本文来自“GPU深度报告:英伟达GB200 NVL72全互联技术,铜缆方案或将成为未来趋势?”。英伟达发布全新 Blackwell 平台,GPU 架构搭载六项变革型加速计算技术,将助推数据处理、工程模拟、电子设计自动化、计算机辅助药物设计、量子计算和生成式 AI 等领域实现突破。Blackwell架构的 GPU 包含 2080 亿个晶体管,TSMC 4NP 工艺制造,两片裸片通过单个 GPU 以 10TB/s 的速度互联。国产AI算力行业报告:浪潮汹涌,势不可挡(2024)2024中国“百模大战”竞争格局分析报告(2024)AI算力研究:英伟达B200再创算力奇迹,液冷、光模块持续革新
英伟达官宣新一代Blackwell架构,华为算力GPU需求破百万片GPU深度报告:英伟达GB200 NVL72全互联技术,铜缆方案或将成为未来趋势?英伟达发布新一代GPU架构,NVLink连接技术迭代升级
大模型语言模型:从理论到实践
技术展望2024:AI拐点,重塑人类潜力
大视研究:中国人工智能(AI)2024各行业应用研究报告英伟达GTC专题:新一代GPU、具身智能和AI应用
2024年策略:AI鼎新,与时偕行
《半导体行业深度报告合集(2024)》
《AI应用专题系列合集》
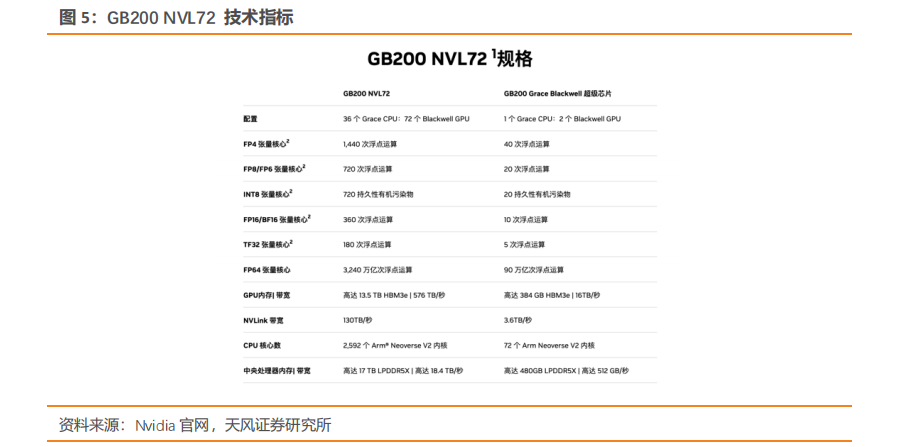
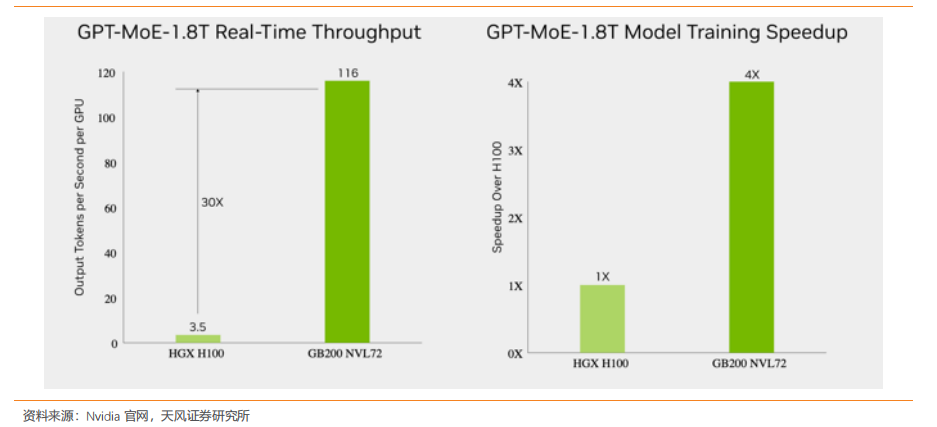
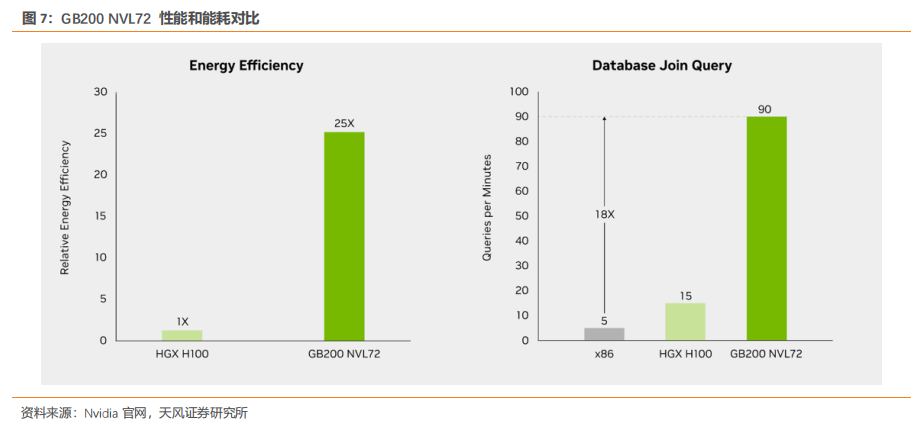
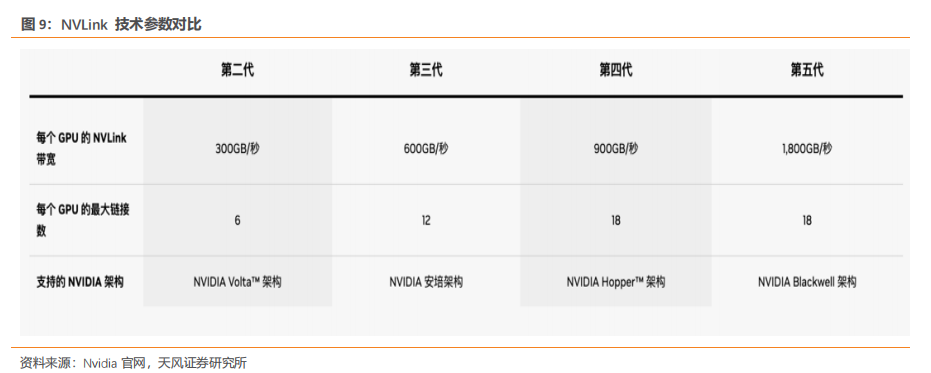
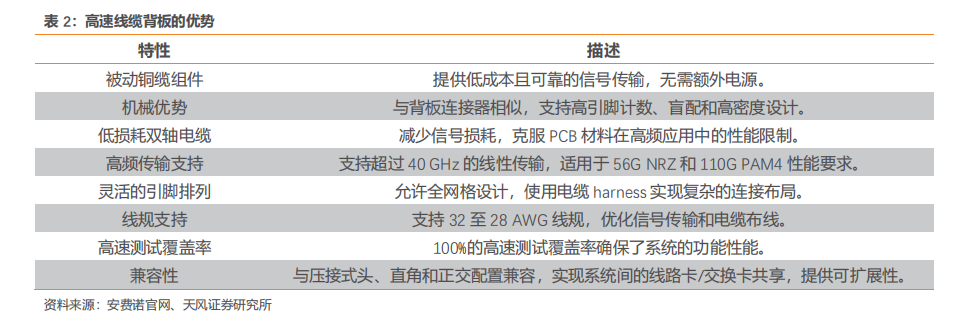
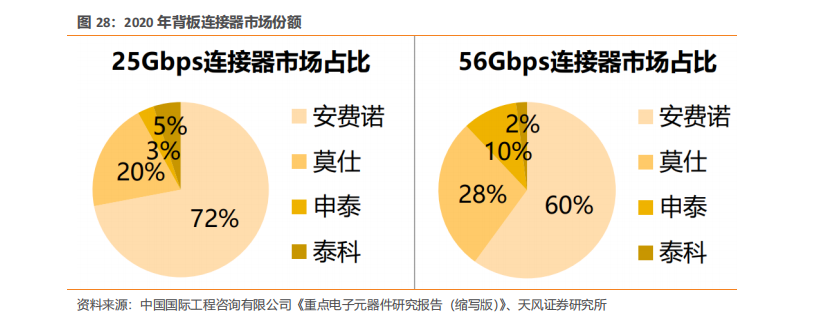
1. HGX B200 训练性能提升三倍,推理能力提升 15 倍NVIDIA HGX B200 和 HGX B100 集成了 NVIDIA Blackwell Tensor Core GPU 与高速互连技术,基于 Blackwell 的 HGX 系统在推理性能上相比前代实现了 15 倍的提升。对于大规模模型如 GPT-MoE-1.8T,HGX B200 的推理性能比上一代 NVIDIA Hopper™ 高出 15 倍。通过采用第二代 Transformer 引擎、定制的 Blackwell Tensor Core 技术、TensorRT™-LLM 和 Nemo™ 框架的创新,显著加速了大型语言模型(LLM)和专家混合(MoE)模型的推理过程。第二代 Transformer 引擎采用 8 位浮点(FP8)和新的精度等技术,能够将大型语言模型如 GPT-MoE-1.8T 的训练速度提高 3 倍。