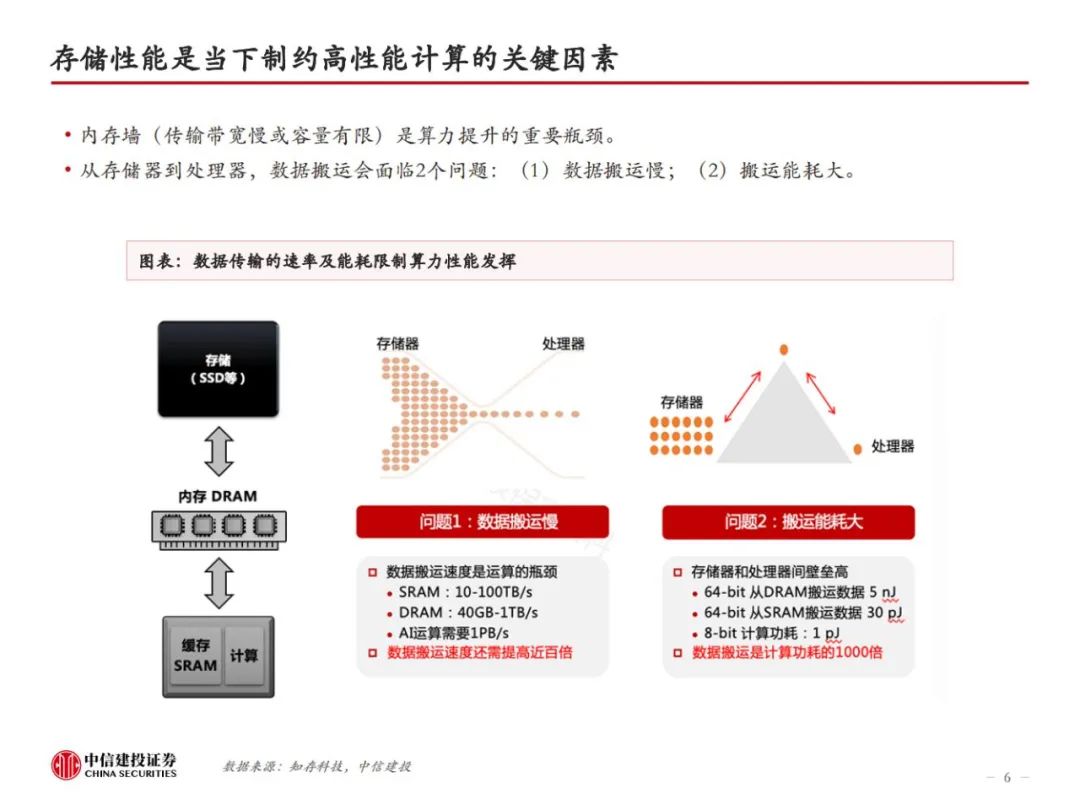
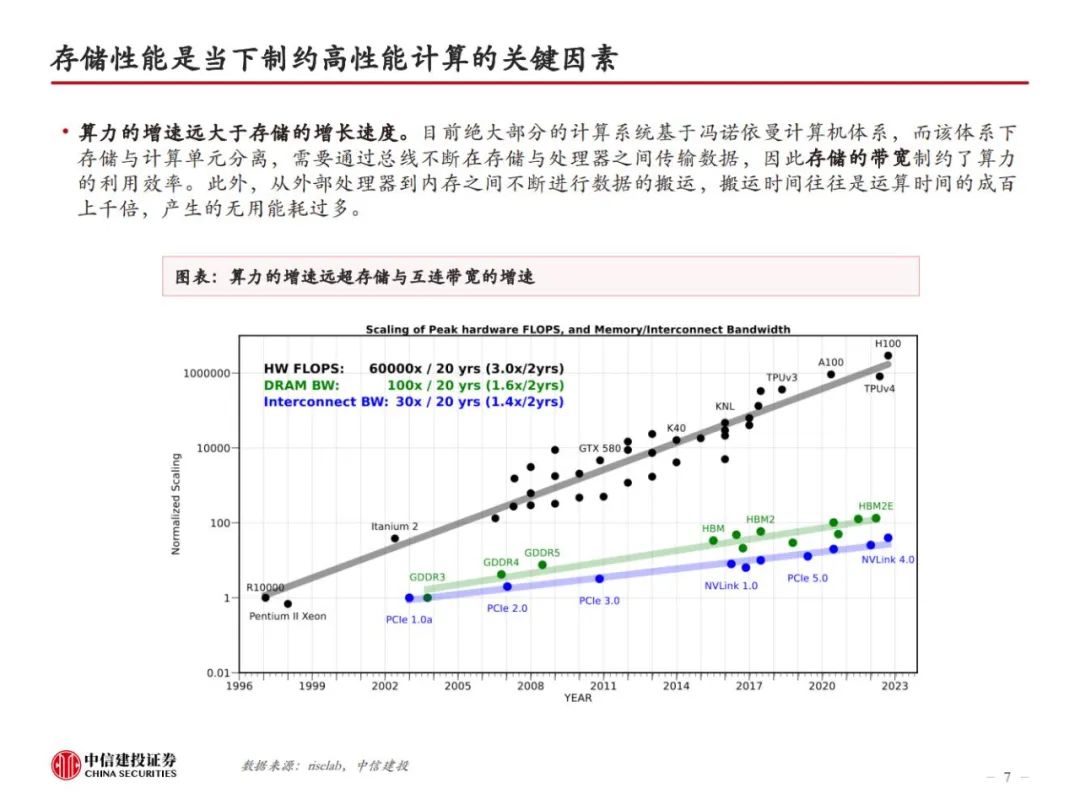
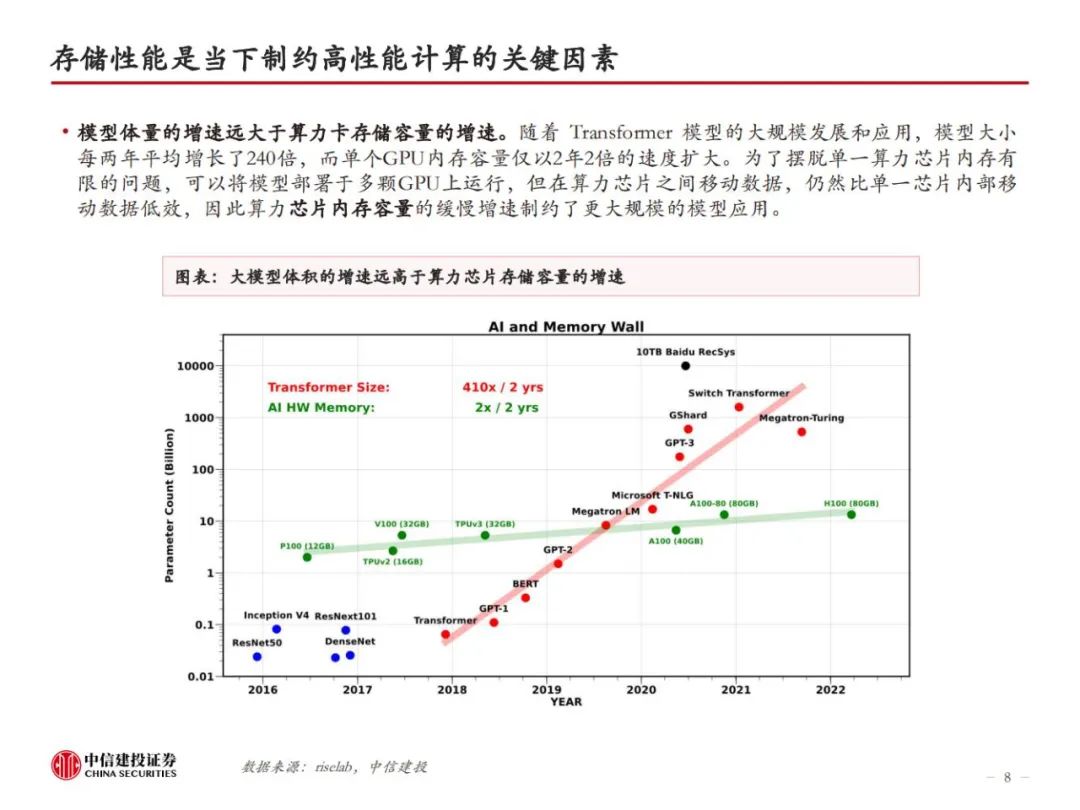
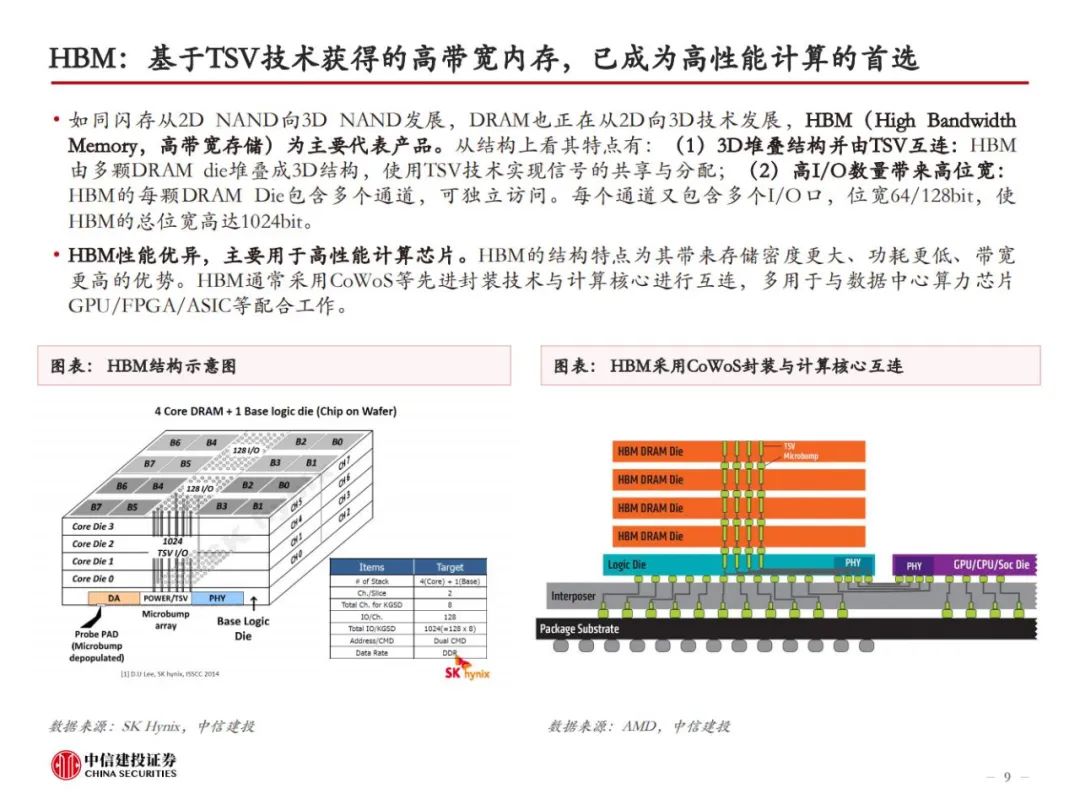
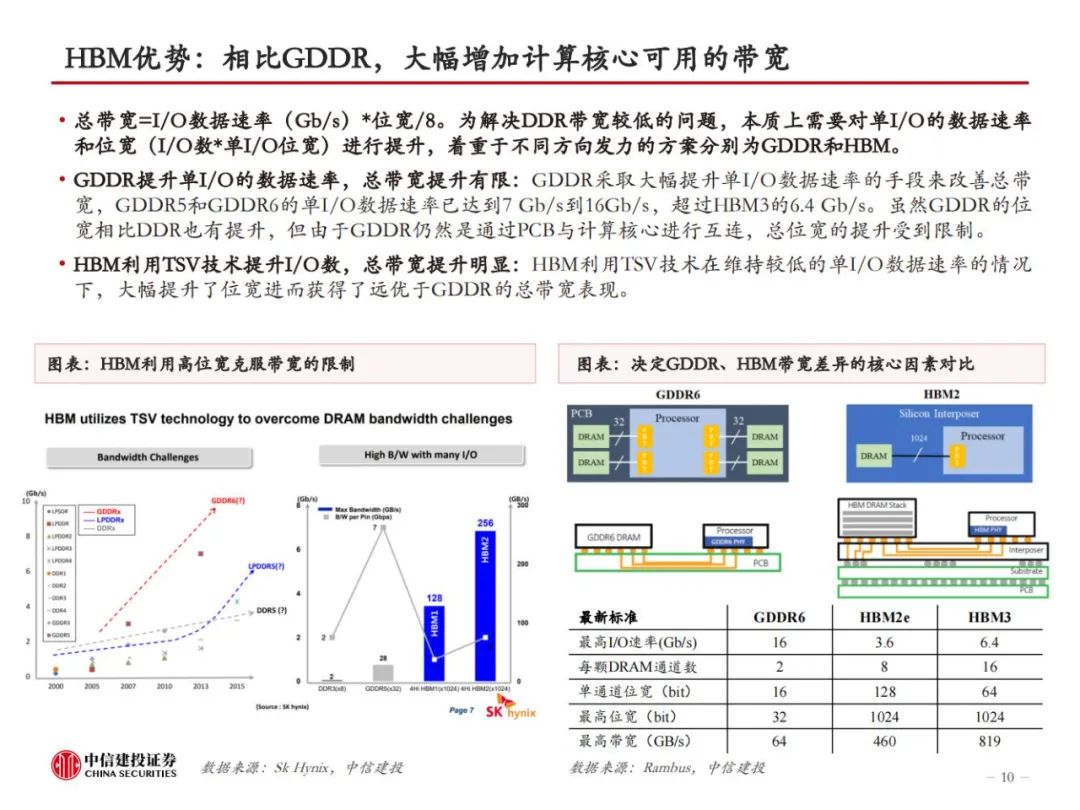
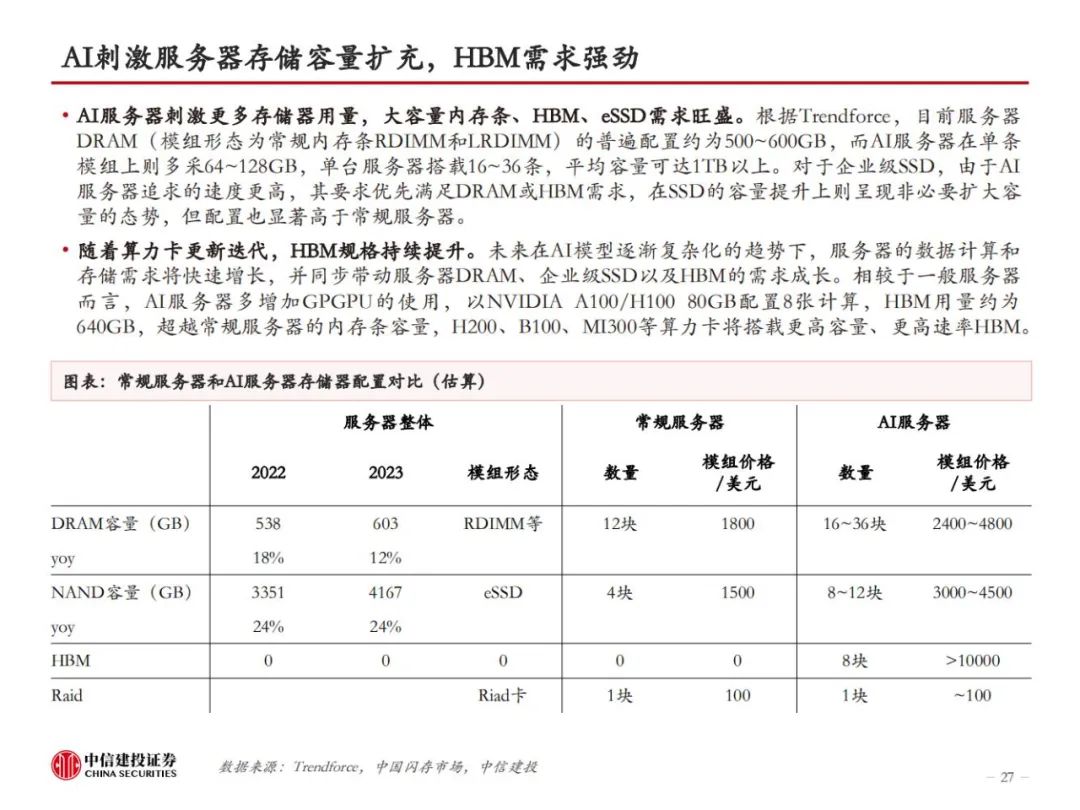
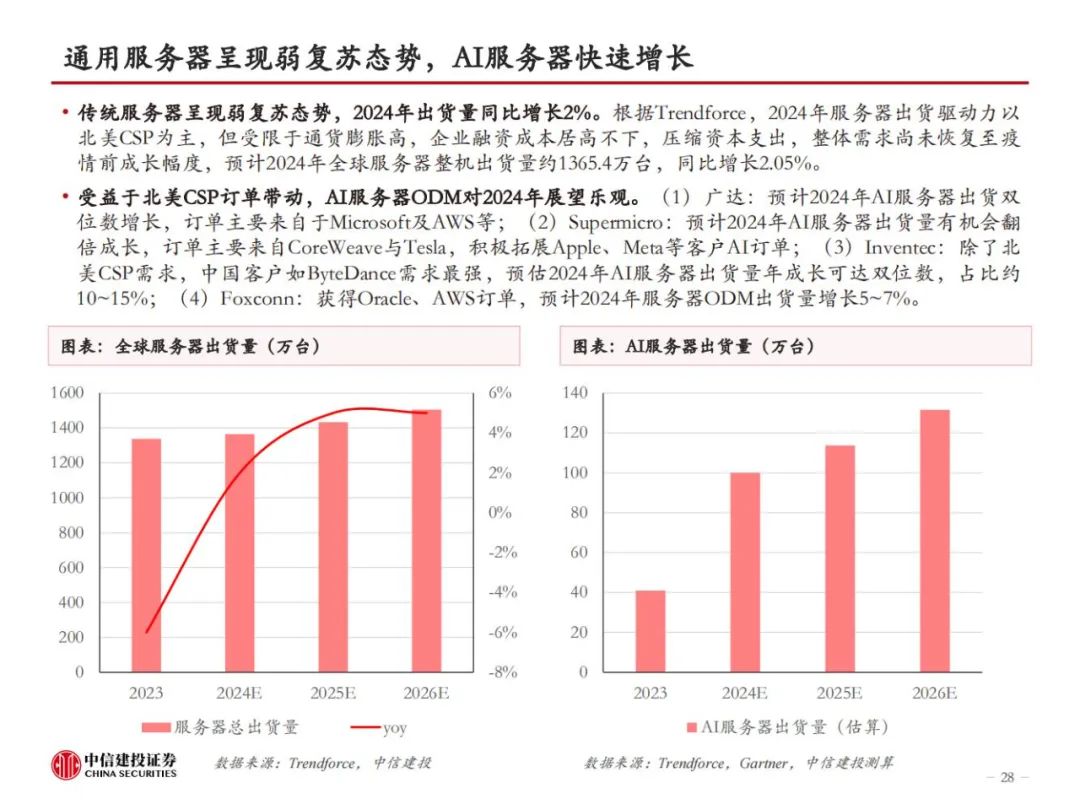
