
InfiniBand在高性能计算(HPC)和人工智能(AI)应用中发挥着关键作用,体现在它提供了高速、低延迟的网络通信能力,以支持大规模数据传输和复杂计算任务。而InfiniBand的重要性还延伸至网络内计算领域,其在此领域的应用正在逐步扩大。通过在网络内部执行计算任务,InfiniBand进一步降低了延迟并提升了整体系统效率,有力推动了HPC和AI领域向更高性能和更强智能迈进。
AI算力研究:英伟达B200再创算力奇迹,液冷、光模块持续革新
英伟达发布新一代GPU架构,NVLink连接技术迭代升级
大模型语言模型:从理论到实践
技术展望2024:AI拐点,重塑人类潜力
英伟达GTC专题:新一代GPU、具身智能和AI应用
AI算力研究:英伟达B200再创算力奇迹,液冷、光模块持续革新
GPU深度报告:英伟达GB200 NVL72全互联技术,铜缆方案或将成为未来趋势?
人工智能系列专题报告:CoWoS技术引领先进封装,国内OSAT有望受益
软硬件融合:从DPU到超异构计算
《大模型技术能力测评合集》
1、大模型时代,智算网络性能评测挑战
2、AIGC通用大模型产品测评篇(2023)
3、人工智能大模型工业应用准确性测评
4、甲子星空坐标系:AIGC通用大模型产品测评篇
5、AIGC通用大模型产品测评篇(2023)
6、2023年中国大模型行研能力评测
1、新型智算中心算力池化技术白皮书 2、智算中心网络架构白皮书 3、面向AI大模型的智算中心网络演进白皮书 4、智算赋能算网新应用白皮书
14份半导体“AI的iPhone时刻”深度系列报告合集
12份走进“芯”时代系列深度报告合集
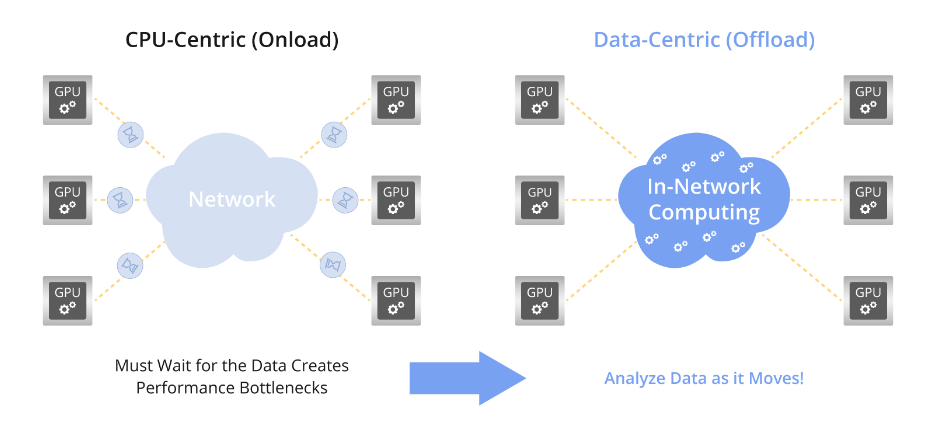
InfiniBand网络内计算(INC)是InfiniBand技术的一种延伸设计,旨在通过将计算能力引入网络来提升系统性能。在网络计算领域中,它有效地解决了AI和HPC应用中的集体通信问题以及点对点瓶颈问题,为数据中心的可扩展性提供了新颖的视角和解决方案。。
In-Network Computing的理念在于将计算功能集成到InfiniBand网络中的交换机和InfiniBand适配器中。这样一来,可以在数据传输的同时执行简单的计算任务,无需将数据传输至服务器等终端节点进行处理,从而消除了这一环节的需求
近年来,现代数据中心的发展体现为一种新型的分布式并行处理架构,这一趋势由云计算、大数据、高性能计算和人工智能驱动。CPU、内存和存储等资源在整个数据中心中分散,并通过诸如InfiniBand、以太网、光纤通道以及Omni-Path等高速网络技术相互连接。协同设计与分工合作共同实现了数据处理任务的集体完成,构建了一个围绕业务数据为核心、平衡的系统架构。
InfiniBand网络内计算通过在网络内部执行计算任务,将数据处理职责从CPU转移到网络,从而实现集成化的网络内计算,减少延迟并提升系统性能。借助网络协议卸载、远程直接内存访问(RDMA)、GPUDirect等关键技术,InfiniBand实现了在线计算、通信延迟降低及数据传输效率优化等功能。这种深度集成的网络内计算为高性能计算和人工智能应用提供了有力的支持。
网络协议卸载是指通过将与网络相关的协议处理任务转移到专用硬件上,从而减轻CPU的处理负担。
InfiniBand网络适配器和 InfiniBand交换机负责处理整个网络通信协议栈的处理工作,涵盖物理层、链路层、网络层以及传输层。这种卸载技术在数据传输过程中消除了对额外软件和CPU处理资源的需求,显著提升了通信性能。
远程直接内存访问(RDMA)技术是为了解决网络传输中服务器端数据处理延迟的问题而开发的。RDMA允许从一台计算机的内存直接将数据传输到另一台计算机的内存,无需CPU介入,从而降低数据处理延迟并提升网络传输效率。
RDMA使得用户应用程序可以直接将数据传输至服务器存储区域,这些数据随后能够通过网络快速传送到远程系统的存储区域。这一过程消除了传输过程中多次数据复制和文本交换操作的需求,从而显著降低了CPU负载。
GPUDirect RDMA是一项利用RDMA能力促进GPU节点之间直接通信的技术,从而提升GPU集群的通信效率。
在集群内部不同节点上的两个GPU进程需要进行通信的情况下,GPUDirect RDMA技术允许RDMA网络适配器直接在两个节点的GPU内存之间传输数据。这消除了CPU参与数据复制的需求,减少了对PCIe总线的访问次数,最大限度地减少了不必要的数据复制操作,并显著提高了通信性能。
