


InfiniBand(IB)是由InfiniBand贸易协会(IBTA)建立的先进计算机网络通信标准。它在高性能计算(HPC)中的广泛采用归功于它能够为网络传输提供卓越的吞吐量、带宽和低延迟。
InfiniBand是计算系统内部和外部的关键数据连接。无论是通过直接链路还是通过网络交换机进行互连,InfiniBand都有助于实现服务器到存储和存储到存储数据传输的高性能网络。InfiniBand网络可扩展性允许通过交换网络进行水平扩展,以满足多样化的网络需求。随着科学计算、人工智能(AI)和云数据中心的快速发展,InfiniBand在端到端高性能网络的HPC超级计算应用中越来越受到青睐。
AI算力研究:英伟达B200再创算力奇迹,液冷、光模块持续革新
英伟达发布新一代GPU架构,NVLink连接技术迭代升级
大模型语言模型:从理论到实践
技术展望2024:AI拐点,重塑人类潜力
英伟达GTC专题:新一代GPU、具身智能和AI应用
AI算力研究:英伟达B200再创算力奇迹,液冷、光模块持续革新
GPU深度报告:英伟达GB200 NVL72全互联技术,铜缆方案或将成为未来趋势?
人工智能系列专题报告:CoWoS技术引领先进封装,国内OSAT有望受益
软硬件融合:从DPU到超异构计算
《大模型技术能力测评合集》
1、大模型时代,智算网络性能评测挑战
2、AIGC通用大模型产品测评篇(2023)
3、人工智能大模型工业应用准确性测评
4、甲子星空坐标系:AIGC通用大模型产品测评篇
5、AIGC通用大模型产品测评篇(2023)
6、2023年中国大模型行研能力评测
1、新型智算中心算力池化技术白皮书 2、智算中心网络架构白皮书 3、面向AI大模型的智算中心网络演进白皮书 4、智算赋能算网新应用白皮书
14份半导体“AI的iPhone时刻”深度系列报告合集
12份走进“芯”时代系列深度报告合集
2015年6月,InfiniBand在全球最强大的超级计算机500强名单中占据了惊人的51.8%,同比增长了15.8%。
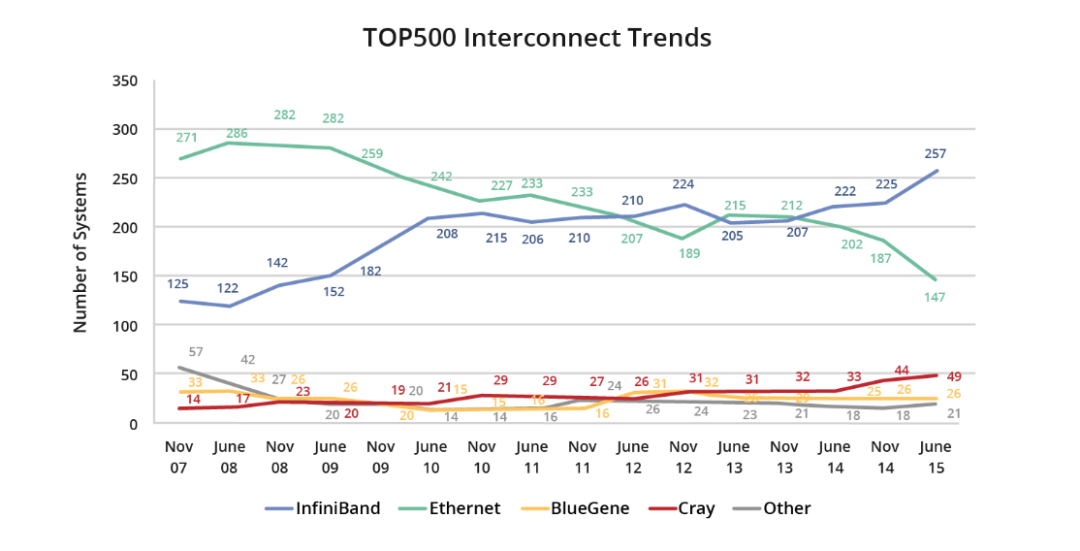
在2022年6月的Top500榜单中,InfiniBand网络再次占据了超级计算机互连设备的领先地位。与之前的榜单相比,InfiniBand网络展现了在数量和性能方面的优势。主要趋势包括:
英伟达(NVIDIA)GPU和网络产品,尤其是迈络思(Mellanox)HDR Quantum QM87xx交换机和BlueField DPU,在超过三分之二的超级计算机中占据了主导互连的地位。
除了传统的HPC应用之外,InfiniBand网络还广泛用于企业级数据中心和公有云。例如,领先的企业超级计算机英伟达(NVIDIA)Selene和Microsoft的Azure公有云利用InfiniBand网络提供卓越的业务性能。
在2023年11月的最新Top500榜单中,InfiniBand保持着领先位置,突显了其持续增长的趋势。InfiniBand在Top500排行榜中备受关注,主要是因为它具有卓越的性能优势。
InfiniBand技术被认为是面向未来的高性能计算(HPC)标准,在超级计算机、存储甚至LAN网络的HPC连接方面享有很高的声誉。InfiniBand技术拥有众多优势,包括简化管理、高带宽、完全CPU卸载、超低延迟、集群可扩展性和灵活性、服务质量(QoS)、SHARP支持等。
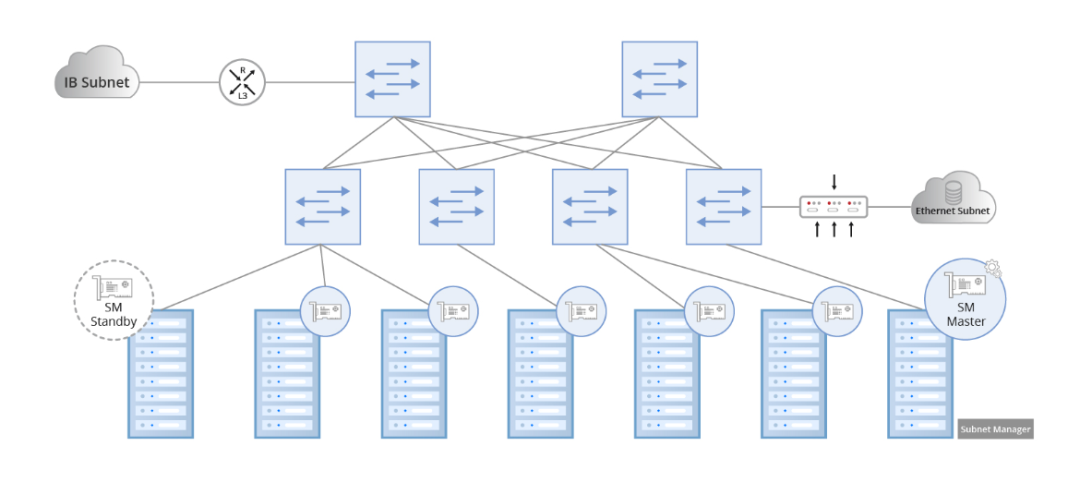
InfiniBand代表了专为软件定义网络(SDN)打造的开创性网络架构,并由子网管理器进行监督。子网管理器负责配置本地子网,确保网络无缝运行。为了管理流量,所有通道适配器和交换机都必须实现与子网管理器协作的子网管理代理(SMA)。在建立或切断链接时,每个子网至少需要一个子网管理器进行初始设置和重新配置。仲裁机制用于指定主子网管理器,其他子网管理器在备用模式下运行。在备用模式下,每个子网管理器都会保留备份拓扑信息并验证子网的运行状态。如果主子网管理器发生故障,备用子网管理器将接管控制权,从而保证子网管理不间断。
自从InfiniBand问世以来,其网络数据速率一直超过以太网,主要是因为它在高性能计算中的服务器互连中得到了广泛应用,满足了对更高带宽的需求。在2014年早期,流行的InfiniBand速率是40Gb/s QDR和56Gb/s FDR。目前,更高的InfiniBand速率,例如100Gb/s EDR和200Gb/s HDR,已被全球众多超级计算机广泛采用。最新的OpenAI工具ChatGPT的推出促使企业考虑在其高性能计算(HPC)系统中部署具有400Gb/s NDR数据速率的先进InfiniBand网络产品,包括InfiniBand NDR交换机和光缆。
