

点击上方蓝字谈思实验室
获取更多汽车网络安全资讯

01
GB200互联架构解析
1.1 NVLink带宽计算
英伟达在对NVLINK的传输带宽计算和对于SubLink/Port/Lane的概念上存在很多混淆的地方,通常单颗B200的NVLINK 5带宽是1.8TB/s,这是做计算的人算带宽通常按照内存带宽的算法以字节每秒(Byte/s)为单位。而在NVLink Switch上或者IB/Ethernet交换机和网卡上,是Mellanox的视角以网络带宽来计算的,通常是以传输的数据位为单位,即比特每秒(bit/s)。
详细解释一下NVLINK的计算方式,NVLINK 3.0开始由四个差分对构成一个"sub-link"(英伟达经常对它用Port/Link,定义有些模糊),这4对差分信号线同时包含了接收和发送方向的信号线,而通常在计算网络带宽时,一个400Gbps的接口是指的同时能够收发400Gbps的数据,如下图所示:
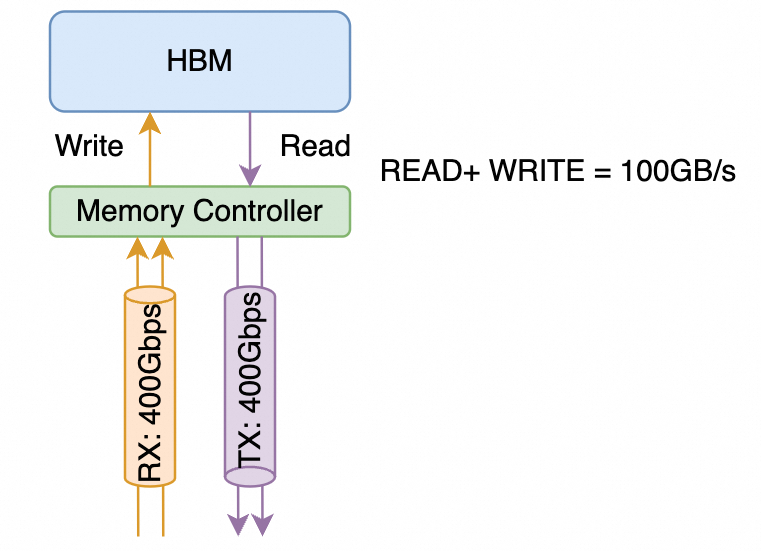
它总共由4对差分信号线构成RX/TX各两对,从网络的视角来看是一个单向400Gbps的链路,而从内存带宽的视角是支持100GB/s的访存带宽。
1.1.1 NVLINK 5.0 互联带宽
在Blackwell这一代采用了224G Serdes,即sub-link的传输速率为200Gbps * 4(4对差分线)/8 =100GB/s,从网络来看单向带宽为400Gbps。B200总共有18个sublink,因此构成了 100GB/s * 18 = 1.8TB/s的带宽,而从网络的视角来看等同于9个单向400Gbps的接口。同理,在NVSwitch的介绍中声明的是 Dual 200Gb/sec SerDes构成一个400Gbps的Port。

为了方便后文的叙述,我们对这些术语进行统一定义如下:
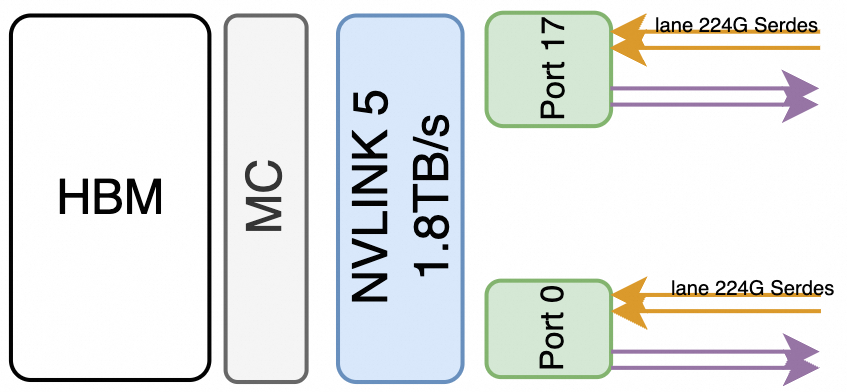
B200 NVLINK带宽为1.8TB/s,由18个Port构成,每个Port 100GB/s,由四对差分线构成,每个Port包含两组224Gbps的Serdes (2x224G PAM4 按照网络接口算为每端口单向400Gbps带宽)。
1.1.2 NVLINK 4.0 互联
我们再补充一下Hopper,在NVLINK 4.0中采用了112G Serdes,即单对差分信号线可以传输100Gbps,累计单个NVLINK的Sub-link构成4x100Gbps= 50GB/s,支持NVLINK 4.0的Hopper这一代产品有18个sub-link(port),则单个H100支持50GB/s * 18 = 900GB/s,单机8卡利用4个NVswitch连接,如下图所示:
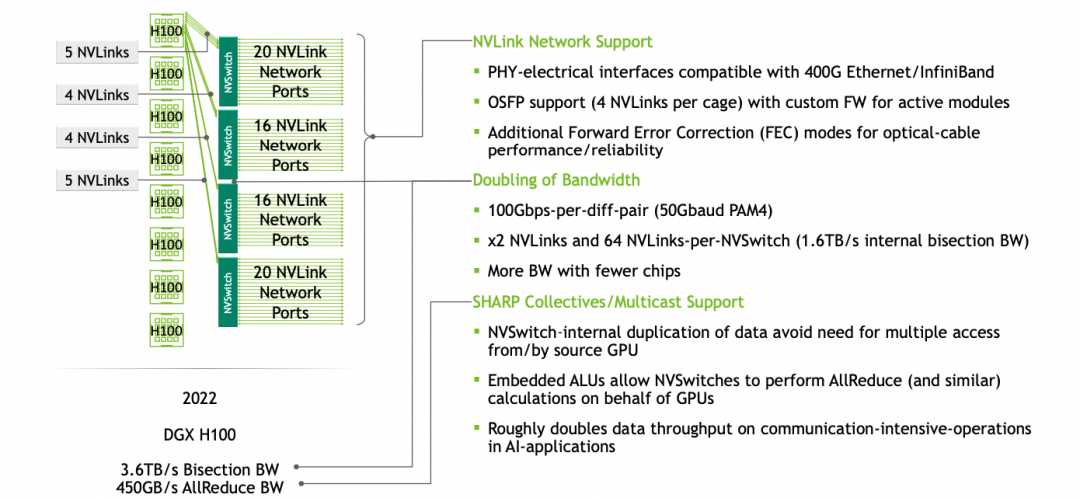
它还可以增加第二层交换机构成一个256卡的集群。

