
----追光逐电 光赢未来----
Opencv是用于快速处理图像处理、计算机视觉问题的工具,支持多种语言进行开发如c++、python、java等,下面这篇文章主要给大家介绍了关于openCV入门学习基础教程的相关资料,需要的朋友可以参考下
一、Canny边缘检测
该边缘检测法步骤如下:
使用高斯滤波器,以平滑图像,滤除噪声。
计算图像中每个像素点的梯度强度和方向。
应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散响应。
应用双阈值(Double-Threshold)检测来确定真实的和潜在的边缘。
通过抑制孤立的弱边缘最终完成边缘检测。
高斯滤波
我们要进行边缘检测过程中肯定要进行梯度计算,计算梯度时那些噪音点也会影响梯度的变化,因此进行去噪。

梯度和方向
使用sobel算子,进行梯度大小和方向的计算。
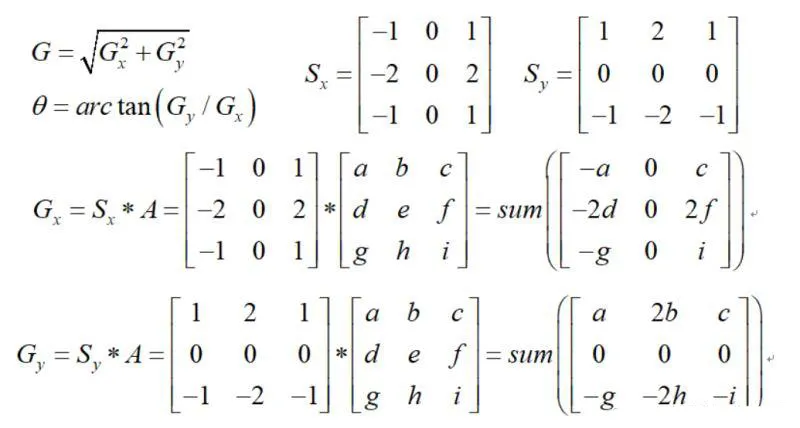
非极大值抑制 NMS
算完梯度后,有些可能大点,有些可能小点,在一个核中,把一些小的梯度值抑制掉,只保留大的,即明显的。
如人脸识别,能够把脸框起来(有多个框框到脸了,只保留最好的。)
法1:

蓝线表示方向,dTmp1和dTmp2都是亚像素点,g1g2g3g4都是知道的,可求dTmp1和dTmp2。在c比dTmp1和dTmp2都大的情况下,保留c,否则就被抑制掉了。
法2:
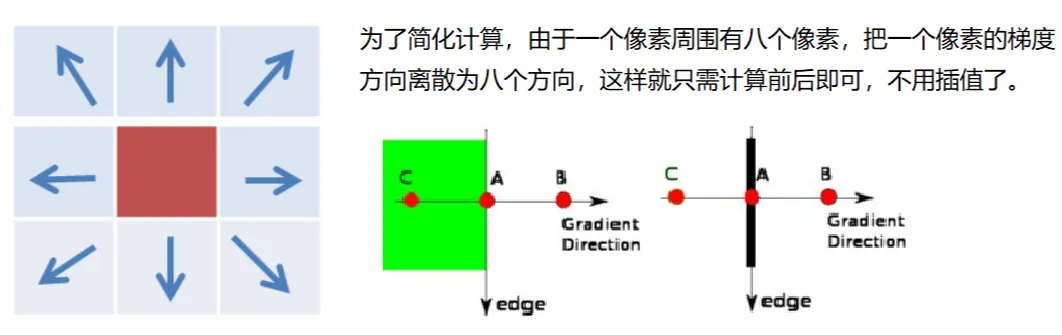
比如我们选择倾斜45°,就过了g1和g4了(上上图),就不用插值了。当前方向离哪个角度近就用选择哪个。
右图中如果A比BC都大,那么A就保存下来了。
双阈值
对一些所有可能边界进行过滤,只保留最真实的。

A点大于maxVal 就是边界 如果有小于minVale的,那就省略掉。
他俩之间的B C分别进行讨论,如果c和边界是连着的,就保留。B没连着,舍弃。
v1=cv2.Canny(img,80,150)
80 150为下上阈值,一定范围内,下阈值越小,上阈值越小越容易被当作边缘。
| img=cv2.imread("./data/gd06.jpg",cv2.IMREAD_GRAYSCALE)
| v1=cv2.Canny(img,80,150)
| v2=cv2.Canny(img,50,100)
| res = np.hstack((v1,v2))
| cv_show('res',res)

| img=cv2.imread("./data/gd05.jpg",cv2.IMREAD_GRAYSCALE)
| v1=cv2.Canny(img,120,250)
| v2=cv2.Canny(img,50,100)
| res = np.hstack((v1,v2))
| cv_show('res',res)

