大侠好,欢迎来到FPGA技术江湖,江湖偌大,相见即是缘分。大侠可以关注FPGA技术江湖,在“闯荡江湖”、"行侠仗义"栏里获取其他感兴趣的资源,或者一起煮酒言欢。“煮酒言欢”进入IC技术圈,这里有近100个IC技术公众号。



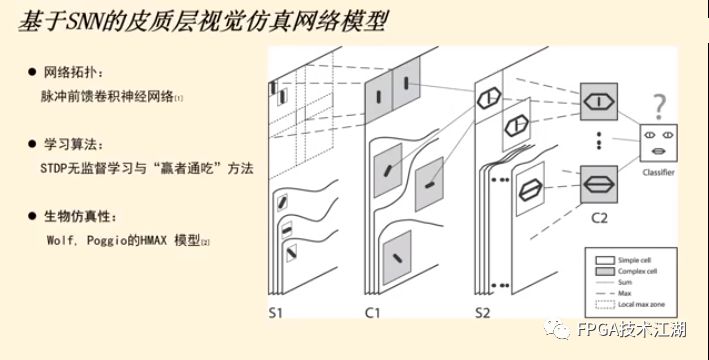
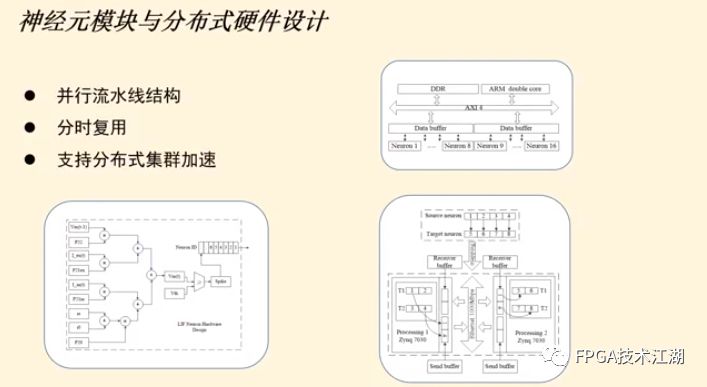
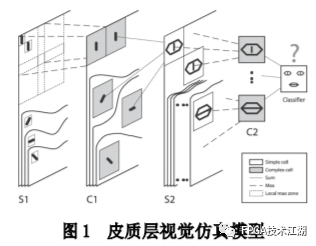
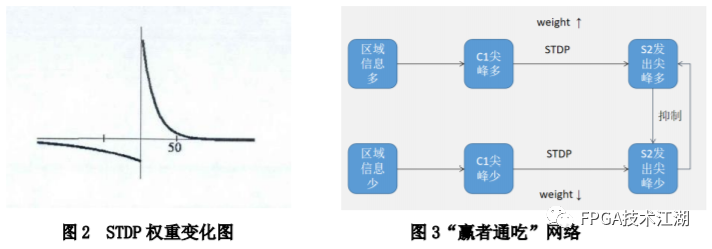
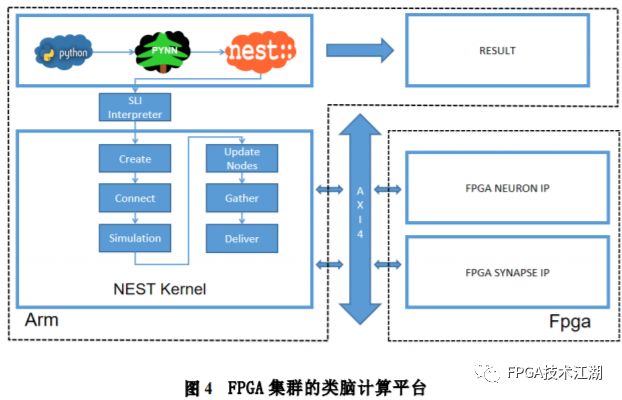
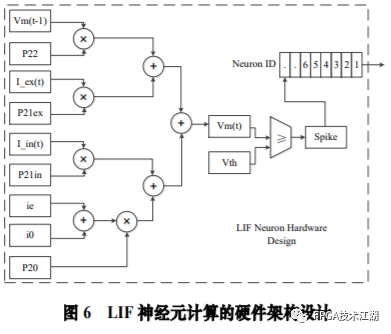
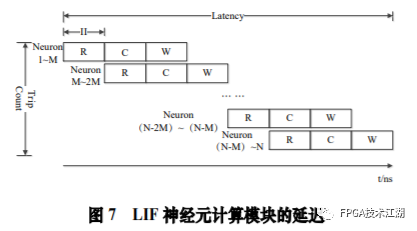
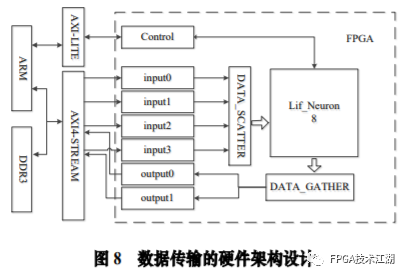
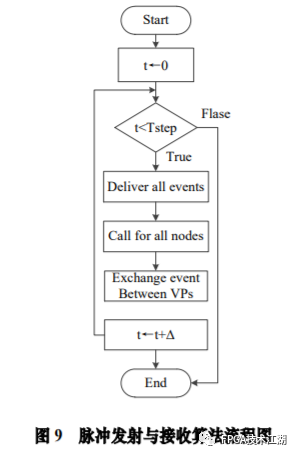
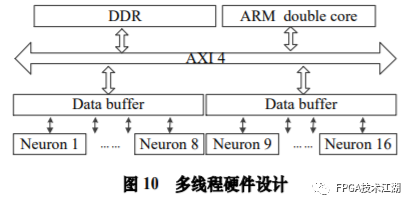
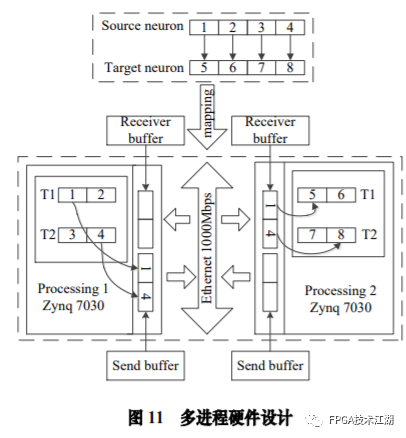
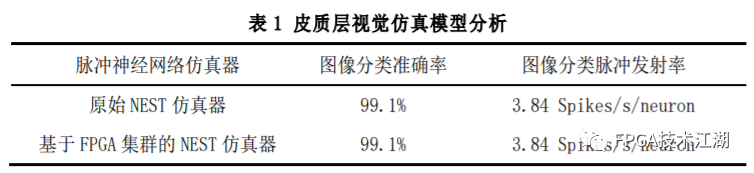
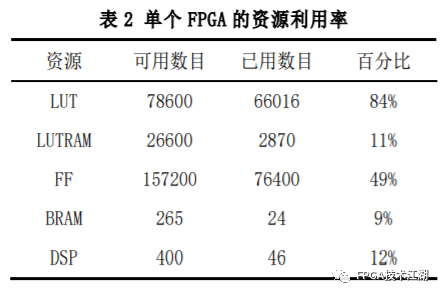
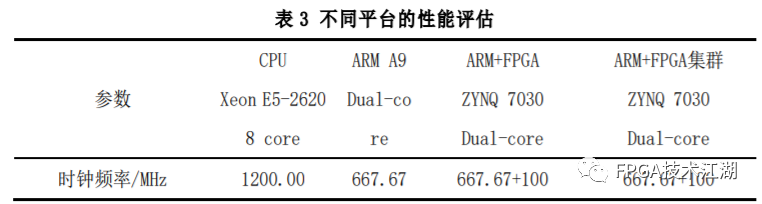
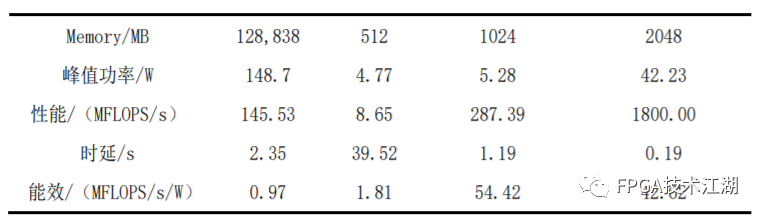
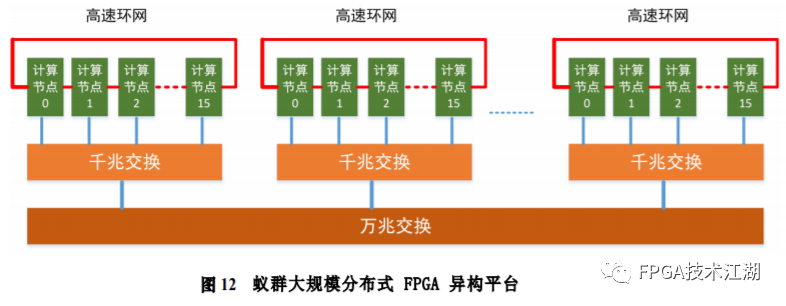
基金项目:国家自然科学基金“基于工作负载表征的类脑体系结构基准测试模型与自动映射方法研究”(61972180);数学工程与先进计算国家重点实验室开放基金(2017A08、2018A04)。* 通过基于 SNN 的类脑计算方式更好地解决无监督的图像识别问题* 通过软硬件协同的方式更好地探索大规模、低功耗类脑系统的设计空间* 通过开源开放推动更多人开展基于 FPGA 的类脑体系结构研究与学习,目前已开放至 Github。该目标图像识别基于脉冲前馈卷积网络,运用 STDP 无监督学习算法,可运用于图像的 无监督分类。(1)本设计搭建的基于 PYNQ 集群的通用低功耗的大规模类脑计算平台,搭载 PYNN,NEST 等通用 SNN 模拟器,可为 SNN 算法开发者和神经学家提供理想满意的类脑仿真实验平台。(2)本设计提供的基于 NEST 仿真器的 FPGA 集群的硬件加速服务可以为实验环境不理 想,应用计算复杂周期长的用户带来显著的速度提升。(3)本设计也为对应用进行计算密集点的分析、SNN 工作负载分析以及对主要计算密集 点进行 FPGA 加速等课题相关议题提供理论基础。