扩展接口采用OSFP的光模块。
如下图所示,OSFP光模块可以支持16对差分信号线, 因此单个OSPF支持4个NVLINK Port。
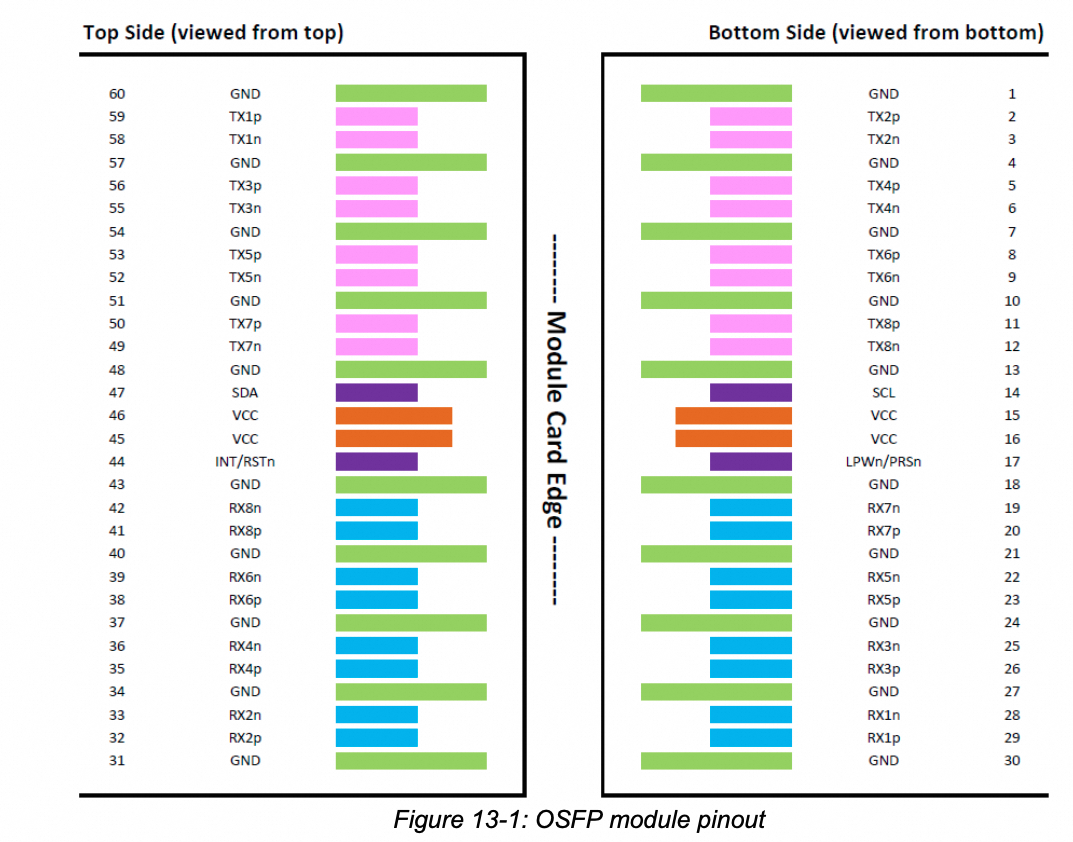
即下图中NVLink Switch包含32个OSFP光模块接口连接器,累计支持32 * 4 = 128个NVLINK4 Port。

1.2 GB200 NVL72
GB200 NVL72的Spec如下图所示,本文主要讨论NVLINK相关的问题。
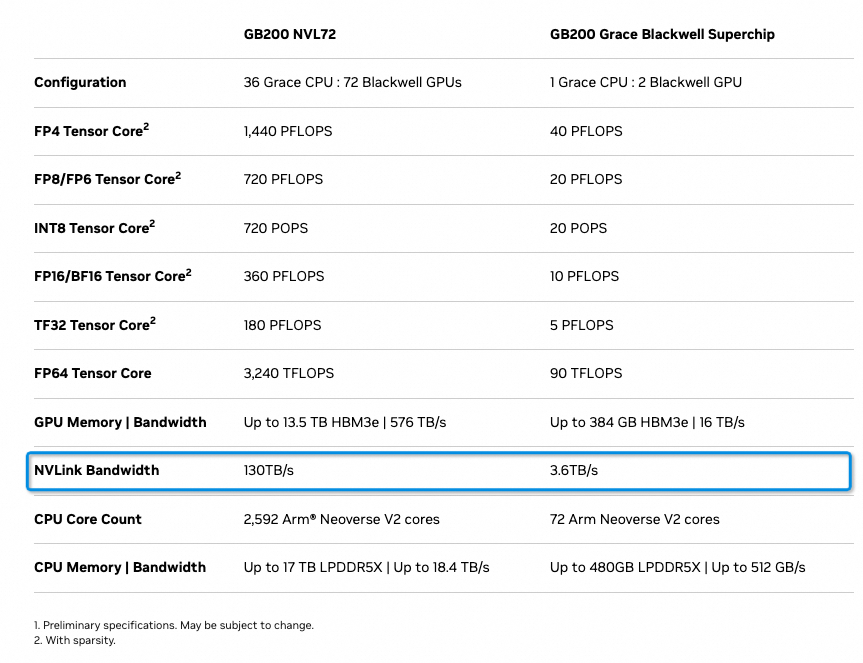
一个GB200包含一颗Grace 72核的ARM CPU和2颗Blackwell GPU。

整个系统由Compute Tray和Switch Tray构成,一个Compute Tray包含两颗GB200子系统,累计4颗Blackwell GPU。

一个Switch Tray则包含两颗NVLINK Switch芯片,累计提供72 * 2 = 144个NVLINK Port,单颗芯片结构如下,可以看到上下各36个Port,带宽为7.2TB/s,按照网络的算法是28.8Tbps的交换容量,相对于当今最领先的51.2Tbps交换芯片小一些,但是需要注意到它由于实现SHARP(NVLS)这样的功能导致的。

整个机柜支持18个Compute Tray和9个Switch Tray,因此构成了一个单机柜72个Blackwell芯片全互联的架构,即NVL72。

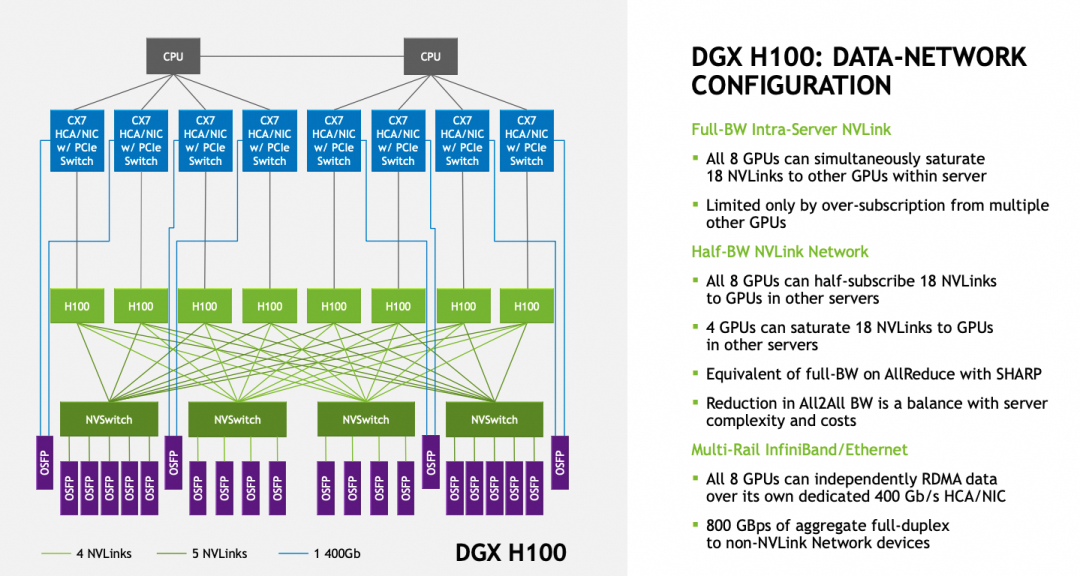
单个GB200子系统则包含2 * 18 = 36个NVLink5 Port,整个系统对外互联上并没有采用OSFP的光模块接口,而是直接通过一个后置的铜线背板连接,如下图所示:


关于光退铜进这些金融机构分析师的说法其实是片面的,Hopper那一代是考虑的相对松耦合的连接方式,导致这些分析师过分的夸大了光模块的需求。而且当时对机柜散热部署等要求更加灵活。而这一代是在单机柜内整柜子交付,属于类似于IBM大型机的交付逻辑,自然而然地就选择了铜背板,同时单个B200功耗更高,整机液冷交付同时还有功耗约束,从功耗的角度来看换铜也可以降低很多。
整个NVL72的互联拓扑如下所示:
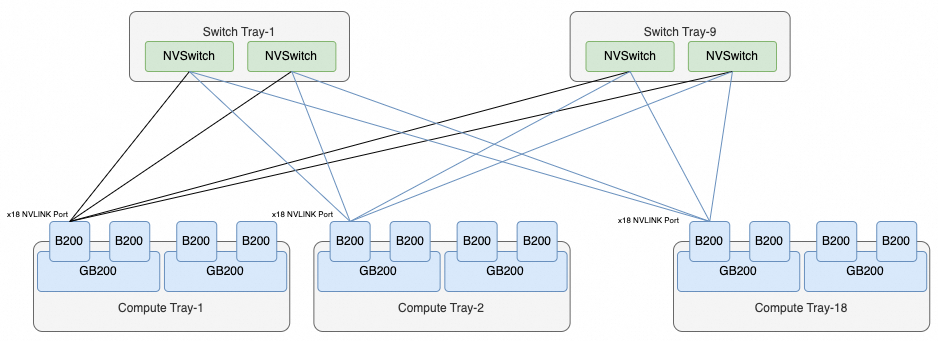
每个B200有18个NVLINK Port,9个Switch Tray刚好共计18颗NVLINK Swtich 芯片,因此每个B200的Port连接一个NVSwitch芯片,累计整个系统单个NVSwitch有72个Port,故整个机器刚好构成NVL72,把72颗B200芯片全部连接起来。
1.3 NVL576
我们注意到在NVL72的机柜中,所有的交换机已经没有额外的接口互联构成更大规模的两层交换集群了,从英伟达官方的图片来看,16个机柜构成两排,虽然总计正好72 * 8个机柜构成576卡集群的液冷方案,单是从机柜连接线来看,这些卡更多的是通过Scale-Out RDMA网络互联的,而并不是通过Scale-Up的NVLINK网络互联。
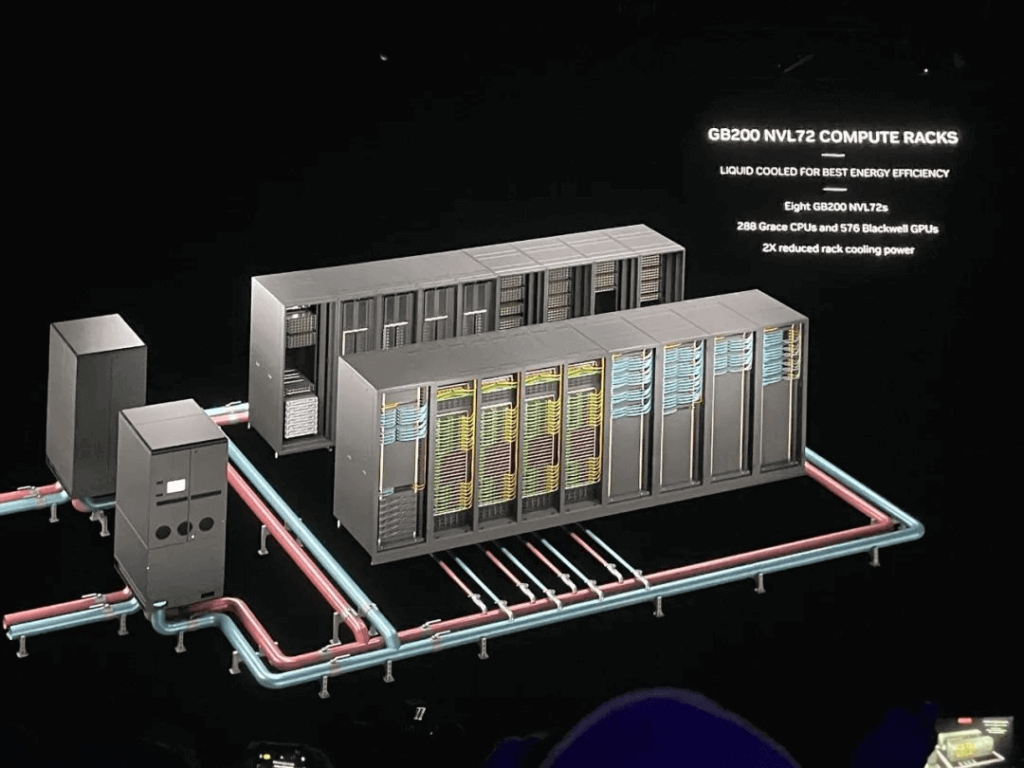
对于一个32,000卡的集群也是通过这样的NVL72的机柜,一列9个机柜,4个NVL72和5个网络机柜,两列18个机柜构成一个Sub-Pod,并通过RDMA Scale-Out网络连接。

当然这个并不是所谓的NVL576,如果需要支持NVL576则需要每72个GB200配置18个NVSwitch,这样单机柜就放不下了,事实上我们注意到官方有这样一段话:

官方说NVL72有单机柜版本,也有双机柜的版本,并且双机柜每个Compute Tray只有一个GB200子系统,另一方面我们注意到NVSwitch上有空余的铜缆接头,很有可能是为了不同的铜背板连接而特制的。

