

本文来自“新型智算中心改造:网络成大模型训练瓶颈,节点内外多方案并存”。AI大模型训练和推理拉动智能算力需求快速增长。
a)模型迭代和数量增长拉动AI算力需求增长:从单个模型来看,模型能力持续提升依赖于更大的训练数据量和模型参数量,对应更高的算力需求;从模型的数量来看,模型种类多样化(文生图、文生视频)和各厂商自主模型的研发,均推动算力需求的增长。
b)未来AI应用爆发,推理侧算力需求快速增长:各厂商基于AI大模型开发各类AI应用,随着AI应用用户数量爆发,对应推理侧算力需求快速增长。
智算中心从集群走向超级池化。智算中心是以GPU、AI加速卡等智能算力为核心,集约化建设的新型数据中心;随着大模型普遍进入万亿规模,算力、显存、互联需求再次升级,高速互联的百卡“超级服务器”可能成为新的设备形态,智算中心将走向超级池化阶段,对设备形态、互联方案、存储、平台、散热等维度提出新的要求。
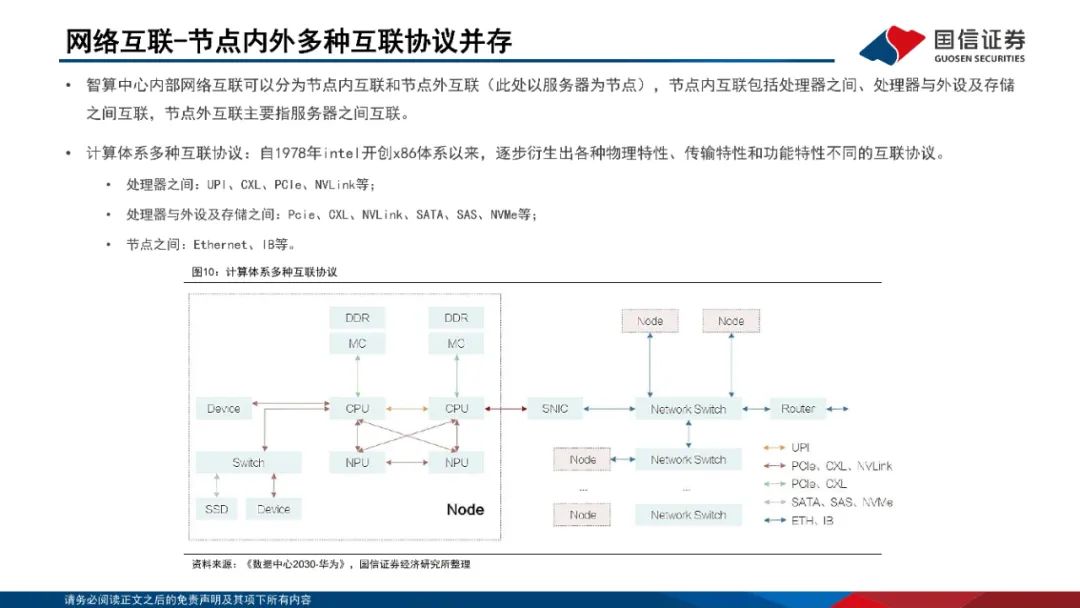
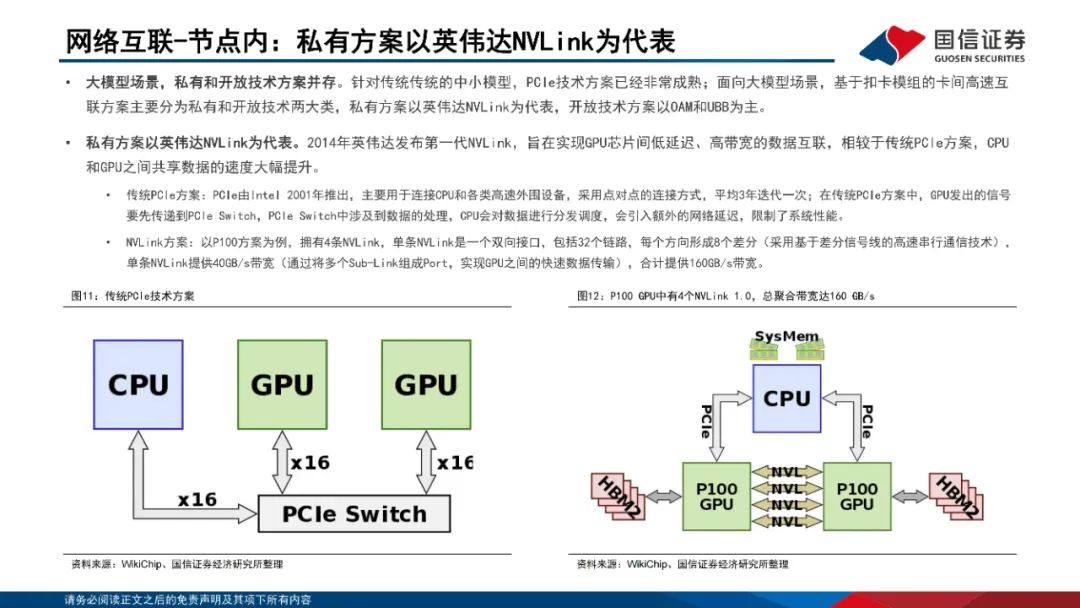
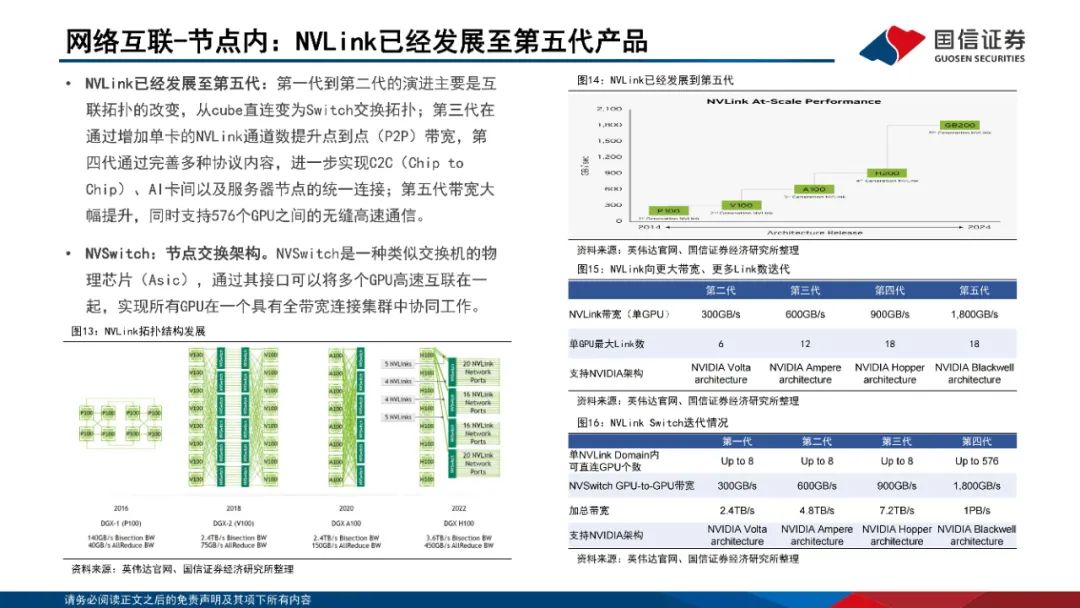
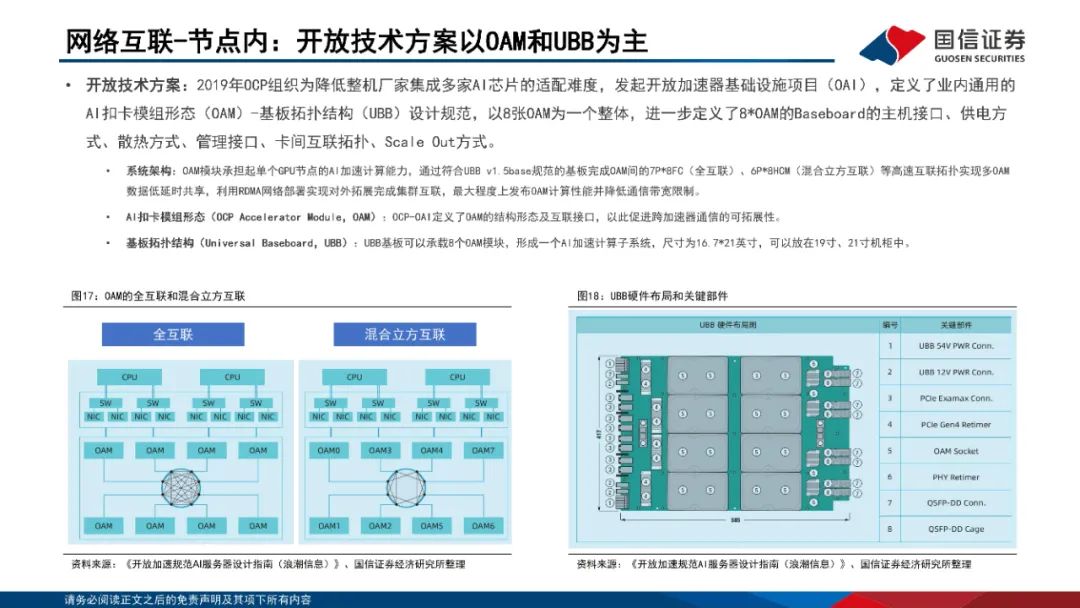
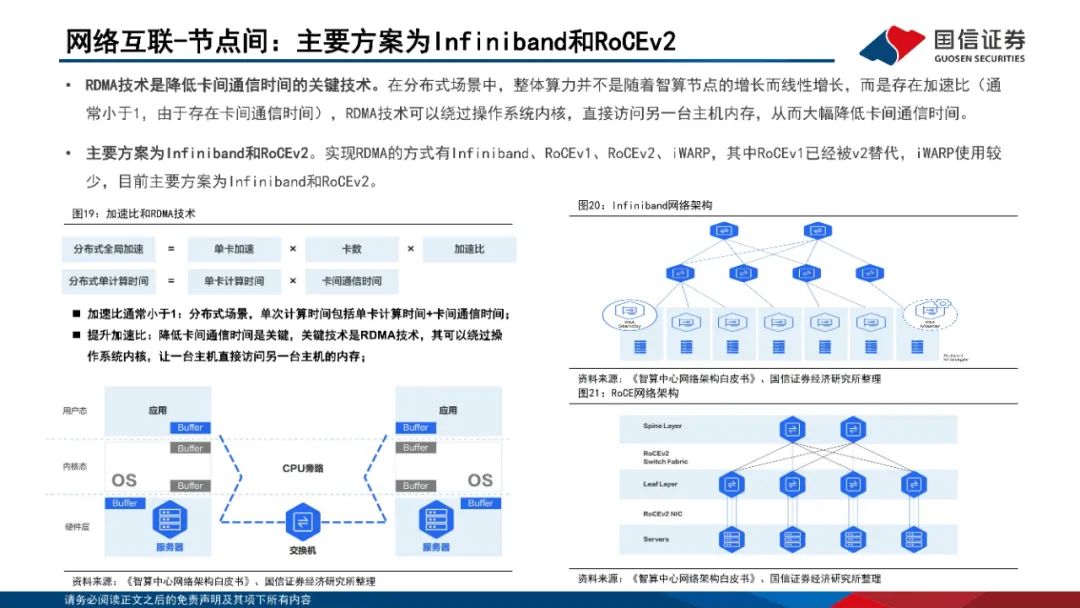
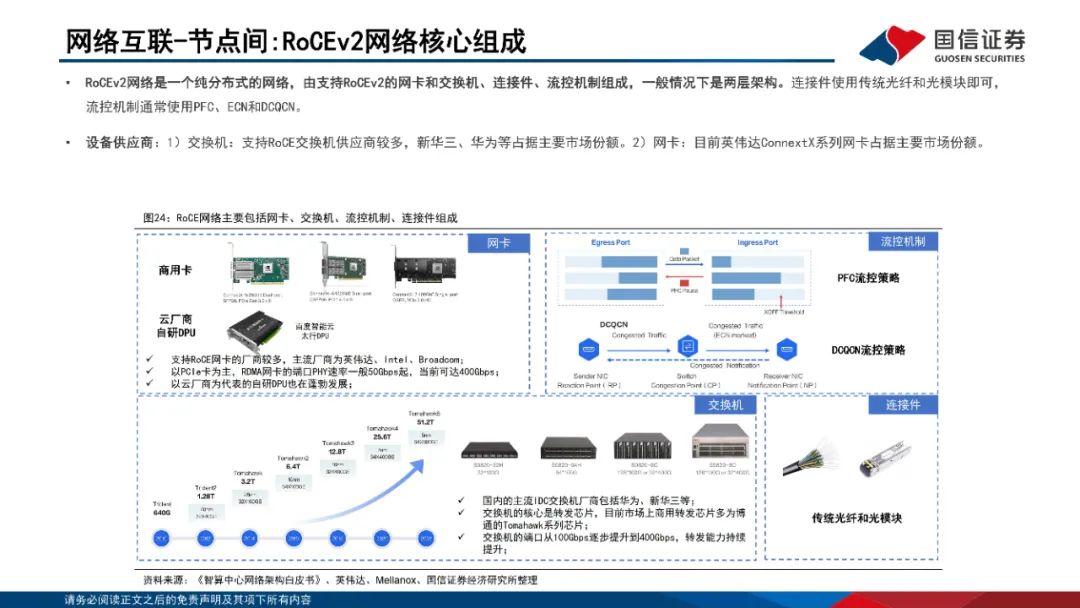
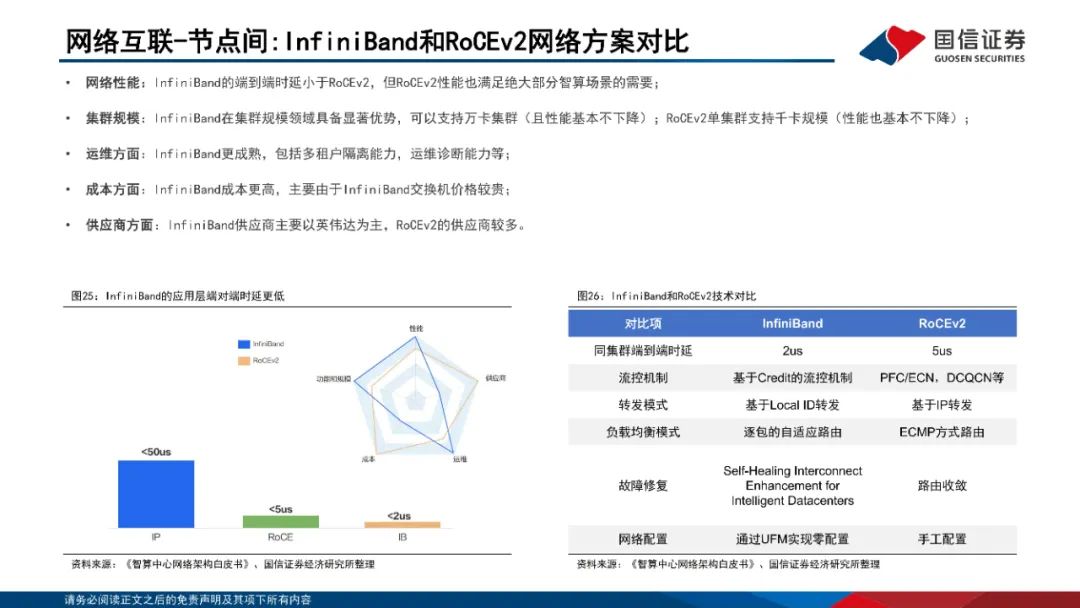
网络互联:节点内外多方案并存。1)节点内:私有方案以英伟达NVLink为代表,NVLink已经发展至第五代产品,同时支持576个GPU之间的无缝高速通信;开放技术方案以OAM和UBB为主,OCP组织定义了业内通用的AI扣卡模组形态(OAM)-基板拓扑结构(UBB)设计规范。