





来源 | 新智元



起源
2011年:Jeff Dean、Greg Corrado和Andrew Ng发起了关于深度学习的研究项目——Google Brain。 2013年:继AlexNet图像识别项目取得成功后,谷歌以4400万美元的价格收购了由Geoffrey Hinton、Alex Krizhevsky和Ilya Sutskever组成的初创公司。 2014年:谷歌收购了由Demis Hassabis、Shane Legg和Mustafa Suleyman创立的DeepMind,价格高达65000万美元

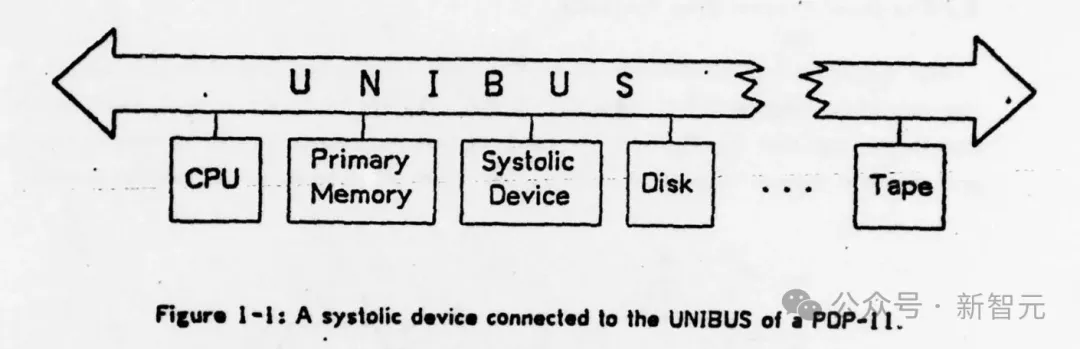
A systolic system is a network of processors which rhythmically compute and pass data through the system….In a systolic computer system, the function of a processor is analogous to that of the heart. Every