图像融合旨在将来自不同源图像的互补信息融合在一起,生成一幅具有更高质量、更多信息量和更清晰的图像。红外与可见光图像融合(IVIF)是图像融合领域的研究热点。
据麦姆斯咨询报道,近期,江苏海洋大学电子工程学院的科研团队在《激光与光电子学进展》期刊上发表了以“红外与可见光图像融合:统计分析,深度学习方法和未来展望”为主题的文章。该文章第一作者为吴一非,通讯作者为杨瑞。
本文将依次回顾红外与可见光图像融合传统方法和基于深度学习的方法,并对前沿深度学习方法做重点论述。同时,对图像融合领域的性能评价方法进行系统分类和介绍;最后,对全文进行了总结以及对IVIF方法的展望。
IVIF传统方法的融合框架主要包括三个关键部分:图像配准与变换、特征提取与选择和融合规则设计。
基于多尺度变换的方法
IVIF传统方法中,基于多尺度变换是最受欢迎的方法之一。它的主要步骤包括三个阶段:第一阶段,将源图像分解成一系列的多尺度表示;第二阶段,根据手工设计的融合规则融合多尺度变换;最后,利用多尺度逆变换得到融合图像。经典的多尺度变换方法包括金字塔变换、小波变换、多尺度几何分析和边缘保持滤波器。
基于稀疏表示的方法
与带前缀基函数的多尺度变换IVIF方法不同,基于稀疏表示(SR)的方法通过学习过完备字典,能够有效地表示和提取图像信息。然而,配准误差或噪声可能会对融合后的多尺度表示系数造成偏差,造成视觉伪影。SR利用滑动窗口技术将图像分成多个重叠的块,将其矢量化以减少伪影并提高对配准不良的鲁棒性。
基于SR的IVIF方法有三个关键步骤:构建过完备字典、稀疏编码和融合策略。过完备字典的质量决定了稀疏编码的信号表示能力,可以将基于SR的方法按照构建过完备字典分为两类:固定基和基于学习的方法。用固定基构建过完备字典简单且计算效率高,而基于学习方法构建的过完备字典更灵活有效。
基于子空间的方法
基于子空间的方法,是传统方法中比较常用的一种方法。这种方法通过将高维输入图像投影到低维空间或子空间中,捕获源图像的内部结构。典型的基于子空间的方法包括主成分分析、独立成分分析和非负矩阵分解。
基于显著性的方法
基于显著性的IVIF方法可以保持显著目标区域的完整性,减少噪声、模糊和其他干扰,从而提高融合图像的视觉质量和清晰度。权重计算和提取显著对象是红外与可见光融合中两种常见的显著性方法。
基于深度学习的方法
基于自动编码器(AE)的方法
由于神经网络在数据驱动模式下具有较强的非线性拟合能力,为了进一步提高图像融合质量,研究者们提出了一系列基于AE的融合方法,融合框架如图1所示。该类方法一般由两个步骤组成:首先,使用大型数据集预训练自动编码器,其中编码器用于特征提取,解码器用于图像重建。然后,大多结合手工设计的融合策略将编码特征进行融合以实现最终的图像融合。
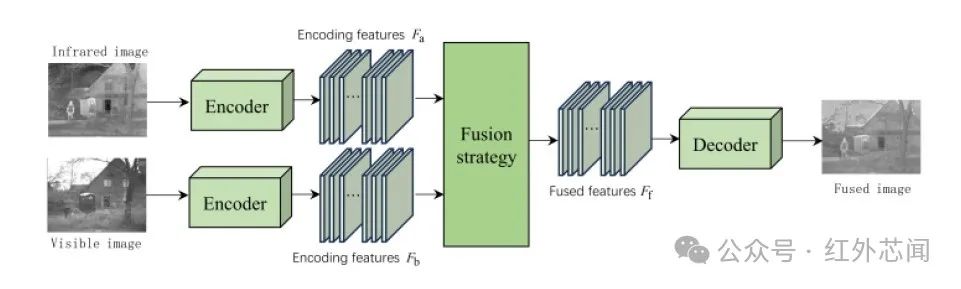
图1 基于AE的IVIF框架
