关注+星标公众号,不错过精彩内容

转自 | 瑞萨嵌入式小百科
什么是人工智能?
人类科技发展日新月异、突飞猛进,不断涌现令人激动的新技术。当前,人工智能(Artificial Intelligent)当属最热门的技术之一。
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。它是一个构建能够推理、学习和行动的计算机和机器的科学领域,这种推理、学习和行动通常需要人类智力,或者涉及超出人类分析能力的数据规模。
下图中的人工智能、机器学习、深度学习、数据挖掘、模式识别等,这些非常相关的术语或知识我们经常看到,也见到很多关于它们之间关系的文章和讨论。一般来说,人工智能是一个很大的研究领域,是很多学科交叉形成的;机器学习是人工智能的一个分支,提供很多算法,深度学习又是机器学习的一个重要分支,它基于人工神经网络;而数据挖掘、模式识别是偏向算法应用的部分。它们之间相辅相成,另外也需要其他领域的知识支持。
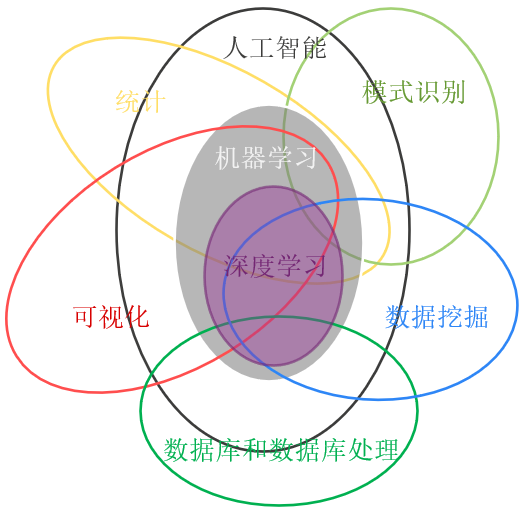
人工智能的目标包括:推理、知识表示、自动规划、机器学习、自然语言理解、计算机视觉、机器人学和强人工智能共八个方面。
• 知识表示和推理包括:命题演算和归结、谓词演算和归结,可以进行一些公式或定理的推导。
• 自动规划包括机器人的计划、动作和学习,状态空间搜索,敌对搜索,规划等内容。
• 机器学习这一研究领域是由AI的一个子目标发展而来,用来帮助机器和软件进行自我学习来解决遇到的问题。
• 自然语言处理是另一个由AI的一个子目标发展而来的研究领域,用来帮助机器与真人进行沟通交流。
• 计算机视觉是由AI的目标而兴起的一个领域,用来辨认和识别机器所能看到的物体。