processor regularly pumps data in and out, each time performing some short computation so that a regular flow of data is kept up in the network. systolic system是一个处理器网络,它有节奏地计算并通过系统传递数据......处理器的功能类似于心脏,每个处理器都会定期将数据泵入和泵出,每次都执行一些简短的计算,以便在网络中保持常规的数据流。
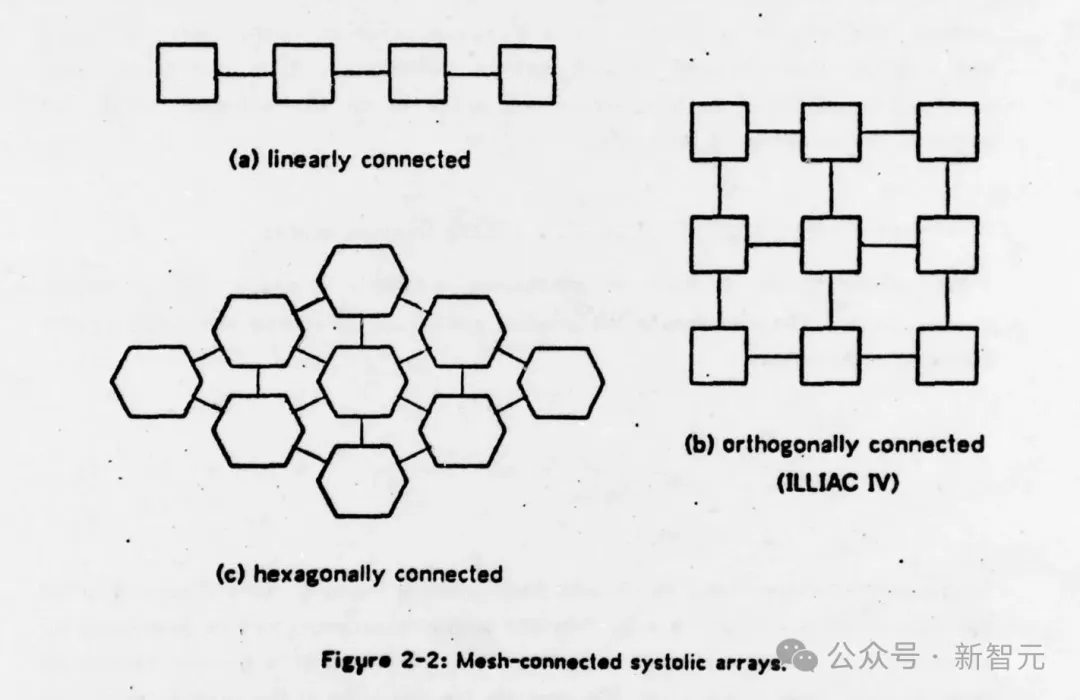
Many basic matrix computations can be pipelined elegantly and efficiently on systolic networks having an array structure. As an example, hexagonally connected processors can optimally perform matrix computation......These