每种InfiniBand速率类型的缩写如下:
XDR-极致数据速率,800Gbps。
CPU卸载是增强计算性能的一项关键技术,而InfiniBand网络架构通过以下方式以最少的CPU资源促进数据传输:
RDMA(远程直接内存访问),一种将数据从一台服务器的内存直接写入另一台服务器的内存的过程,无需CPU参与。
利用GPUDirect技术是另一种选择,它允许直接访问GPU内存中的数据,并加速数据从GPU内存传输到其他节点。此功能可提高人工智能(AI)、深度学习训练、机器学习等计算应用程序的性能。
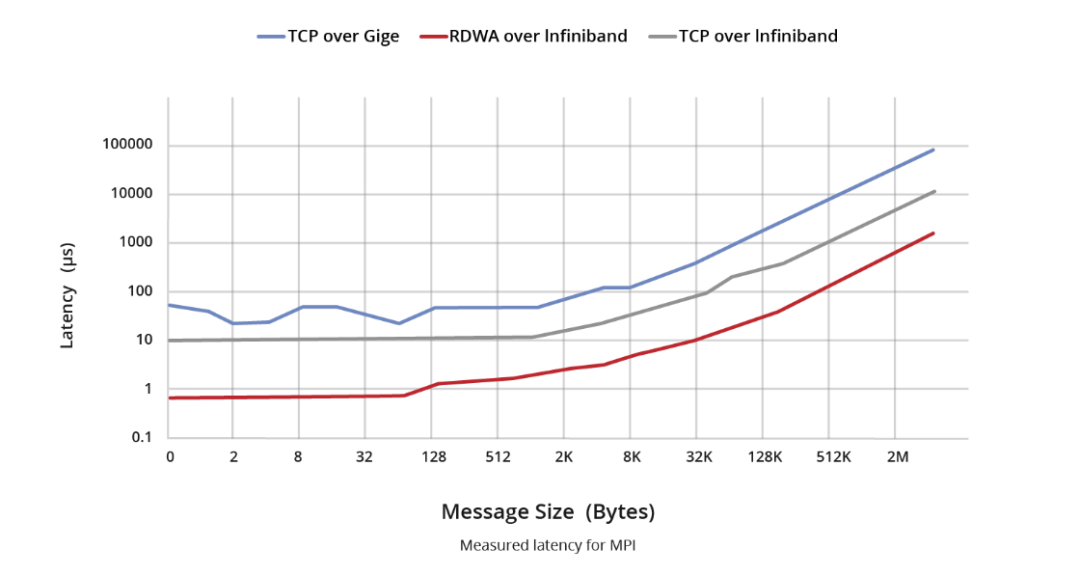
InfiniBand和以太网之间的延迟对比可以分为两个主要组成部分。首先,在交换机层面上,以太网交换机在网络传输模型中作为第2层设备运行,通常采用MAC表查找寻址和存储转发机制(某些产品可能采用InfiniBand的直通技术)。以太网交换机中,IP、MPLS、QinQ和其他处理等复杂服务会导致处理持续时间延长,延迟测量结果通常以微秒为单位(直通支持可能超过200ns)。相比之下,InfiniBand交换机简化了第2层处理,仅依靠16位LID转发路径信息。此外,采用直通技术可将转发延迟显著降低到100ns以下,已经超过以太网交换机的速率。
如前所述,在网卡(NIC)层面,RDMA技术消除了网卡遍历CPU进行消息转发的需要。这种加速尽可能地减少了封装和解封装期间消息处理的延迟。通常,InfiniBand网卡的发送和接收延迟(写入、发送)为600ns,而使用以太网的基于以太网TCP UDP应用程序的发送和接收延迟通常徘徊在10us左右。这导致InfiniBand和以太网之间的延迟差距超过10倍。
InfiniBand网络的一个重要优势在于其能够在单个子网中部署多达48,000个节点,形成一个庞大的第二层网络。此外,InfiniBand网络避开了ARP等广播机制,从而避免了广播风暴和相关的额外带宽浪费。多个InfiniBand子网的连接可通过路由器和交换机实现,展示了该技术在支持各种网络拓扑方面的多功能性。
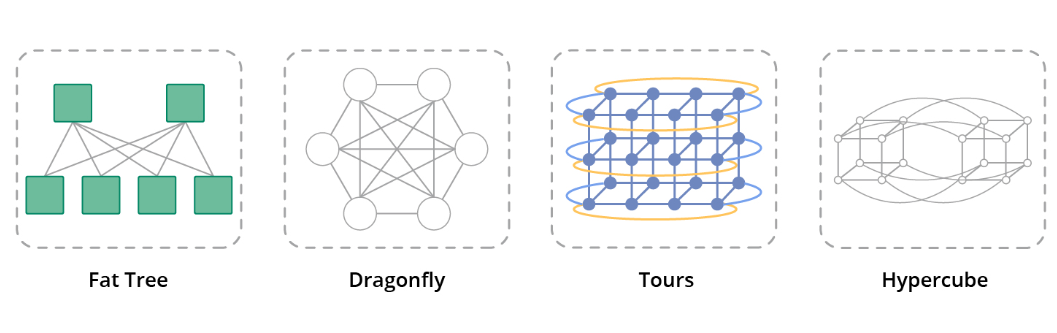