(1)本应用基于脉冲前馈卷积网络,运用 STDP 无监督学习算法,相较于 CNN 等传统神经网络,更具有生物真实性,事件触发型的权重更新模式使计算需求降低,能耗减少。(2)利用 SNN 仿真器能够大规模分布式计算的特性,搭建出基于 PYNQ 集群的通用低功耗的大规模类脑计算平台,并通过皮质层视觉仿真模型、HPC Benchmark 等进行了结果验证和性能测试。(3)本设计设计的基于 NEST 仿真器的 FPGA 集群的硬件加速器,通过并行流水线结构实现 8 个神经元同时计算并采用分时复用 8 个神经元实现任意规模的脉冲神经网络的加速,并 使用 FPGA 实现 STDP 学习算法使得集群支持片上学习系统。提供的加速服务在保证应用仿真 结果精确的同时,支持多节点多线程的仿真模式,大大了缩短仿真的时间,提高了整个系 统的能效比。该 SNN 应用用于测试一次性物体外观学习,基于一个或很少的训练实例学习新的对象特征。该基准使用 PyNN 独立仿真语言编写并且编写内核使用 NEST 库。如图 1 所示,该网络由 5 层尖峰神经元组成。前 4 个是交替的简单和复杂的单元层(S1, C1,S2,C2),第 5 个是分类器(例如 SVM)。使用 Spike-Timing-Dependent Plasticity (STDP)在 C1-S2 层之间进行对象特征的学习。该网络架构属于麻省理工学院 Riesenhuber &Poggio 提出的 HMAX 模型中的一种,HMAX 模型是从哺乳动物脑部视觉处理的生理性提 取出来。2.1.2 STDP 无监督学习算法和“赢者通吃”网络STDP 和抑制连接相互配合能有很好的找出赢家的效果。首先,STDP 通过突触两端的神 经元激发时间顺序来调整突触权重,如图 2 所示,横坐标表示突触后神经元脉冲发送时间 和突触前神经元脉冲发放时间差∆t,纵坐标表示突出权重变化量。在∆t>0 时,呈增长状态, 称之为 LTP(Long-term potentiation),随着时间的增加,增长量趋于 0。在∆t<0 时,呈 减少状态,称之为 LTD(Long-term depression),时间差越大则减少量越大[5]。其次,在 STDP 与抑制连接配合[6]后,具体效果如图 3 所示,上端的激发多的 C1 神经元 会比下端的激发少的 C1 神经元更容易刺激相应 S2 神经元激发,因为上端激发的 S2 神经元 会根据连接发出抑制权重,则下端的 S2 神经元会很难激发。至此,STDP 的作用体现出来 了,由于作为目标神经元下端的 S2 神经元很难激发,则下端 C1 神经元和 S2 神经元连接权 重根据 STDP 规则会下降,而与此相反,由于作为目标神经元下端的 S2 神经元经常激发, 上端的 C1-S2 连接权重根据 STDP 规则会上升。