HBM是当前算力的内存瓶颈。存储性能是当下制约高性能计算的关键因素,从存储器到处理器,数据搬运会面临带宽和功耗的问题。为解决传统DRAM带宽较低的问题,本质上需要对单I/O数据速率和位宽进行提升。HBM由于采用了TSV、微凸块等技术,DRAM裸片、计算核心间实现了较短的信号传输路径、较高的I/O数据速率、高位宽和较低的I/O电压,因此具备高带宽、高存储密度、低功耗等优势。即便如此,当前HBM的性能仍然跟不上算力卡的需求。
下载链接:
AI的内存瓶颈,高壁垒高增速(2024)
1、NVIDIA A100 Tensor Core GPU技术白皮书2、NVIDIA Kepler GK110-GK210架构白皮书3、NVIDIA Kepler GK110-GK210架构白皮书4、NVIDIA Kepler GK110架构白皮书6、NVIDIA Tesla V100 GPU架构白皮书
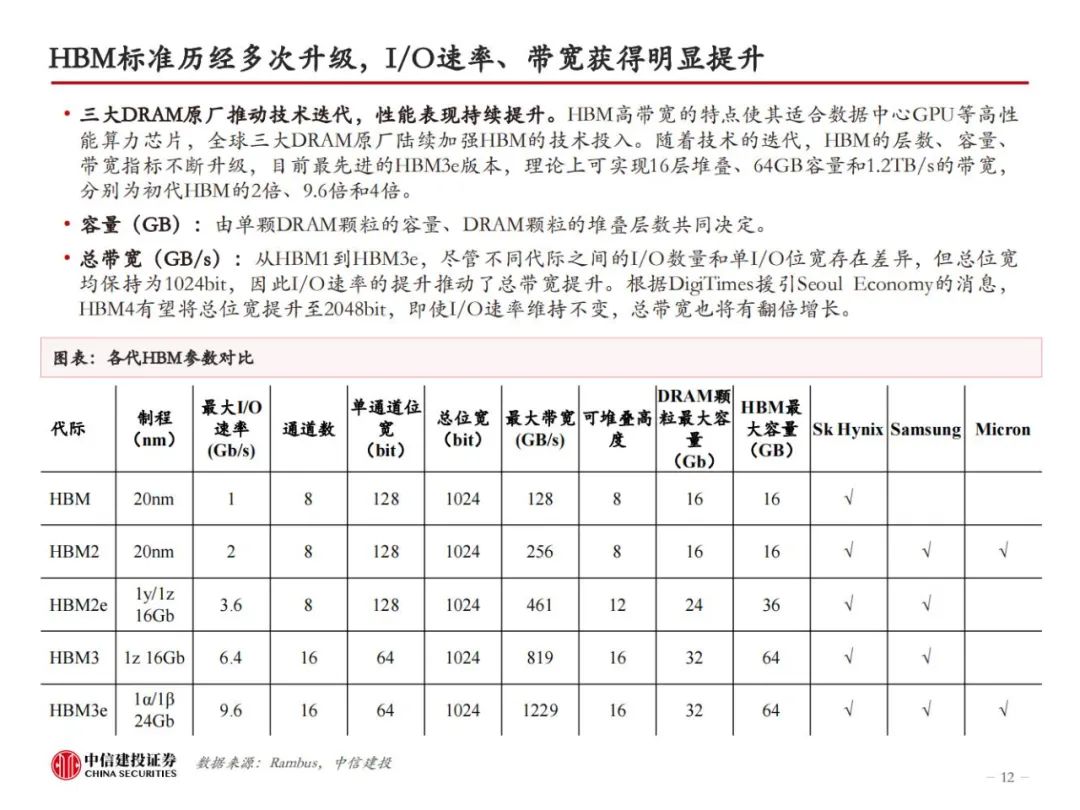
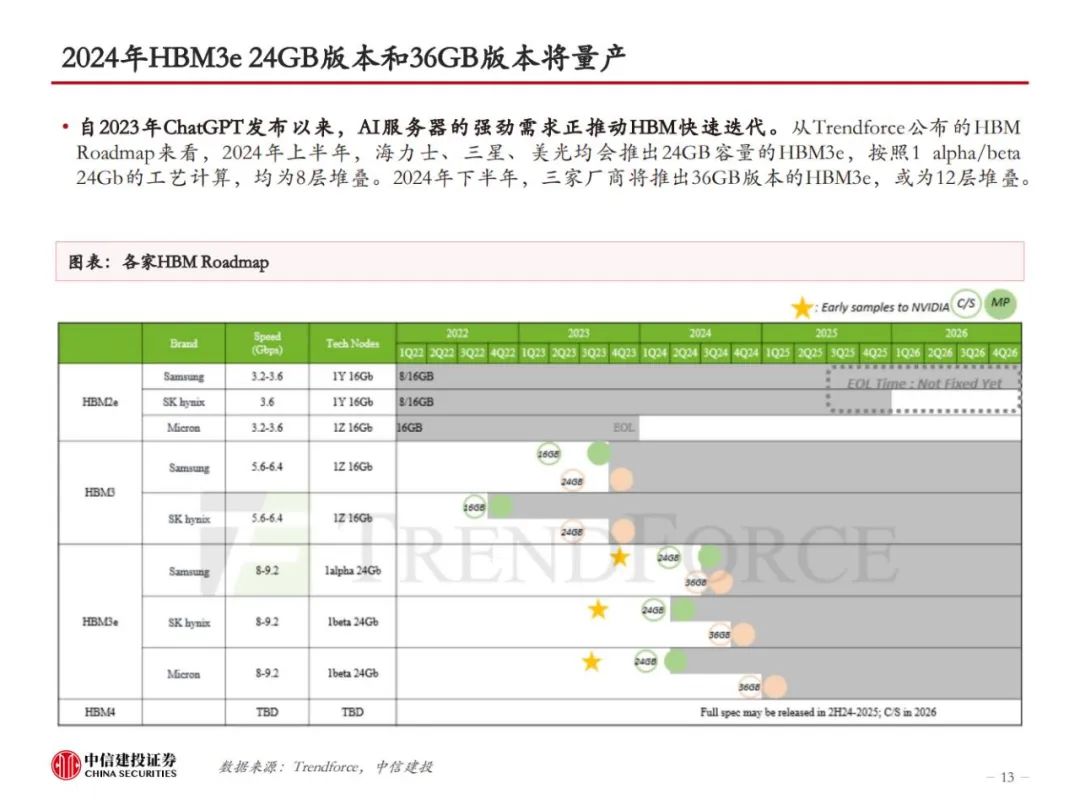
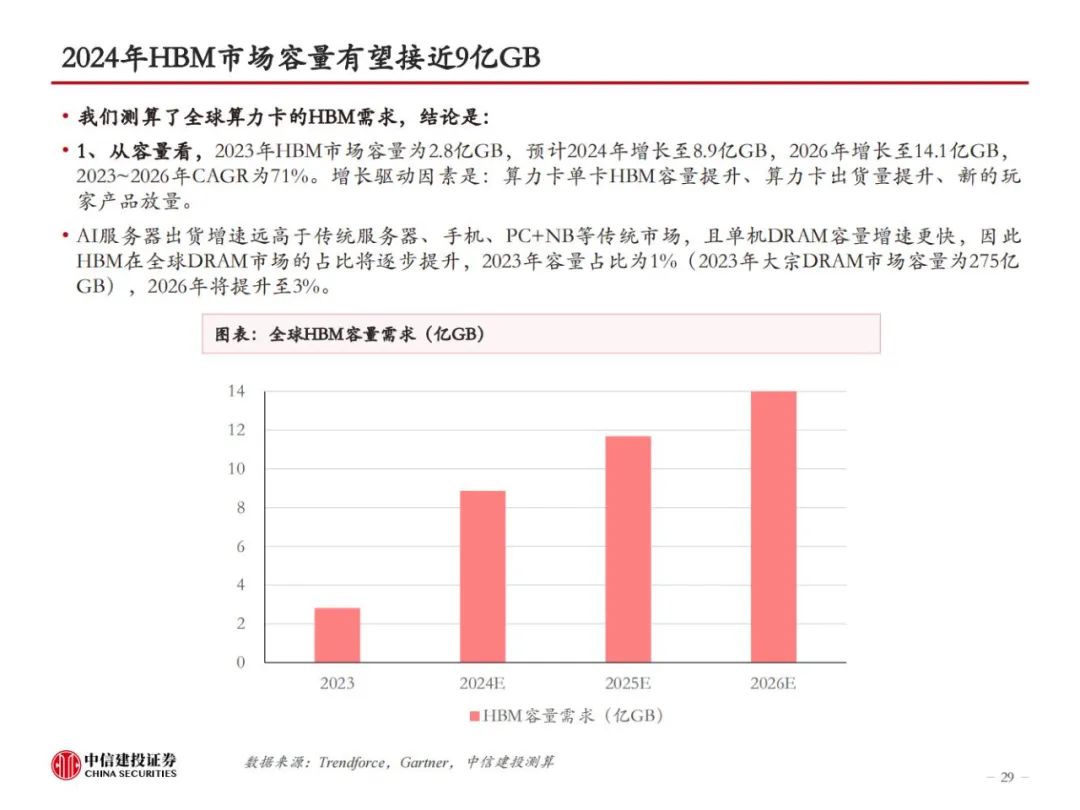
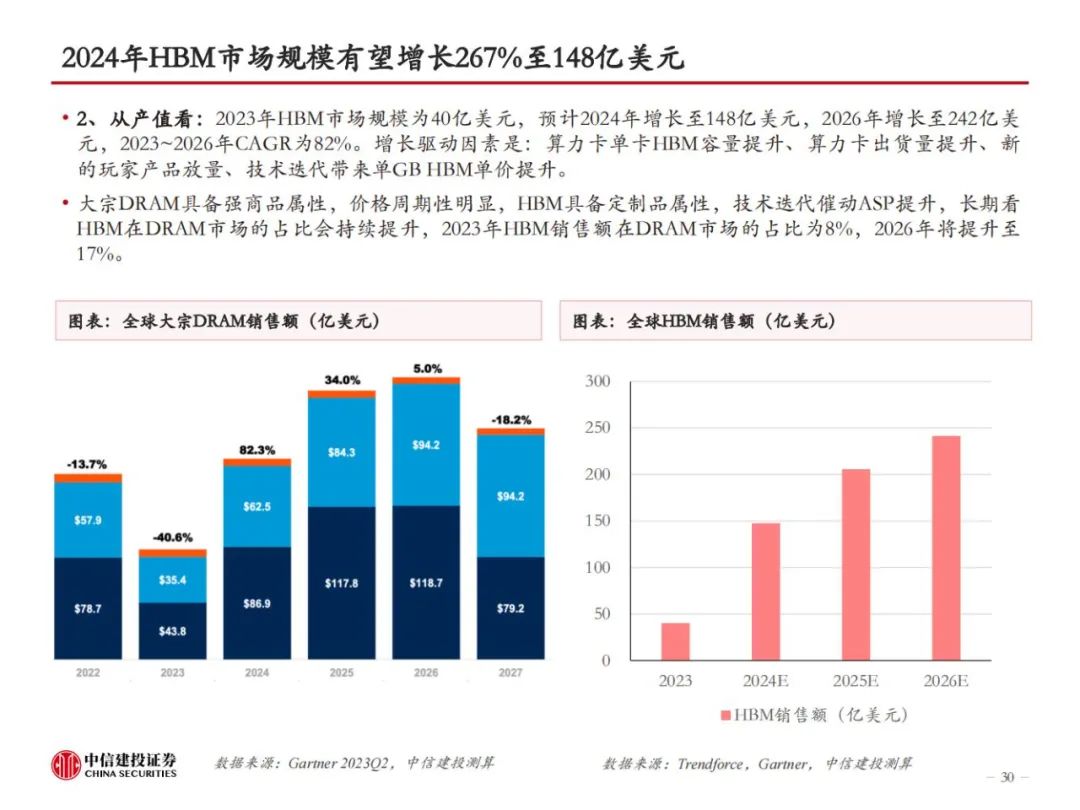
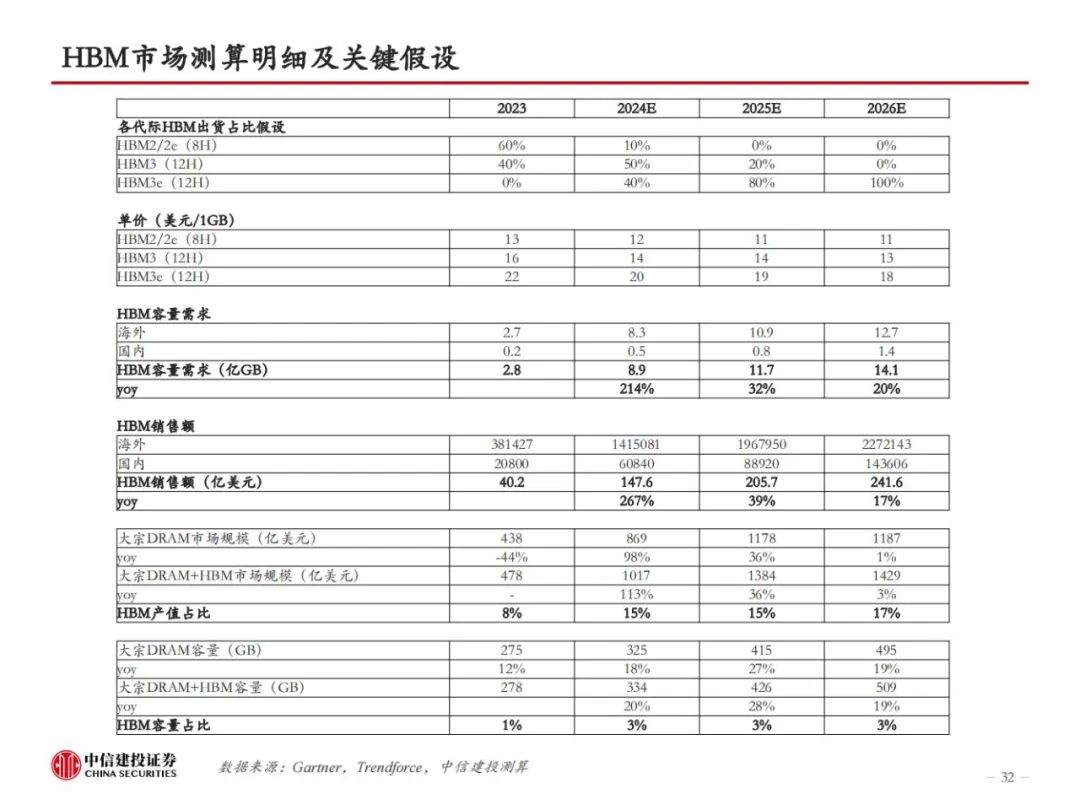
三大原厂持续加大研发投入,HBM性能倍数级提升。随着技术的迭代,HBM的层数、容量、带宽指标不断升级,目前最先进的HBM3e版本,理论上可实现16层堆叠、64GB容量和1.2TB/s的带宽,分别为初代HBM的2倍、9.6倍和4倍。