

Hex文件格式(本文讲的是Intel Hex)是好多好多年以前定义的格式,解析这文件的工具网上搜出来的也是一大摞一大摞的。记住,我们就别瞎折腾自己写一个了哦。我们要学会站在巨人的肩膀上做开发,别干那些重复又累人的活儿。
话说回来,常用的解析Hex文件的工具有:IntelHex(Python),bincopy(Python)以及SRecordizer(C++),当然还有其他的,如BIN2MOT、binex 等等。
今天,我就教大家用IntelHex来玩转Hex文件,玩起来,Hex和Bin是没区别的!
等等,如果你还不了解Hex文件格式,请戳《SREC、Hex、Bin等烧录文件格式完全解读》。
如果你精通Hex文件格式,我也不介意你自己手动敲一个,但我教你个快捷的办法:
from intelhex import IntelHexih = IntelHex()for i in range(256):ih[i] = iih.tofile("hex256.hex", format="hex")ih.tofile("hex256.bin", format="bin")
生成出来的是长这样的:
:10000000000102030405060708090A0B0C0D0E0F78:10001000101112131415161718191A1B1C1D1E1F68:10002000202122232425262728292A2B2C2D2E2F58:10003000303132333435363738393A3B3C3D3E3F48:10004000404142434445464748494A4B4C4D4E4F38:10005000505152535455565758595A5B5C5D5E5F28:10006000606162636465666768696A6B6C6D6E6F18:10007000707172737475767778797A7B7C7D7E7F08:10008000808182838485868788898A8B8C8D8E8FF8:10009000909192939495969798999A9B9C9D9E9FE8:1000A000A0A1A2A3A4A5A6A7A8A9AAABACADAEAFD8:1000B000B0B1B2B3B4B5B6B7B8B9BABBBCBDBEBFC8:1000C000C0C1C2C3C4C5C6C7C8C9CACBCCCDCECFB8:1000D000D0D1D2D3D4D5D6D7D8D9DADBDCDDDEDFA8:1000E000E0E1E2E3E4E5E6E7E8E9EAEBECEDEEEF98:1000F000F0F1F2F3F4F5F6F7F8F9FAFBFCFDFEFF88:00000001FF
而其bin形式内容是:
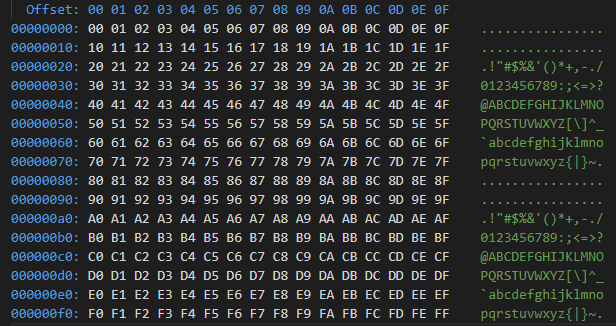
另外,如果想将生产的hex文件当字符串使用,可以直接使用Python内置的StringIO,像这样:
from io import StringIOfrom intelhex import IntelHexih = IntelHex()= 0x10= 0x11= 0x12sio = StringIO()ih.write_hex_file(sio)hexstr = sio.getvalue()sio.close()print(hexstr)
:03000A00101112C0
:00000001FF
这里面这个strhex就是这个Hex文件的字符串形式,可以直接在代码里面使用。
你不要看小这个读功能哦,它不但可以将Hex文件读出来使用,而且还可以将Bin文件读出来当Hex来使用。
ih = IntelHex() # create empty objectih.loadhex('hex256.hex') # load from hex#ih.loadfile('hex256.hex',format='hex') # also load from hex#ih.fromfile('hex256.hex',format='hex') # also load from hex
以上,这里有三种方法(loadhex、loadfile、fromfile)将Hex文件load进来,都是一样的结果。
同样道理,我们来试试load Bin文件试试:
ih = IntelHex() # create empty objectih.loadbin('hex256.bin') # load from bin#ih.fromfile('hex256.bin',format='bin') # also load from bin
以上办法,是将整个Bin文件load进去的,如果将这个Bin文件load到一个特定地址开始呢?