此外,得益于具有1.8TB/s GPU 到 GPU 互连速度的第五代 NVLink、InfiniBand 网络和 NVIDIA MagnumIO™ 软件的支持,这些技术共同保证了企业和广泛 GPU 计算集群的高效可扩展性。2. GB200 训练性能提升至 4 倍,推理能力提升至 30 倍GB200 NVL72 ,解锁实时万亿参数模型,为万亿参数的大型语言模型(LLM)推理提供了 30 倍的实时速度提升。GB200 NVL 72 通过其机架级设计,连接 36 个 Grace CPU 和72 个 Blackwell GPU,为数据中心提供前所未有的计算能力。NVIDIA GB200 NVL72 的核心,GB200 Grace Blackwell Superchip,采用 NVIDIA NVLink-C2C 互连技术,将两个高性能 NVIDIA Blackwell Tensor Core GPU 与一个 NVIDIA Grace CPU 连接,实现高效的计算协同。GB200 NVL72 同时集成了尖端功能和第二代 Transformer 引擎,利用第五代NVIDIA NVLink,支持 FP4 AI 精度。GB200 NVL72 大幅提升大规模训练速度,最新 GB200 NVL72 包含更快的第二代Transformer 引擎,具有 FP8 精度,能够将大型语言模型的大规模训练速度提升 4 倍。得益于每秒 1.8TB 的 GPU 到 GPU 互连速度、InfiniBand 网络和 NVIDIA Magnum IO软件的第五代 NVLink 技术,实现了显著的性能提升。GB200 NVL72 采用的液体冷却技术不仅提升了计算密度,减少了占地面积,而且通过高带宽、低延迟的 GPU 通信,显著减少了数据中心的碳足迹和能源消耗。与传统的 NVIDIA H100 风冷基础设施相比,GB200在相同功耗下实现了 25 倍的性能提升,同时降低了水消耗。GB200 利用 NVIDIABlackwell 架构的高带宽内存性能、NVLink-C2C 以及专用解压缩引擎,大幅提高了关键数据库查询的速度,相比 CPU 提升了 18 倍,并将总体拥有成本(TCO)降低了 5 倍,为企业处理、分析大量数据提供了强大的支持。3. 第五代 NVLink GPU 为百亿亿次计算和万亿参数模型提供基础NVIDIA 推出世界首个高速 GPU 互连技术 NVLink,提供的速度远超基于 PCIe 的解决方案,是多 GPU 系统扩展内存和性能的理想选择。它为处理最大视觉计算工作负载、释放百亿亿次计算能力和万亿参数人工智能模型的全部潜力提供了关键基础。NVLink 释放数万亿参数 AI 模型的加速性能,显著提升了大型多 GPU 系统的可扩展性。每个 NVIDIA Blackwell Tensor Core GPU 支持多达 18 个 NVLink 100 GB/秒的连接,带宽达到 1.8 TB/秒,是上一代产品的两倍,超过 PCIe Gen5 的十四倍以上。