长此以往,上端 C1 神经元不仅在激发频率 高于下端 C1 神经元,而且在权重值上也高于下端 C1 神经元,这样的结果就是下端 S2 神经 元开始“黯淡”,上端 S2 神经元赢得竞争的胜利。从整体架构上看,图片信息越多的区域 对应的 S2 神经元更有可能赢得竞争胜利。在训练仿真结束后,S2 中赢得竞争胜利的神经元最具特征,将 C1 中与其连接 36 个 STDP 突触权重作为训练好的特征权重。本系统由包含 PYNN 类脑框架、NEST 仿真器、PYNQ 框架以及 FPGA 神经元和 STDP 硬件模块。如图 4 所示,顶层应用设计语言为 Python,在 PYNN 架构协助下调用 NEST 仿真器, 各种命令通过 python interpreter 和 SLI interpreter 解释后,进入 NEST kernel。根据各种命令进行底层网络创建包括神经元创建、突触连接创建、仿真时间设置等。在此基础上,本组设计了 FPGA 神经元加速模块和 FPGA STDP 突触加速模块,根据不网络拓扑和计算要求,提供不同计算密集点提供加速模块。如图 5 所示,本课题的通用平台集成 16 块 PYNQ 板,板级连接遵循 TCP/IP 协议。PYNQ-Z2 开发板以 ZYNQ XC7Z020 FPGA 为核心,配备有以太网,HDMI 输入/输出,MIC 输入,音频 输出,Arduino 接口,树莓派接口,2 个 Pmod,用户 LED,按钮和开关。NEST 作为一款非常流行的类脑模拟器开源软件,应用广泛。NEST 一大优势是可用于模 拟任何规模的脉冲神经网络,如可模拟哺乳动物的视觉或听觉皮层这样的信息处理模型。也可模拟网络活动的动力学模型,比如层状皮质网络或平衡随机网络以及学习和可塑性模 型。同时 NEST 的另一大优势就是支持集成式的 MPI、OpenMP 通讯协议,可以进行分布式计 算大大提高仿真速度。如图 4 所示,NEST 的主体结构分为创建模型、连接模型,模拟仿真。仿真模块分为突 触传递、更新神经元、MPI 传输。针对对应用计算密集点分析,本设计主要是对于更新神 经元模块进行加速。LIF神经元计算模块采用流水线设计来提高吞吐率,如图7所示,由神经元输入缓冲经过一系列 乘加运算得到当前的神经元膜电位,如果膜电位大于阈值则会输出结果到神经元输出缓冲,输出的脉冲携带神经元的id(Identity),将发出脉冲的神经元id存储到共享内存,并按照输出顺序排列在一段连续的内存空间,设置结束标志位为0,直到读取到0,则说明本轮神经元更新所发射的脉冲读取完毕。单个神经元计算模块存在4个乘法并行单元,以及2个加法并行单元,充分利用了神经元计算模块内的并行性。神经元流水线结构如图 7 所示,其分为数据读取 R,神经元计算 C,数据写回三个模块 W。LIF 神经元硬件架构数据流和控制流如图 8 所示:NEST仿真器运行在ARM核,通过AXI-LITE控制LIF_NEURON神经元计算模块,并将神经元总数量 通过寄存器输出到LIF_NEURON硬件模块。