

大家好,我是杂烩君。
嵌入式代码优化是一个复杂的过程,它不仅取决于代码本身,还取决于目标硬件平台、编译器以及优化的目标(例如速度、内存使用、功耗等)。
不过,有一些通用的技巧可以在编写嵌入式代码时考虑到:
在内存空间较为充足的情况下,有时候可以牺牲一些空间来换取程序的运行速度。查表法就是 以空间换取时间 的典型例子。
比如:编写程序统计一个8bit(0x0~0xFF)数据中1的个数。
使用查表法:
static int table[16] = {0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4};
int get_digits_1_num(unsigned char data)
{
int cnt = 0;
unsigned char temp = data & 0xf;
cnt = table[temp];
return cnt;
}
优于:
int get_digits_1_num(unsigned char data)
{
int cnt = 0;
unsigned char temp = data & 0xf;
for (int i = 0; i < 4; i++)
{
if (temp & 0x01)
{
cnt++;
}
temp >>= 1;
}
return cnt;
}
查表法把0x0~0xF中的所有数据中每个数据的1的个数都记录下来,存放到一个表中。这样一来,数据与数据中1的个数就建立起了一一对应关系,就可以通过数组索引来获取得到结果。常规法使用for循环的方式来实现,缺点是占用了不少处理器的时间。
特别地,对于越复杂地运算,查表法较常规法更有优势。另一方面,查表法的代码往往比常规法要简洁些。
C99中,结构体中的最后一个元素允许是未知大小的数组,这就叫作 柔性数组 。
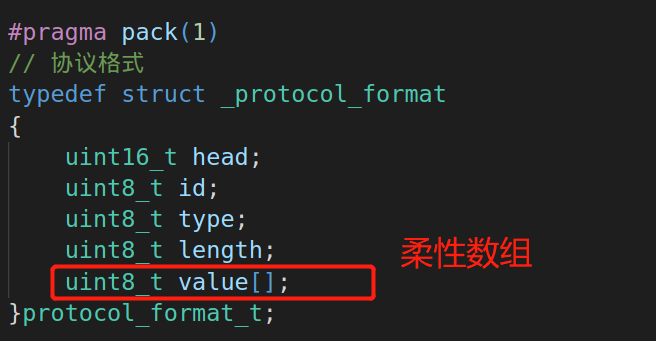
柔性数组的特点:
在C99标准环境中,使用柔性数组:
typedef struct _protocol_format
{
uint16_t head;
uint8_t id;
uint8_t type;
uint8_t length;
uint8_t value[];
}protocol_format_t;
优于使用指针:
typedef struct _protocol_format
{
uint16_t head;
uint8_t id;
uint8_t type;
uint8_t length;
uint8_t *value;
}protocol_format_t;
柔性数组的方式结构体占用较指针的方式少。
柔性数组的方式相对与指针的方式更为简洁,给结构体申请空间的同时也给柔性数组申请空间,柔性数组的方式只需要申请一次空间,是一块连续内存,连续的内存有益于提高访问速度;而指针的方式,除了给结构体申请空间之外,还得给结构体里的指针成员申请空间。
使用指针的方式写代码会比柔性数组的方式会繁琐一些,特别地,如果在释放内存的时候把顺序弄反了,则结构体里的指针成员所指向的内存就释放不掉,会造成内存泄露。
有些数据在存储时并不需要占用一个完整的字节,只需要占用一个或几个二进制位即可。
比如:管理一些标志位。
使用位域:
struct {
unsigned char flag1:1;
unsigned char flag2:1;
unsigned char flag3:1;
unsigned char flag4:1;
unsigned char flag5:1;
unsigned char flag6:1;
unsigned char flag7:1;
unsigned char flag8:1;
} flags;
优于:
struct {
unsigned char flag1;
unsigned char flag2;
unsigned char flag3;
unsigned char flag4;
unsigned char flag5;
unsigned char flag6;
unsigned char flag7;
unsigned char flag8;
} flags;
使用位操作:
uint32_t val = 1024;
uint32_t doubled = val << 1;
uint32_t halved = val >> 1;
优于:
uint32_t val = 1024;
uint32_t doubled = val * 2
uint32_t halved = val / 2
有时候,可以牺牲一点代码的简洁度、减少循环控制语句的执行频率以提高性能。
无依赖的循环展开:
process(array[0]);
process(array[1]);
process(array[2]);
process(array[3]);
优于:
for (int i = 0; i < 4; i++)
{
process(array[i]);
}
有依赖的循环展开:
long calc_sum(int *a, int *b)
{
long sum0 = 0;
long sum1 = 0;
long sum2 = 0;