基于AE的方法都采用了手动设计的融合策略,尽管取得了不错的融合效果,但融合结果可能并不理想。解决手工设计融合策略问题是改进基于AE方法的一个研究方向。
基于卷积神经网络(CNN)的方法
CNN是一种典型的神经网络模型,具有很强的特征提取能力。基于CNN的IVIF方法(如图2)通常依靠神经网络强大的拟合能力,在精心设计的损失函数或真值标签下实现有效信息的提取和重构。
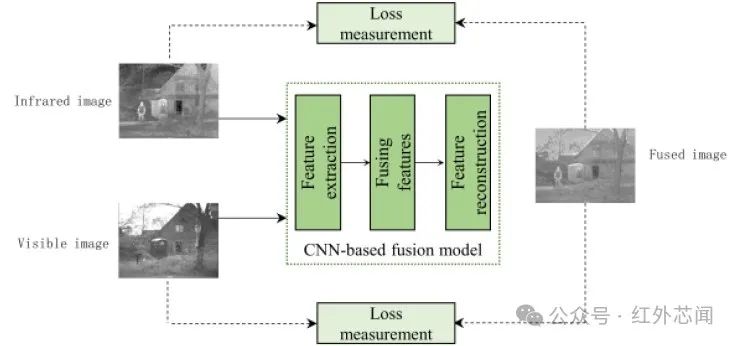
图2 基于CNN的IVIF框架
基于生成对抗网络(GAN)的方法
随着生成对抗网络(GAN)的出现,由于其能够生成信息丰富、视觉效果良好的图像,因此在图像IVIF领域得到了广泛应用。基于GAN的图像融合网络(如图3)主要由生成器和判别器组成,通过利用判别器对生成器生成的融合图像与判别依据进行判别,其中判别依据可以是源图像,也可以是其他方法生成的融合图像。如果判别为假,通过不断调整生成器的参数重新生成融合图像,直到判别器判别为真,通过上述对抗过程最终生成更高质量的融合图像。
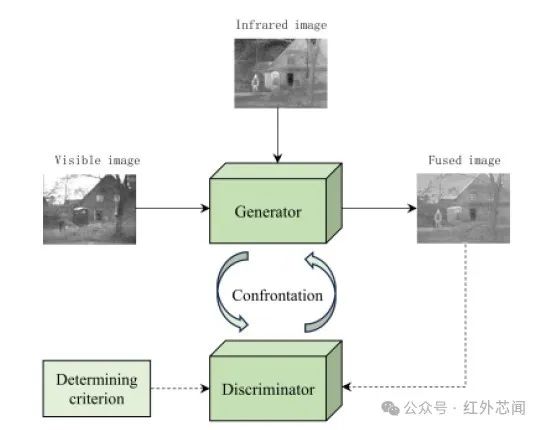
图3 基于生成对抗网络GAN的IVIF框架
基于变换器(Transformer)的方法
现有的基于深度学习的方法通常采用卷积操作进行特征提取,捕获图像局部特征;但容易忽略图像中存在的远距离依赖关系,训练过程中会损失一定的全局信息。近年来,一些最新的图像融合研究工作发现,Transformer在处理序列数据和建模远距离依赖关系方面表现出色,研究人员提出了很多基于Transformer的IVIF方法,融合框架如图4所示。
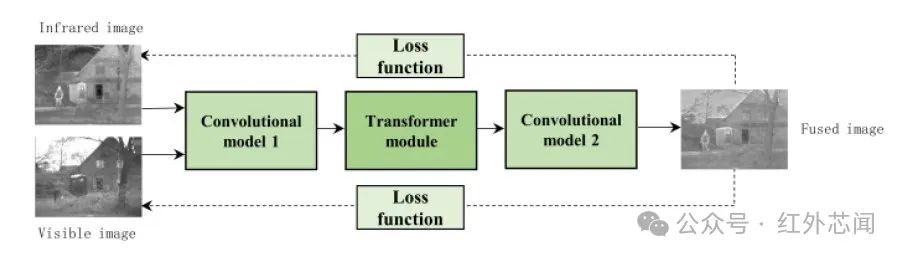
图4 基于Transformer的IVIF框架
IVIF技术已广泛应用于目标识别、视频监控和医疗卫生等领域。然而,不同融合方法得到的融合图像具有不同特点,而融合图像的质量很大程度上影响着实际应用中的性能。因此,研究人员提出了许多方法来评估融合图像的质量,这些方法可以分为主观评价方法和客观评价方法。
主观评价方法
主观评价方法是最直接的评价方法,可以反映人类对多种因素(如清晰度、对比度、颜色自然度等)的主观感知,从而更真实地评估图像融合结果对视觉的影响,更接近实际应用中人们的实际感受。然而,受主观性和主观偏见等因素的影响,为了更准确地评估图像融合算法,通常会将主观评价与客观评价方法相结合,以获得更全面、可靠的评价结果。
客观评价方法
客观评价方法旨在量化评估融合图像与源图像之间的差异,以判断融合算法的性能和效果。这些方法利用各种指标和技术来测量融合后图像的质量、信息保留程度、对比度、颜色平衡等方面的特征。