AXI-STREAM协议由四个DMA控制器实现,通过 AXI-STREAM将神经元变量参数写入到输入缓冲,通过DATA_SCATTER模块分发到LIF神经元中各个 变量,LIF_NEURON神经元更新完成后,通过DATA_GATHER模块写回到输出缓冲。本文采用8个LIF神 经元并行计算,并通过分时复用的方式读取和更新共享内存中的数据。其中,AXI-STREAM的最大数据位宽为1024bit,ZYNQ7030的DDR3 1066f支持2.01GB/s的数据带宽, LIF神经元计算模块最大带宽需求为1.175GB/s,即满足设计的要求。2.5.2 支持 FPGA 集群的 NEST 仿真器多节点设计为了便于大规模的脉冲神经网络仿真,NEST仿真器本身支持OpenMP(Open Multi-Processing) 的共享内存多线程技术与MPI(Message Passing Interface)的分布式内存多进程技术,可适应不 同的集群平台。本设计在NEST仿真器中加入了支持LIF神经元多线程硬件模块。并通过以太网的通 信方式实现支持FPGA集群的设计。NEST仿真器中在脉冲神经网络仿真之前建立网络的连接。神经元通过平均分配的原则分配到各 个进程中的线程,并赋予每个神经元全局id、线程id及进程id,随后根据NEST仿真器中的查找表建 立突触,通过突触建立各个进程和线程之间的连接关系,进程中使用MPI消息机制进行神经元之间 的脉冲消息传递,每个突触连接包含权重、延迟、目标神经元全局id。目标神经元用来查找目标节点,延迟用来定义从源神经元到目标神经元需要的仿真步长。NEST仿真器中会给每个线程分配接收buffer和发送buffer,接收buffer负责接收所有传入的脉冲信息,发送buffer负责存放发射脉冲的信息,每个线程都会存在同样大小和同样数据的接收 buffer,并通过本线程的id从接收buffer取相应的脉冲事件数据,然后通过突触连接找到对应的神经元进行脉冲的传递。而MPI的信息交换机制是将进程中的发送buffer拷贝并发送到其他所有接收进程,NEST仿真器中网络的脉冲发射与接收设计流程图如图9所示。其中 t 为仿真步长,Deliver all events 为将所有的脉冲事件从本线程的接收 buffer 中取出,并根据全局 id 发射到相应的神经元,Call for all nodes 是更新计算所有的节 点,Exchange event between VPs 是通过 MPI 技术将发送 buffer 的数据进行交换。由于 ZYNQ7030 的 PS(Process System)端为 ARM A9 双核处理器,且支持双线程运行, 所以本文设计了 2 个 LIF 神经元硬件模块。由 ARM 端的每个线程分别控制 1 个 LIF 神经元 硬件模块,如图 10 所示。