二、 图像轮廓
上面说的是边缘,随便一个线段也能被检测成边缘。而轮廓是一个整体,正常是封闭的连在一起的。
2.1 轮廓收集
cv2.findContours(img,mode,method)
RETR_EXTERNAL :只检索最外面的轮廓;
RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中;
RETR_CCOMP:检索所有的轮廓,并将他们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界;
RETR_TREE:检索所有的轮廓,并重构嵌套轮廓的整个层次;(常用,推荐)
method:轮廓逼近方法
CHAIN_APPROX_NONE:以Freeman链码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)。
CHAIN_APPROX_SIMPLE:压缩水平的、垂直的和斜的部分,也就是,函数只保留他们的终点部分。
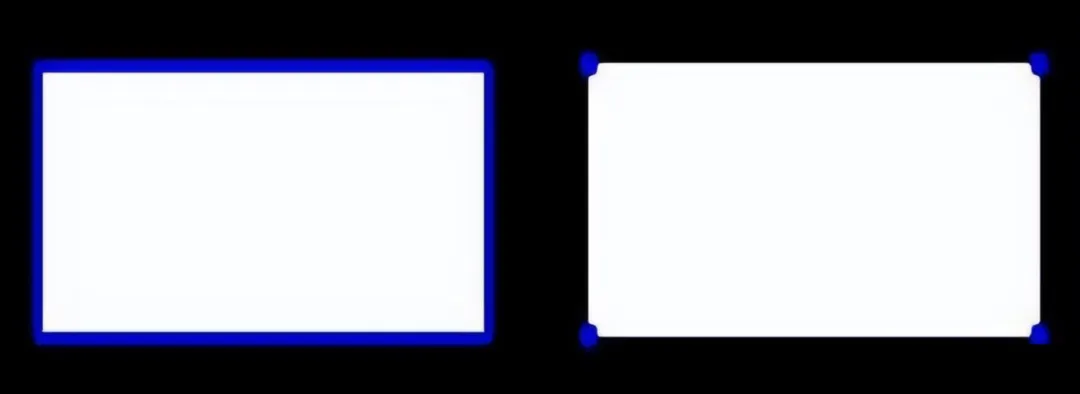
上图就是两种method,一个是整个框,一个是点,都能起到定位作用。
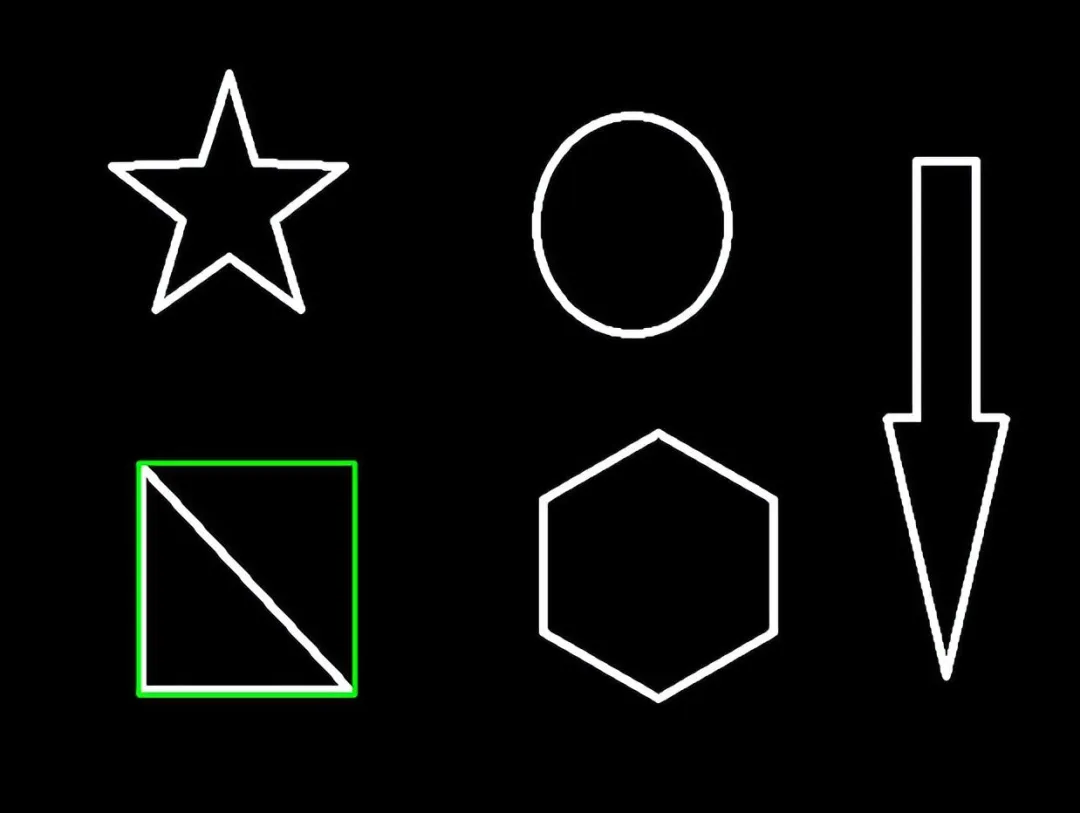
为了更高的准确率,我们选择使用二值图像:
| img = cv2.imread('contours.png')
| gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
| ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)# 127为分割阈值,超过的部分取255
| cv_show('thresh',thresh)
这里用到了cv2.threshold 是上一篇文章学的。
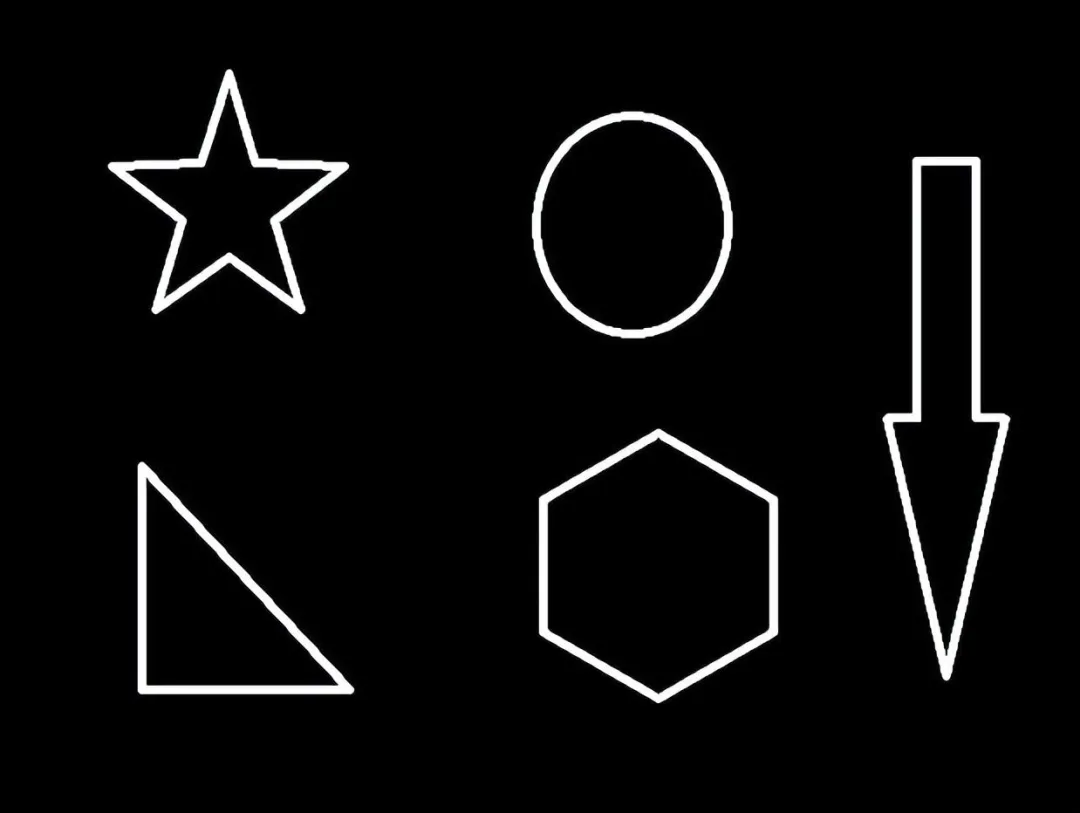
| # contours轮廓信息 hierarchy层级
| contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
其返回值有两个:
轮廓的信息:比如上面5个图案,10个边缘(内边缘外边缘),这10个边缘信息保存在了contours元组里。
层级:hierarchy 暂时用不上,用到了再说。
2.2 轮廓绘制
res = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 2)
参数为:图像,轮廓,轮廓索引(-1默认所有),颜色模式(BGR),线条厚度(不宜太大)
