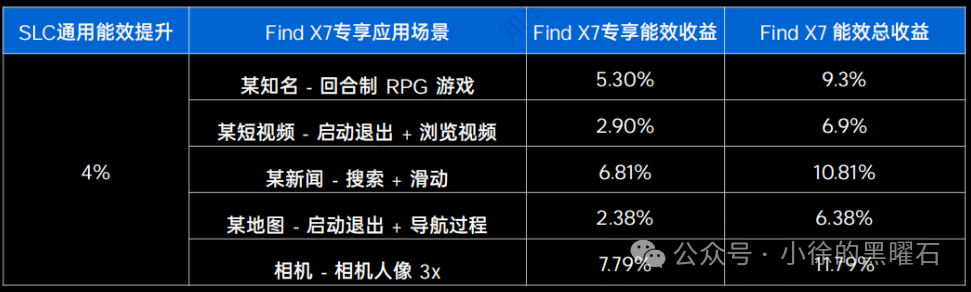
从oppo官方释放的信息来看,潮汐优化应用运算速度的底层原理主要是对CPU内部的L3缓存进行优化,可以根据不同的场景进行动态分配。
手机处理器其实和PC架构是一致的,是冯诺依曼架构,这种架构的存储和计算是分离的(存算一体也是当前的技术热点,即在存储器中嵌入计算能力,用来解决“存储墙”问题,感兴趣的同学可以了解一下),如下图所示的就是典型的冯诺依曼架构,其中运算单元负责计算,存储器负责存储,在处理器计算的时候,需要先将数据从存储器调用到运算单元,完成计算之后,再送到存储器。
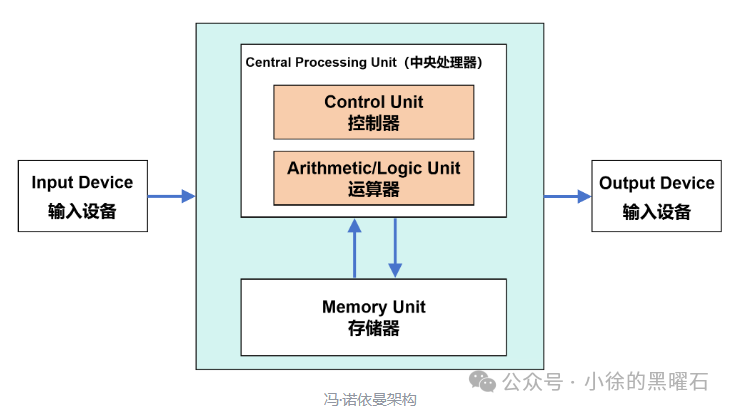
但是随着摩尔定律的发展,CPU和GPU的运算速度已经非常快,而存储芯片的速度相比较CPU/GPU而言,是很慢的,速度上的巨大差异,导致两者之间的沟通出现了问题,存储芯片的性能无法满足CPU/GPU的需求,这就是冯诺依曼架构的主要瓶颈,所以呢,工程师们想出了多级存储架构来解决这个问题,如下图所示,可以发现,随着容量越来越大,速度也越来越慢,数据就是通过这些存储,一级一级进行缓冲的。
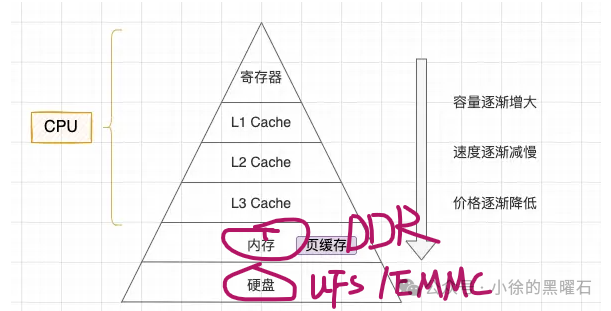
需要注意的是,DDR/EMMC这两级存储都属于大多数手机厂商自己可以调校和优化的部分,而oppo这次主打的就是优化处理器内部的L3缓存,那么什么是L1/L2/L3缓存,为什么优化L3缓存就可以优化速度呢?
