
----追光逐电 光赢未来----

为图像分类而创建和训练的神经网络确定图像上物体的类别,并返回其名称和这种预测的概率。例如,在左边的图像上,它返回了这是一只 "猫",这个预测的置信度是92%(0.92)。
对象检测的神经网络,除了对象类型和概率外,还返回对象在图像上的坐标:X、Y、宽度和高度,如第二张图像所示。此外,物体检测神经网络可以检测到图像上的几个物体及其边界框。
最后,除了物体类型和边界框之外,为图像分割而训练的神经网络还能检测物体的形状,如右图所示。
有许多不同的神经网络架构是为这些任务开发的,对于每一项任务,过去你都必须使用一个单独的网络。幸运的是,在YOLO创建之后,情况发生了变化。现在你可以使用一个单一的平台来解决所有这些问题。
在这篇文章中,我们将发现使用YOLOv8的物体检测。我将指导你如何创建一个网络应用,用它来检测图像上的交通灯和路标。在接下来的文章中,我将介绍其他功能,包括图像分割。
在接下来的章节中,我将展示创建一个物体检测器所需的所有具体步骤。按照这个步骤,在阅读结束时,你将会有一个工作的人工智能驱动的网络应用。
所以,请确保你的电脑上安装了Python和Jupyter笔记本,让我们开始吧。
二、开始使用yolov8
从技术上讲,YOLOv8是一组卷积神经网络模型,使用PyTorch框架创建和训练。
此外,YOLOv8软件包提供了一个单一的Python API,可以使用相同的方法与所有这些模型一起工作。这就是为什么,要使用它,你需要一个运行Python代码的环境。我强烈建议使用Jupyter笔记本。
要使用PIP将YOLOv8安装到你的电脑上,在Jupyter笔记本中运行以下命令:
!pip install ultralytics进入全屏模式 退出全屏模式
ultralytics 包中有一个YOLO 类,用于创建神经网络模型。
要访问它,请将其导入你的Python代码中:
from ultralytics import YOLO进入全屏模式 退出全屏模式
现在一切准备就绪,可以创建神经网络模型了:
model = YOLO("yolov8m.pt")正如我之前写的,YOLOv8是一组神经网络模型。这些模型是用PyTorch创建和训练的,并导出为扩展名为.pt 的文件。有三种类型的模型存在,每种类型有5个不同大小的模型:
你选择的模型越大,你可以获得更好的预测质量,但它的工作速度会越慢。在本教程中,我将介绍物体检测,这就是为什么在前面的代码片段中,我选择了 "yolov8m.pt",这是一个用于物体检测的中等大小的模型。
当你第一次运行这段代码时,它将从Ultralytics服务器下载yolov8m.pt 文件到当前文件夹,然后,将构建model 对象。现在你可以训练这个model ,检测对象,并输出到生产中使用。对于所有这些任务,它有方便的方法:
train({path to dataset descriptor file})- 用来训练图像数据集的模型。
predict({image})- 用于对指定的图像进行预测,例如,检测所有物体的边界框,该模型可以在该图像上找到。
export({format})- 用于将该模型从默认的PyTorch格式导出到指定的格式。
所有用于物体检测的YOLOv8模型已经在COCO数据集上进行了预训练,COCO数据集是一个由80种类型的图像组成的巨大集合。因此,如果你没有特别的需求,那么你可以按原样运行它,而不需要额外的训练。例如,你可以下载这张图片为 "cat_dog.jpg":

并运行predict 来检测上面的所有物体:
results = model.predict("cat_dog.jpg")predict 方法接受许多不同的输入类型,包括一张图片的路径、一个图片的路径数组、著名的PILPython库的Image对象等。
在通过模型运行输入后,它为每个输入图像返回一个结果数组。因为我们只提供了一张图片,所以它返回一个只有一个项目的数组,你可以用这种方式提取:
result = results[0]这个结果包含了检测到的对象和方便处理它们的属性。最重要的是boxes 数组,里面有检测到的图像上的边界框的信息。你可以通过运行len 函数来确定检测到多少个对象:
len(result.boxes)当我运行这个函数时,我得到了 "2",这意味着有两个盒子被检测到,可能一个是狗,一个是猫。
然后,你可以在一个循环中分析每个盒子,或者手动分析。让我们得到第一个:
box = result.boxes[0]盒子对象包含包围盒的属性,包括
xyxy - 盒子的坐标,是一个数组 [x1,y1,x2,y2] 。
cls - 对象类型的ID
conf - 模型对这个对象的信心水平。如果它非常低,比如< 0.5,那么你可以直接忽略这个盒子。
让我们打印一下检测到的盒子的信息:
print("Object type:", box.cls)print("Coordinates:", box.xyxy)print("Probability:", box.conf)
对于第一个盒子,你会收到以下信息:
Object type: tensor([16.])Coordinates: tensor([[261.1901, 94.3429, 460.5649, 312.9910]])Probability: tensor([0.9528])
如上所述,YOLOv8包含PyTorch模型。PyTorch模型的输出被编码为PyTorch Tensor对象的数组,所以你需要从每个数组中提取第一项:
print("Object type:",box.cls[0])print("Coordinates:",box.xyxy[0])print("Probability:",box.conf[0])
Object type: tensor(16.)Coordinates: tensor([261.1901, 94.3429, 460.5649, 312.9910])Probability: tensor(0.9528)