| img = cv2.imread('contours.png')
| gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
| ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)# 127为分割阈值,超过的部分取255
|
| # contours轮廓信息 hierarchy层级
| contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
|
| #传入 图像,轮廓,轮廓索引(-1默认所有),颜色模式(BGR),线条厚度(不宜太大)
| # 注意需要copy,不然原图会变。。。
| draw_img = img.copy()
| res = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 2)
| cv_show('res',res)
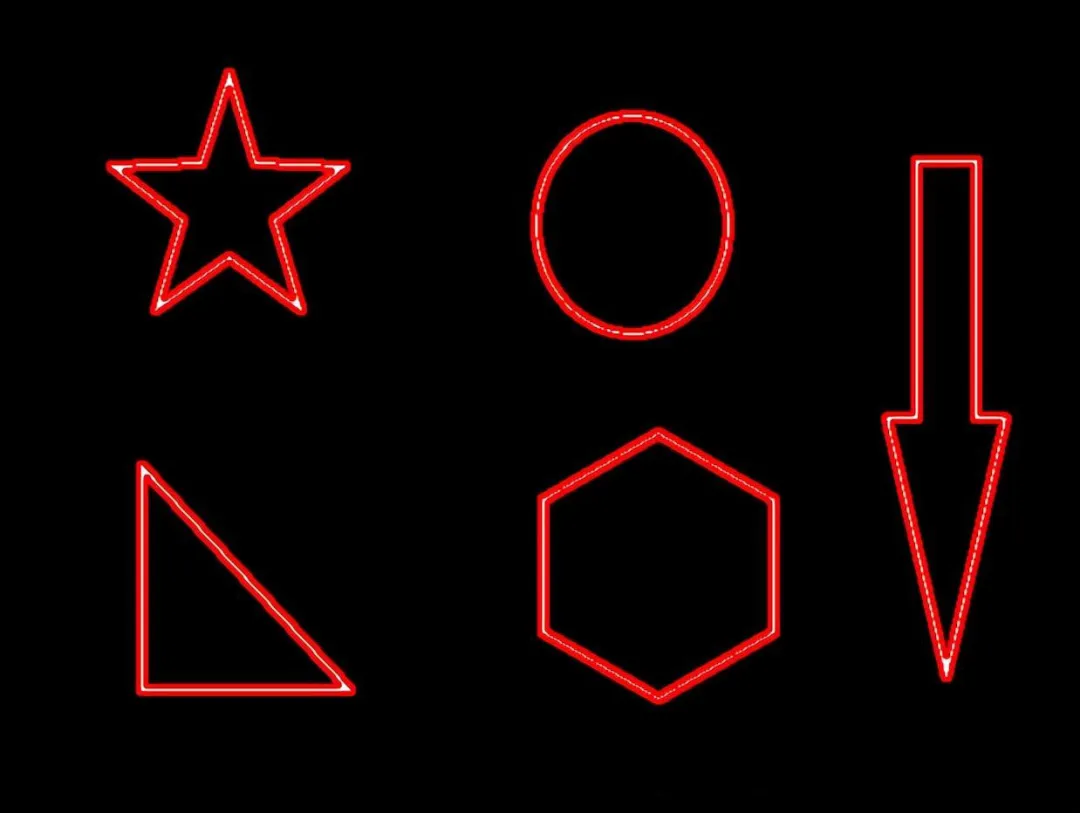
仔细看它把10个(内外)轮廓都画出来了,这与我们传入的参数 -1 有关。
当然我们也可以选择其中某个:
| draw_img = img.copy()
| # 三角的外轮廓
| res = cv2.drawContours(draw_img, contours, 0, (0, 0, 255), 2)
| cv_show('res',res)
| draw_img = img.copy()
| # 三角的内轮廓
| res = cv2.drawContours(draw_img, contours, 1, (0, 0, 255), 2)
| cv_show('res',res)
| draw_img = img.copy()
| # 六边形外轮廓
| res = cv2.drawContours(draw_img, contours, 2, (0, 0, 255), 2)
| cv_show('res',res)
2.3 轮廓特征
这里就介绍个周长和面积吧,后面用到别的再说。
| cnt = contours[0] # 第0个轮廓 三角的外轮廓
| #周长,True表示轮廓是闭合的
| cv2.arcLength(cnt,True) # 8500.5
| #面积
| cv2.contourArea(cnt) # 437.9482651948929
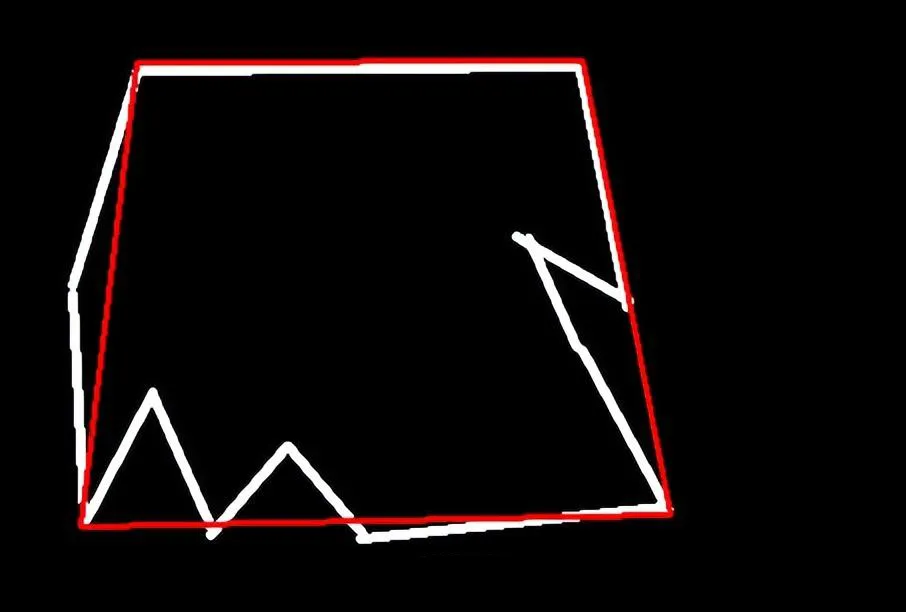
2.4 轮廓近似
什么是轮廓近似呢,比如下图左侧图案很麻烦,我们可以把它近似看成右边的,就是轮廓近似。