综上所述,红外与可见光图像融合的客观评价指标主要从融合图像的信息量、特征、结构、视觉效果和相关系数等方面进行评价。其中,信息论类指标主要关注图像信息的增益,特征类指标反映图像的亮度、对比度等特征,结构相似性类指标注重衡量图像结构的相似性,视觉感知类指标强调图像视觉信息的保留量,而相关性类指标主要考虑图像之间的相关性。因此,在实际应用中可以根据任务需求选择适当的指标类别,或者根据具体情况综合考虑不同类别的指标来评价融合结果的性能。
本文对三大工程类在线文献数据库近20年相关论文发表情况进行了分析,并单独对各类基于深度学习的IVIF算法文献发表数量统计分析,研究发展趋势,为IVIF的新技术研究提供参考。同时,在此基础上回顾了IVIF技术的研究现状,介绍了传统方法,并详细比较了基于深度学习的方法。此外,还对五大类IVIF图像融合性能评价方法进行了比较分析。
目前红外与可见光图像融合技术已经许多成果,但是仍有还存在许多问题亟待研究者们去解决。在未来一段时间内,改进红外与可见光图像融合方法将包括以下几个方面:
(1)图像配准方法的研究。现有融合算法大多都是基于已配准的源图像。然而,在实际应用中,不同类型传感器很难捕获空间严格对齐的图像,空间信息的不匹配将极大影响融合图像的质量。因此,精确的配准算法的研究就显得尤为重要。
(2)融合图像色彩保真度问题。现有IVIF方法大多只关注于融合可见光图像的梯度信息和红外图像的强度信息,很少注意到保留可见光图像中颜色信息的重要性。但是从Yue等人研究中可以清楚地发现具有高色彩保真度的图像更适合人类的视觉感知。因此,在保留强度信息和梯度信息的同时,保留可见光图像的色彩保真度是未来提升融合图像质量的一个重要研究方向。
(3)提升图像融合的效率。近年来研究者基于深度学习的方法,提出了更大更深的模型来提升图像融合的性能,但同时影响了图像的融合效率。未来IVIF方法的高效性也是研究者的重点关注方向之一。
(4)创新基于Transformer的方法。目前,已经涌现了很多基于Transformer的IVIF方法,但是,将Transformer应用到IVIF任务中还处于起步状态,未来将会浮现出更多基于Transformer的IVIF方法,Transformer解决全局依赖关系的能力会被更多、更好的挖掘。
(5)结合高级视觉任务。现有的大部分IVIF 方法都能够很好的加强红外与可见光融合的图像视觉质量,获得不错的定量指标。但是,目前方法中针对下游应用任务的要求考虑较少,不能很好的满足下游应用的具体需求。所以,在保持良好图像融合效果的情况下,又能符合具体视觉任务需求将是今后研究的一个重要课题之一。
(6)完善的性能评价方法。红外与可见光图像融合由于没有真值标签,如何准确评估融合算法的性能没有统一完善的标准。不同的研究需求和应用领域可能会选择不同的评价指标,这使得比较不同方法的结果变得有挑战性。所以,需要进一步建立一种更为通用、公平和能被广泛接受的图像融合评价标准。
DOI: 10.3788/LOP232360
延伸阅读:
《新兴图像传感器技术及市场-2024版》
《光谱成像市场和趋势-2022版》