对于较小规模的情况,建议使用2层胖树拓扑结构,而对于较大规模的情况,可以选择3层胖树网络拓扑结构。在特定规模之上,可以采用经济高效的Dragonfly拓扑结构来进一步提升可扩展性。
在管理InfiniBand网络时,如果各种应用程序共存于同一子网上,且具有不同的优先级要求,那么提供服务质量(QoS)就成为一个关键因素。QoS表示为不同的应用程序、用户或数据流提供不同优先级服务的能力。在InfiniBand环境中,可以将高优先级应用程序分配给特定的端口队列,从而确保这些队列中的消息得到优先处理。
InfiniBand通过实施虚拟通道(VL)实现QoS。虚拟通道是共享公共物理链路的离散逻辑通信链路。每个VL能够支持多达15个标准虚拟通道以及一个指定为VL15的管理通道。这种方法可以根据优先级对流量进行有效隔离,从而允许在InfiniBand网络内优先传输高优先级应用程序。
在理想情况下,网络运行稳定且没有故障。然而,现实情况中长期运行的网络偶尔会出现故障。为了解决这些挑战并确保快速恢复,InfiniBand采用了一种称为自我修复网络的机制,这是一种集成到InfiniBand交换机中的硬件功能。
NVIDIA Mellanox InfiniBand解决方案包括InfiniBand交换机、网卡和迈络思(Mellanox)线缆等硬件组件,利用自我修复网络实现从链路故障中快速恢复。这种基于硬件的功能能够在惊人的1ms内恢复链路故障,比正常恢复时间快了5000倍。
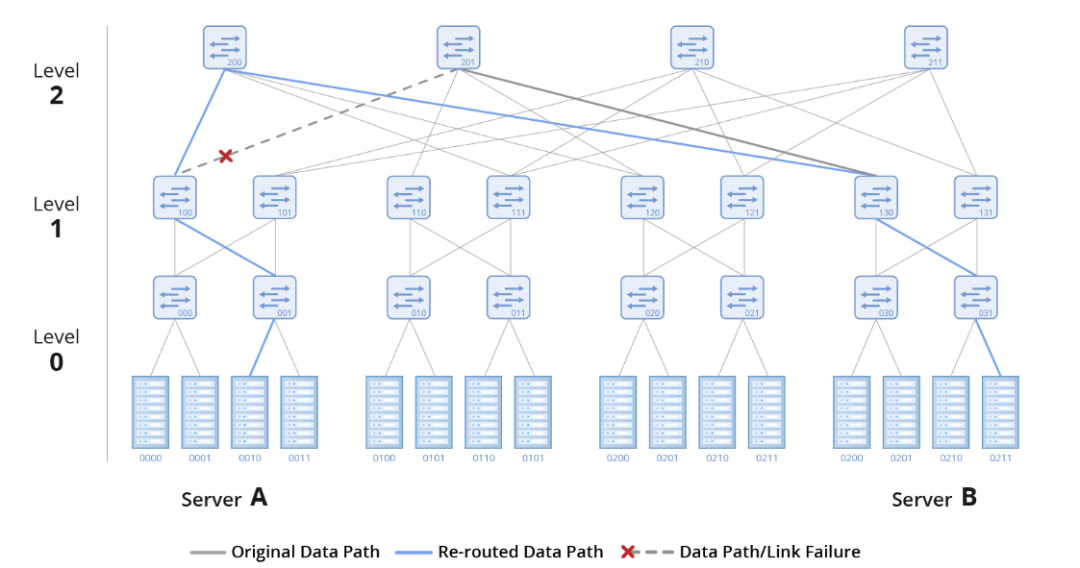
提高网络利用率是高性能数据中心的一项关键要求。在InfiniBand网络中,一种有效的实现方法是负载均衡。
负载均衡是一种路由策略,可以在多个可用端口之间分配流量。其中自适应路由是一个关键特性,可以确保流量在交换机端口之间均匀分布。这个特性在交换机上得到硬件支持,并由自适应路由管理器进行管理。
当自适应路由处于活动状态时,交换机上的队列管理器将监控所有组出口端口上的流量,均衡每个队列上的负载,并将流量引导至未充分利用的端口。自适应路由可动态平衡负载,防止网络拥塞并优化网络带宽利用率。
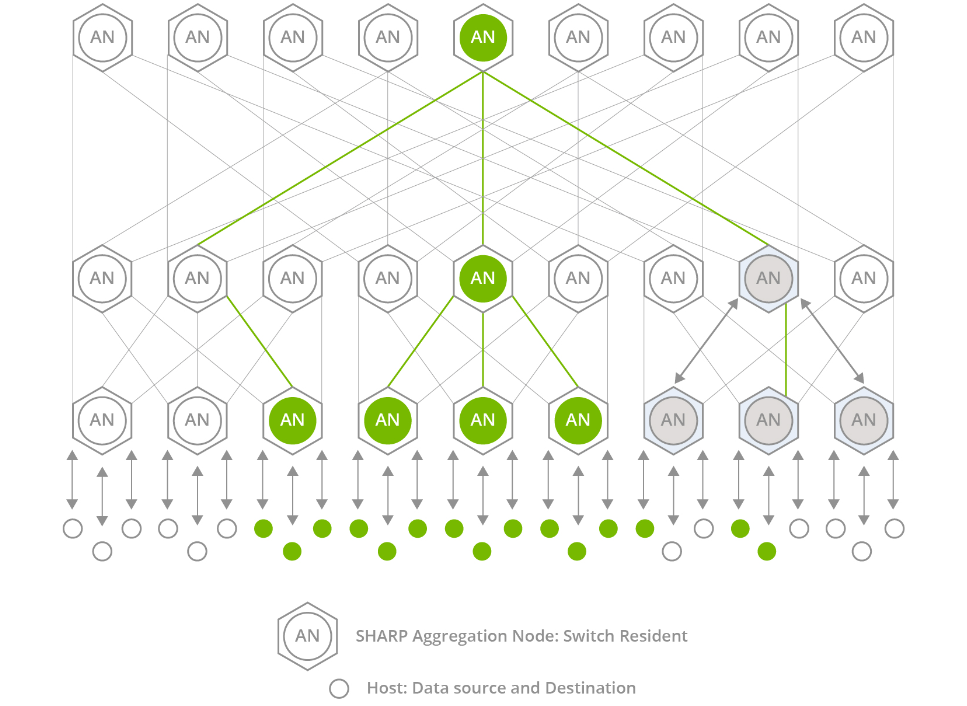
