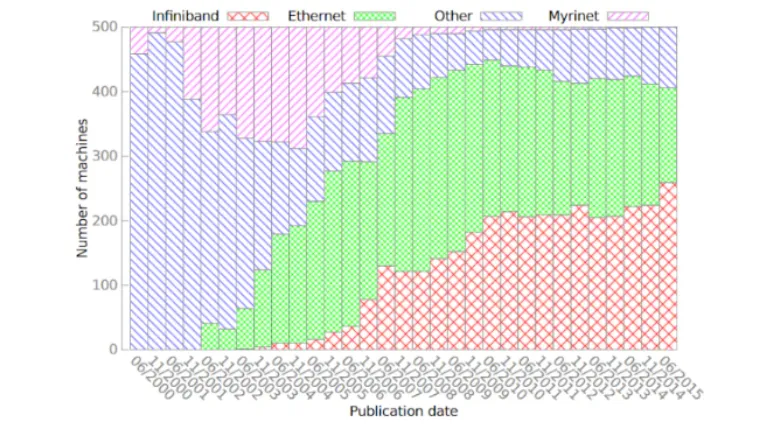
在高性能计算(HPC)系统的发展初期,通常选择专业网络解决方案,如Myrinet、Quadrics和InfiniBand,而不是以太网解决方案。通过定制网络方案可以有效解决以太网解决方案的限制,增强带宽、降低延迟、改善拥塞控制。2010年,IBTA推出了RoCE协议技术标准,随后于2014年发布了RoCEv2协议技术标准,大幅提升网络带宽。以太网性能的显著提升引起行业对与传统以太网兼容的高性能网络解决方案的日益关注。这种转变打破了以太网在排名前500的HPC集群中使用率下降的趋势,使以太网在排名中保持了重要地位。
新型智算中心改造:网络成大模型训练瓶颈,节点内外多方案并存量子计算:打破传统范式,通用计算应用可期
面向超万卡集群的新型智算技术白皮书(2024)
《NVIDIA BlueField系列合集》
1、NVIDIA BlueField:BlueField产品更新介绍
2、NVIDIA BlueField:BlueField硬件系统介绍3、NVIDIA BlueField:BlueField DPU NVQual Overview1、面向办公自动化领域的 AI Agent 建设思考与分享 3、LLM和Multi-Agent在运维领域的实验探索5、大规模工程及领域架构治理与服务架构合理性的度量1、MoonBit 月兔:大语言模型时代的软件开发起点 2、AI 大模型技术在数据库 DevOps 的实践 1、超大规模多模态预训练模型M6的关键技术突破及产业应用 量子科技专题系列一:逐梦量子,星辰大海(2024)5、2024大模型驱动的汽车行业群体智能技术白皮书 2024洞悉AI人群新范式:AI机会人群社媒研究报告暨人群工厂系列白皮书2024中国空间计算行业概览:空间计算先行,软硬件内容生态共振(摘要版)企业竞争图谱:2024年AIPC(人工智能个人电脑)
尽管Myrinet和Quadrics逐渐退出了应用方案选择之列,InfiniBand仍然在高性能网络中占据着重要的地位。此外Cray、天河和Tofulseries等专用网络系列也发挥着重要作用。
RoCE协议简介
RoCE协议是一种集群网络通信协议,它实现在以太网上进行远程直接内存访问(RDMA)。作为TCP/IP协议的特色功能,该协议将数据包的发射/接收任务转移到网络适配器上,改变了系统进入内核模式的需求。因此它减少与复制、封装和解封装相关的开销,很大程度上降低了以太网通信的延迟。此外它在通信过程中充分利用CPU资源,减轻了网络拥塞,并提高了带宽的有效利用率。RoCE协议包括两个版本:RoCE v1和RoCE v2。RoCE v1作为链路层协议运行,要求通信双方在相同的第2层网络中。相比之下RoCE v2作为网络层协议运行,使得RoCE v2协议数据包可以在第3层进行路由,提供了更好的可扩展性。RoCE V1协议
RoCE协议保留了InfiniBand(IB)的接口、传输层和网络层,但将IB的链路层和物理层替换为以太网的链路层和网络层。在RoCE数据包的链路层数据帧中,以太网类型字段的值由IEEE指定为0x8915,明确标识其为RoCE数据包。然而,由于RoCE协议没有采用以太网的网络层,RoCE数据包缺少IP字段。因此对于RoCE数据包来说,在网络层进行路由是不可行的,限制了它们在第2层网络内的传输。RoCE V2协议