这个的原理其实也很简单,我发挥我的绘画功能给你们展示一下:
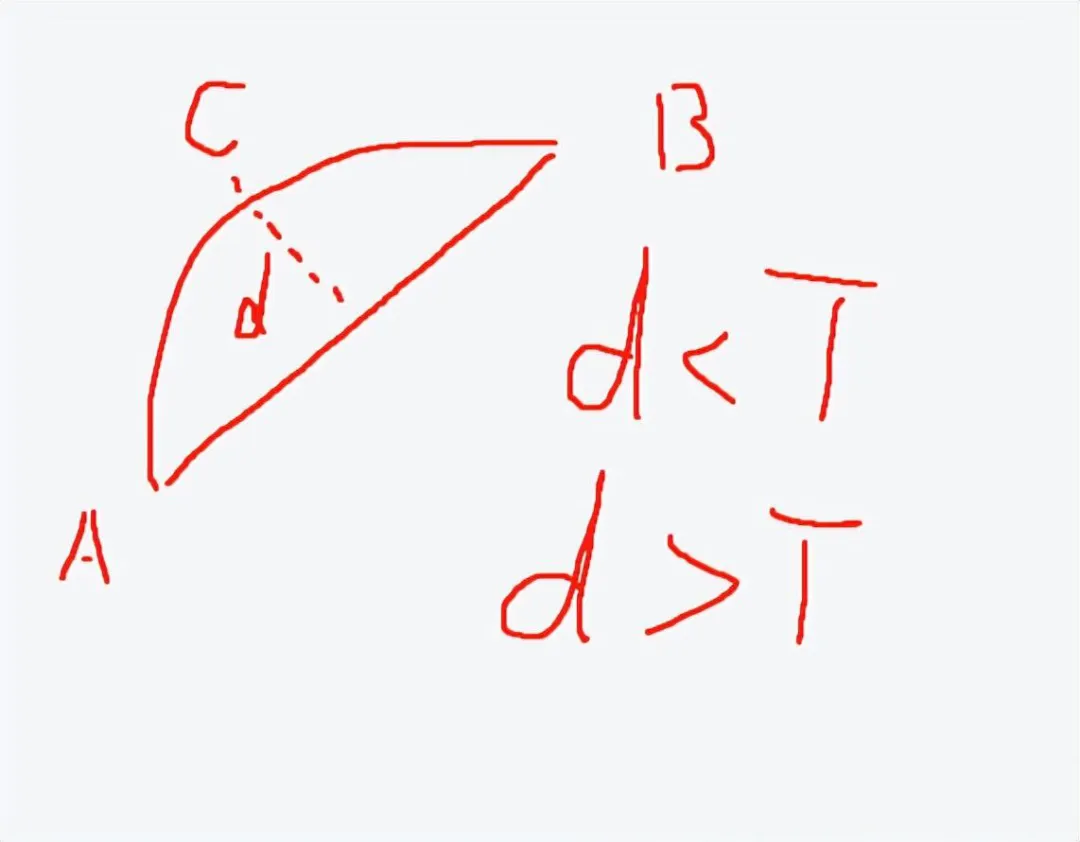
把曲线AB近似成直线AB,至于要d
我们近似一下下图:

边缘绘制:
| img = cv2.imread('contours2.png')
| gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
| ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
|
| contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
| cnt = contours[0]
|
| draw_img = img.copy()
| res = cv2.drawContours(draw_img, [cnt], -1, (0, 0, 255), 2)
| cv_show('res',res)

| epsilon = 0.02*cv2.arcLength(cnt,True) # 周长百分比 0.02
|
| # 参数:轮廓 阈值,一般用周长百分比
| # 返回:轮廓
| approx = cv2.approxPolyDP(cnt,epsilon,True)
|
| draw_img = img.copy()
| res = cv2.drawContours(draw_img, [approx], -1, (0, 0, 255), 2)
| cv_show('res',res)
approx = cv2.approxPolyDP(cnt,epsilon,True)
参数:轮廓 阈值,一般用周长百分比
返回:轮廓

把阈值变大一点:
| epsilon = 0.1*cv2.arcLength(cnt,True)
| approx = cv2.approxPolyDP(cnt,epsilon,True)
|
| draw_img = img.copy()
| res = cv2.drawContours(draw_img, [approx], -1, (0, 0, 255), 2)
| cv_show('res',res)
2.5 外接图形
| img = cv2.imread('contours.png')
|
| gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
| ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
| # binary,
| contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
| cnt = contours[0]
|
| # 外接矩形 得到x,y,w,h就能把矩形画出来了
| x,y,w,h = cv2.boundingRect(cnt)
| img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
| cv_show('img',img)
x,y,w,h = cv2.boundingRect(cnt)
三、图像金字塔
3.1 高斯金字塔
高斯金字塔:向下采样(缩小)

上面金字塔最底层44 往上一层变成22 长宽变为原来一半面积变为原来1/4,去除所有偶数行和列就是为了这一操作。
高斯金字塔:向上采样(扩大)
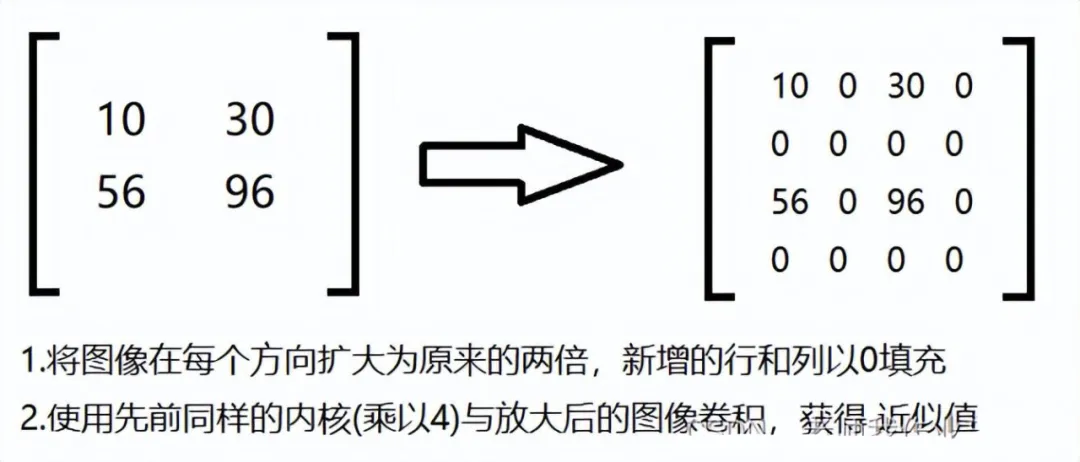
用0填充后,用卷积核把那几个值分布在0上,获得近似值。
| img=cv2.imread("./data/gd01.jpg")
| cv_show('img',img)
|
| up=cv2.pyrUp(img)
| cv_show('up',up)
|
| up2=cv2.pyrUp(up)
| cv_show('up2',up2)
|
| down=cv2.pyrDown(img)
| cv_show('down',down)
上面其实就是图片的放大与缩小。
下面要注意,缩小放大后的图片会变得模糊,毕竟之前我们是用0填充,卷积核计算获得的近似值。
| # 先扩大后缩小后,由于当时是用0填充的,会损失信息。
| up=cv2.pyrUp(img)
| up_down=cv2.pyrDown(up)
| # 显然变得模糊了
| cv_show('up_down',np.hstack((img,up_down)))