多线程采用共享内存的方式,使用 2 个 LIF 神经元硬件模块同时读写 DDR3 内存,可充分发挥 DDR 的带宽优势,但由于线程之间的存在上下文的切换,多线程的加速比并不能达到理论的最大值。如图 11 所示,多进程采用分布式内存的方式,每个进程包含发送缓冲和接受缓冲,在脉冲神经网路仿真开始前将网络拓扑结构映射到 NEST 仿真器,为每个线程和进程分配神经元,发出的脉冲信号通过以太网从发送缓冲发送到接受缓冲。每个进程节点配备单独的 DDR3 内存,可增加整个系统的内存容量,并提供更高的计算性能,但同时也需要考虑多节点的 通信问题。1.NEST仿真器:NEST 2.14.0版本,GCC 5.0编译器,Python3.5。2.皮质层视觉仿真模型:最小延迟 min d 为1ms,仿真精度为0.1ms,总生物仿真时间为50ms,神 经元数量为48904,突触数量为275456。3.FPGA设计软件:Xilinx Vivado 2018(Xilinx FPGA设计集成工具)、Xilinx Vivado HLS 2018 (高层次综合工具)。4.CPU:Inter Xenon E5-2620,八个核心,其内存为128GB DDR3。5.ARM:ARM A9处理器主频为667MHz,2个核心,内存为1GB DDR3。6.FPGA集群系统:FPGA集群包含8个Xilinx ZYNQ 7030节点,每个节点包括PS(Process System) 端的ARM A9双核处理器系统和一个PL(可编程逻辑)端的FPGA器件。FPGA时钟频率为100MHZ。FPGA 板卡之间采用1000Mbps网络带宽的以太网进行通信,并采用TCP/IP协议。本文NEST仿真器中神经元计算模块采用单精度浮点数据精度,与原NEST仿真器的神经元计算模 块双精度浮点数据精度相比,在皮质层视觉模型仿真图像分类的准确率和脉冲发射率方面并无差别,其结果如表1所示。单个FPGA节点中2个LIF神经元硬件模块的资源利用率情况如表2所示。本文实现基于FPGA集群的脉冲神经网络仿真器NEST,以皮质层视觉模型仿真为案例,分别对比 Inter服务器版八核CPU Xenon E5-2620和ARM A9双核CPU,其时钟频率、内存、性能等,如表3所示:本文中实现的基于 FPGA 集群的 NEST 仿真器,在计算能效方面,其单个节点能效是 ARM A9 的30 倍,是 Inter Xeon E5-2620 的56.10 倍;FPGA 集群的能效是 Inter Xeon E5-2620 的43.93 倍, 是 ARM A9 的23.54 倍。在速度方面,单个节点速度是 ARM A9 的33.21 倍,是 Inter Xeon E5-2620 的1.97 倍;FPGA 集群的速度是 ARM A9 的208 倍,是 Inter Xeon E5-2620 的12.36 倍。(1)这次设计是开创了基于 NEST 仿真器进行 FPGA 集群加速的案例,为后面 SNN 工作 负载深入研究做好铺垫。