long sum3 = 0;
for (int i = 0; i < 250; i += 4)
{
sum0 += arr0[i + 0] * arr1[i + 0];
sum1 += arr0[i + 1] * arr1[i + 1];
sum2 += arr0[i + 2] * arr1[i + 2];
sum3 += arr0[i + 3] * arr1[i + 3];
}
return (sum0 + sum1 + sum2 + sum3);
}
优于:
long calc_sum(int *a, int *b)
{
long sum = 0;
for (int i = 0; i < 1000; i ++)
{
sum += arr0[i] * arr1[i];
}
return sum;
}
尽可能把长的有依赖的代码链分解成几个可以在流水线执行单元中并行执行的没有依赖的代码链,提高流水线的连续性。通常4次展开为最佳方式。
使用内联函数替换重复的短代码,一方面,可以避免函数的回调,加速了程序的执行,利用指令缓存,增强局部访问性;另一方面,可以方便代码管理。
如:翻转led的操作。
static inline void toggle_led(uint8_t pin)
{
PORT ^= 1 << pin;
}
// 这会减少函数调用的开销,因为函数体会直接嵌入到调用点
toggle_led(LED_PIN);
首先使用合适的数据类型。
比如几种数据类型都满足需求的情况下,更小的可能并不是最合适的。
比如:素组索引的变量类型。
数组索引应尽量采用int类型。
int i;
for (i = 0; i < N; i++)
{
// ...
}
优于:
char i;
for (i = 0; i < N; i++)
{
// ...
}
定义为char类型,一般会有溢出的风险,因此编译器需要使用多余的指令判断是否溢出;而使用int类型,一般编译器默认不会超过这么大的循环次数,从而减少了不必要的指令。
其它情况下,在满足数据范围的情况下,能够使用字符型(char)定义的变量,就不要使用整型(int)变量来定义;能够使用整型变量定义的变量就不要用长整型(long int),能不使用浮点型(float)变量就不要使用浮点型变量。
长循环在最内层:
for (col = 0; col < 5; col++)
{
for (row = 0; row < 100; row++)
{
sum = sum + a[row][col];
}
}
优于长循环在最外层:
for (row = 0; row < 100; row++)
{
for(col=0; col < 5; col++ )
{
sum = sum + a[row][col];
}
}
在多重循环中,应当将最长的循环放在最内层, 最短的循环放在最外层,以减少 CPU 跨切循环层的次数。
通常,循环并不需要全部都执行。
例如,如果我们在从数组中查找一个特殊的值,一经找到,我们应该尽可能早的断开循环。例如:如下循环从10000个整数中查找是否存在-99。
char found = FALSE;
for(i = 0; i < 10000; i++)
{
if (list[i] == -99)
{
found = TRUE;
}
}
if (found)
{
printf("Yes, there is a -99. Hooray!\n");
}
这段代码无论我们是否查找得到,循环都会全部执行完。更好的方法是一旦找到我们查找的数字就终止继续查询。把程序修改为:
found = FALSE;
for (i = 0; i < 10000; i++)
{
if (list[i] == -99)
{
found = TRUE;
break;
}
}
if (found)
{
printf("Yes, there is a -99. Hooray!\n");
}
假如待查数据位于第23个位置上,程序便会执行23次,从而节省9977次循环。
必要时,手动对齐结构体的内存排列。
比如:
typedef struct test_struct
{
char a;
short b;
char c;
int d;
char e;
}test_struct;
该结构体在32bit环境中,该结构体所占的字节数为16。
可以手动调整各成员的位置来进行空白字节填充以达到对齐的效果。如:
typedef struct test_struct
{
char a;
char c;
short b;
int d;
char e;
}test_struct;
则结构体变量test_s所占的字节数变为12字节,比原来的16字节省下了4个字节。
确保中断处理快速且尽可能短。
// 中断例程应该尽量简短
void ISR()
{
flag = true;
}
使用硬件模块或特有指令来减轻CPU负担。
// 比如,直接使用DMA传输而不经由CPU
DMA_Config(&src, &dest, length);
DMA_Start();
以上就是本次的分享。一些优化可能会增加代码的复杂性或降低可读性或其它方面的影响,因此在决定应用优化时,需权衡不同方面的影响。