InfiniBand交换机还具有SHARP网络计算技术,该技术代表可扩展的分层聚合和缩减协议。SHARP是集成到交换机硬件中的软件,是一个集中管理的软件包。
通过将聚合通信任务从CPU和GPU卸载到交换机,SHARP可以优化这些通信。它可以防止节点之间的冗余数据传输,从而减少必须遍历网络的数据量。因此,SHARP显著提高了加速计算的性能,尤其是在AI和机器学习等MPI应用中。
InfiniBand支持各种网络拓扑,如胖树、Torus、Dragonfly+、Hypercube和HyperX,满足网络扩展、降低总拥有成本(TCO)、最小化延迟和延长传输距离等不同需求。
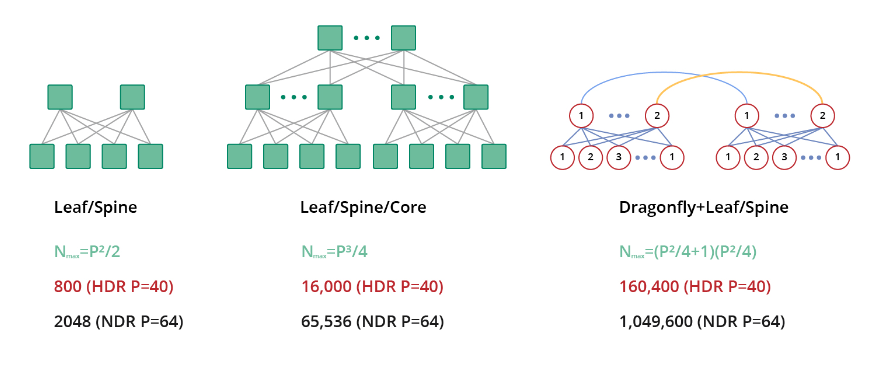
InfiniBand利用其无与伦比的技术优势,显著简化了高性能网络架构,减轻了多级架构层次结构带来的延迟。此功能为无缝升级关键计算节点的访问带宽提供了强大的支持。InfiniBand网络因其高带宽、低延迟以及与以太网的兼容性,越来越多地在各种场景中得到应用。
随着客户端需求的不断增长,100Gb/s EDR正逐渐退出市场。目前NDR的数据速率被认为过高,而HDR凭借其提供HDR100(100G)和HDR200(200G)的灵活性获得广泛采用。
英伟达(NVIDIA)提供两种类型的InfiniBand HDR交换机。第一种是HDR CS8500模块化机箱交换机,这是一款29U交换机,提供多达800个HDR 200Gb/s端口。每个200G端口支持拆分为2X100G,最多支持1600个HDR100(100Gb/s)端口。第二种是QM87xx系列固定交换机,1U面板集成了40个200G QSFP56端口。这些端口可以拆分为多达80个HDR 100G端口,以连接到100G HDR网卡。同时,每个端口还向后支持EDR速率以连接100G EDR网卡卡。需要注意的是,单个200G HDR端口只能降速到100G连接EDR网卡,不能拆分成2X100G连接两个EDR网卡。
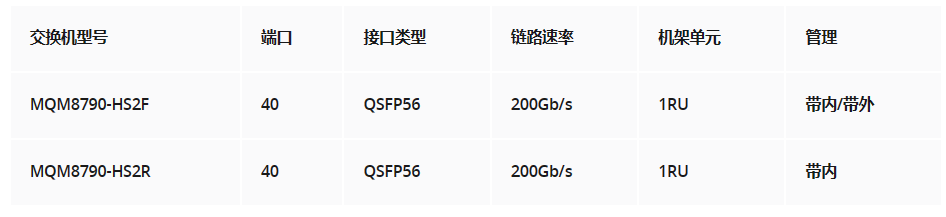
200G HDR QM87xx交换机有两种型号:MQM8700-HS2F和MQM8790-HS2F。这两种型号之间的唯一区别在于管理方法。QM8700交换机具有支持带外管理的管理端口,而QM8790交换机需要英伟达(NVIDIA)UFMR平台进行管理。