明显右边模糊了,我们把两张图片做个差值:
| # 做差就能看出区别
| up=cv2.pyrUp(img)
| up_down=cv2.pyrDown(up)
| cv_show('img-up_down',img-up_down)

这就是不同的部分。
3.2 拉普拉斯金字塔
和上面最后缩小放大后的图片一样,拉普拉斯这个每一层都是 原始-缩小(放大了的图片) 第二层用第一层的结果去减了。
| down=cv2.pyrDown(img)
| down_up=cv2.pyrUp(down)
| l_1=img-down_up
| cv_show('l_1',l_1)

四、直方图
4.1 像素直方图绘制
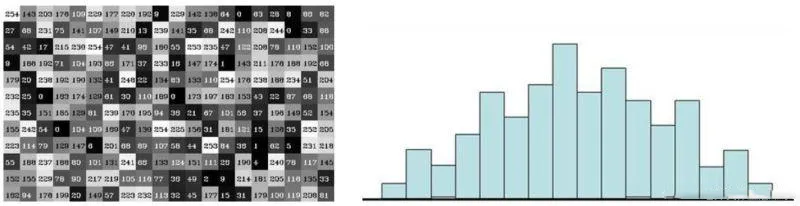
左侧灰度图像素点 右侧像素点直方图
cv2.calcHist(images,channels,mask,histSize,ranges)
images: 原图像图像格式为 uint8 或 float32。当传入函数时应 用中括号 [] 括来例如[img]
channels: 同样用中括号括来它会告函数我们统幅图像的直方图。如果入图像是灰度图它的值就是 [0]如果是彩+ 色图像 的传入的参数可以是 [0][1][2] 它们分别对应着 BGR。
mask: 掩模图像。统计整幅图像的直方图就mask = None。但是如果你想统计图像某一分的直方图的你就制作一个掩模图像并使用它。
histSize:BIN 的数目。也应用中括号括来如0-10是一个柱子 11-20是一个柱
ranges: 像素值范围常为 [0256]
| img = cv2.imread('./data/gd01.jpg',0) #0表示灰度图
| hist = cv2.calcHist([img],[0],None,[256],[0,256])
| plt.hist(img.ravel(),256);
| plt.show()
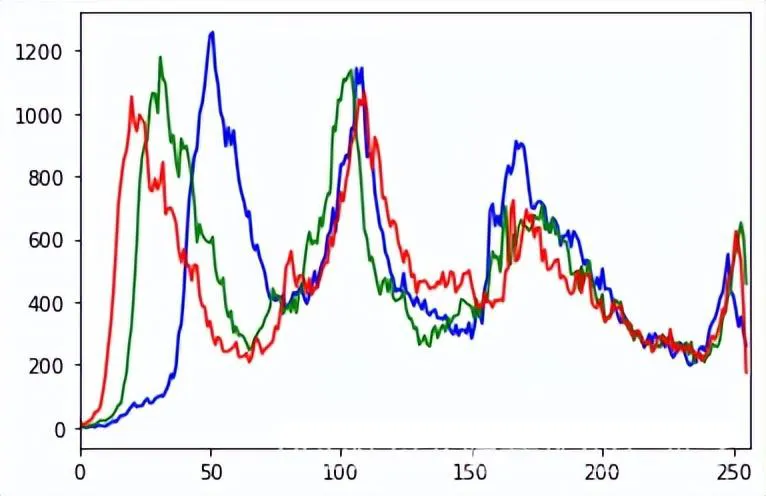
| img = cv2.imread('./data/gd01.jpg')
| color = ('b','g','r')
| for i,col in enumerate(color):
||histr = cv2.calcHist([img],[i],None,[256],[0,256])
| plt.plot(histr,color = col)
| plt.xlim([0,256])
mask操作
我们取一小块区域,然后获得图片中这一块区域的图像
| # 创建mast
| mask = np.zeros(img.shape[:2], np.uint8)
| print (mask.shape)
| mask[100:300, 100:400] = 255
| cv_show('mask',mask)

| masked_img = cv2.bitwise_and(img, img, mask=mask)#与操作
| cv_show('masked_img',masked_img)

| hist_full = cv2.calcHist([img], [0], None, [256], [0, 256])
| hist_mask = cv2.calcHist([img], [0], mask, [256], [0, 256])
| plt.subplot(221), plt.imshow(img, 'gray')
| plt.subplot(222), plt.imshow(mask, 'gray')
| plt.subplot(223), plt.imshow(masked_img, 'gray')
| plt.subplot(224), plt.plot(hist_full), plt.plot(hist_mask)
| plt.xlim([0, 256])
| plt.show()

