


----追光逐电 光赢未来----

监督学习山谷:教导机器的艺术
想象一下,监督学习山谷是一个充满教室的地方,每个教室里的孩子(机器模型)都在学习如何区分苹果和香蕉(分类问题),或者预测明天的天气温度(回归问题)。老师(数据科学家)会给他们展示大量的例子(标记数据),这些例子就像是答案卡,告诉孩子们每个水果是什么,或者每天的确切温度。随着时间的推移,孩子们开始学会如何根据以前看到的水果的特征识别新的水果,或者预测温度。这个过程就像是在训练小狗做特技,给它看正确的动作,并用零食奖励它。

监督式机器学习的相关算法
分类算法:
逻辑回归(Logistic Regression)
决策树(Decision Trees)
随机森林(Random Forest)
K最近邻(K-Nearest Neighbors)
支持向量机(Support Vector Machines)
回归算法:
线性回归(Linear Regression)
弹性网络(Elastic Net)
决策树(Decision Trees)
随机森林(Random Forest)
XGBoost
神经网络(Neural Networks)
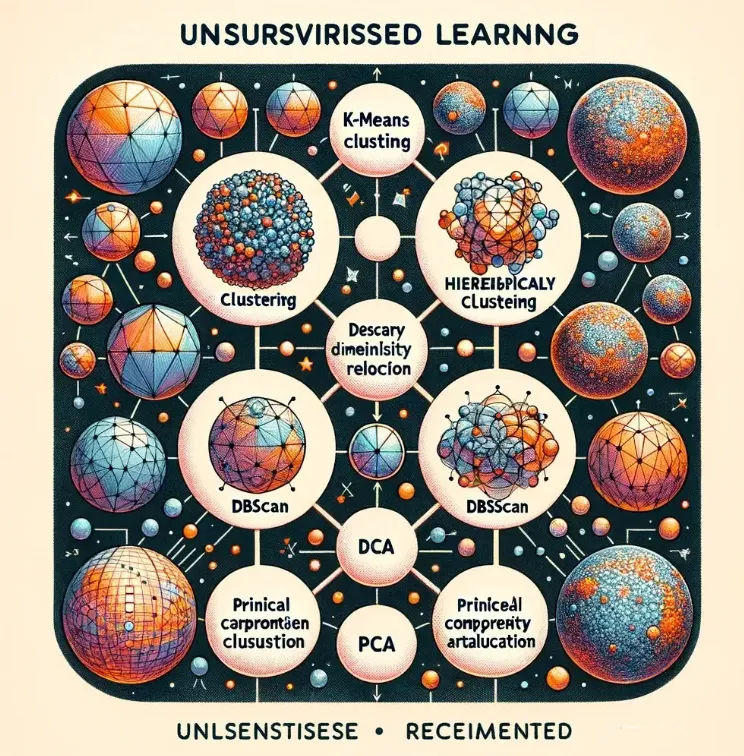
无监督学习森林:探索未知的旅程
接下来,我们进入一个更神秘的地方——无监督学习森林。这里没有老师,也没有标准答案。想象一下,你是一名探险者,带着一张空白地图(数据集)进入森林,试图找到未知领域的规律和结构。聚类算法就像是你的罗盘,帮助你将相似的景点(数据点)分成不同的区域(群组)。而降维技术,则像是魔法望远镜,帮你去除掉那些遮挡视线的树木(无关特征),让你更清晰地看到森林的全貌。
在这片森林中,每一次的探险都可能带来新的发现。有时,你可能会找到一片由相似动物构成的区域(聚类),或者发现通过减少一些不必要的小路(降维),可以更快地穿越森林。
无监督机器学习算法
聚类算法:
K-均值聚类(K-Means Clustering)
DBSCAN
层次聚类(Hierarchical Clustering)
其他无监督算法:
主成分分析(PCA)
关联规则学习(Association Rule Learning)
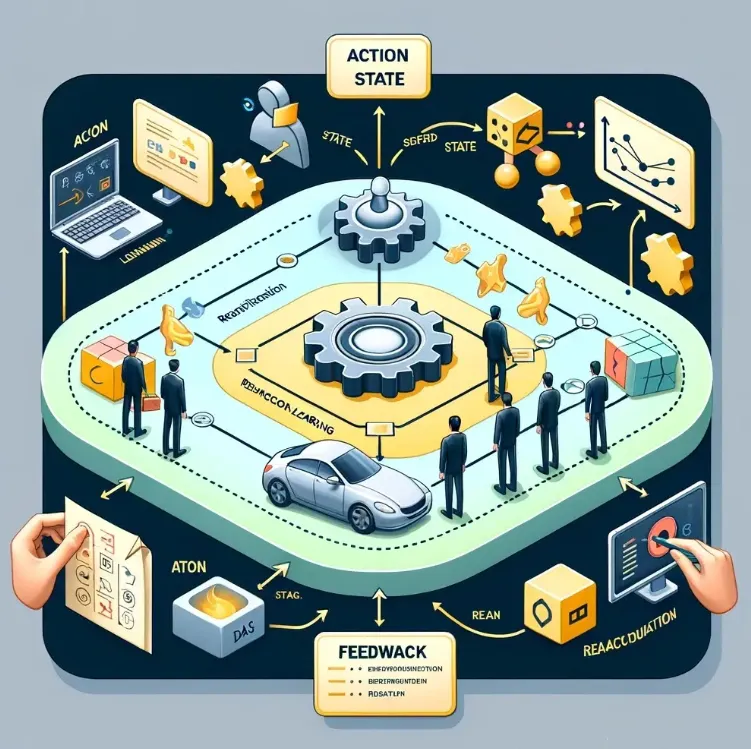
强化学习岛:奖励驱动的探索
最后,我们乘船来到一个充满挑战和奖励的地方——强化学习岛。在这里,机器是一位勇敢的探险家,它必须通过尝试和错误来学习如何在岛上生存(解决问题)。每当它做出正确的决策(如找到水源或食物),它就会得到奖励(正反馈)。而当它走错路或遇到危险时,则会受到惩罚(负反馈)。通过这种方式,机器开始学习哪些行为是好的,哪些是坏的。