RoCE v2协议在RoCE协议的基础上持续优化。RoCEv2通过融合以太网网络层和使用UDP协议的传输层,改造了RoCE协议所使用的InfiniBand(IB)网络层。它利用以太网网络层中IP数据报的DSCP和ECN字段来实现拥塞控制。这使得RoCE v2协议数据包可以进行路由,确保了更好的可扩展性。由于RoCEv2完全取代了原始的RoCE协议,通常提到RoCE协议时指的是RoCE v2协议,除非明确指定为RoCE的第一代协议。无丢包网络和RoCE拥塞控制机制
在基于RoCE协议网络中,确保RoCE流量的无缝传输至关重要。在RDMA通信过程中,数据包必须无丢失且按正确顺序到达目的地。任何数据包丢失或乱序到达的情况都需要进行“回退N”的重传操作,并且预期到达的后续数据包不应存储在缓存中。RoCE协议实现了一个双重拥塞控制机制:初始阶段利用DCQCN进行逐步减速,然后利用PFC进入传输暂停阶段。尽管严格将其划分为拥塞控制策略和流量控制策略,但通常被认为是拥塞控制的两个阶段。在网络中涉及多对一通信的应用场景中,经常会出现拥塞问题,表现为交换机端口上待发送缓冲区消息总大小的迅速增加。在无控制的情况下,可能导致缓冲区饱和,从而导致数据包丢失。因此在初始阶段,当交换机检测到端口上待发送缓冲区消息的总大小达到特定阈值时,它会标记RoCE数据包的IP层中的ECN字段。收到这个数据包后,如果接收方观察到交换机标记的ECN字段,它会向发射方发送一个拥塞通知数据包(CNP),促使发射方降低发送速率。在达到ECN字段阈值时,并不是所有的数据包都会被标记。在这个过程中,两个参数Kmin和Kmax起着重要作用。当拥塞队列长度低于Kmin时,不会进行标记。当队列长度在Kmin和Kmax之间变化时,随着队列长度的增加,标记的概率也会增加。如果队列长度超过Kmax,所有的数据包都会被标记。接收方并不会为每个接收到的带有ECN标记的数据包发送一个CNP数据包,而是在每个时间间隔内接收到带有ECN标记的数据包后,发送一个CNP数据包。通过这种方式,发送方可以根据接收到的CNP数据包数量来调整发送速度,从而避免过多的数据包被标记和丢失。这种动态的拥塞控制机制可以提供更有效的流量调节和更可靠的数据传输。
在网络拥塞恶化的情况下,当交换机检测到特定端口的待发送队列长度达到更高的阈值时,交换机会向消息的上游发送方发送一个PFC帧。这个操作会导致数据传输暂停,直到交换机中的拥塞得到缓解。一旦拥塞得到缓解,交换机会向上游发送方发送一个PFC控制帧,表示发送可以恢复。PFC流控支持在不同的流量通道上进行暂停,可以调整每个通道相对于总带宽的带宽比例。这种配置允许在一个通道上暂停流量传输,而不影响其他通道上的数据传输。ROCE & Soft-RoCE
