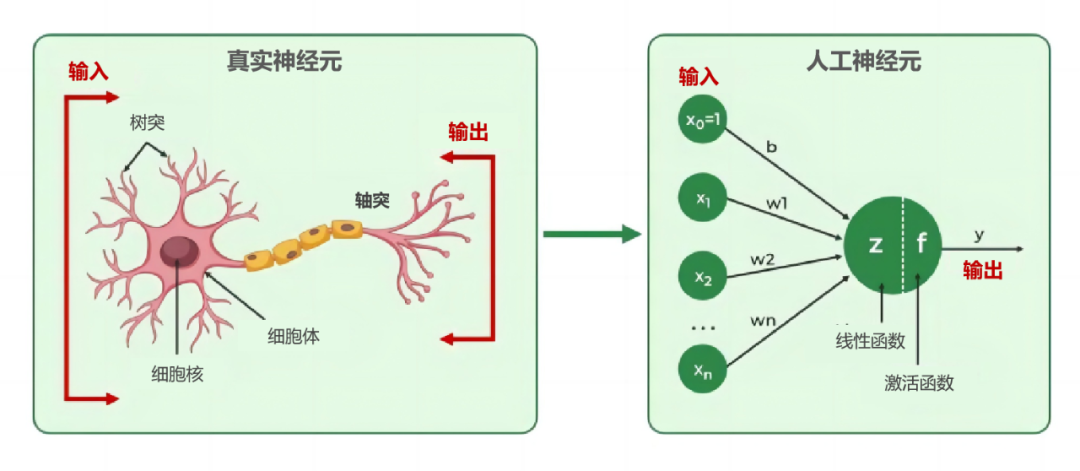
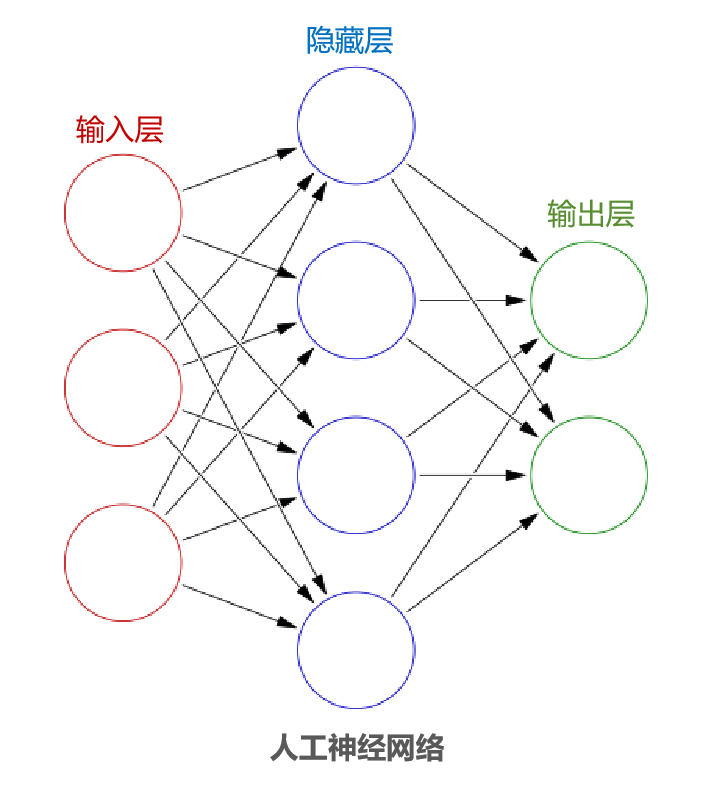
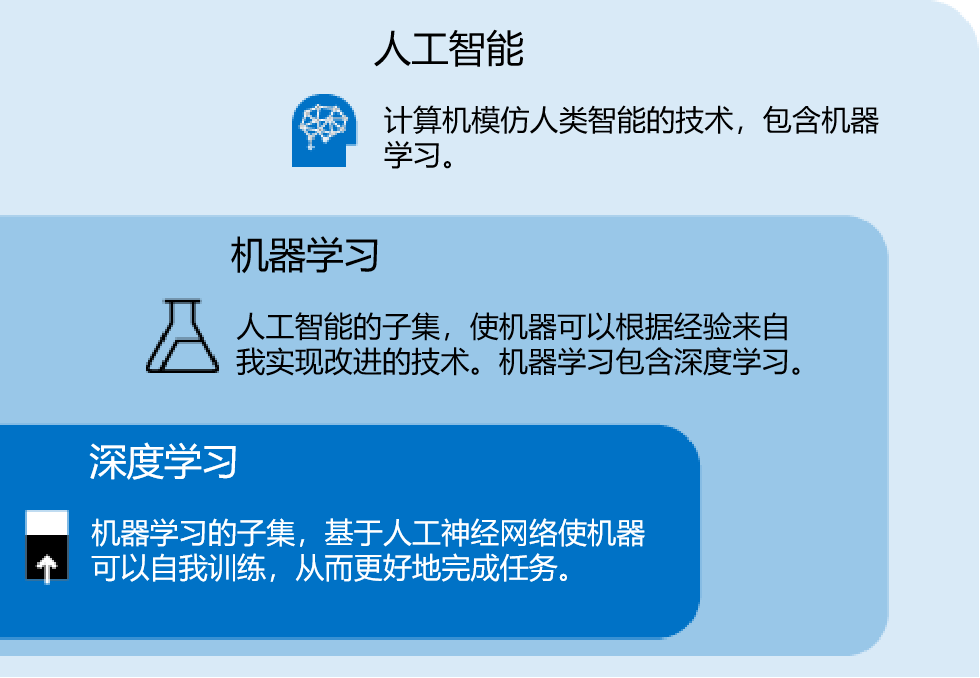
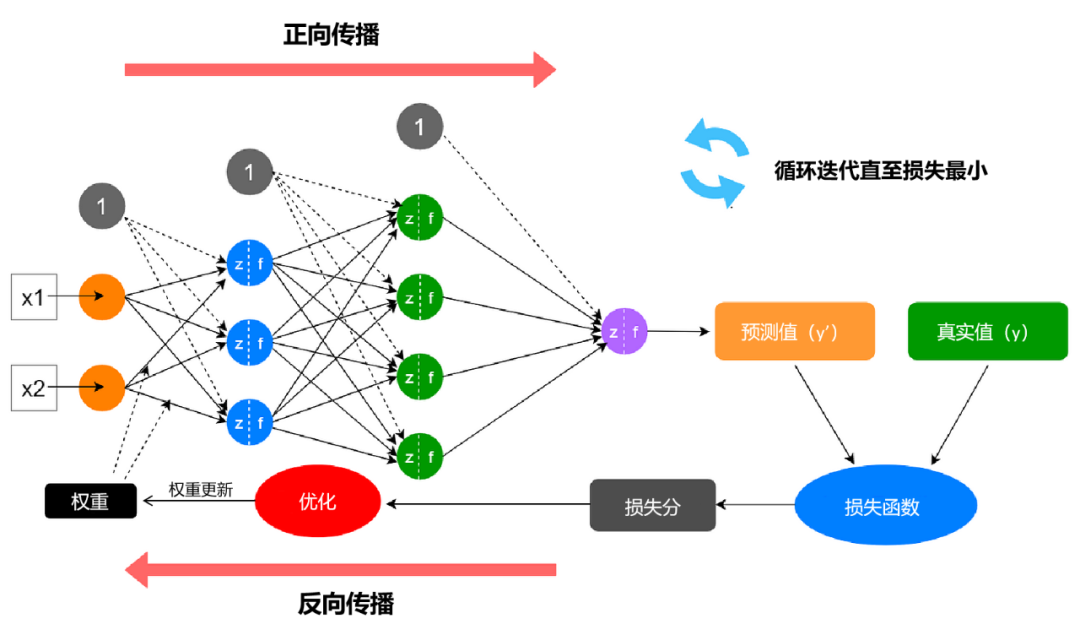