现在你看到的数据是Tensor 对象。要从张量中解压实际值,你需要对内部有数组的张量使用.tolist() 方法,对有标量值的张量使用.item() 方法。让我们把数据提取到适当的变量中:
cords = box.xyxy[0].tolist()class_id = box.cls[0].item()conf = box.conf[0].item()print("Object type:", class_id)print("Coordinates:", cords)print("Probability:", conf)
Object type: 16.0Coordinates: [261.1900634765625, 94.3428955078125, 460.5649108886719, 312.9909973144531]Probability: 0.9528293609619141
现在你看到了实际的数据。坐标可以四舍五入,概率也可以四舍五入到点后的两位数。
这里的对象类型是16 。它是什么意思呢?让我们再来谈谈这个问题。所有神经网络能够检测到的物体都有数字ID。在YOLOv8的预训练模型中,有80个对象类型,ID从0到79。COCO的对象类别是众所周知的,可以很容易地在互联网上搜索到。此外,YOLOv8的结果对象包含方便的names 属性来获得这些类别:
print(result.names){0: 'person',1: 'bicycle',2: 'car',3: 'motorcycle',4: 'airplane',5: 'bus',6: 'train',7: 'truck',8: 'boat',9: 'traffic light',10: 'fire hydrant',11: 'stop sign',12: 'parking meter',13: 'bench',14: 'bird',15: 'cat',16: 'dog',17: 'horse',18: 'sheep',19: 'cow',20: 'elephant',21: 'bear',22: 'zebra',23: 'giraffe',24: 'backpack',25: 'umbrella',26: 'handbag',27: 'tie',28: 'suitcase',29: 'frisbee',30: 'skis',31: 'snowboard',32: 'sports ball',33: 'kite',34: 'baseball bat',35: 'baseball glove',36: 'skateboard',37: 'surfboard',38: 'tennis racket',39: 'bottle',40: 'wine glass',41: 'cup',42: 'fork',43: 'knife',44: 'spoon',45: 'bowl',46: 'banana',47: 'apple',48: 'sandwich',49: 'orange',50: 'broccoli',51: 'carrot',52: 'hot dog',53: 'pizza',54: 'donut',55: 'cake',56: 'chair',57: 'couch',58: 'potted plant',59: 'bed',60: 'dining table',61: 'toilet',62: 'tv',63: 'laptop',64: 'mouse',65: 'remote',66: 'keyboard',67: 'cell phone',68: 'microwave',69: 'oven',70: 'toaster',71: 'sink',72: 'refrigerator',73: 'book',74: 'clock',75: 'vase',76: 'scissors',77: 'teddy bear',78: 'hair drier',79: 'toothbrush'}
这就是:这个模式所能检测到的一切。现在你可以发现,16 是 "狗",所以,这个边界框是检测到的DOG的边界框。让我们修改一下输出,以更有代表性的方式显示结果:
cords = box.xyxy[0].tolist()cords = [round(x) for x in cords]class_id = result.names[box.cls[0].item()]conf = round(box.conf[0].item(), 2)print("Object type:", class_id)print("Coordinates:", cords)print("Probability:", conf)
在这段代码中,我使用Python列表理解法对所有坐标进行了四舍五入,然后,我通过ID得到了检测到的对象类的名称,使用result.names 字典,也对信心进行了四舍五入。最后,你应该得到以下输出:
Object type: dogCoordinates: [261, 94, 461, 313]Probability: 0.95
这个数据已经足够显示在用户界面上了。现在让我们写一段代码,在一个循环中为所有检测到的盒子获取这些信息:
for box in result.boxes:class_id = result.names[box.cls[0].item()]cords = box.xyxy[0].tolist()cords = [round(x) for x in cords]conf = round(box.conf[0].item(), 2)print("Object type:", class_id)print("Coordinates:", cords)print("Probability:", conf)print("---")
这段代码将对每个盒子做同样的处理,并将输出以下内容:
Object type: dogCoordinates: [261, 94, 461, 313]Probability: 0.95---Object type: catCoordinates: [140, 170, 256, 316]Probability: 0.92---