这些接口是不是会在铜互联背板上方再留一些OSFP Cage来用于第二层NVSwitch互联就不得而知了,但这样的方法有一个好处,单机柜的版本是Non-Scalable的,双机柜版本的是Scalable的,如下图所示:
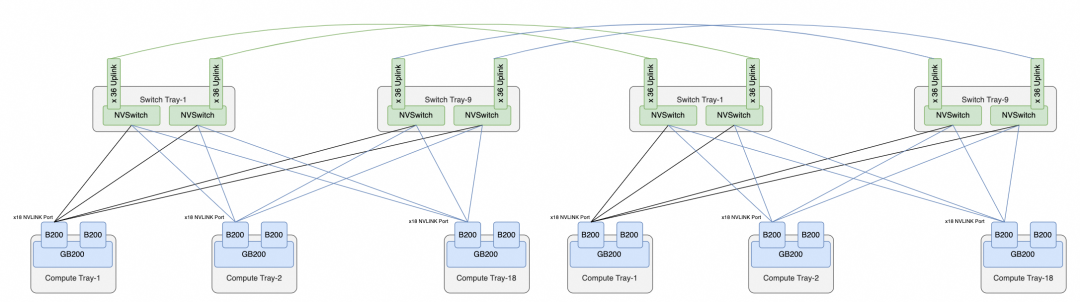
两个机柜的版本有18个NVSwitch Tray,可以背靠背互联构成NVL72.虽然交换机多了一倍,但是为以后扩展到576卡集群,每个交换机都提供了36个对外互联的Uplink,累计单个机柜有36 * 2 * 9 =648个上行端口,构成NVL576需要有16个机柜,则累计上行端口数为 648 * 16 = 10,368个,实际上可以由9个第二层交换平面构成,每个平面内又有36个子平面,由18个Switch Tray构成,NVL576的互联结构如下所示:
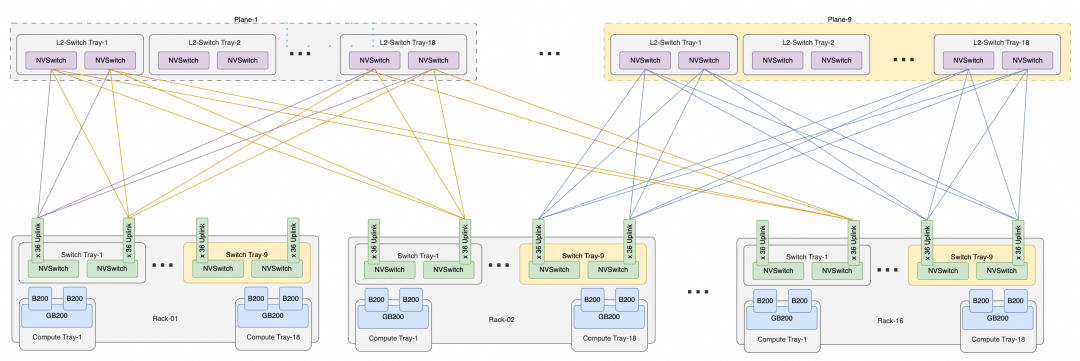
1.4 从业务视角看到NVL576
对于NVL576这样超大规模的单一NVLink Scale-Up组网是否真的有客户,我个人是持怀疑态度的,AWS也只选择了NVL72来提供云服务。主要的问题是2层组网的可靠性问题和弹性售卖的问题来看,NVL576并不是一个好的方案,系统复杂性太高。
这样的方案存在的价值和当年思科搞CRS-1 MultiChassis集群类似,当年思科也是弄了一个16卡单个机柜,累计可以通过8个8个交换矩阵机柜互联72个线卡机柜来构成一个超大规模系统。主要是需要在市场上留一个技术领先的flag/benchmark,最终这样大规模的理论存在的系统埋单的用户几乎没有。
另一方面是从下一代大模型本身的算力需求来看的,meta的论文《How to Build Low-cost Networks for Large Language Models (without Sacrificing Performance)?》[1]讨论过, 对于NVLink互联的Scale-Up网络,论文中将其称为一个(High Bandwidth Domain,HBD),对HBD内的卡的数目K进行了分析:
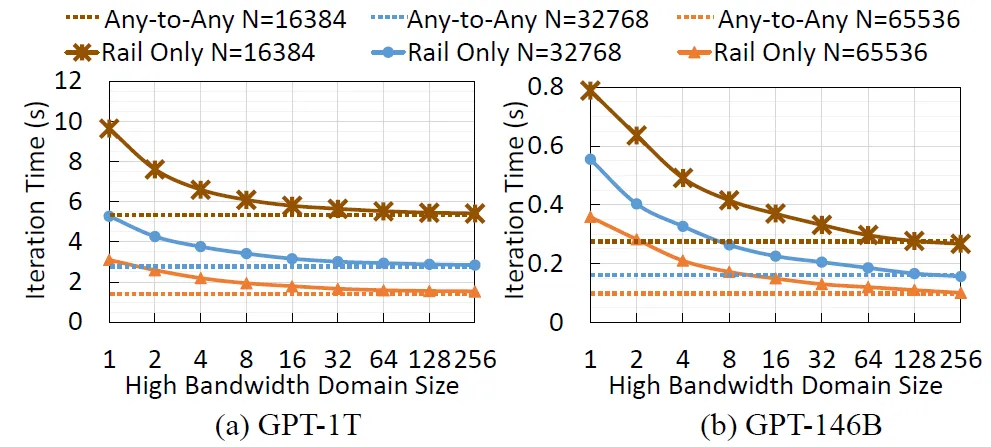
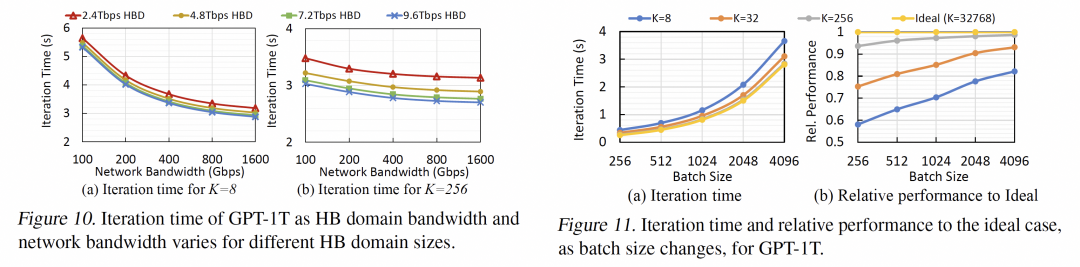
针对GPT-1T的模型来看,K=36以上时对性能提升相对于K=8还是很明显的,而对于K>72到K=576时的边际收益相对于系统的复杂性而言是得不偿失的,另一方面我们可以看到,当Scale-Up的NVLINK网络规模增大时,实际上HBD之间互联的RDMA带宽带来的性能收益在减小,最终的一个平衡就是通过NVL72并用RDMA Scale-Out来构建一个32,000卡的集群。
02
互联系统演进:思科的故事
2.1 算力/内存瓶颈带来的分布式架构
最早的时候,思科的路由器是采用单颗PowerPC处理器执行转发的。随着互联网的爆发,对于路由查表等访存密集型计算导致了性能瓶颈,因此逐渐出现了进程交换/CEF等多种方式,通过数据总线将多个处理器连接起来:
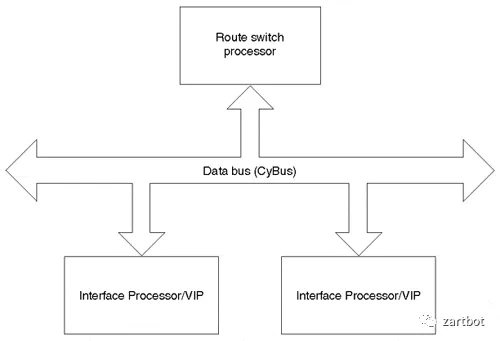
这些做法和早期的NVLINK 1.0 / NVLINK 2.0类似,例如Pascal那一代也是采用这种芯片间直接总线互联的方式。
2.2 交换矩阵出现
1995年的时候,Nick Mckeown在论文"Fast Switched Backplan for a Gigabit Switched Router"中提出使用CrossBar交换机构成一个背板来支撑更高规模的Gigabit级的路由器,即后来的Cisco 12000系列高端路由器。
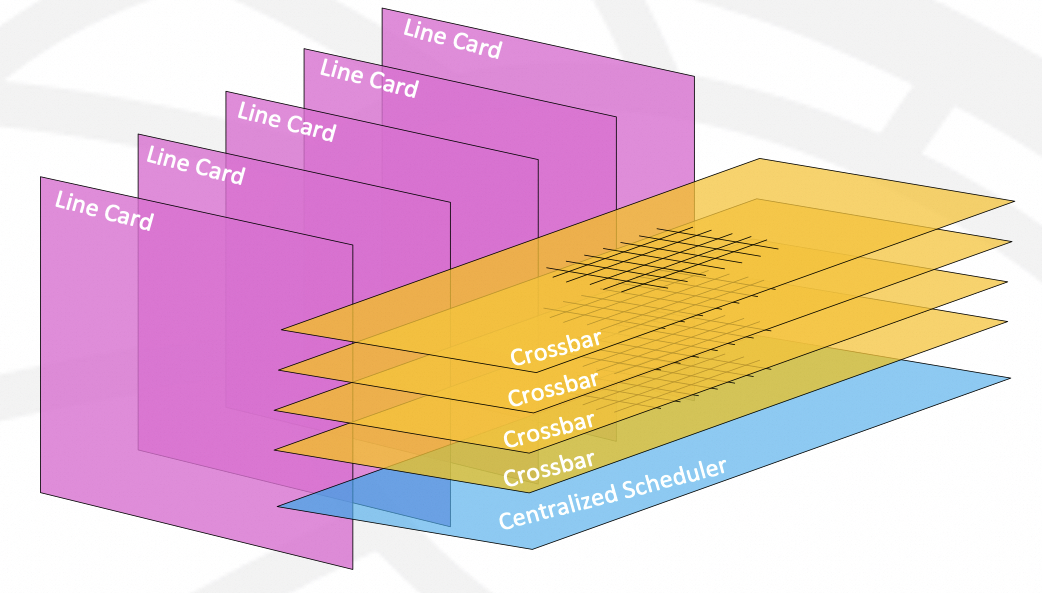
这些交换背板和当下的NVSwitch以及NVSwitch Tray构建的NVL8~NVL72的系统背后的原理是完全一致的。都是在单颗芯片遇到内存墙后,通过多个芯片互联构建一个更大规模的系统。
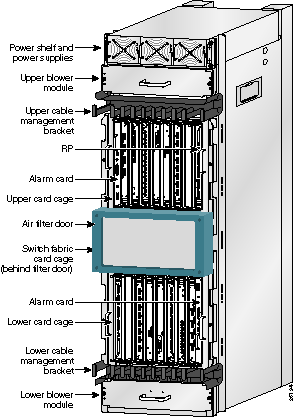
Cisco12000的单机柜构造,中间是Switch Fabric和GB200机柜中间的9个Switch Tray类似,而顶部和底部都有8个业务线卡(LineCard)插槽,对应于GB200的每个Compute Tray。
而这里面相对核心的技术是VOQ和iSLIP调度算法的设计,等价来说,当模型执行All-to-All时,有可能会多个B200同时向一个B200写入数据,因此会产生一定的头阻(Head-Of-Line Blocking,HOLB),聪明的人类总会在十字路口前后加宽一点作为缓冲,也就是所谓的Input Queue和Output Queue:
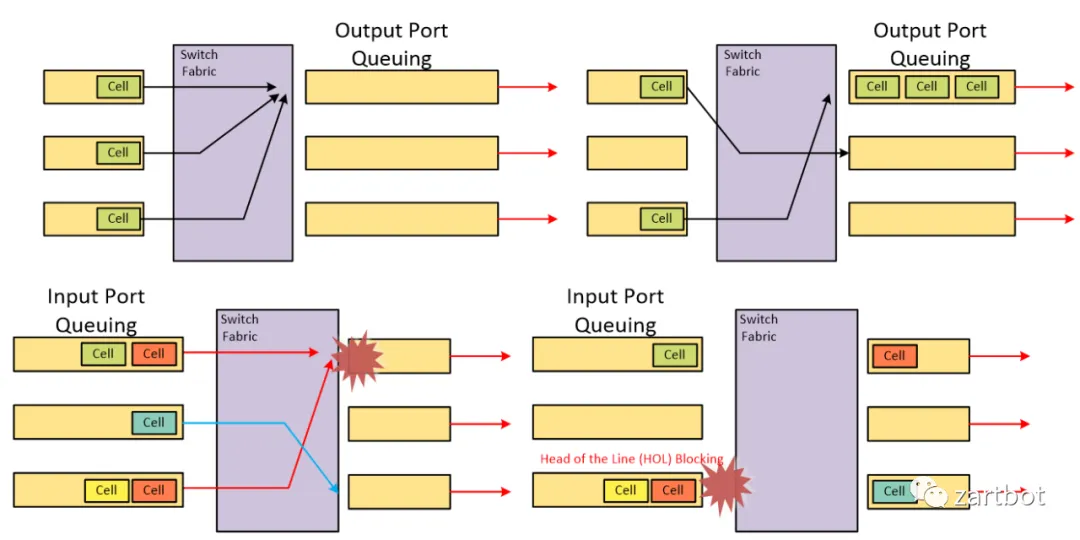
可惜问题又来了,对于Output Queue而言, 虽然可以最大限度的使用带宽, 但需要队列缓存具有N * R的操作速度. 而对于Input Queue, 缓存可以用R的速度进行处理, 但是会遇到HOL Blocking的问题. 在一个IQ交换机上受制于HOL Blocking的crossbar最大吞吐量计算可得为 58.6%。
解决IQ HOL Blocking问题的一种简单方案是使用虚拟输出排队(virtual output queueing , VOQ).在这种结构下,每个输入端口为每个输出设置一个队列,从而消除了HOL Blocking. 并保持缓存的操作速度为R。
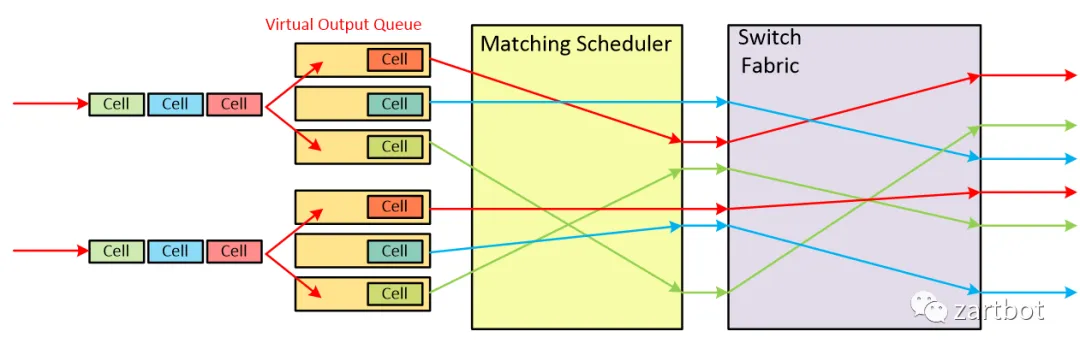
当然英伟达在NVLINK上采用了Credit based的设计方案,Credit的分发仲裁等都是国内一些做GPU创业的公司值得深入研究的问题。
2.3 MultiStage多级架构和光互联演进
而NVL576更像是思科在2003年推出的Carrier Routing System(CRS-1)。