从Trendforce公布的HBM Roadmap来看,2024年上半年,海力士、三星、美光均会推出24GB容量的HBM3e,均为8层堆叠。2024年下半年,三家厂商将推出36GB版本的HBM3e,或为12层堆叠。此外,HBM4有望于2026年推出。
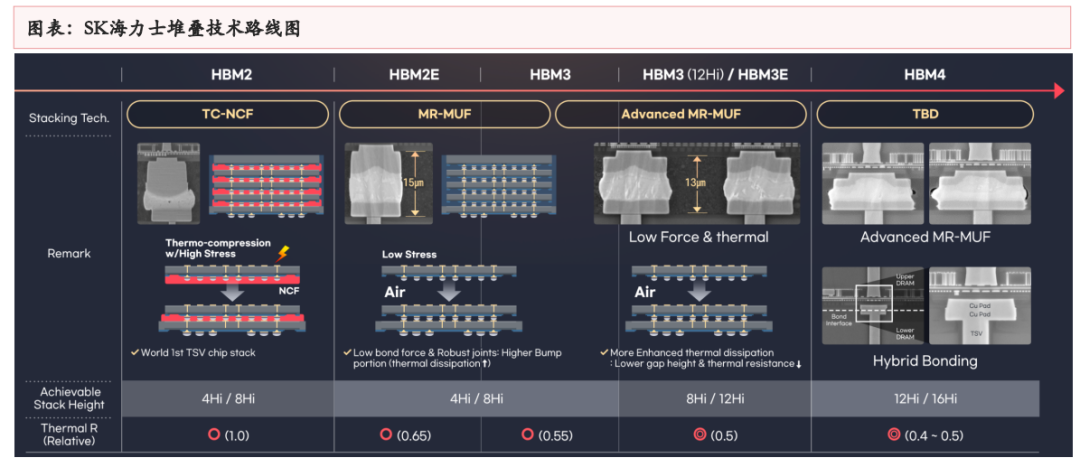
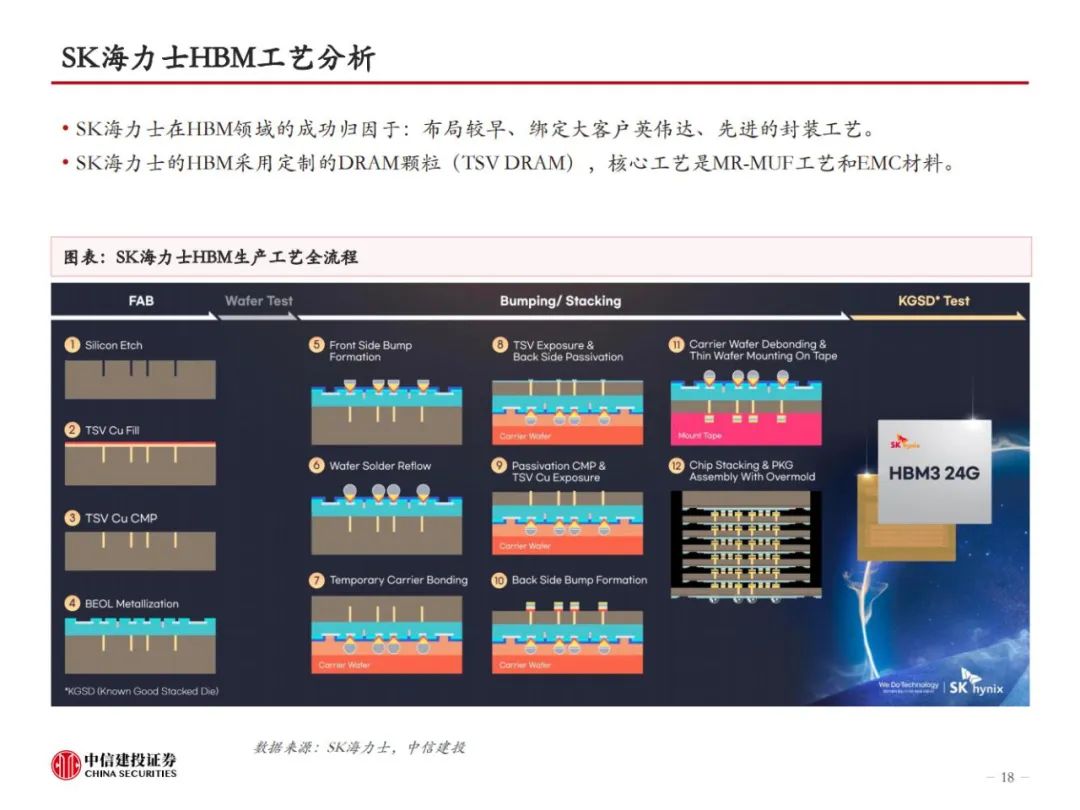
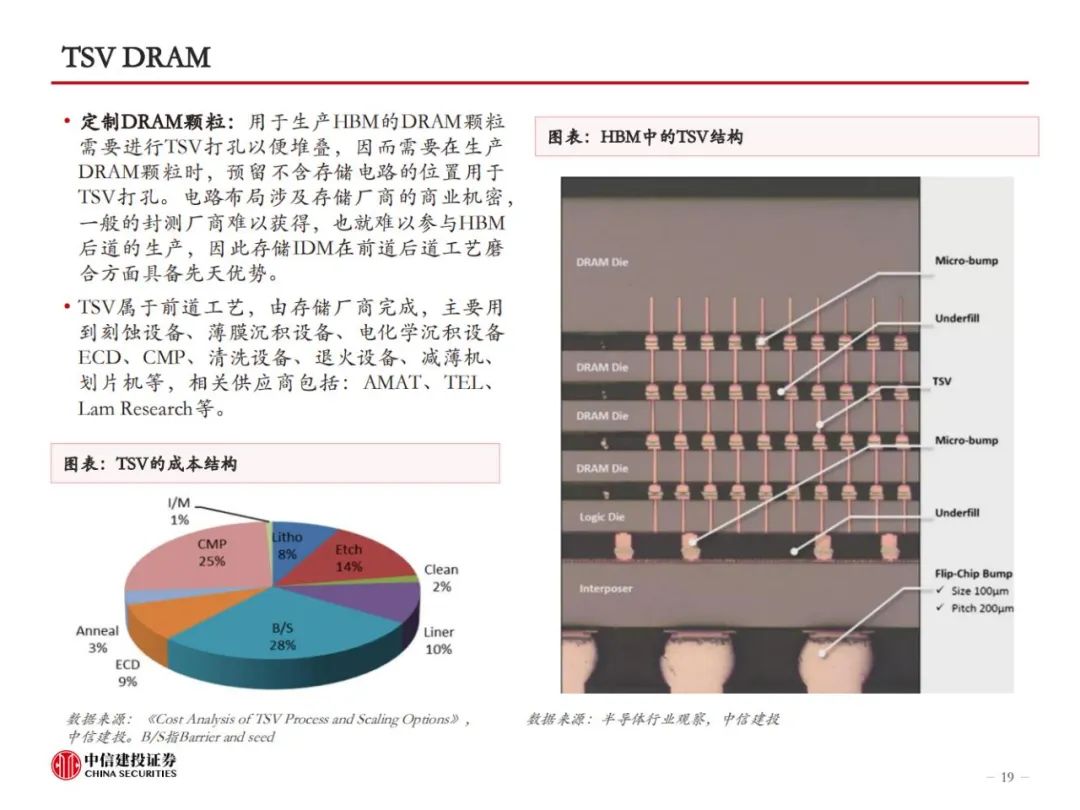
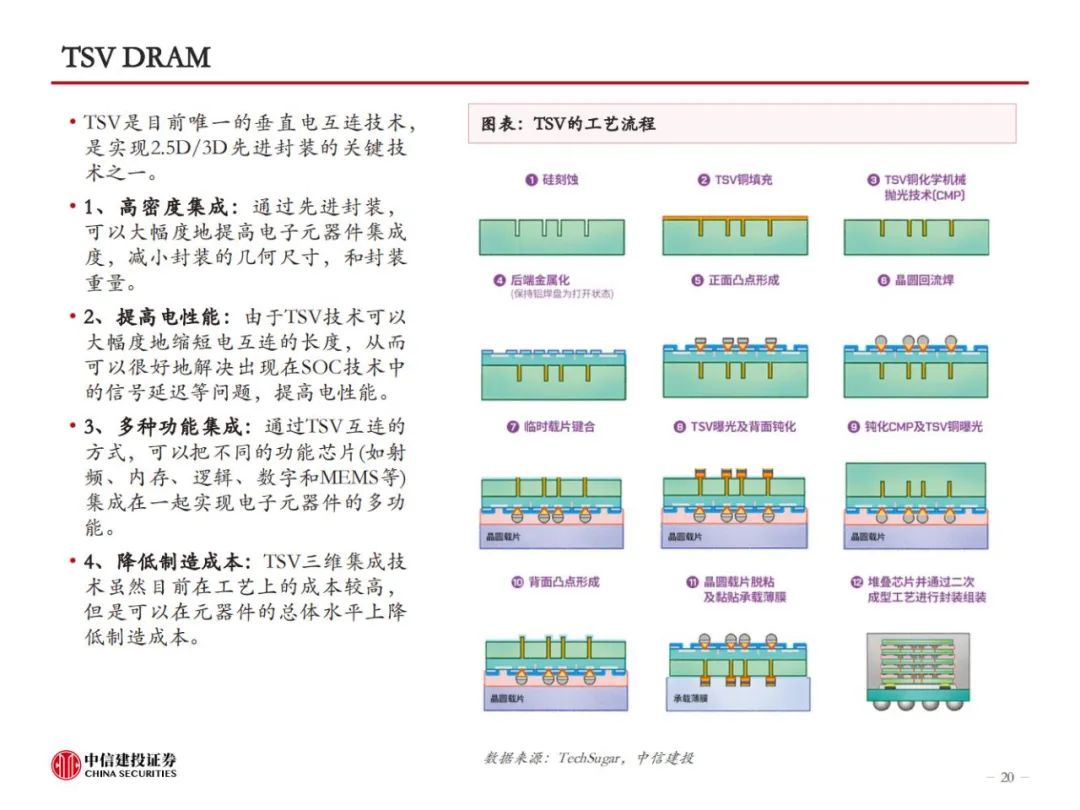