• 机器人学也是脱胎于AI的目标,用来给一个机器赋予实际的形态以完成实际的动作。
• 强人工智能是人工智能研究的最主要目标之一,强人工智能也指通用人工智能(Artificial General Intelligence,AGI),或具备执行一般智慧行为的能力。强人工智能通常把人工智能和意识、感性、知识和自觉等人类的特征互相连结。

人工智能的三要素:数据、算法、模型。
• 数据是基础,基于数据发现数据的规律。
• 算法是关键,如何用数据去求解模型,变成可以运行的程序。
• 模型是核心,用何种模型解释数据,发现数据规律。
人工智能之机器学习
机器学习是人工智能的一个重要分支,它通过计算的手段、学习经验(也可以说是利用经验)来改善系统的性能。它包括:有监督学习、无监督学习和强化学习。其中的算法有:回归算法(最小二乘法、LR等),基于实例的算法(KNN、LVQ等),正则化方法(LASSO等),决策树算法(CART、C4.5、RF等),贝叶斯方法(朴素贝叶斯、BBN等),基于核的算法(SVM、LDA等),聚类算法(K-Means、DBSCAN、EM等),关联规则(Apriori、FP-Grouth),遗传算法,人工神经网络(PNN、BP等),深度学习(RBN、DBN、CNN、DNN、LSTM、GAN等),降维方法(PCA、PLS等),集成方法(Boosting、Bagging、AdaBoost、RF、GBDT等)。
人工智能之深度学习
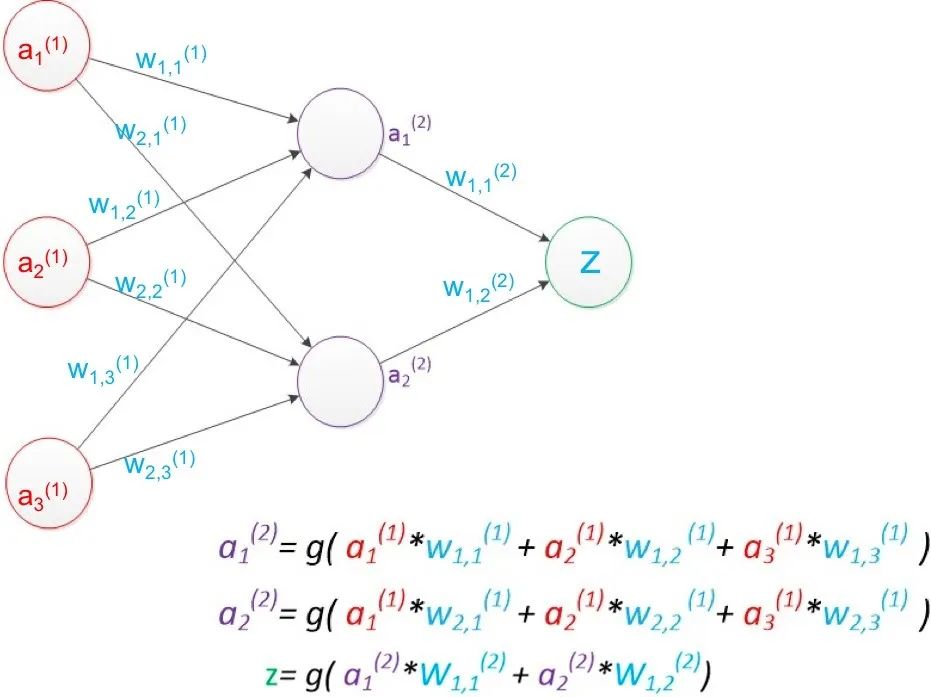