systolic arrays enjoy simple and regular communication paths, and almost all processors used in the network are identical. As a result, special purpose hardware devices based on systolic arrays can be built inexpensively using the VLSI technology. 许多基本的矩阵计算可以在具有数组结构的脉动网络上优雅而有效地执行流水线。例如,六边形连接的处理器可以最佳地执行矩阵计算......这些脉动阵列享有简单而规则的通信路径,并且网络中使用的几乎所有处理器都是相同的。因此,使用VLSI技术可以廉价地构建基于脉动阵列的专用硬件设备。


TPU架构
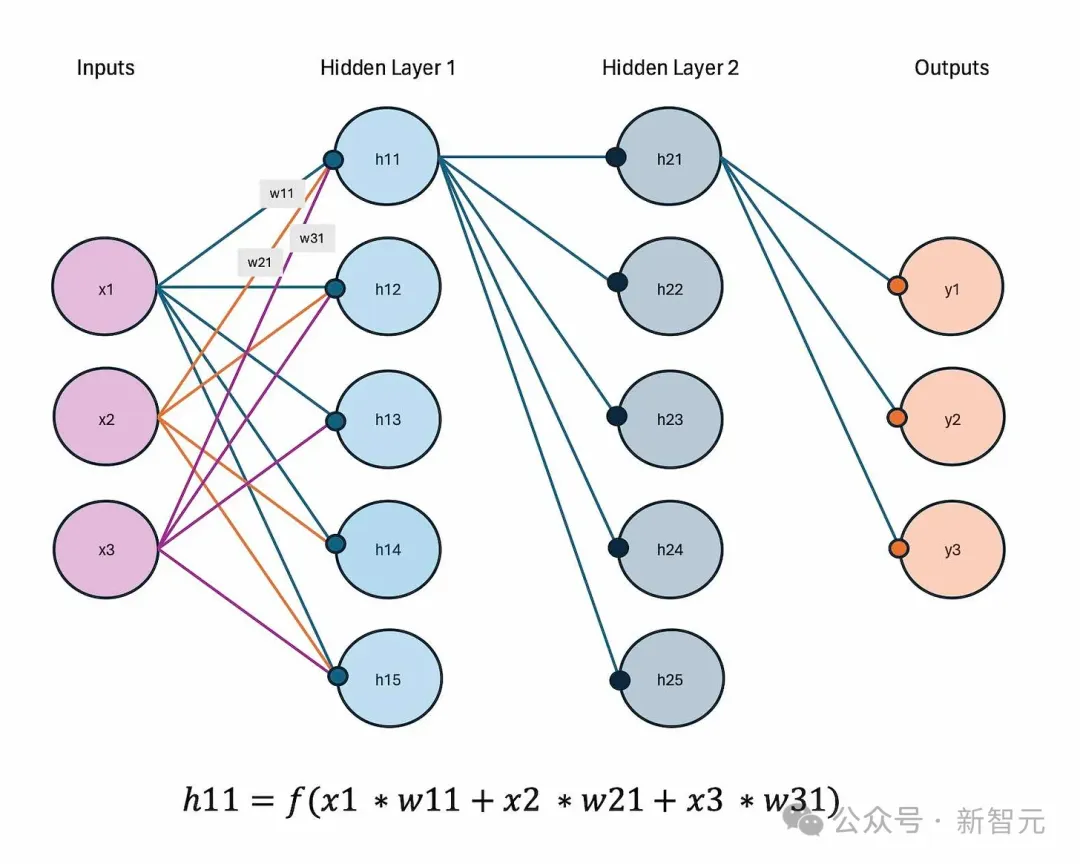
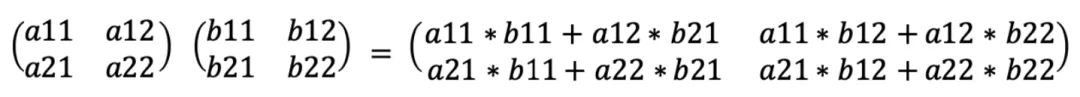
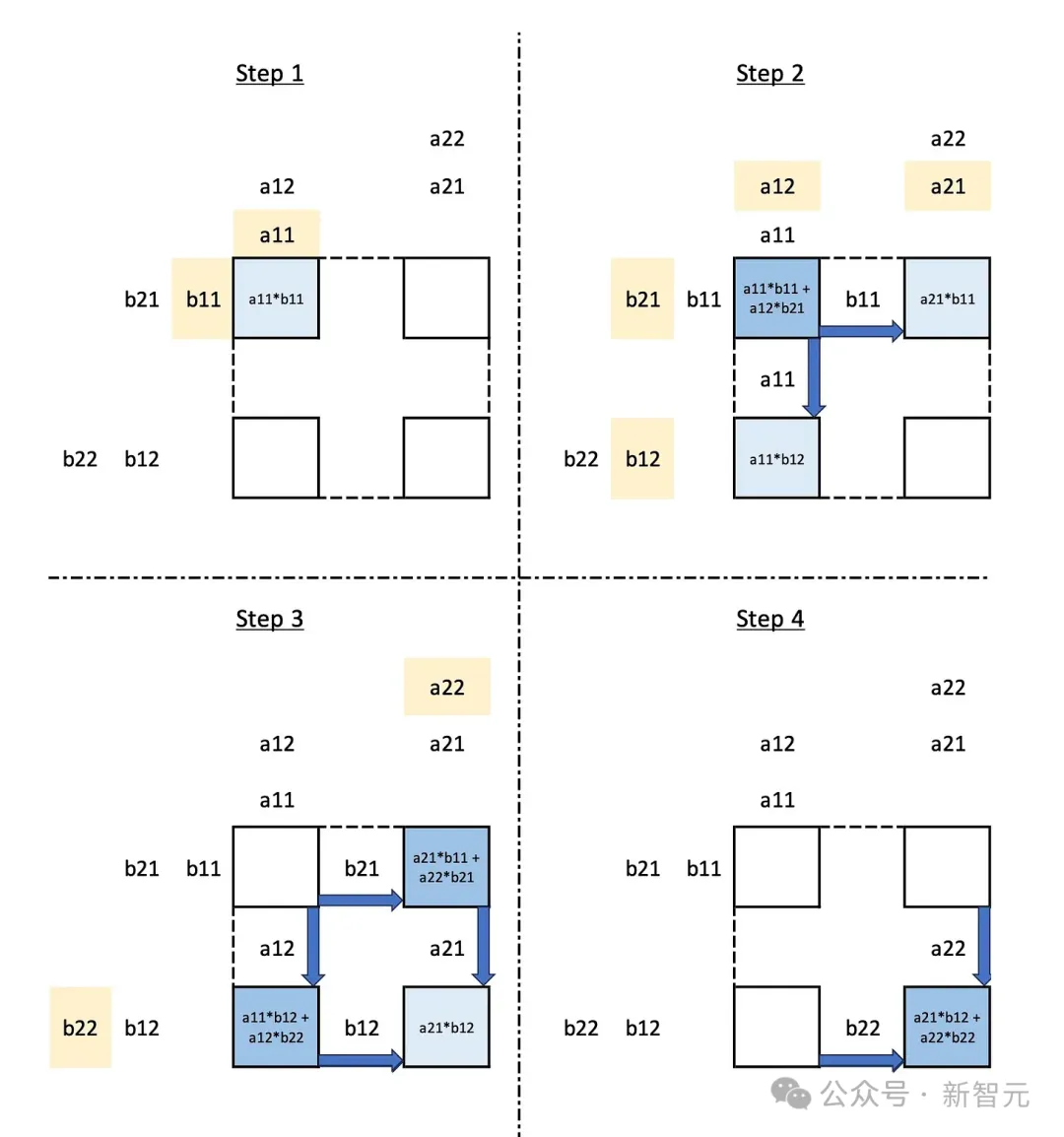