2)节点间:主要方案为Infiniband和RoCEv2;Infiniband网络主要包括InfiniBand网卡、InfiniBand交换机、Subnet Management(SM)、连接件组成;RoCEv2网络是一个纯分布式的网络,由支持RoCEv2的网卡和交换机、连接件、流控机制组成。InfiniBand在网络性能、集群规模、运维等方面具备显著优势。
量子计算:打破传统范式,通用计算应用可期
面向超万卡集群的新型智算技术白皮书(2024)
《NVIDIA BlueField系列合集》





香山:开源高性能RISC-V处理器
AI算力研究:英伟达B200再创算力奇迹,液冷、光模块持续革新
GPU深度报告:英伟达GB200 NVL72全互联技术,铜缆方案或将成为未来趋势?
人工智能系列专题报告:CoWoS技术引领先进封装,国内OSAT有望受益
软硬件融合:从DPU到超异构计算
《大模型技术能力测评合集》
1、大模型时代,智算网络性能评测挑战
2、AIGC通用大模型产品测评篇(2023)
3、人工智能大模型工业应用准确性测评
4、甲子星空坐标系:AIGC通用大模型产品测评篇
5、AIGC通用大模型产品测评篇(2023)
6、2023年中国大模型行研能力评测
1、新型智算中心算力池化技术白皮书 2、智算中心网络架构白皮书 3、面向AI大模型的智算中心网络演进白皮书 4、智算赋能算网新应用白皮书
14份半导体“AI的iPhone时刻”深度系列报告合集
12份走进“芯”时代系列深度报告合集
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