在高性能以太网网卡领域,虽然现在大多数采用RoCE协议,但仍有在特定情况下某些网卡不支持RoCE。为了填补这一空白,IBIV、迈络思(Mellanox)和其品牌的合作,催生了开源项目Soft-RoCE。这个项目适用于设备不支持RoCE协议的节点,使它们能够与设备RoCE支持的节点一起使用Soft-RoCE进行通信,如图所示,尽管可能不会提升前者的性能,但它可以使后者充分发挥其性能优势。尤其是在数据中心等应用场景中,将升级限制在具有RoCE支持的以太网卡的高I/O存储服务器上,可以显著提高整体性能和可扩展性。此外RoCE和Soft-RoCE的组合适应了逐步集群升级的需求,避免了同时进行全面升级的必要性。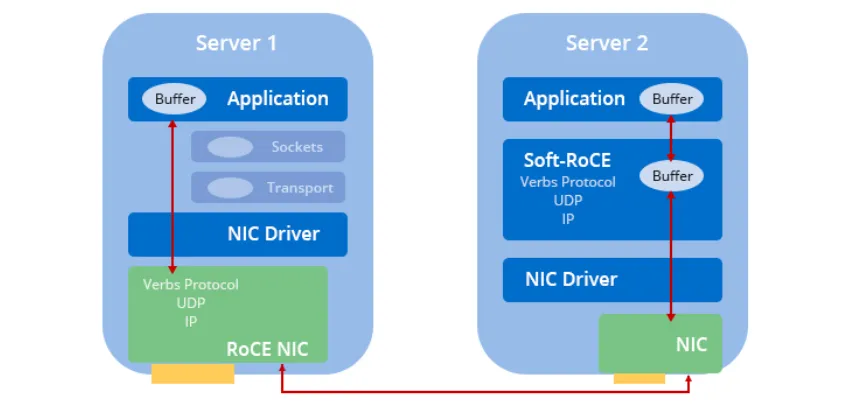
高性能计算(HPC)环境中实施RoCE时面临挑战
高性能计算(HPC)网络的基本要求
高性能计算(HPC)网络依赖于两个基本前提:低延迟和在动态流量模式下保持低延迟的功能。对于低延迟,RoCE被设计用于解决这个问题。RoCE可有效地将网络操作卸载到网卡上,从而实现低延迟和降低CPU利用率。对于在动态流量模式下保持低延迟,主要关注重心转移到了拥塞控制上。高度动态的HPC流量模式的复杂性对RoCE构成了挑战,在这方面导致了性能不佳。ROCE的低延迟
与传统的TCP/IP网络相比,InfiniBand和RoCEv2都绕过内核协议栈,从而很大程度上提高了延迟性能。实证测试表明,绕过内核协议栈可以将同一集群内应用层的端到端延迟从 50μs(TCP/IP)降低到5μs(RoCE)甚至2μs(InfiniBand)的水平。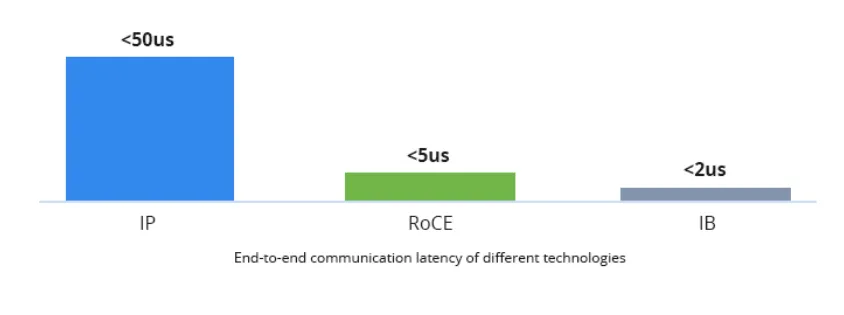
RoCE数据包结构
假设我们要使用RoCE发送1字节的数据,封装这个1字节数据包的额外开销如下:以太网链路层:14字节MAC头 + 4字节CRC 以太网IP层:20字节 以太网UDP层:8字节 IB传输层:12字节基本传输报头(BTH) 总计:58字节 假设我们要使用IB发送1字节的数据,封装这个1字节数据包的额外开销如下:IB链路层:8字节本地路由头(LHR)+ 6字节CRC IB网络层:0字节(当只有2层网络时,链路层的链路下一头部(LNH)字段可以表示该数据包没有网络层) IB传输层:12字节基本传输报头(BTH) 总计:26字节如果是自定义网络,数据包结构可以进一步简化。例如,天河-1A的迷你数据包(MP)头部由8字节组成。由此可见,以太网底层结构的复杂性是将RoCE应用于HPC的障碍之一。数据中心的以太网交换机通常需要具备如SDN、QoS等其他功能,这些功能的实现需要额外的成本。关于这些以太网功能,以太网和RoCE是否与这些功能兼容?同时这些功能是否会影响RoCE的性能?RoCE拥塞控制面临的挑战
RoCE协议的两个方面中的拥塞控制机制都面临着特定的挑战,这些挑战可能会妨碍在动态流量模式下保持低延迟。优先级流量控制(PFC)依赖于暂停控制帧来防止接收过多的数据包,这种策略容易导致数据包丢失。与基于信用的方法不同,PFC往往导致较低的缓冲区利用率,对于具有有限缓冲区的交换机来说尤为具有挑战性,通常与较低的延迟相关。相反,基于信用的方法提供了更精确的缓冲区管理。RoCE中的数据中心量化拥塞通知(DCQCN),类似于InfiniBand的拥塞控制,采用了反向通知的方式,将拥塞信息传递给目的地,然后返回给发射方进行速率限制。RoCE遵循一组固定的减速和加速策略公式,而InfiniBand允许自定义策略,提供更大的灵活性。虽然通常使用默认配置,但有自定义选项是更适用。测试中最多每N=50μs生成一个拥塞通知包(CNP),将这个值降低的可行性尚不确定。在InfiniBand中,CCTI_Timer的最低设置可以达到1.024μs,但实际实现这样小的值尚未确定。从拥塞点直接将拥塞信息返回给源端,这被称为前向通知。虽然可以根据以太网规范了解其限制,但关于InfiniBand未采用这种方法的具体原因,仍存在疑问。RoCE在高性能计算(HPC)中的应用