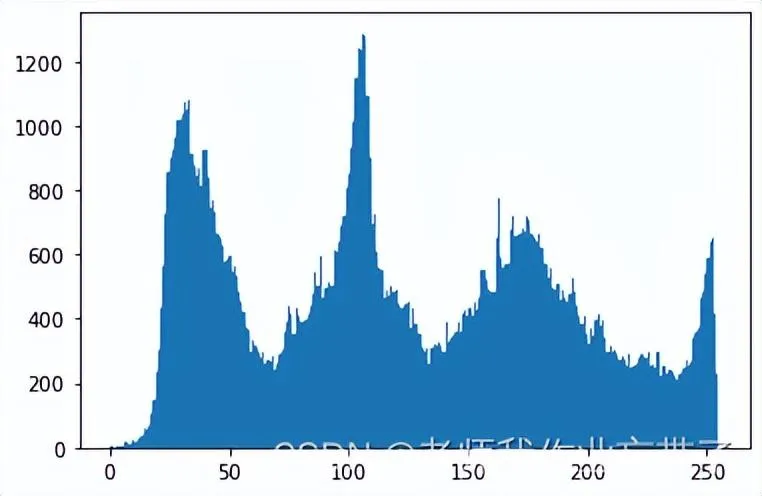
4.2 直方图均衡化


如上图,像素点都集中在一个地方,我们在不破坏其特征的前提下让高瘦的分布变得矮胖一点,亮度什么的也就都会发生些变化。
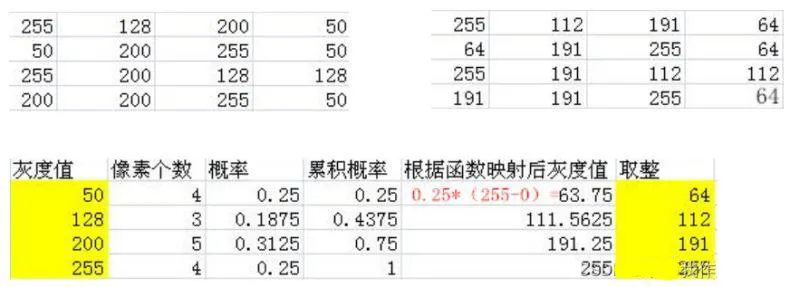
注:这里的映射是 累积概率*取值范围(255-0)
| img = cv2.imread('./data/gd01.jpg',0) #0表示灰度图 #clahe
| plt.hist(img.ravel(),256);
| plt.show()
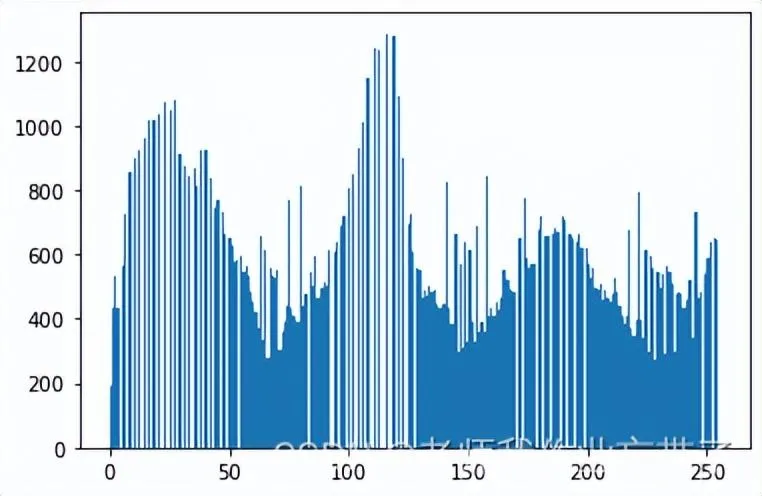
| equ = cv2.equalizeHist(img)
| plt.hist(equ.ravel(),256)
| plt.show()
| res = np.hstack((img,equ))
| cv_show('res',res)

图片比之前亮一些了。
4.3 自适应直方图均衡化
| clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
| res_clahe = clahe.apply(img)
| res = np.hstack((img,equ,res_clahe))
| cv_show('res',res)

五、傅里叶变换
我们生活在时间的世界中,早上7:00起来吃早饭,8:00去挤地铁,9:00开始上班...
以时间为参照就是时域分析,但是在频域中一切都是静止的!
傅里叶变换的作用
高频:变化剧烈的灰度分量,例如边界
低频:变化缓慢的灰度分量,例如一片大海
滤波
低通滤波器:只保留低频,会使得图像模糊
高通滤波器:只保留高频,会使得图像细节增强
opencv中主要就是cv2.dft()和cv2.idft(),输入图像需要先转换成np.float32 格式
得到的结果中频率为0的部分会在左上角,通常要转换到中心位置,通过shift变换。
cv2.dft()返回的结果是双通的(实部,虚部),通常还需要转换成图像格式才能展示(0,255)。
| import numpy as np
| import cv2
| from matplotlib import pyplot as plt
| img = cv2.imread('./data/gd06.jpg',0)
| img_float32 = np.float32(img)
| dft = cv2.dft(img_float32, flags = cv2.DFT_COMPLEX_OUTPUT)
| dft_shift = np.fft.fftshift(dft)
| magnitude_spectrum = 20*np.log(cv2.magnitude(dft_shift[:,:,0],dft_shift[:,:,1]))
| plt.subplot(121),plt.imshow(img, cmap = 'gray')
| plt.title('Input Image'), plt.xticks([]), plt.yticks([])
| plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
| plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
| plt.show()

| img = cv2.imread('./data/gd06.jpg',0)
| img_float32 = np.float32(img)
| dft = cv2.dft(img_float32, flags = cv2.DFT_COMPLEX_OUTPUT)
| dft_shift = np.fft.fftshift(dft)
| rows, cols = img.shape
| crow, ccol = int(rows/2) , int(cols/2) # 中心位置
| # 低通滤波
| mask = np.zeros((rows, cols, 2), np.uint8)
| mask[crow-30:crow+30, ccol-30:ccol+30] = 1
| # IDFT
| fshift = dft_shift*mask
| f_ishift = np.fft.ifftshift(fshift)
| img_back = cv2.idft(f_ishift)
| img_back = cv2.magnitude(img_back[:,:,0],img_back[:,:,1])
| plt.subplot(121),plt.imshow(img, cmap = 'gray')
| plt.title('Input Image'), plt.xticks([]), plt.yticks([])
| plt.subplot(122),plt.imshow(img_back, cmap = 'gray')
| plt.title('Result'), plt.xticks([]), plt.yticks([])
| plt.show()