深度学习是机器学习的一个重要分支,它基于人工神经网络。深度学习的学习过程之所以是深度性的,是因为人工神经网络的结构由多个输入、输出和隐藏层构成。每个层包含的单元可将输入数据转换为信息,供下一层用于特定的预测任务。得益于这种结构,机器可以通过自身的数据处理进行学习。以两层网络为例,如下图,其中a是“单元”的值,w表示“连线”权重,g是激活函数,一般为方便求导采用sigmoid函数。采用矩阵运算来简化图中公式:a(2) = g( a(1) * w(1) ), z = g( a(2) * w(2) )。设训练样本的真实值为y,预测值为z,定义损失函数 loss = (z – y)2,所有参数w优化的目标就是使对所有训练数据的损失和尽可能的小,此时这个问题就被转化为一个优化问题,常用梯度下降算法求解。一般使用反向传播算法,从后往前逐层计算梯度,并最终求解各参数矩阵。
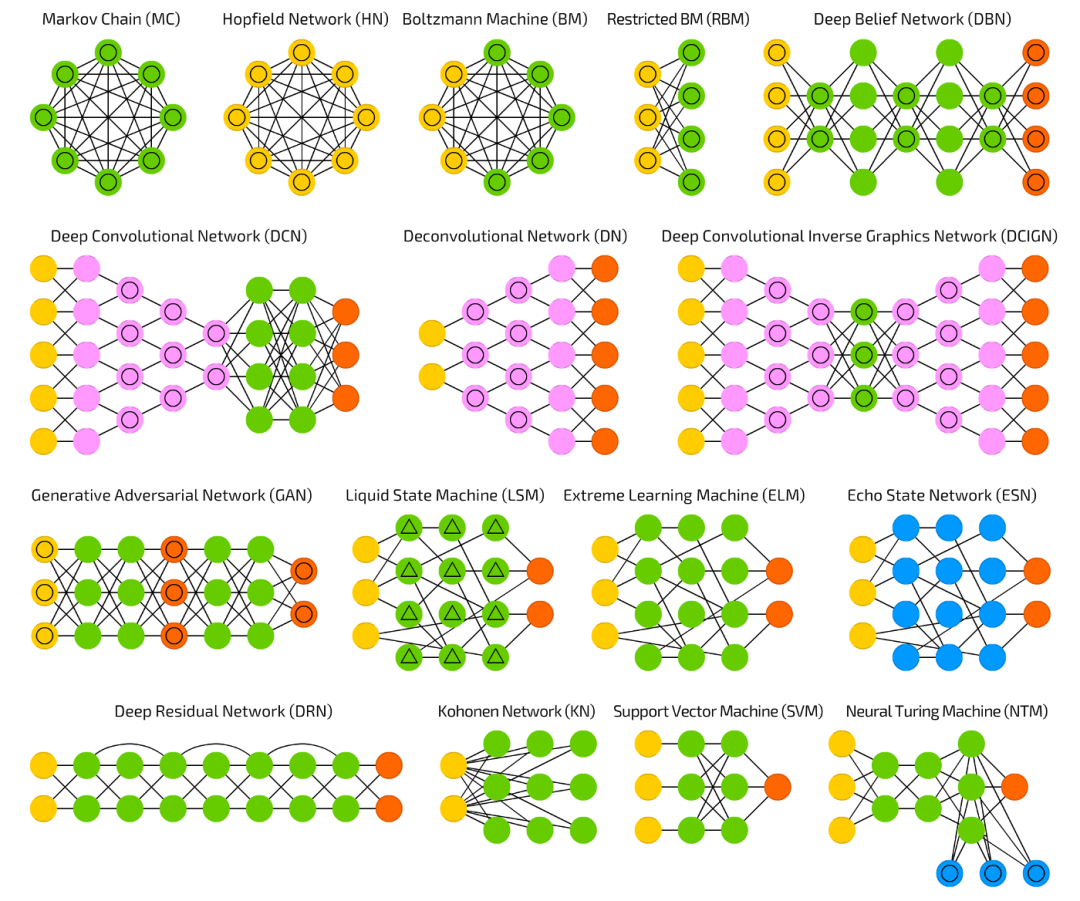
人工智能之传统机器学习
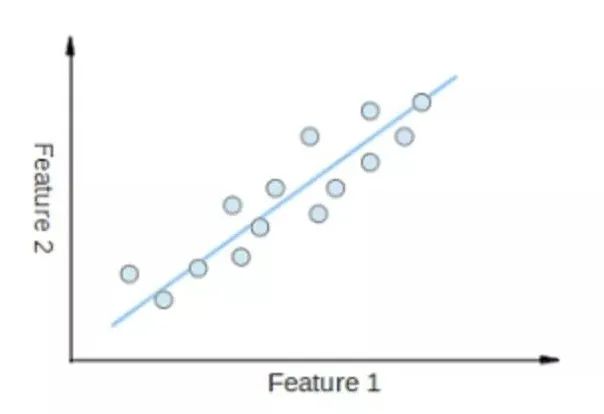
• 线性回归(Liner Regression)
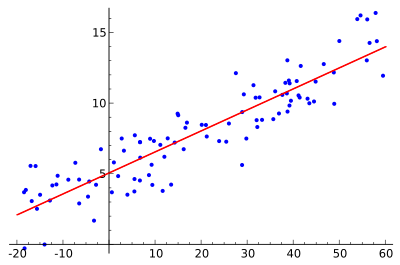
o 线性回归就是找到一条直线,使用数据点来寻找最佳拟合线。它试图通过将直线方程与该数据拟合来表示自变量(x值)和数值结果(y值)。如公式,y=kx+b,y是因变量,x是自变量,利用给定的数据集求k和c的值。
• 逻辑回归(Logistic Regression)
o 逻辑回归与线性回归类似,但它用于输出二元分类情况(即,输出结果只有两个可能值),对最终输出的预测是一个非线性的S型函数。
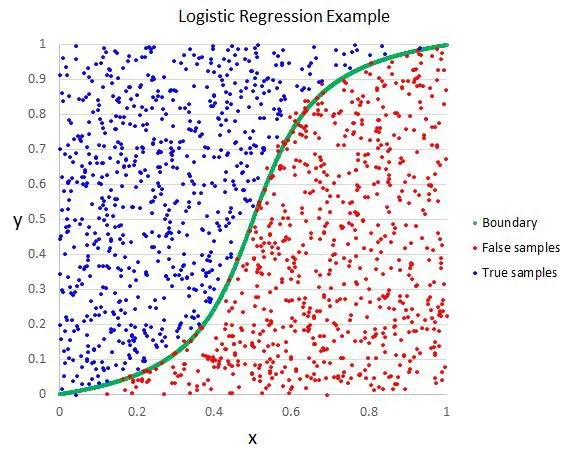
