变。
●智算运营和运维域:支持超万卡集群高效集合通信和调度。支持按租户灵活资源发放和任务调度,支持多任务并行训练。
《70+篇半导体行业“研究框架”合集》
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