ih1.loadbin('hex256.bin',offset=40) # load binary data and place them注意这个load进去的文件,是从offset地址开始填充Bin内容的,offset之前的内容是用默认值替代的。
我们可以测试下:
ih2 = IntelHex() # create empty objectih2.loadbin('hex256.bin',offset=40)print(ih2[38],ih2[39],ih2[40],ih2[41])
255 255 0 1
ih = IntelHex('hex256.hex')这个多简单,但是注意,这种方法是load不了Bin文件的,当然,你可以用这种方法load一个初始化好的对象,如:
ih = IntelHex(ih2)4. 获取文件的内容
从上面的例子可以看到,我们可以直接从对象ih加个下标来取取内容。
要注意下,这个ih[x]取出来的值是整型的,范围是0-255,而这个x就是Bin内容的地址。
我们不止可以用ih[x]读数据,还能写数据,如ih[x] = y
实际上,这个取值和赋值是Python类里面的两个不同方法:__getitem__和__setitem__,如果你有超大量的数据要读或者写,效率就不说话那么高了。当然,如果你只是操作1MB以内的内容,也无所谓了。后续我会解释有没有提高效率的方法。
这个是比较常用的,其实也很简单,直接用tobinfile就可以解决。
ih = IntelHex('hex256.hex')ih.tobinfile('hex2bin.bin')
我们还可以将Bin文件转换成Bin文件,呃呃……我是说提取你想要的片段
ih2.tobinfile('hex2bin.bin', 35, 45)注意,这个35是提取的起始地址,45是结束地址。
这个hex2bin.bin文件就是这样的:
0000: FF FF FF FF FF 00 01 02 03 04 05
其中里面的FF就是默认值,其实我们可以用padding改变它,如果需要的话:
ih2.padding = 0x55ih2.tobinfile('hex2bin.bin', 35, 45)
这就变成了:
0000: 55 55 55 55 55 00 01 02 03 04 05
这里有个做好的hex2bin.py脚本,非常方便使用
Usage:
python hex2bin.py [options] INFILE [OUTFILE]
Arguments:
INFILE name of hex file for processing.
OUTFILE name of output file. If omitted then output
will be writing to stdout.
Options:
-h, --help this help message.
-p, --pad=FF pad byte for empty spaces (hex value).
-r, --range=START:END specify address range for writing output
(hex value).
Range can be in form 'START:' or ':END'.
-l, --length=NNNN,
-s, --size=NNNN size of output (decimal value).
例如可以这样的:
python hex2bin.py -r 0000:00FF foo.hex
倒过来也行,首先将Bin load成一个IntelHex对象,然后调用ih.tofile(fout, format='hex')即可
ih2 = IntelHex()ih2.loadbin('hex256.bin',offset=40)ih2.tofile('bin2hex.hex', format='hex')
到这里,你会发现,这跟转Bin不是一样的吗,是的,一样。只要你有一个IntelHex对象,你就可以随意转Hex或者Bin了。
这里有个做好的bin2hex.py脚本,非常方便使用
Usage:
python bin2hex.py [options] INFILE [OUTFILE]
Arguments:
INFILE name of bin file for processing.
Use '-' for reading from stdin.
OUTFILE name of output file. If omitted then output
will be writing to stdout.
Options:
-h, --help this help message.
--offset=N offset for loading bin file (default: 0).
有时候,你是不是想想看看Bin文件里面的内容而要去找能显示Bin内容的编辑器啊,例如WinHex或者Notepad++的Hex插件。或者你想看看Hex文件里面的实际内存,而找不到理想的工具啊。
我这里有个简便的方法。
ih2.dump()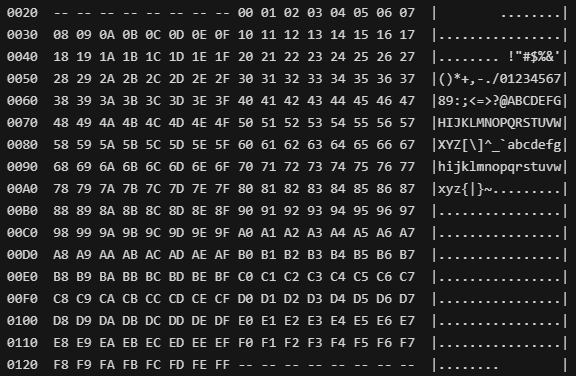
呵呵,就这么简单粗暴。
当然,这个dump是有参数的,你可以根据你的需要做不同处理
def dump(self, tofile=None, width=16, withpadding=False):"""Dump object content to specified file object or to stdout if None.Format is a hexdump with some header information at the beginning,addresses on the left, and data on right.@param tofile file-like object to dump to@param width number of bytes per line (i.e. columns)@param withpadding print padding character instead of '--'@raise ValueError if width is not a positive integer"""
这里有个做好的hex2dump.py脚本,非常方便使用
Usage:
python hex2dump.py [options] HEXFILE
Options:
-h, --help this help message.