当时也是面对互联网泡沫时期对带宽的巨大需求,构建了多级交换网络的系统。
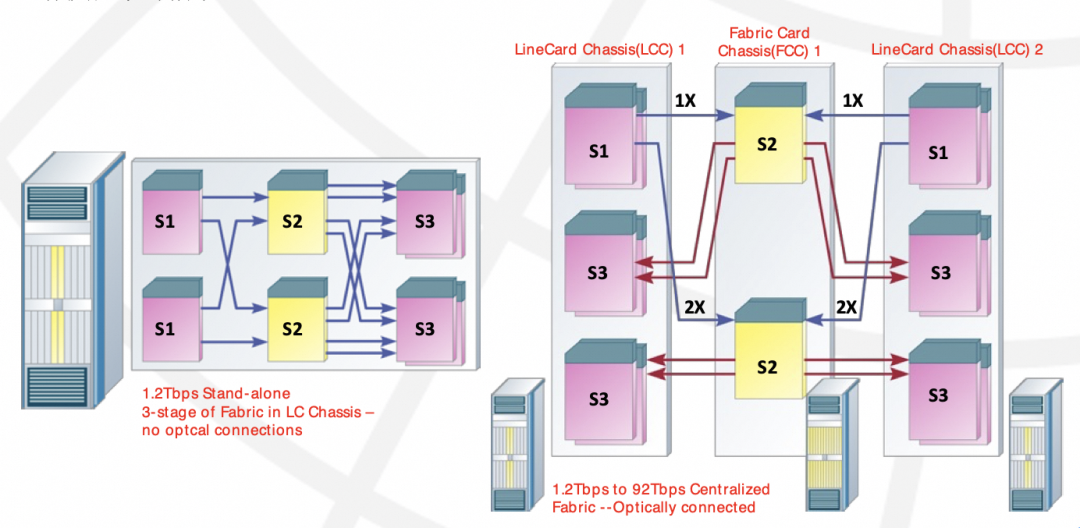
单个机柜3-stage的交换网络构建的Switch Tray,等同于当前的Non-Scalable的GB200 NVL72。而多机柜的结构则是对应于NVL576,当年思科也是将单机柜16个Linecard可以扩展到采用8个Fabric机柜+72个LineCard机柜来构建1152个LineCard的大规模集群,当年思科的内部连接也是采用光互联。

机箱之间的光连接器如下图所示:

需要注意的是这个时间点还有一个人,那就是现在英伟达的首席科学家Bill Dally,他创建了Avici公司通过3D-Torus互联来构建Tbit级路由器。
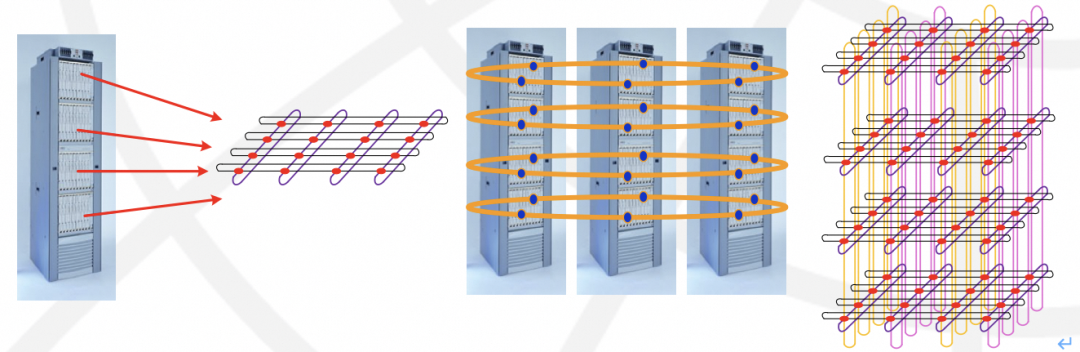
3D-Torus的互联是不是又想到了Google的TPU?而后来华为也OEM了Avici这套系统并标记为NE5000售卖,再后来才是自己研发的核心路由器产品NE5000E。而同一个时代,Juniper的诞生也在核心路由器这个领域给思科带来很多压力。或许英伟达一家独大的日子接下来会引来更多的挑战者。
另一方,MEMS的光交换机也是在那个年代引入的,和如今Google利用光交换机似乎也有一些似曾相识的感觉。
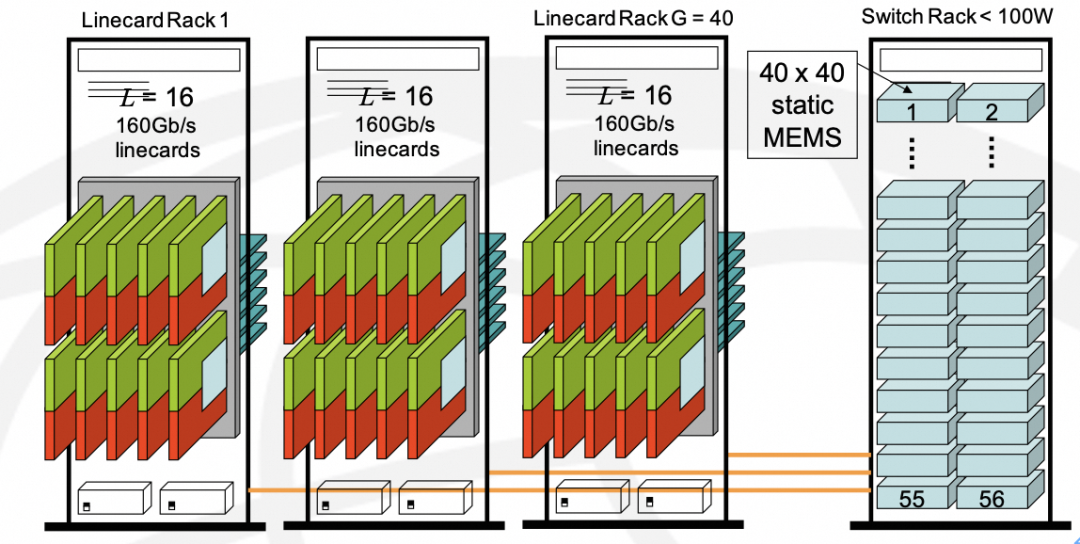
03
英伟达未来的演进
2023 年互联系统的大会HOTI上,Bil Dally做了一个Keynote: Accelerator Clusters,The New Suppercomputer[2]从片上网络和互联系统的角度来谈主要就是三大块内容:
Topolgy:CLOS/3D-Torus/Dragonfly
Routing
Flow control
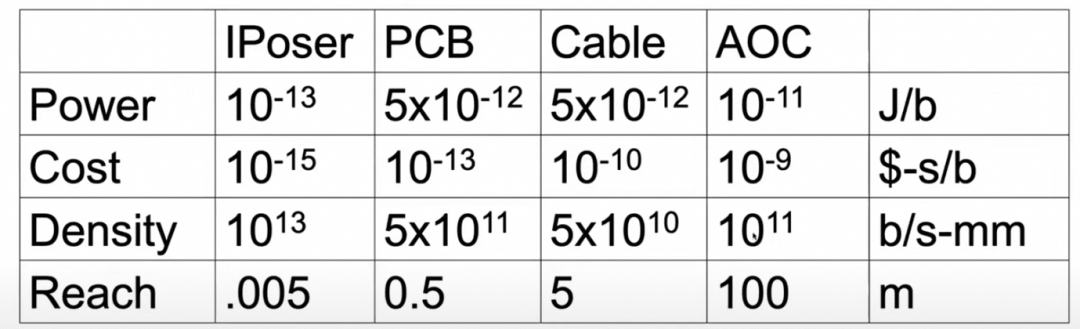
不同的器件连接有不同的带宽和功耗:
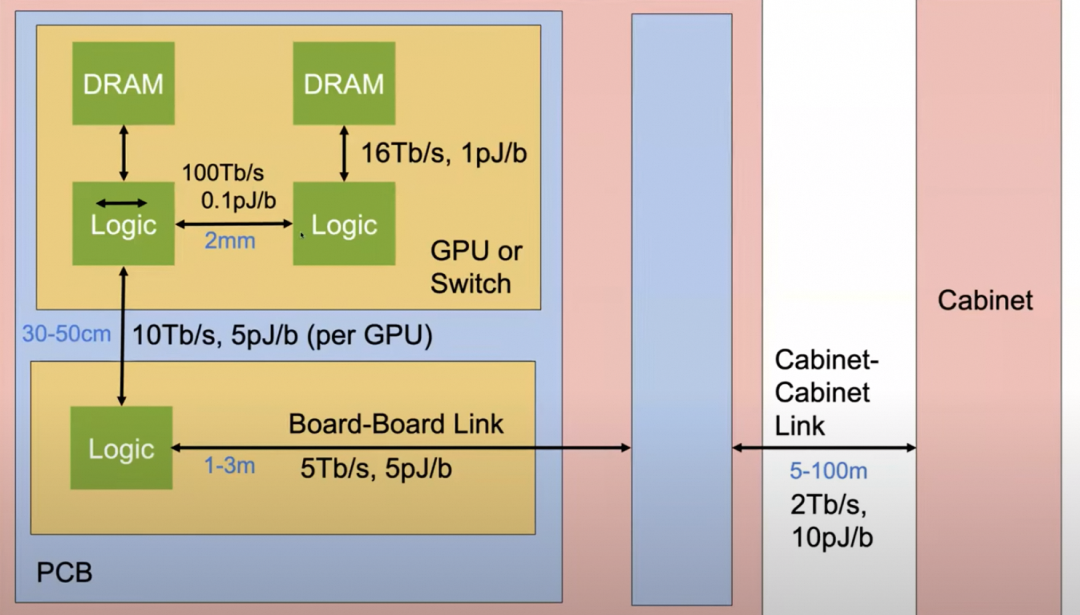
问题是如何有机地将它们组合起来,需要考虑功耗/成本/密度和连接距离等多个因素。
3.1 光互联
通过这些维度的度量,Co-Package Optic DWDM成为一种选择:
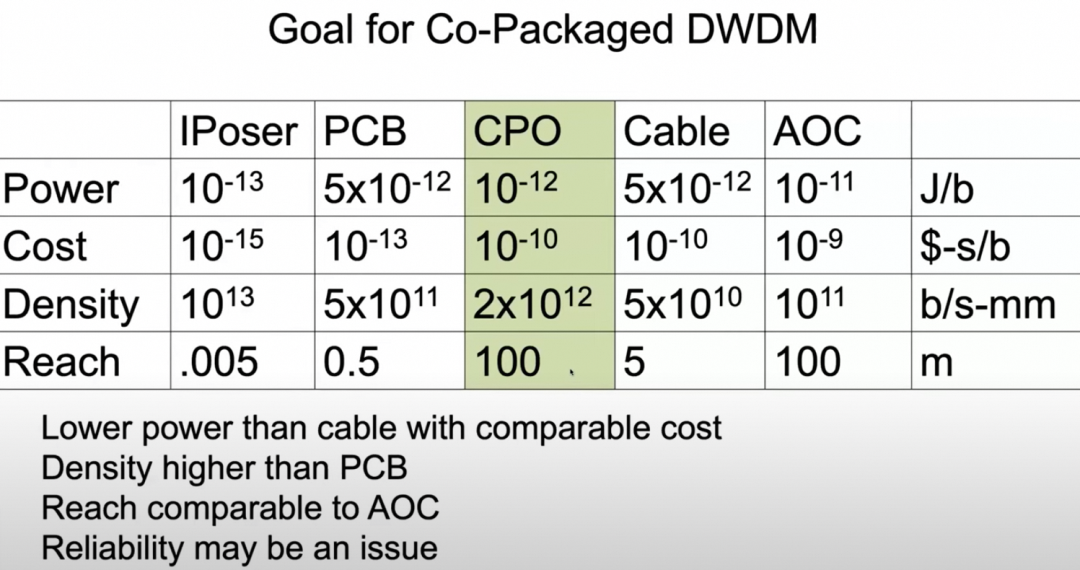
构建光互联的系统概念图如下:
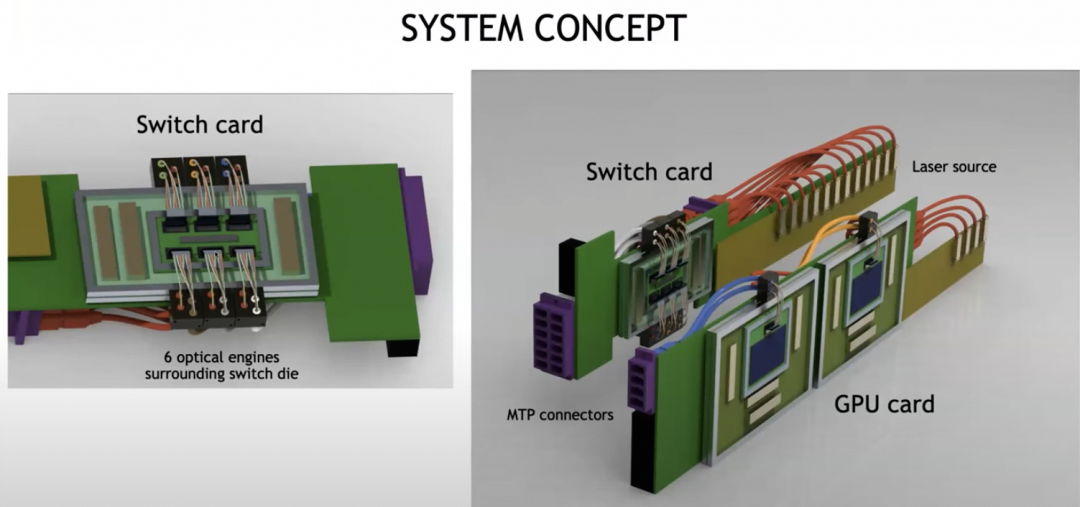
最终构建一个超大规模的光互联系统。
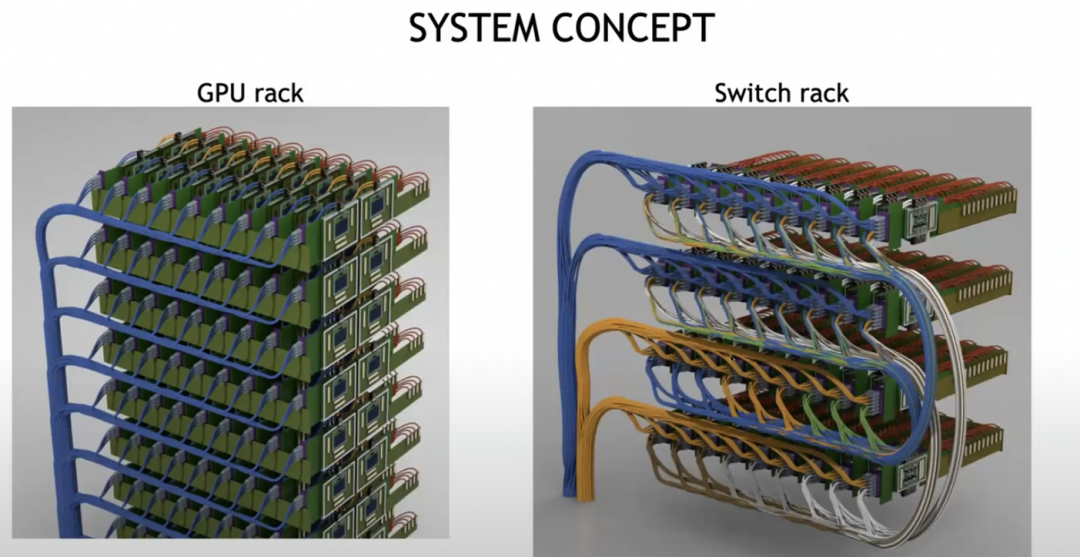
这一点上你会看到和思科当年做的CRS-1多机框系统几乎完全一致,GPU Rack等同于Cisco LineCard Chassis, Switch Rack等同于思科的Fabric Chassis,并且都是光互联,同时也使用了DWDM技术来降低连接复杂度并提升带宽。