NVLink Switch 协同 NVLink 释放数据传输能力。NVLink Switch 通过连接多个 NVLink,实现了机架内和机架间全速度的 GPU 通信,这是一种 1.8TB/s 双向直接 GPU 到 GPU 互连技术,极大地扩展了服务器内多 GPU 的输入和输出能力。NVLink Switch 还配备NVIDIA 可扩展分层聚合和缩减协议(SHARP)™ 引擎,优化了网络内缩减和多播加速,进一步提高了通信效率。NVLink Switch 允许 NVLink 连接跨节点扩展,形成高带宽、多节点 GPU 集群,实际上创建了数据中心级的 GPU。在 NVL72 系统中,NVLink Switch 实现了 130TB/s 的 GPU 带宽,大大增强了大型模型的并行处理能力。这种设计使得多服务器集群可以随着计算量的增加而扩展 GPU 通信,支持的 GPU 数量是单个 8 个 GPU 系统的 9 倍。NVLink 和 NVLink Switch 作为 NVIDIA 数据中心解决方案的关键构建模块,整合了 NVIDIA AI Enterprise 软件套件和 NVIDIA NGC™ 目录中的硬件、网络、软件、库及优化的 AI 模型和应用程序。.4. 专为人工智能设计的数据中心 DGX SuperPODNVIDIA 发布专门设计用于训练和推理万亿参数生成式 AI 模型的数据中心,DGX SuperPOD™ ,通过配备 DGX GB200 系统。每个采用液冷技术的机架装备有 36 个NVIDIA GB200 Grace Blackwell Superchips,这些超级芯片集成了 36 个 NVIDIA GraceCPU 和 72 个 Blackwell GPU,并通过 NVIDIA NVLink 技术连接。DGX SuperPOD 可以通过 NVIDIA Quantum InfiniBand 连接多个机架,实现数万个 GB200 超级芯片的扩展,以支持大规模 AI 模型的训练和推理需求。它配备了智能控制平面,该平面能够追踪硬件、软件和数据中心基础设施中的数千个数据点,确保系统的连续运行、数据完整性,同时规划维护并自动重新配置集群以避免停机。配备的 DGX GB200 系统在每个 GB200 超级芯片中搭载了一个 Grace CPU 和两个 Blackwell GPU,这些组件通过第五代 NVLink 连接,实现了每秒 1.8TB(TB/s)的 GPU 到 GPU 带宽。这样的设计不仅优化了数据传输速度,还极大提高了处理效率,使 DGX SuperPOD 成为处理万亿参数生成 AI 模型的理想选择。5. NVL72 机架级系统支持万亿参数 LLM 训练和实时推理GB200 NVL72 的机架级设计,通过在单个 NVIDIA NVLink 域上连接 72 个 Blackwell GPU,标志着 AI 超级计算的一次重大进步。