针对应用,进行了 SNN 应用整体工作负载分析、计算密集点分析、 以及对主要计算密集点进行加速,以达到更好的能效比。(2)本组具有蚁群大规模类脑计算集群平台,目前可以达到一百多的计算节点的 集群。无论是从研究的深度和广度,可以帮助我们更好的进行对 SNN 工作负载的分析和加速 效果的类比。(3)无论是欧盟大规模的类脑计算平台 SpiNNaker,还是软件仿真器 NEST、NEURON 等 都支持多节点集群式仿真,以求达到更好的仿真速度。而本设计既有瞩目的能效比表现,关键又能 在集群的基础上进行加速,保证 SNN 仿真器并行优势,同时也能保证仿真结果的正确性。(1)目前在进行对 SNN 工作负载的分析时,除了计算密集点在神经元计算,还发现在 无监督式学习算法在 SNN 应用中日益火爆。这就意味着在网络拓扑复杂、神经元击发率较 高的情况下,以 STDP 主导的突触计算将成为新的计算密集点。目前已经完成在单节点单线 程上对 STDP 突触计算的加速,加速效果不错。下一步工作准备支持多节点多线程加速。(2)下一步本组希望能够做成通用的 SNN 分析器,主要能够根据不同的应用和网络拓扑,自动分析计算密集点所在和给出合理的计算节点,使应用得到最合适的计算加速比。(3)最后也希望做成通用的 SNN 加速器,根据分析的计算密集点,能够自动根据网络 拓扑大小进行相应加速。(4)专用平台:本课题提供规模更大的专用实验平台为大规模分布式 FPGA 异构平台。如图 12 所示是蚁群平台的总体架构,平台的每个模组(组装在一个机箱内)有 16 个 FPGA 异构计算节点。模组内部的计算节点除了采用千兆以太网连接之外还有板级的高速环网, 为支持灵活的 SNN 通信机制空间探索提供了硬件支撑。目前已达到一百个计算节点规模的类脑计算集群平台。于 SNN 来说,作为第三代神经网络,SNN 虽然在实际应用上使用较少,在监督学习这一 块表现目前也不如第二代人工神经网络,但是研究人员普遍认为 SNN 是解决第二代网络种 种问题的一条不错出路。并且,国内外也有越来越多的团队在解决 SNN 相关不足和实际运 用方面不懈努力,以期 SNN 能成为新一代的深度学习发展热点。于仿真加速来说,无论是通过工作负载和集群分析获得更好的加速比,还是通过 FPGA 加速以更优秀的能效比,这些也是机器学习的研究者们一直追求和不懈奋斗的。减少碳排 放,节约能源,绿色合理可持续的发展道路也是符合人类发展的大趋势。在此背景下,本作品所做的一点小小的工作,也能汇入 SNN 第三代神经网络研究工作 的洪流。对此,我们始终觉得这项工作很有意义并引以为荣。[1]https://github.com/clancylea/SNN-simulator-NEST_14.0-xilinx_FPGA_cluster[2] Marc-Oliver Gewaltig and Markus Diesmann.NEST (Neural Simulation Tool)[J].Scholarpedia, 2007,2(4):1430.