美国最新的超级计算机采用Slingshot网络,这是一种增强版的以太网。该网络利用与传统以太网兼容的Rosetta交换机,解决了RoCE的特定限制。当链路的两端支持专用设备(如网卡和Rosetta交换机)时,可以实现网络增强。这些功能包括将IP数据包帧大小最小化为32字节,与相邻交换机共享队列占用信息,并实施改进的拥塞控制。虽然平均交换机延迟为350ns,相当于高性能以太网交换机,但低于InfiniBand(IB)和一些专用超级计算机的交换机实现的延迟,如的Cray XC超级计算机交换机。在实际应用中,Slingshot网络表现出可靠的性能。《Slingshot互连的深入分析》一文中主要将其与之前的Cray超级计算机进行了比较,而没有与InfiniBand进行直接比较。此外CESM和GROMACS应用程序通过使用低延迟的25G以太网和带宽更高的100G以太网进行测试。尽管这两种网络之间的带宽差异达到了四倍,但测试结果为它们的性能进行了有价值的比较。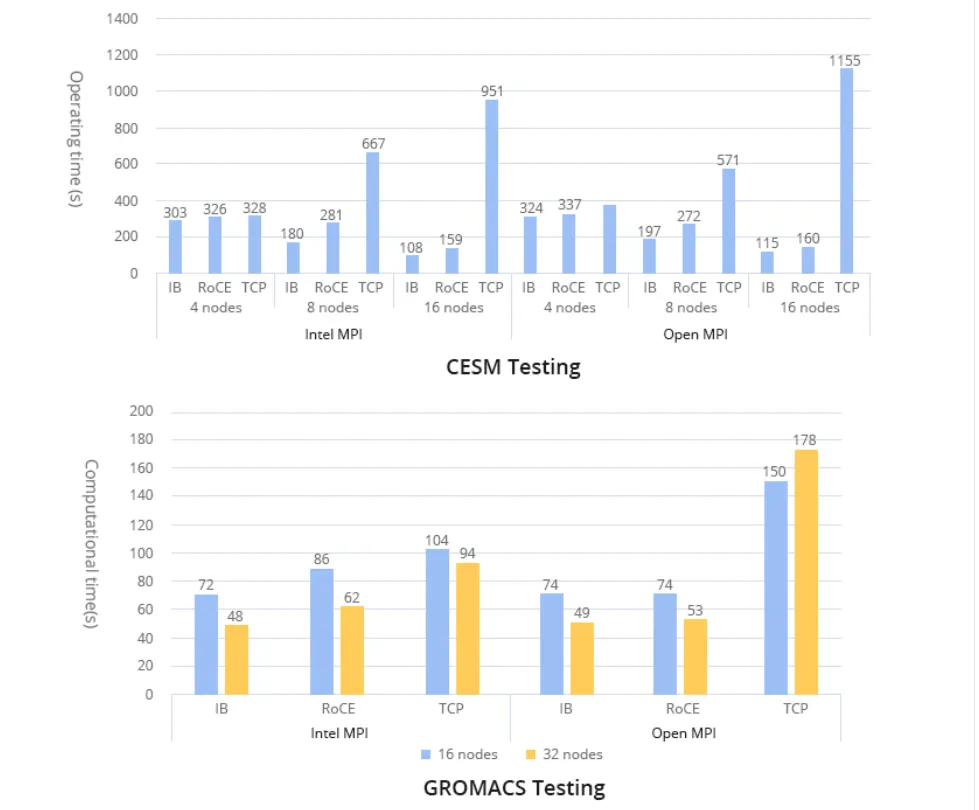
结论
凭借专业的技术团队,飞速(FS)在各种应用场景中赢得了客户的信赖。然而飞速(FS)在高性能计算(HPC)的RoCE技术应用中存在一定的挑战:
- 与InfiniBand交换机和某些定制的高性能计算网络交换机相比,以太网交换机的延迟较高。
随着人工智能数据中心网络的高速发展,选择合适的解决方案至关重要。传统的TCP/IP协议已不再适用于对高网络性能要求较高的人工智能应用。RDMA技术,特别是InfiniBand和RoCE应用,已成为备受推崇的网络解决方案。InfiniBand在高性能计算和大规模GPU集群等领域展示出了卓越的性能。相比之下,作为基于以太网的RDMA技术,RoCE提供了增强的部署灵活性。相关阅读:
初识RDMA网络传输技术
InfiniBand,撼动不了以太网?
英伟达Quantum-2 Infiniband平台技术A&Q
一颗Jericho3-AI芯片,用来替代InfiniBand?
RoCE技术在HPC中的应用分析
GPU集群:NVLink、InfiniBand、ROCE、DDC技术分析
InfiniBand高性能网络设计概述
一文了解InfiniBand和RoCE网络技术
关于InfiniBand和RDMA网络配置实践
InfiniBand与RoCE对比分析:AI数据中心网络选择指南
14份半导体“AI的iPhone时刻”深度系列报告合集
12份走进“芯”时代系列深度报告合集
《70+篇半导体行业“研究框架”合集》
《42份智能网卡和DPU合集》
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。