这种独特的配置显著减少了传统网络扩展时的通信开销,使得对 1.8T 参数的模型进行实时推理成为可能,同时将模型训练速度提升了 4 倍。借助 72 个 NVLink 连接的 Blackwell GPU 和 30 TB 的统一内存,在 130 TB/s的计算结构上运行,GB200 NVL72 在单个机架中创造了一个 exaFLOP 级别的 AI 超级计算平台。这种创新为处理最复杂的大型模型提供了前所未有的计算能力。GB200 NVL72 的 Blackwell 架构通过引入硬件解压缩引擎,具备大规模本地解压缩压缩数据能力,优化了端到端的分析管道。原生支持 LZ4、Deflate 和 Snappy 压缩格式,这一解压缩引擎加速了内存绑定的内核操作,提供了高达 800 GB/s 的性能。解压缩引擎的加入,结合高达 8 TB/s 的高内存带宽和 Grace CPU 的高速 NVLink 芯片到芯片(C2C)互连,显著加快了数据库查询过程。在查询基准测试中,Grace Blackwell 的执行速度比 CPU(Sapphire Rapids)快 18 倍,比 NVIDIA H100 Tensor Core GPU 快 6 倍。GB200 NVL72 的核心,NVIDIA GB200 Grace Blackwell 超级芯片,通过 NVLink C2C 接口连接,提供了 900 GB/s 的双向带宽,简化了编程过程,并支持了更大内存需求的万亿参数 LLM、变压器模型和大规模模拟模型。基于全新 NVIDIA MGX 设计的 GB200 计算托盘,包含两个 Grace CPU 和四个 Blackwell GPU,采用液体冷却技术,大幅降低了成本和能耗同时提供了 80 petaflops 的 AI 性能和 1.7 TB 的快速内存。6. 网络交换机 X800 系列,转为大规模 AI 设计NVIDIA Quantum-X800 平台代表了 NVIDIA Quantum InfiniBand 技术的最新进展,专门为处理万亿参数级别的 AI 模型设计。此平台汇集了 NVIDIA Quantum-X800 InfiniBand交换机、NVIDIA ConnectX®-8 SuperNIC 以及 LinkX 电缆和收发器,共同构成了一个强大的网络解决方案。NVIDIA Quantum-X800 InfiniBand 交换机具备 144 个端口,每个端口的连接速度高达800Gb/s,配备了 SHARP v4 的基于硬件的网内计算、自适应路由、基于遥测的拥塞控制、性能隔离功能以及支持统一结构管理器 (UFM) 的专用端口。此外,交换机还引入了高级的能效功能,如低功耗链路状态和功耗分析,旨在降低能源消耗并提高整体性能。NVIDIA ConnectX-8 SuperNIC 以 800Gb/s 的连接速度和超低延迟特性,支持最新的高级网络内计算技术。它继承了 ConnectX 架构的优势,提供加速的 MPI 硬件引擎、服务质量、自适应路由、拥塞控制等高级网络功能。