为了回答上面的问题,我们可以先了解一些高速缓存的基础知识:
1、高速缓存的作用?
(1)CPU内核和外部的DDR存储之间,如前面所说,是存在速度差的,为了拉平两者的速度差,所以会在两者之间插入速度更高的cache,在工作时,会将近期CPU要用的信息调入缓存,这样CPU就可以直接从缓存中获取信息,从而提高访问速度;
(2)CPU和I/O设备会竞争同一条内存总线,有可能出现CPU等待I/O设备的情况,如果能够直接从缓存模型中获取数据,就可以减少竞争,提高CPU的效率;
2、为什么有三级缓存?分别作用是什么?
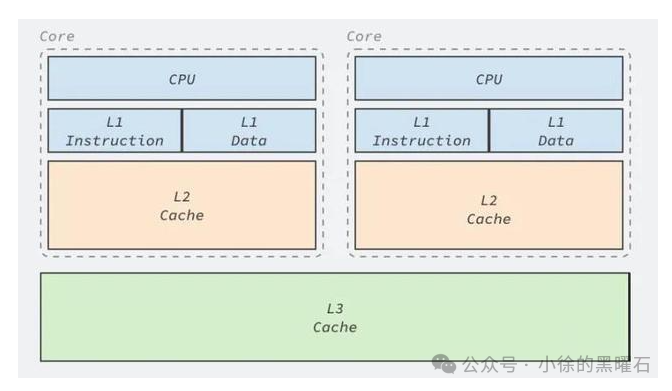
其实在cache的概念刚出现的时候,处理器和内存之间只有一级缓存,但是随着技术的发展,现在的处理器普遍采用了L1/L2/L3三级结构缓存,自顶向下容量是逐渐增加的,访问速度也会降低,当缓存没有命中时,缓存系统会向更低的层次搜索。
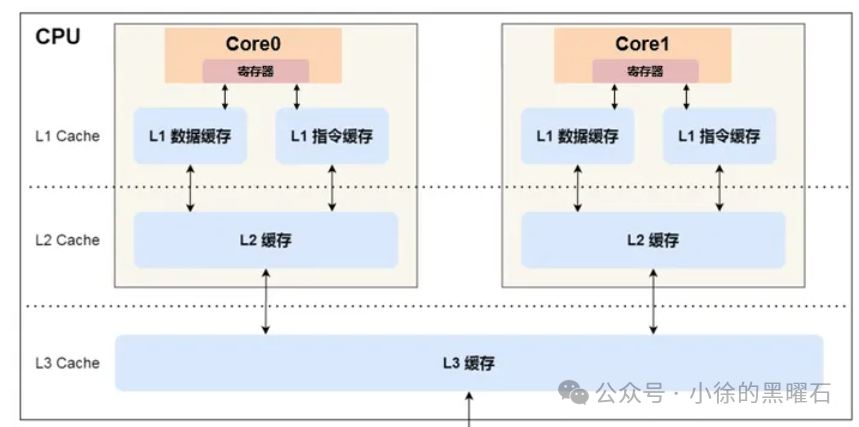
缓存的结构设计详细如上图所示:
L1 缓存:最接近CPU,访问速度几乎和寄存器一样快,一般是KB级别,处理的每个core都有自己的L1 cache,L1也分为两块,一块是存储数据,一块是存储指令;
L2 缓存:每个core都是独有的,但是比L1更远,规格也比L1更大,通常在MB级别;
L3 缓存:距离core最远,L3缓存和L1/L2的最大区别之一就是L3一般是多个core共用的,其大小通常在MB和几十MB不等。
通过对缓存基础知识回顾之后,我们再回到潮汐架构本身来说,如下图是MTK