这个逻辑函数将中间结果映射到结果变量y,其值范围在0和1之间。这些值是y出现的概率。S型逻辑函数的性质让逻辑回归更适合用于分类问题。
• 决策树(Decision Tree)
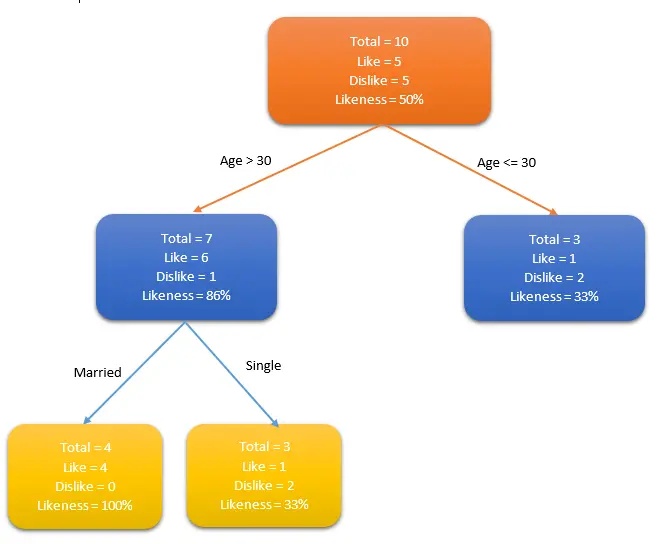
o 决策树用于回归和分类问题。训练模型通过学习树表示的决策规则来学习预测目标变量的值。树是具有相应属性的节点组成的。在每个节点上,根据可用的特征询问有关数据问题,左右分支表示可能的答案,最终节点(叶节点)对应一个预测值。每个特征的重要性是通过自顶而下方法确定的,节点越高,其属性越重要。如下图人群中谁喜欢使用信用卡例子中,如果一个人结婚了,他超过30岁,他们更有可能拥有信用卡(100%偏好)。测试数据用于生成决策树。
• 朴素贝叶斯(Naïve Bayes)
o 朴素贝叶斯基于贝叶斯定理。它测量每个类的概率,每个类的条件概率给出x值。这个算法用于分类问题,得到一个二进制”是/非”的结果。

• 支持向量机(Support Vector Machine/SVM)
o 支持向量机是一种用来解决二分类问题的机器学习算法,它通过在样本空间中找到一个划分超平面,将不同类别的样本分开,同时使得两个点集到此平面的最小距离最大,两个点集中的边缘点到此平面的距离最大。如下图所示,图中有黑点和白点两类样本,支持向量机的目标就是找到一条直线(H3),将黑点和白点分开,同时所有黑点和白点到这条直线(H3)的距离加起来的值最大。
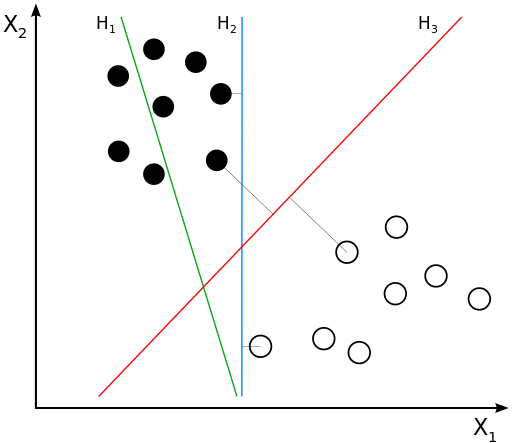
• K-最近邻算法(K-Nearest Neighbors/KNN)