可扩展层级聚合与减少协议(SHARP)是一种针对涉及集体通信的高性能计算和人工智能应用而设计的集体通信网络卸载技术,旨在优化效率。
SHARP将计算引擎单元集成到InfiniBand交换机芯片中,支持各种定点或浮点计算。在包含多个交换机的集群环境中,SHARP在物理拓扑结构上建立一个逻辑树形结构,使得多个交换机能够并行且分布式地处理集体通信操作。这种SHARP树状结构的并行和分布式处理极大地减少了集体通信的延迟,减轻了网络拥塞,并提高了集群系统的可扩展性。该协议支持诸如屏障(Barrier)、Reduce、All-Reduce等操作,从而提升了大规模计算环境中的集体通信效率。
由于其能够提升整体系统性能和效率,InfiniBand网络内计算在HPC和AI领域得到了显著的应用。
在以计算密集型任务为主的高性能计算(HPC)领域中,InfiniBand对于缓解CPU/GPU资源竞争至关重要。高性能计算任务的通信密集特性,包括点对点通信和集体通信,需要有效的通信协议支持。在此背景下,卸载技术、RDMA、GPUDirect以及SHARP等技术被广泛采用,以优化计算性能。
作为前沿技术的人工智能,极大程度上依赖于InfiniBand网络内计算来加快训练过程并获得高精度模型。在当前环境下,GPU或专用AI芯片是AI训练平台的计算核心。这些平台利用InfiniBand加速训练过程,众所周知这是一个计算密集型的过程。卸载应用程序通信协议对于减少AI训练期间的延迟至关重要。GPUDirect RDMA技术被用于提升GPU集群之间的通信带宽,有效减少了通信延迟。
InfiniBand网络内计算作为一种创新的网络计算技术,为HPC和AI领域提供了高效且可靠的计算支持。作为信息技术领域的重要创新之一,InfiniBand网络内计算将持续引领网络计算技术的进步和发展。
InfiniBand,撼动不了以太网?
英伟达Quantum-2 Infiniband平台技术A&Q
一颗Jericho3-AI芯片,用来替代InfiniBand?
RoCE技术在HPC中的应用分析
《RDMA技术参考文献汇总》
《RDMA技术合集(下)》
1、总线级数据中心网络技术白皮书.pdf
2、RDMA提高数据传输效率.pdf
3、配置 InfiniBand 和 RDMA 网络.pdf
4、华为RDMA.pdf
5、面向AI智能无损数据中心网络.pdf
6、面向分布式 AI智能网卡低延迟Fabric技术.pdf
7、NVMe存储SPDK 加速前后端 IO.pdf
8、基于RDMA多播机制的分布式持久性内存文件系统.pdf
9、云环境下分布式存储性能优化实践.pdf
《RDMA技术合集(上)》
1、智能网卡低延迟Fabric技术.pdf
2、RDMA参数选择.pdf
3、RDMA在数据中心中的应用研究.pdf
4、RDMA系统的挑战.pdf
5、RDMA网络人工智能训练重要硬件
6、RDMA技术白皮书(中文版)
7、RDMA技术调研
8、RDMA在数据中心中的应用研究
《NVIDIA InfiniBand网络技术新特性(2023)》
1、NVIDIA InfiniBand-NDR Q&A
2、NVIDIA Infiniband Networking Update 2023
《OFA Workshop 2023合集》
《NVIDIA Jetson机器软件栈更新合集》
1、NVIDIA Jetson自主机器软件栈更新
2、NVIDIA Jetson赋能新一代自主机器
《集成电路及芯片知识汇总(2)》
《集成电路及芯片知识汇总(1)》
OrionX GPU AI算力资源池化技术白皮书
HPDA/AI市场表现Update浅析(附报告)
HPC市场份额剖析和全球超算计划(附报告)
Hyperion Research:SC22 HPC Market Update(2022.11)
Hyperion Research:ISC22 Market Update(2022.5)
Intersect360全球HPC-AI市场报告(2022—2026)
Intersect360 AMD CPU和GPU调研白皮书
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