| img = cv2.imread('./data/gd06.jpg',0)
| img_float32 = np.float32(img)
| dft = cv2.dft(img_float32, flags = cv2.DFT_COMPLEX_OUTPUT)
| dft_shift = np.fft.fftshift(dft)
| rows, cols = img.shape
| crow, ccol = int(rows/2) , int(cols/2) # 中心位置
| # 高通滤波
| mask = np.ones((rows, cols, 2), np.uint8)
| mask[crow-30:crow+30, ccol-30:ccol+30] = 0
| # IDFT
| fshift = dft_shift*mask
| f_ishift = np.fft.ifftshift(fshift)
| img_back = cv2.idft(f_ishift)
| img_back = cv2.magnitude(img_back[:,:,0],img_back[:,:,1])
| plt.subplot(121),plt.imshow(img, cmap = 'gray')
| plt.title('Input Image'), plt.xticks([]), plt.yticks([])
| plt.subplot(122),plt.imshow(img_back, cmap = 'gray')
| plt.title('Result'), plt.xticks([]), plt.yticks([])
| plt.show()

六、模板匹配
模板匹配和卷积原理很像,模板在原图像上从原点开始滑动,计算模板与(图像被模板覆盖的地方)的差别程度,这个差别程度的计算方法在opencv里有6种,然后将每次计算的结果放入一个矩阵里,作为结果输出。
假如原图形是AxB大小,而模板是axb大小,则输出结果的矩阵是(A-a+1)x(B-b+1)
| img = cv2.imread('./data/gd04.jpg', 0)
| template = cv2.imread('./data/gd_face.jpg', 0)
| h, w = template.shape[:2]

它们的关系就是(A-a+1)x(B-b+1)
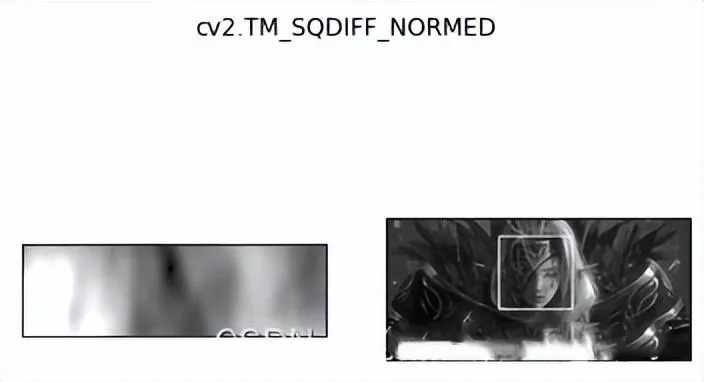
res = cv2.matchTemplate(img, template, cv2.TM_SQDIFF)
TM_SQDIFF:计算平方不同,计算出来的值越小,越相关
TM_CCORR:计算相关性,计算出来的值越大,越相关
TM_CCOEFF:计算相关系数,计算出来的值越大,越相关
TM_SQDIFF_NORMED:计算归一化平方不同,计算出来的值越接近0,越相关
TM_CCORR_NORMED:计算归一化相关性,计算出来的值越接近1,越相关
TM_CCOEFF_NORMED:计算归一化相关系数,计算出来的值越接近1,越相关
| methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
| 'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
| res = cv2.matchTemplate(img, template, cv2.TM_SQDIFF)
| # res.shape 为(139, 458)
| # 最小值最大值及其坐标位置 因为用的cv2.TM_SQDIFF 所以越小越好
| min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)

比如我要用到的图像和脸:


| for meth in methods:
| img2 = img.copy()
| # 匹配方法的真值
| method = eval(meth)
| print (method)
| res = cv2.matchTemplate(img, template, method)
| min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
| # 如果是平方差匹配TM_SQDIFF或归一化平方差匹配TM_SQDIFF_NORMED,取最小值
| if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
| top_left = min_loc
| else:
| top_left = max_loc
| bottom_right = (top_left[0] + w, top_left[1] + h)
| # 画矩形
| cv2.rectangle(img2, top_left, bottom_right, 255, 2)
| plt.subplot(121), plt.imshow(res, cmap='gray')
| plt.xticks([]), plt.yticks([]) # 隐藏坐标轴
| plt.subplot(122), plt.imshow(img2, cmap='gray')
| plt.xticks([]), plt.yticks([])
| plt.suptitle(meth)
| plt.show()





匹配多个对象
能匹配一个当然也能匹配多个:
| img_rgb = cv2.imread('./data/mario.jpg')
| img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
| template = cv2.imread('./data/mario_coin.jpg', 0)
| h, w = template.shape[:2]
| res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
| threshold = 0.8
| # 取匹配程度大于%80的坐标
| loc = np.where(res >= threshold)
| for pt in zip(*loc[::-1]): # *号表示可选参数
| bottom_right = (pt[0] + w, pt[1] + h)
| cv2.rectangle(img_rgb, pt, bottom_right, (0, 0, 255), 2)
| cv2.imshow('img_rgb', img_rgb)
| cv2.waitKey(0)

匹配金币:


申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