NVIDIA Quantum-X800 平台的连接选项通过 NVIDIA LinkX互连产品组合提供了极大的灵活性,支持构建首选网络拓扑。无论是采用无源光纤电缆还是线性有源铜缆 (LACC),LinkX的连接式收发器都能满足高性能网络的需求。7、线缆解决方案成为未来趋势,线缆背板连接将有望成为主流Blackwell 微架构芯片 GB200,该芯片采取 NVLink 全互联技术,采用铜缆直连方案,实现芯片间的数据传输,可提高整体计算能力,满足人工智能和深度学习的需要。相对于光纤解决方案,铜缆解决方案具有成本低、布线便捷的优点,未来 AI 服务器使用铜缆直连技术或将成为主流。为满足设备厂商的需求,我们预计未来高速背板连接器将主要使用线缆连接方案,铜线需求有望将迅速增加。线缆背板技术已经存在 10 余年。最近从 10 Gbps 背板生态系统升级到 25 Gbps 及以上的背板生态系统让线缆背板技术成为适用于当今系统架构的理想解决方案。相较于 PCB 背板,线缆背板的优势是:华丰科技、中航光电等一批国内的高速背板供应商因此迅速成长起来,市场份额不断增加,打破了海外厂商的垄断局面。从最初的 1.25G开始提升,到 2007 年安费诺推出 20+G 产品,2012 年莫仕推出 56G 产品,2020 年以来国内厂商华丰 56G 产品逐渐进入量产。截至 2023 年 6 月,泰科、安费诺、莫仕等海外厂商112G 高速线缆背板产品进入量产阶段,部分国内厂商已完成小批量试制,有望近年进入量产。随着人工智能和机器学习的指数级增长,市场需求不断升级,未来 224G 的产品成为新的研发和竞争方向。
下载链接:
服务器行业深度报告:AI和“东数西算”双轮驱动,服务器再起航
AI时代的3D内容生产工具
复盘与未来推演(AI应用):追本溯源之后,我们相信什么?
深度研究:量子计算:人工智能与新质生产力的“未来引擎”
多模态,AI大模型新一轮革命
2024前沿人工智能安全的最佳实践
人工智能大模型工业应用准确性测评
2024 AI智算产业趋势展望分析报告
边缘智能:铺平人工智能的“最后一公里”
泛半导体产业黑灯工厂发展研究洞察白皮书
PCIe标准的演进和测试要求
《英伟达GTC 2024技术汇总》
1、英伟达GTC 2024主题演讲:见证AI的变革时刻
2、展望GTC变革,共享AI盛宴
3、英伟达GTC专题:新一代GPU、具身智能和AI应用
英伟达GTC专题:新一代GPU、具身智能和AI应用(精华)
2024年策略:AI鼎新,与时偕行
人工智能生成图像的危害分析与网络真实性保护(2024)
家庭大脑白皮书(2024):大模型时代智慧家庭应用新范式
《半导体行业深度报告合集(2024)》
《70+篇半导体行业“研究框架”合集》
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。