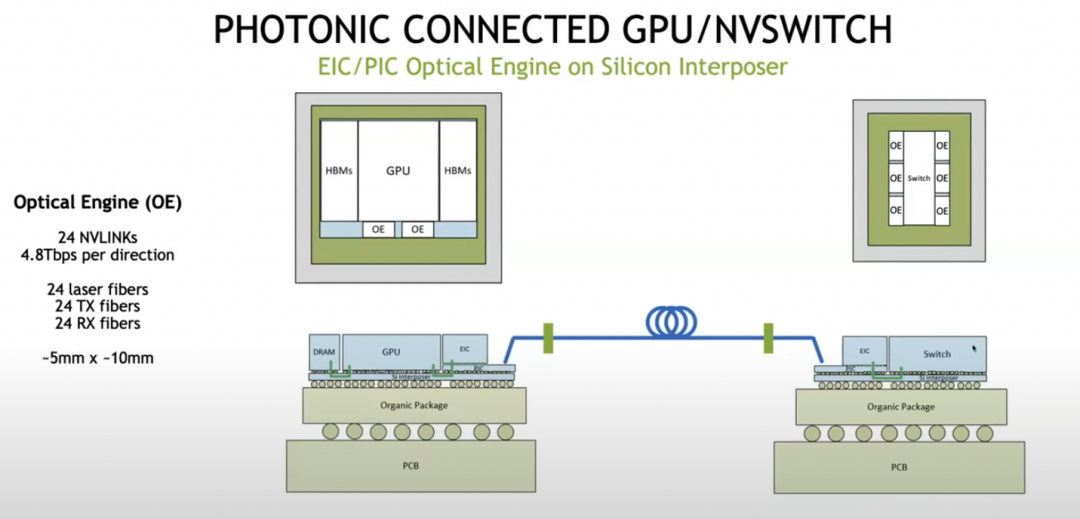
芯片架构上则采用了Optical Engine作为chiplet进行互联。
而互联结构上则是更多的想去采用DragonFly拓扑并利用OCS光交换机。
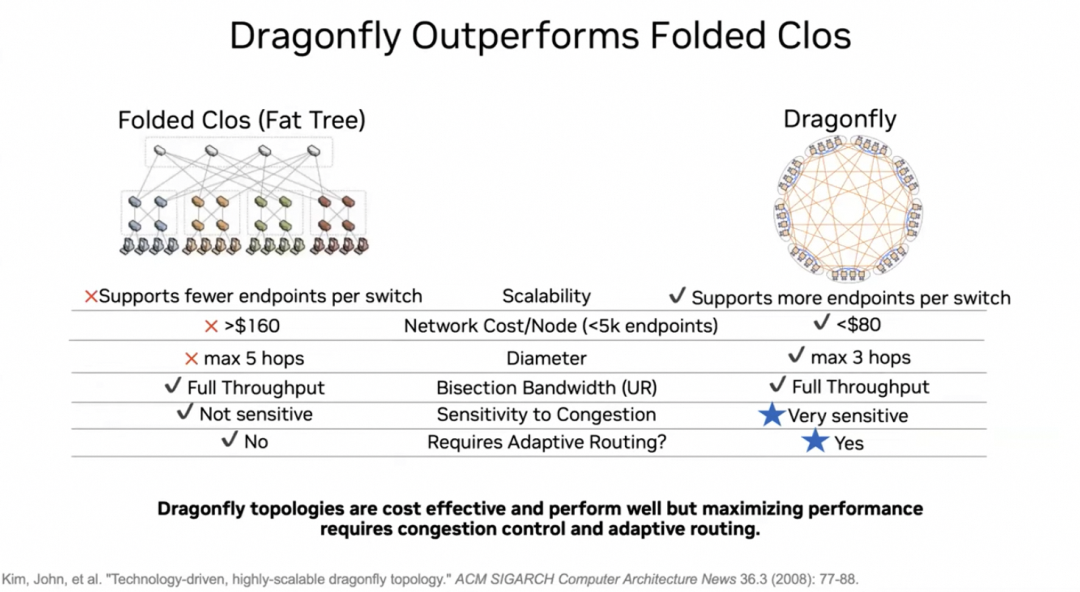
至于FlowControl这些拥塞控制算法上,Bill在谈论一些类似于HOMA/NDP的机制,还有Adaptive Routing等。事实上并不用这么复杂,因为我们有更好的MultiPath CC算法,甚至不需要任何新的交换机特性支持。
3.2 算法和特殊硬件结合
另一方面来看,Transformer已经出来7年了,当然它是一个非常优秀的算法,既占满了算力有Compute Bound的算子,又有Memory Bound的算子,而整个工业界是否还有更精妙的算法呢?
在《大模型时代的数学基础(4)》中我们介绍了一些算法,例如稀疏Attention的Monarch Mixer以及不需要Attention机制的Mamba/RMKV等模型,当然还有很多人正在研究的基于范畴论/代数几何/代数拓扑等算法下的优化。当然还有不同精度的数值格式,例如Blackwell开始支持的FP4/FP6格式,以及未来可能支持的Log8格式。
其实历史上思科也是依靠算法和特殊硬件来逐渐提高单芯片的算力摆脱复杂互联结构的。当时通过TreeBitMap这些路由查表算法在普通的DRAM上就可以支持大规模的路由查询。
同时借助于多核和片上网络等技术的发展,构建了超高性能的SPP/QFP/QFA网络处理器,而这些技术又辗转着在AWS Nitro/ Nvidia BlueField / Intel IPU等DPU处理器上再次出现。
算法/算力和硬件的反复迭代才是时代发展的脉搏。
04
结论
本文分析了最新的Blackwell这一代GPU的互联架构,并且针对《英伟达的思科时刻》对于两次科技浪潮中,两家公司面临单芯片算力跟不上爆发性需求后进行的分布式系统构建和互联架构的探索,并分析了英伟达首席科学家Bill Dally在2023 Hoti的演讲,基本上能够看清楚英伟达未来的发展路径了。
但是我们同时也注意到,思科在互联网泡沫的高峰时期,也诞生了Juniper/Avici这样的公司,英伟达也是在那个年代作为挑战者战胜了3Dfx,后来又在专业领域战胜了SGI。任何一个时代都值得期待,而赢下来的不是单纯的堆料扩展,而是算法和算力结合硬件的创新。
从挑战者来看,算力核本身抛开CUDA生态,其实难度并不大。最近Jim Keller和日韩一些HBM玩家动作频频,是否BUDA+RISC-V+HBM会成为一个新兴的力量。
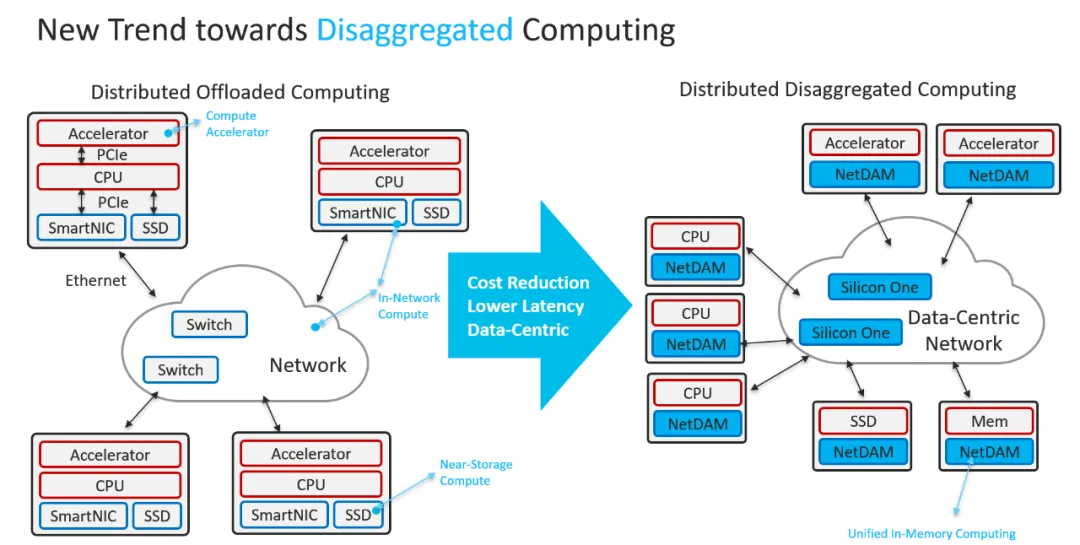
从互联系统替代IB/NVLINK来看,以太网已经有了51.2Tbps的交换芯片,基于以太网高速连接HBM的通信协议,并且支持SHARP这些随路计算在网计算的东西早在三年前NetDAM就设计好了。
参考资料:
How to Build Low-cost Networks for Large Language Models (without Sacrificing Performance)?:https://arxiv.org/abs/2307.12169
HOTI 2023: Bill Dally Keynote: Accelerator Clusters:https://www.youtube.com/watch?v=napEsaJ5hMU
本文转载自zartbot,作者:扎波特的橡皮擦
线下交流
专业社群

精品活动推荐



更多文章
关于涉嫌仿冒AutoSec会议品牌的律师声明
一文带你了解智能汽车车载网络通信安全架构
网络安全:TARA方法、工具与案例
汽车数据安全合规重点分析
浅析汽车芯片信息安全之安全启动
域集中式架构的汽车车载通信安全方案探究
系统安全架构之车辆网络安全架构
车联网中的隐私保护问题
智能网联汽车网络安全技术研究
AUTOSAR 信息安全框架和关键技术分析
AUTOSAR 信息安全机制有哪些?
信息安全的底层机制
汽车网络安全
Autosar硬件安全模块HSM的使用
首发!小米雷军两会上就汽车数据安全问题建言:关于构建完善汽车数据安全管理体系的建议