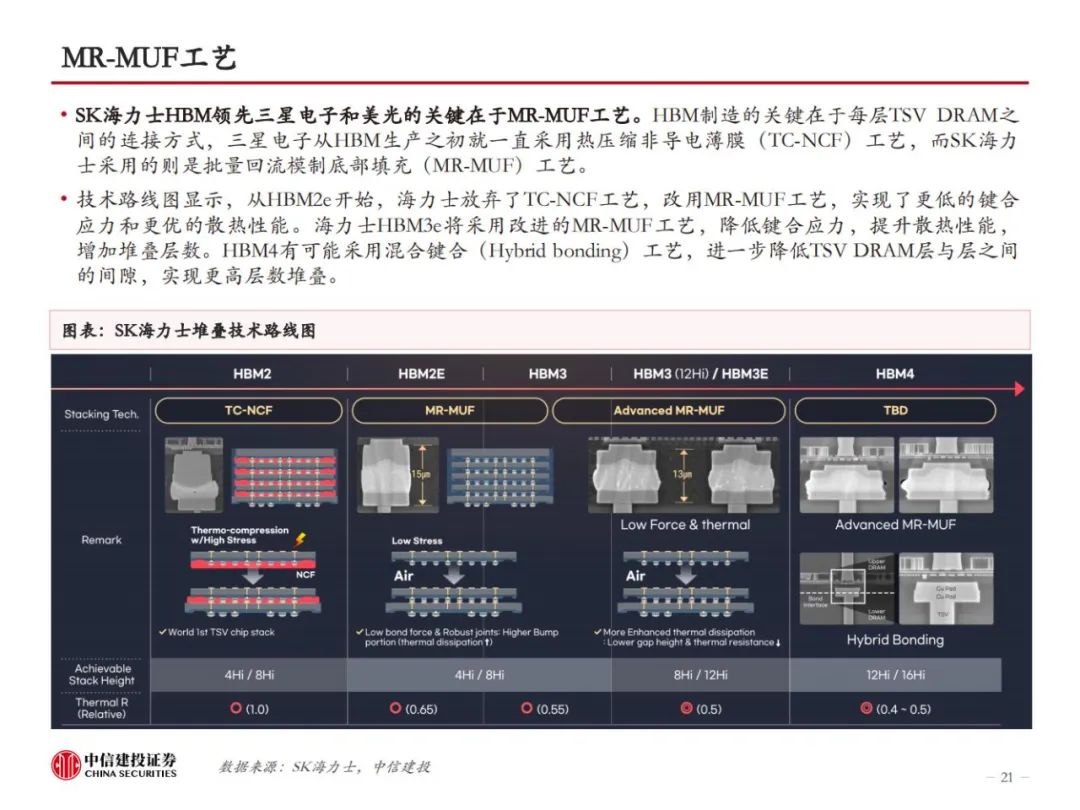
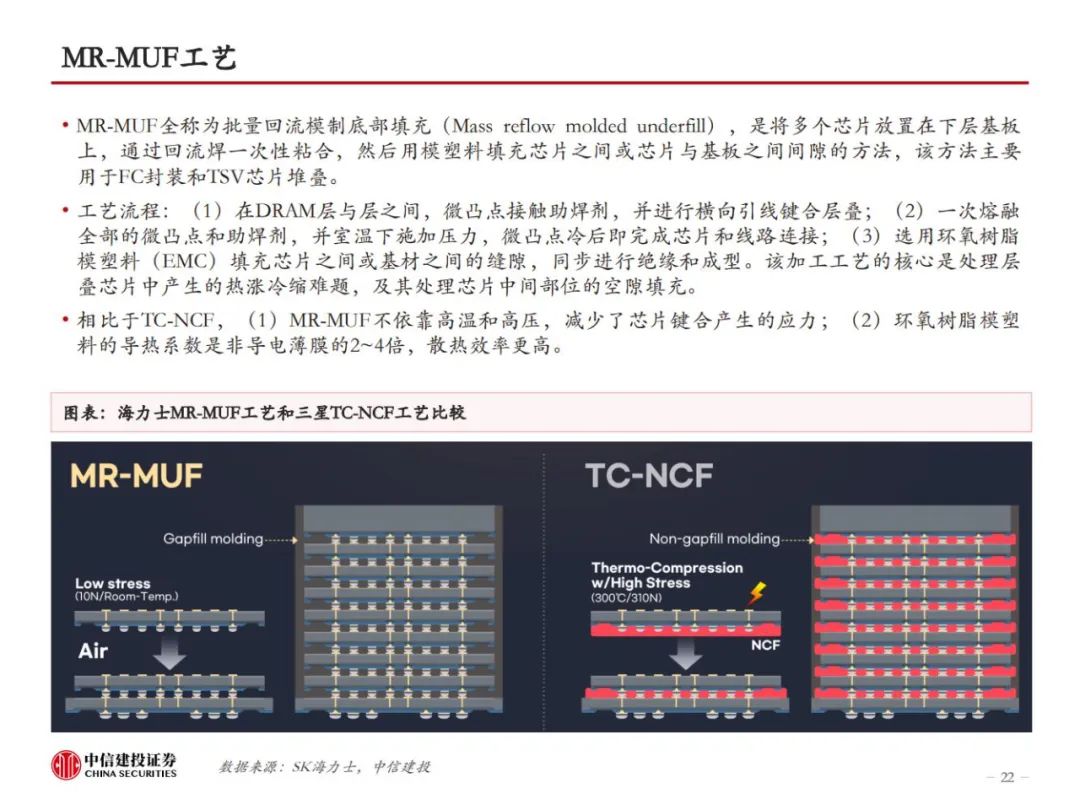
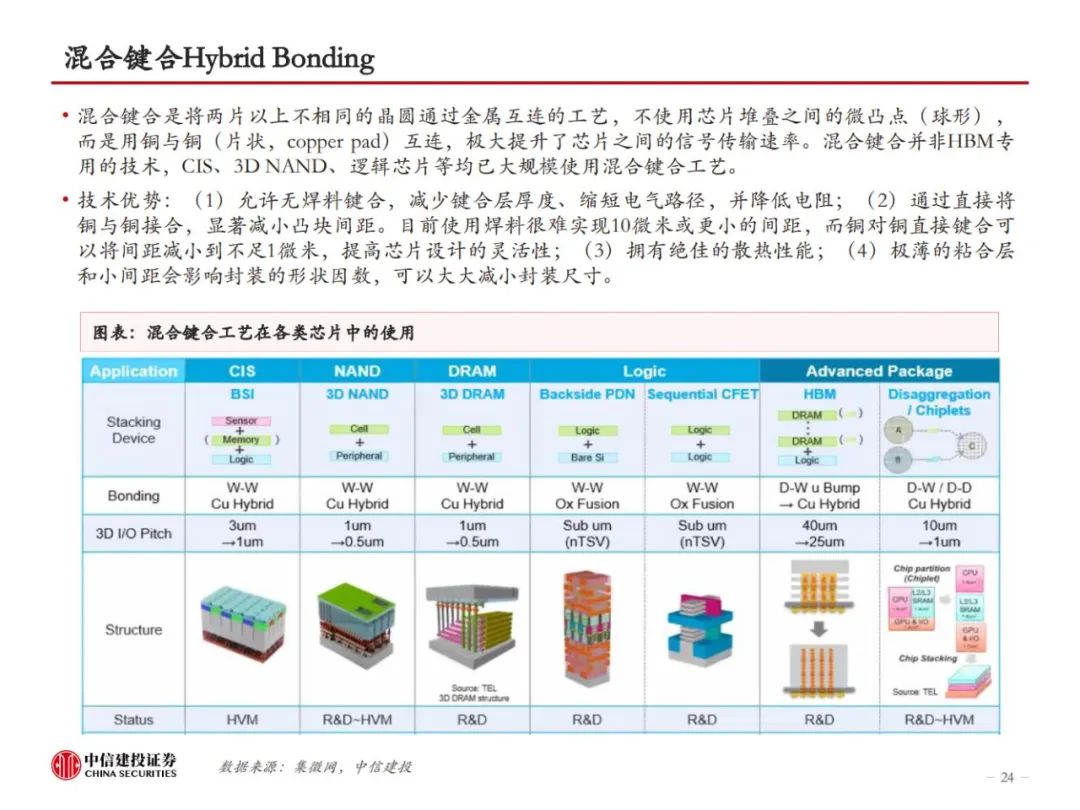
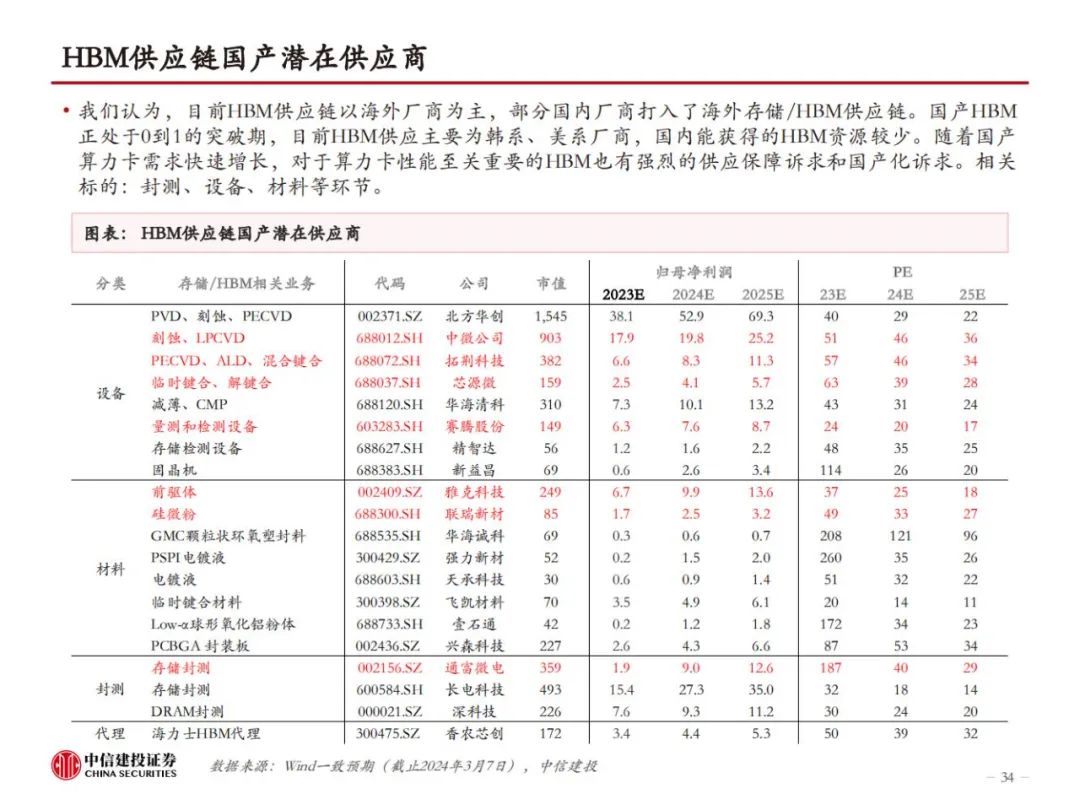
HBM制造集成前道工艺与先进封装,TSV、EMC、键合工艺是关键。HBM制造的关键在于TSV DRAM,以及每层TSV DRAM之间的连接方式。目前主流的HBM制造工艺是TSV+Micro bumping+TCB,例如三星的TC-NCF工艺,而SK海力士则采用改进的MR-MUF工艺,在键合应力、散热性能、堆叠层数方面更有优势。