想象强化学习岛上有各种各样的环境,从密林深处到高山之巅,每一个环境都代表一个不同的挑战。机器探险家(学习代理)需要在这些环境中找到最佳路径,比如在岛上寻找宝藏(目标)的最短路径,或者学习如何驾驶一艘船穿越风暴(复杂任务)。这个过程中的Q学习、R学习和时间差分学习就像是探险家的不同生存技能,帮助它在这个充满挑战的环境中成长和适应。
强化学习算法
Q学习(Q-Learning)
R学习(R-Learning)
时序差分学习(TD-Learning)
五、学习路线图
对于初学者,首先应该掌握监督学习和无监督学习的概念和方法,因为这些是最常见也是最有实际应用价值的机器学习类型。强化学习虽然复杂且应用较为特定,但了解其基本原理也是有益的。在实践中,你可能首先不会直接应用强化学习,除非你工作在特定领域如自动化控制、游戏设计或者机器人技术等。
六、实际应用
监督学习:广泛应用于信用评分、客户细分、销售预测等商业问题。例如,使用逻辑回归进行二分类问题,如预测客户是否会购买产品;使用线性回归进行销售预测等。
无监督学习:主要用于市场细分、客户细分、异常检测等。比如使用K-均值聚类对客户进行分组,以便更有效地进行市场定位和资源分配。
强化学习:虽然在商业应用中不如前两种算法普遍,但在游戏设计、机器人导航、自动化交易等领域展现出巨大的潜力。例如,强化学习被用于开发能够击败人类职业选手的围棋软件。
七、结论
作为一名数据科学家或机器学习工程师,理解这三种类型的机器学习及其相关算法对于构建有效的数据驱动解决方案至关重要。从监督学习开始,逐步探索无监督学习和强化学习,可以帮助你更好地理解数据的内在结构和动态,进而开发出更加智能和自适应的系统。不过,要记得实践是学习的关键,尝试将这些算法应用于实际问题中,通过实践来深化理解和技能。
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