-r, --range=START:END specify address range for dumping
(ascii hex value).
Range can be in form 'START:' or ':END'.
Arguments:
HEXFILE name of hex file for processing (use '-' to read
from stdin)
如果有两个Hex,想将他们合并成一个,你会怎么做?
IntelHex有现成的方法,也非常简便
ih1 = IntelHex()ih2 = IntelHex()ih1[0] = 0ih1[1] = 1ih2[1] = 11ih2[5] = 5ih2[6] = 6ih1.merge(ih2, overlap='ignore')ih1.dump()
0000 00 01 -- -- -- 05 06 -- -- -- -- -- -- -- -- -- |.. .. |
以上merge函数的参数overlap要注意下,有三种选择:
overlap='error', 表示如果ih1和ih2有重复的内容,运行这函数会产生Error;overlap='ignore',表示如果ih1和ih2有重复的内容,运行这函数会忽略ih2的这个重复值;overlap='replace',表示如果ih1和ih2有重复的内容,运行这函数会将ih2的重复值替换到ih1对应的位置。
另外,这个merge是不限于两个Hex的哦,Hex和Bin合并也行。
为了方便使用,这里有个现成的脚本hexmerge.py
Usage:
python hexmerge.py [options] FILES...
Options:
-h, --help this help message.
-o, --output=FILENAME output file name (emit output to stdout
if option is not specified)
-r, --range=START:END specify address range for output
(ascii hex value).
Range can be in form 'START:' or ':END'.
--no-start-addr Don't write start addr to output file.
--overlap=METHOD What to do when data in files overlapped.
Supported variants:
* error -- stop and show error message (default)
* ignore -- keep data from first file that
contains data at overlapped address
* replace -- use data from last file that
contains data at overlapped address
Arguments:
FILES list of hex files for merging
(use '-' to read content from stdin)
You can specify address range for each file in the form:
filename:START:END
See description of range option above.
You can omit START or END, so supported variants are:
filename:START: read filename and use data starting from START addr
filename::END read filename and use data till END addr
Use entire file content:
filename
or
filename::
对于比较Bin文件还好,找个BeyondCompare就非常直观地看到差异。如果要比较两个Hex呢,或者Hex和Bin比较呢?
from intelhex import diff_dumpsdiff_dumps(ih1, ih2)
--- a
+++ b
@@ -1 +1 @@
-0000 00 01 -- -- -- 05 06 -- -- -- -- -- -- -- -- -- |.. .. |
+0000 -- 0B -- -- -- 05 06 -- -- -- -- -- -- -- -- -- | . .. |
熟悉Linux上的diff命令就很容易理解了,不详细解释这个diff格式了,有感兴趣可以网上搜索diff查看,很详细很容易理解。
为了方便使用,这里有个现成的脚本hexmerge.py
hexdiff: diff dumps of 2 hex files.
Usage:
python hexdiff.py [options] FILE1 FILE2
Options:
-h, --help this help message.
-v, --version version info.