对于QM8700和QM8790,每种交换机都提供两种气流选项。其中,MQM8790-HS2F交换机具有P2C(电源到线缆)气流,可通过风扇模块上的蓝色标记来识别。如果忘记了颜色标记,也可以通过将手放在开关的进气口和出风口前面来确定气流方向。MQM8790-HS2R交换机采用C2P(线缆到电源)气流,风扇模块上有红色标记。QM87xx系列交换机型号详情如下:
CQM8700和QM8790交换机通常用于两种连接应用。一种与200G HDR网卡连接,从而实现使用200G到200GAOC/DAC线缆的直接连接。另一种常见的应用是连接100G HDR网卡,需要使用200G转2X100G线缆将交换机的物理200G(4X50G)QSFP56端口拆分为两个虚拟100G(2X50G)端口。拆分后,端口符号从x/y转换为x/Y/z,其中“x/Y”表示拆分前端口的原始符号,“z”表示单通道端口的编号(1,2),每个子物理端口被视为一个单独的端口。
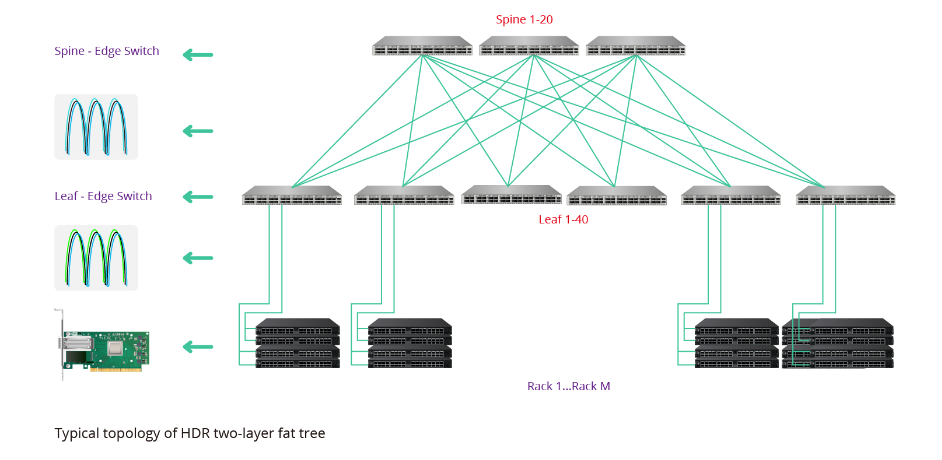
与HDR交换机相比,HDR网卡(NIC)种类繁多。关于速率,有两种选择:HDR100和HDR。
HDR100网卡支持100Gb/s的传输速率,两个HDR100端口可以使用200G HDR转2X100G HDR100线缆连接到HDR交换机。与100G EDR网卡相比,HDR100网卡的100G端口可以同时支持4X25G NRZ传输和2X50G PAM4传输。
200G HDR网卡支持200G的传输速率,可以使用200G直连线缆直接连接到交换机。
除了两种接口数据速率外,每种速率的网卡都可以根据业务需求选择单端口、双端口和PCIe类型。常用的IB HDR网卡型号如下:

HDR InfiniBand网络架构简单明了,同时提供了多种硬件选项。对于100Gb/s速率,有100G EDR和100G HDR100解决方案。200Gb/s速率包括HDR和200G NDR200选项。各种应用中使用的交换机、网卡和附件存在显著差异。InfiniBand高性能HDR和EDR交换机、智能网卡、纳多德(NADDOD)/迈络思(Mellanox)/思科(Cisco)/惠普(HPE)光缆&高速线缆&光模块产品组合解决方案,为数据中心、高性能计算、边缘计算、人工智能等应用场景提供更具优势和价值的光网络产品和综合解决方案。这大大增强了客户的业务加速能力,成本低且性能优异。