[3] Masquelier, Timothée, Thorpe S J. Unsupervised Learning of Visual Features through Spike Timing Dependent Plasticity[J].PLoS Computational Biology, 2007, 3(2):e31.[4] Serre T, Wolf L, Poggio T (2005) Object recognition with features inspired by visual cortex.CVPR 2: 994–1000.[5] Song S, Miller KD, Abbott LF (2000) Competitive hebbian learning through spike-timing–dependent synaptic plasticity.Nat Neurosci 3: 919–926.[6] Thorpe SJ (1990) Spike arrival times: A highly efficient coding scheme for neural networks.In: Eckmiller R, Hartmann G, Hauske G, editors.Parallel processing in neural systems and computers.Amsterdam: Elsevier.pp. 91–94.[7] Riesenhuber M, Poggio T (1999) Hierarchical models of object recognition in cortex.Nat Neurosci 2: 1019–1025.- THE END -
🍁
【免费】FPGA工程师人才招聘平台
FPGA人才招聘,企业HR,看过来!
系统设计精选 | 基于FPGA的实时图像边缘检测系统设计(附代码)
基于原语的千兆以太网RGMII接口设计
时序分析理论和timequest使用_中文电子版
求职面试 | FPGA或IC面试题最新汇总篇
资料汇总|FPGA软件安装包、书籍、源码、技术文档…(2024.01.06更新)
FPGA就业班,05.04开班,新增课程内容不加价,高薪就业,线上线下同步!

FPGA技术江湖广发江湖帖
无广告纯净模式,给技术交流一片净土,从初学小白到行业精英业界大佬等,从军工领域到民用企业等,从通信、图像处理到人工智能等各个方向应有尽有,QQ微信双选,FPGA技术江湖打造最纯净最专业的技术交流学习平台。
FPGA技术江湖微信交流群

加群主微信,备注姓名+学校/公司+专业/岗位进群
FPGA技术江湖QQ交流群

备注姓名+学校/公司+专业/岗位进群