第一步,a11和b11加载到左上角的MAC中,相乘并存储结果。 第二步,a12和b21加载到左上角的MAC中,相乘并添加到先前计算的结果中。这一步得到了结果矩阵的左上角值。同时,b11被传输到右上角的MAC,乘以新加载的a21,并存储结果;a11被传输到左下角的MAC,乘以新加载的b12,并存储结果; 第三步,b21被传输到右上角的MAC,乘以新加载的值a22,结果被添加到以前存储的结果中;a12被传输到左下角的MAC,乘以新加载的b22,并将结果添加到先前存储的结果中。此时得到了结果矩阵的右上角和左下角值。同时,a12和b21被传输到右下角的MAC,相乘并存储结果。 第四步,将a22和b22传输到右下角的MAC,相乘并将结果添加到先前存储的值中,从而得到结果矩阵的右下角值。
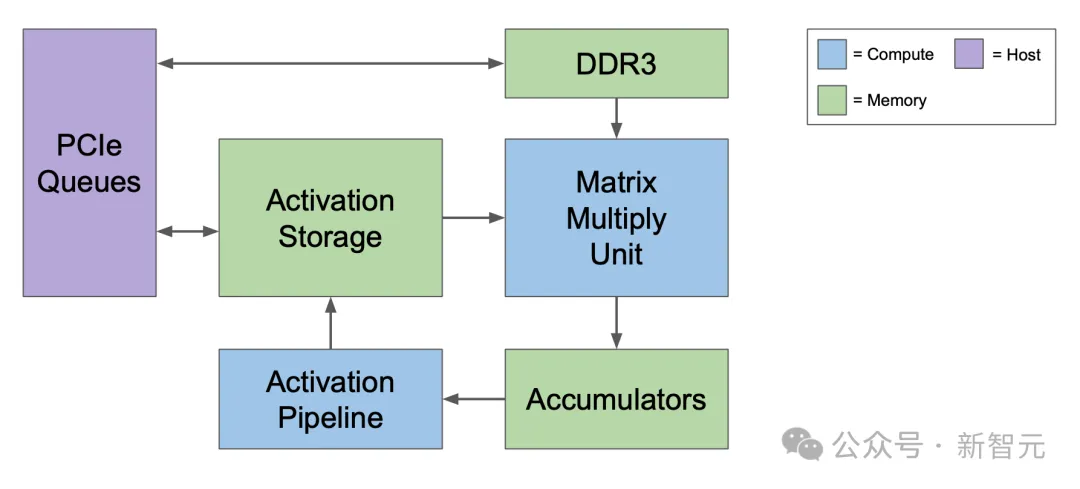
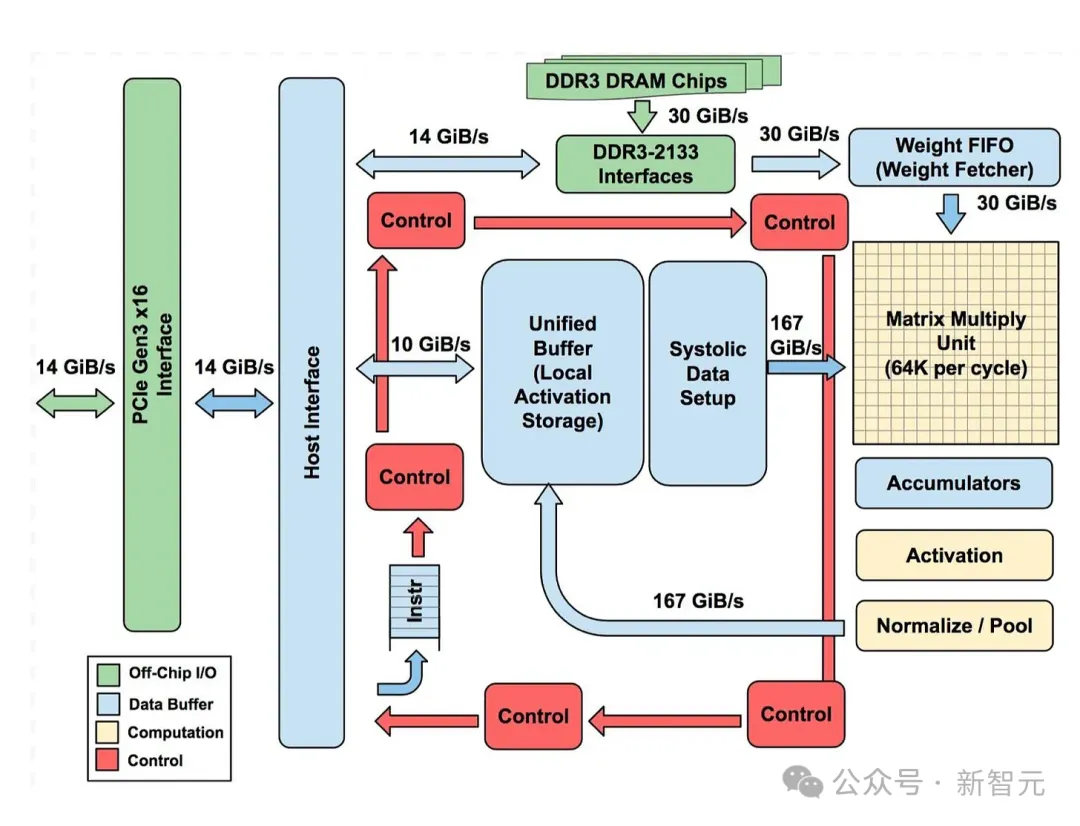
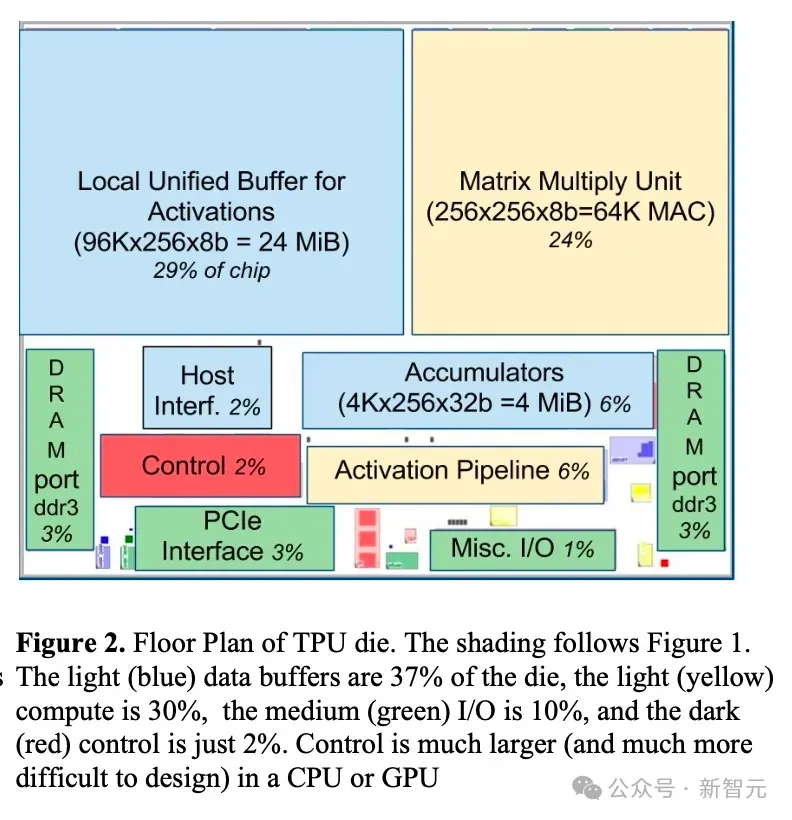
DDR3 DRAM / Weight FIFO:权重存储在通过DDR3-2133接口连接到TPU v1的DDR3 RAM芯片中。权重通过PCIe从主机的内存预加载,然后可以传输到权重FIFO存储器中,供矩阵乘法单元使用。 Matrix Multiply Unit:256 x 256大小的矩阵乘法单元,顶部输入256个权重值,左侧是256个input值。 Accumulators:运算结果从脉动阵列的底部汇总到累加器中(内存)。 Activation:激活函数。 Unified Buffer / Systolic Data Setup:应用激活函数的结果存储在统一缓冲区存储器中,然后可以作为输入反馈到矩阵乘法单元,以计算下一层所需的值。
Read_Host_Memory
Read_Weights
Loop_Start
Matrix_Multiply
Activate
Loop_End
Write_Host_Memory
TPU v1的MAC数量是K80 GPU的25倍,片上内存是K80 GPU的3.5倍。 TPU v1的推理速度比K80 GPU和Haswell CPU快15到30倍。 TPU v1的相对计算效率是GPU的25到29倍。







关注下面公众号
和我一起探索港股市场的所有秘密
👇🏻