ih = IntelHex('hex256.hex')data_prefix = "const unsigned char hexdata[] = \n{"data_subfix = "\n};\n"print(data_prefix, end='')for i, data in enumerate(ih.tobinarray()):if(i%16 == 0): print("\n ", end='')print("0x%02X, "%data, end='')print(data_subfix)
const unsigned char hexdata[] ={0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x0A, 0x0B, 0x0C, 0x0D, 0x0E, 0x0F,0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x16, 0x17, 0x18, 0x19, 0x1A, 0x1B, 0x1C, 0x1D, 0x1E, 0x1F,0x20, 0x21, 0x22, 0x23, 0x24, 0x25, 0x26, 0x27, 0x28, 0x29, 0x2A, 0x2B, 0x2C, 0x2D, 0x2E, 0x2F,0x30, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37, 0x38, 0x39, 0x3A, 0x3B, 0x3C, 0x3D, 0x3E, 0x3F,0x40, 0x41, 0x42, 0x43, 0x44, 0x45, 0x46, 0x47, 0x48, 0x49, 0x4A, 0x4B, 0x4C, 0x4D, 0x4E, 0x4F,0x50, 0x51, 0x52, 0x53, 0x54, 0x55, 0x56, 0x57, 0x58, 0x59, 0x5A, 0x5B, 0x5C, 0x5D, 0x5E, 0x5F,0x60, 0x61, 0x62, 0x63, 0x64, 0x65, 0x66, 0x67, 0x68, 0x69, 0x6A, 0x6B, 0x6C, 0x6D, 0x6E, 0x6F,0x70, 0x71, 0x72, 0x73, 0x74, 0x75, 0x76, 0x77, 0x78, 0x79, 0x7A, 0x7B, 0x7C, 0x7D, 0x7E, 0x7F,0x80, 0x81, 0x82, 0x83, 0x84, 0x85, 0x86, 0x87, 0x88, 0x89, 0x8A, 0x8B, 0x8C, 0x8D, 0x8E, 0x8F,0x90, 0x91, 0x92, 0x93, 0x94, 0x95, 0x96, 0x97, 0x98, 0x99, 0x9A, 0x9B, 0x9C, 0x9D, 0x9E, 0x9F,0xA0, 0xA1, 0xA2, 0xA3, 0xA4, 0xA5, 0xA6, 0xA7, 0xA8, 0xA9, 0xAA, 0xAB, 0xAC, 0xAD, 0xAE, 0xAF,0xB0, 0xB1, 0xB2, 0xB3, 0xB4, 0xB5, 0xB6, 0xB7, 0xB8, 0xB9, 0xBA, 0xBB, 0xBC, 0xBD, 0xBE, 0xBF,0xC0, 0xC1, 0xC2, 0xC3, 0xC4, 0xC5, 0xC6, 0xC7, 0xC8, 0xC9, 0xCA, 0xCB, 0xCC, 0xCD, 0xCE, 0xCF,0xD0, 0xD1, 0xD2, 0xD3, 0xD4, 0xD5, 0xD6, 0xD7, 0xD8, 0xD9, 0xDA, 0xDB, 0xDC, 0xDD, 0xDE, 0xDF,0xE0, 0xE1, 0xE2, 0xE3, 0xE4, 0xE5, 0xE6, 0xE7, 0xE8, 0xE9, 0xEA, 0xEB, 0xEC, 0xED, 0xEE, 0xEF,0xF0, 0xF1, 0xF2, 0xF3, 0xF4, 0xF5, 0xF6, 0xF7, 0xF8, 0xF9, 0xFA, 0xFB, 0xFC, 0xFD, 0xFE, 0xFF,};
从以上的案例,我们可以学习到,可以通过对象加下标可以取值,那么我们也可以写个Checksum或CRC函数直接计算。
但是,这并非很好的方法,因为对于大数据量的Hex文件,这效率很低的。如果文件不是特别大,电脑内存允许的情况下,可以直接转成Bin再算Checksum,这样效率会高很多。
from intelhex import IntelHeximport binasciiih = IntelHex('hex256.hex')val = binascii.crc32(ih.tobinarray())print("CRC32 = 0x%08X"%val)
CRC32 = 0x29058C73
Hex文件里会有很多空隙,会分成很多段,我们想查看或者获取这些信息,怎么做呢?
ih = IntelHex()ih[1] = 1ih[2] = 1ih[3] = 1ih[7] = 1ih[8] = 1ih[11] = 1ih[12] = 1print(ih.segments())ih.tofile("hexsegments.hex", format='hex')
[(1, 4), (7, 9), (11, 13)]
实际上这个segments获取的是从哪个地址到哪个地址是有内容的。
这里还有个更方便的方法,hexinfo.py
hexinfo: summarize a hex file's contents.
Usage:
python hexinfo.py [options] FILE [ FILE ... ]
Options:
-h, --help this help message.
-v, --version version info.
例如
python hexinfo.py hexsegments.hex
得到的信息是:
- file: './hexsegments.hex'
data:
- { first: 0x00000001, last: 0x00000003, length: 0x00000003 }
- { first: 0x00000007, last: 0x00000008, length: 0x00000002 }
- { first: 0x0000000B, last: 0x0000000C, length: 0x00000002 }
注:上文提到的脚本:
bin2hex.py
hex2bin.py
hex2dump.py
hexdiff.py
hexinfo.py
hexmerge.py
请见:
https://github.com/python-intelhex/intelhex
如果无法访问,在公众号对话框回复Hex获取下载链接。