o KNN算法是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习。用最近的邻居(k)来预测未知数据点。k值是预测精度的一个关键因素,无论是分类还是回归,衡量邻居的权重都非常有用,较近邻居的权重比较远邻居的权重大。KNN算法的缺点是对数据的局部结构非常敏感。计算量大,需要对数据进行规范化处理,使每个数据点都在相同的范围。
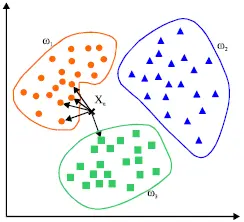
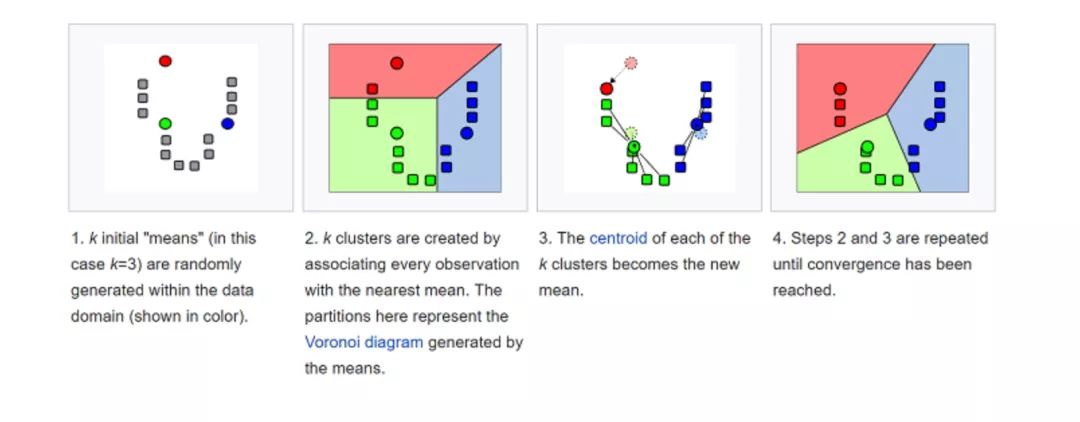
• K均值(K-Means)
o k-平均算法(K-Means)是一种无监督学习算法,为聚类问题提供了一种解决方案。K-Means算法把n个点(可以是样本的一次观察或一个实例)划分到k个集群(cluster),使得每个点都属于离他最近的均值(即聚类中心,centroid)对应的集群。重复上述过程一直持续到重心不改变。
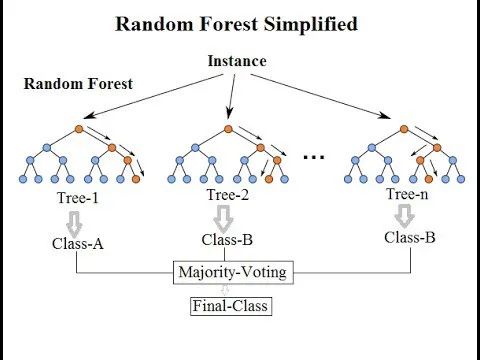
• 随机森林(Random Forest)
o 随机森林(Random Forest)是一种非常流行的集成机器学习算法。这个算法的基本思想是,许多人的意见要比个人的意见更准确。在随机森林中,我们使用决策树集成(参见决策树)。为了对新对象进行分类,我们从每个决策树中进行投票,并结合结果,然后根据多数投票做出最终决定。
• 降维(Dimensional Reduction)
o 降维是指在限定条件下,降低随机变量个数,得到一组“不相关”主变量的过程,并可进一步细分为特征选择和特征提取两大方法。

嵌入式界的机器视觉Vision Board开发板来了

业界首款Cortex-M85 MCU性能到底如何?

MCU百万次读写闪存测试