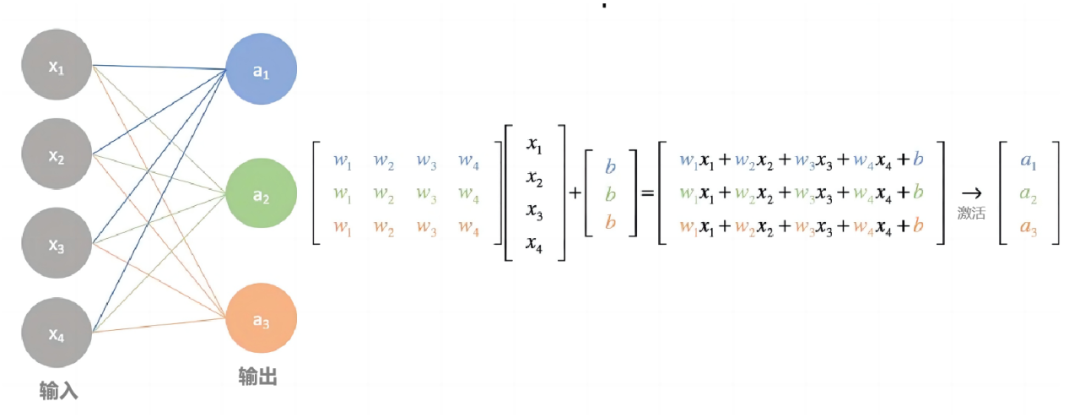
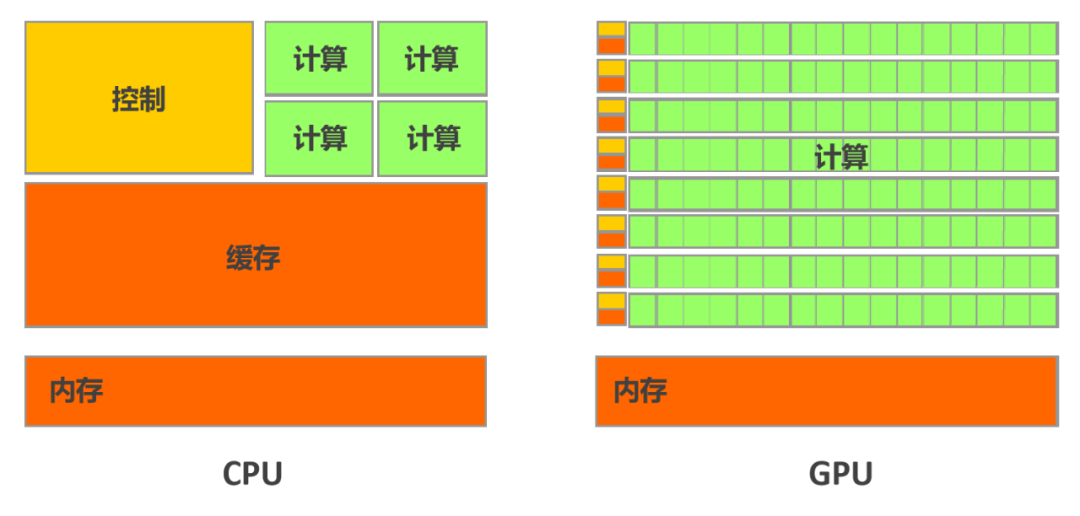
一、技术背景与市场机遇在智能家居高速发展的今天,用户对家电设备的安全性、智能化及能效表现提出更高要求。传统取暖器因缺乏智能感知功能,存在能源浪费、安全隐患等痛点。WTL580-C01微波雷达感应模块的诞生,为取暖设备智能化升级提供了创新解决方案。该模块凭借微波雷达技术优势,在精准测距、环境适应、能耗控制等方面实现突破,成为智能取暖器领域的核心技术组件。二、核心技术原理本模块采用多普勒效应微波雷达技术,通过24GHz高频微波信号的发射-接收机制,实现毫米级动作识别和精准测距。当人体进入4-5米有效