速率和可靠性的差异:这些技术之间的主要差异在于它们的速率和可靠性。在高性能计算网络中,InfiniBand优先用于需要快速数据传输的应用程序,而以太网的可靠性使其更适合在LAN网络中进行一致的数据传输。
数据中心网络的演变:尽管英伟达(NVIDIA)推出了InfiniBand 400G NDR解决方案,但一些用户仍在继续使用100G EDR解决方案。Omni-Path和InfiniBand都是以100Gb/s速率运行的高性能数据中心网络的常见选择。
网络结构区别:虽然这两种技术提供相似的性能,但Omni-Path和InfiniBand的网络结构有很大不同。举例来说,使用InfiniBand的400节点集群只需要15台英伟达(NVIDIA)Quantum 8000系列交换机和特定线缆,而Omni-Path需要24台交换机和大量有源光缆。
InfiniBand EDR解决方案的优势:与Omni-Path相比,InfiniBand EDR解决方案在设备成本、运营和维护成本以及总体功耗方面具有显著优势。这使得InfiniBand成为更环保的选择。
来源:
https://community.fs.com/cn/article/exploring-infiniband-network-hdr-and-significance-of-ib-applications-in-supercomputing.html
相关阅读:
InfiniBand,撼动不了以太网?
英伟达Quantum-2 Infiniband平台技术A&Q
一颗Jericho3-AI芯片,用来替代InfiniBand?
RoCE技术在HPC中的应用分析
Hyperion Research:SC22 HPC Market Update(2022.11)
Hyperion Research:ISC22 Market Update(2022.5)
Intersect360全球HPC-AI市场报告(2022—2026)
Intersect360 AMD CPU和GPU调研白皮书
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