目前的TCB工艺可支撑最多16层的HBM生产,随着HBM堆叠层数增加,以及HBM对速率、散热等性能要求的提升,HBM4开始可能引入混合键合工艺,对应的,TSV、GMC/LMC的要求也将提高。















【终稿】2024年中国AR产业发展洞察研究
AI的内存瓶颈,高壁垒高增速(2024)
2024年AIGC发展趋势报告
2、电源管理芯片行业概览及研究框架
3、中国半导体系列报告:电源管理芯片行业概览
4、电源管理芯片研究框架《HotChips 2023及历年技术合集(汇总)》AI服务器催化HBM需求爆发,核心工艺变化带来供给端增量(2024)服务器行业报告:AI和东数西算双轮驱动,服务器在启航(2024)新进封装加速迭代,迈向2.5D 3D封装(2024)1、人工智能专题研究(一):大模型推动各行业AI应用渗透
2、人工智能专题研究(二):AI大模型开展算力竞赛,打开AI芯片、光模块和光芯片需求缺口
3、人工智能专题研究(三):Gemini 1.0有望拉动新一轮AI产业革新,算力产业链受益确定性强
4、人工智能专题研究(四):OpenAI发布Sora文生视频模型,AI行业持续高发展硅光技术产业深度研究:芯片出光,硅光技术开启高速与高集成度传输时代半导体检测行业报告:集成电路国产化加速,第三方检测发展空间广阔算力国产化大势所趋,昇腾构建自主高端AI计算竞争力2023人工智能专题报告:AI大模型应用中美比较研究华为发布会:Mate60系列引领创新,全场景新品技术升级走进芯时代(77):XR身处人文与科技十字路口,开启空间计算时代走进芯时代(60):AI算力GPU,AI产业化再加速,智能大时代已开启走进芯时代(58):高性能模拟替代渐入深水区,工业汽车重点突破走进芯时代(57):算力大时代,处理器SOC厂商综合对比走进芯时代(49):“AI芯片”,AI领强算力时代,GPU启新场景落地走进芯时代(46):“新能源芯”,乘碳中和之风,基础元件腾飞走进芯时代(43):显示驱动芯—面板国产化最后一公里走进芯时代(74):以芯助先进算法,以算驱万物智能本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。