Enter fullscreen mode Exit fullscreen mode
这样,你就可以玩其他的图片,看到COCO训练的模型所能检测到的一切。
另外,如果你愿意,你可以用函数式的方式重写同样的代码,使用列表理解:
def print_box(box):class_id, cords, conf = boxprint("Object type:", class_id)print("Coordinates:", cords)print("Probability:", conf)print("---")[print_box([result.names[box.cls[0].item()],[round(x) for x in box.xyxy[0].tolist()],round(box.conf[0].item(), 2)]) for box in result.boxes]
这段视频展示了本章在Jupyter Notebook中的整个编码过程,假设它已经安装
在开始时,使用对众所周知的对象进行预训练的模型是可以的,但在实践中,你可能需要一个解决方案来检测具体的业务问题的特定对象。
例如,有人可能需要检测超市货架上的特定产品或在X光片上发现脑瘤的类型。这些信息极有可能在公共数据集中无法获得,也没有免费的模型可以知道所有的事情。
因此,你必须教你自己的模型来检测这些类型的对象。要做到这一点,你需要为你的问题创建一个带注释的图像数据库,并在这些图像上训练模型。
如何准备数据来训练YoloV8模型
为了训练模型,你需要准备有注释的图像,并将它们分成训练和验证数据集。训练集将用于教导模型,验证集将用于测试本研究的结果,以衡量训练后的模型的质量。你可以把80%的图像放到训练集,20%放到验证集。
这些是你需要遵循的步骤,以创建每个数据集:
决定并编码你想教你的模型检测的对象的类别。例如,如果你只想检测猫和狗,那么你可以说 "0 "是猫,"1 "是狗。
为你的数据集建立一个文件夹,并在其中建立两个子文件夹:"图像 "和 "标签"。
将图像放到 "图像 "子文件夹中。你收集的图像越多,对训练越有利。
对于每张图片,在 "标签 "子文件夹中创建一个注释文本文件。注释文本文件的名称应与图像文件相同,扩展名为".txt"。在注释文件中,你应该添加关于每个物体的记录,这些记录以下列格式存在于相应的图像
{object_class_id} {x_center} {y_center} {width} {height}
实际上,这是机器学习过程中最枯燥的手工工作:为所有物体测量边界框并将其添加到注释文件中。此外,坐标应该被归一化,以适应从0到1的范围。要计算它们,你需要使用以下公式:
x_center = (box_x_left+box_x_width/2)/image_width
y_center = (box_y_top+box_height/2) /image_height
width = box_width/image_width
height = box_height/image_height
例如,如果你想把我们之前使用的 "cat_dog.jpg "图片添加到数据集中,你需要把它复制到 "images "文件夹中,然后测量并收集以下关于图片的数据,以及它的边界框:
图像:
image_width = 612
image_height = 415
对象:

然后,在 "标签 "文件夹中创建 "cat_dog.txt "文件,并使用上述公式,计算出坐标:
狗(类id=1):
x_center = (261+200/2)/612 = 0.589869281
y_center = (94+219/2) /415 = 0.490361446
width = 200/612 = 0.326797386
height = 219/415 = 0.527710843
猫 (class id=0):
x_center = (140+116/2)/612 = 0.323529412
y_center = (170+146/2)/415 = 0.585542169
宽度 = 116/612 = 0.189542484
高度 = 0.351807229
并在文件中添加以下几行:
1 0.589869281 0.490361446 0.326797386 0.5277108430 0.323529412 0.585542169 0.189542484 0.351807229
第一行包含狗的包围盒(class id=1),第二行包含猫的包围盒(class id=0)。当然,你可以同时拥有许多狗和许多猫的图像,你可以为它们都添加边界框。
在添加和注释了所有图像后,数据集就准备好了。你需要创建两个数据集,并把它们放在不同的文件夹里。最终的文件夹结构可以是这样的:
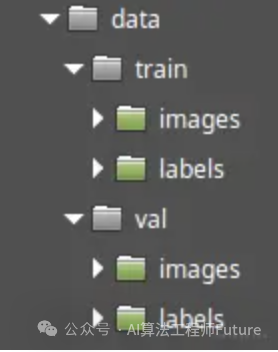
这里的训练数据集位于 "train "文件夹中,验证数据集位于 "val "文件夹中。
最后,你需要创建一个数据集描述符YAML文件,指向创建的数据集并描述其中的对象类别。这是一个关于上面创建的数据的文件的例子:
train: ../train/imagesval: ../val/imagesnc: 2names: ['cat','dog']
在前两行中,你需要指定训练数据集和验证数据集的图像的路径。这些路径可以是相对于当前文件夹的,也可以是绝对的。然后,nc ,指定这些数据集中存在的类的 数量,names ,是一个按正确顺序排列的类名数组。这些项目的索引是你在注释图像时使用的数字,这些索引将在使用predict 方法检测对象时由模型返回。所以,如果你用 "0 "表示猫,那么它应该是names 数组中的第一个项目。
这个YAML文件应该被传递给模型的train 方法,以开始一个训练过程。
为了使这个过程更容易,有很多软件可以为机器学习直观地注释图像。你可以在搜索引擎上搜索 "为机器学习注释图像的软件 "来获得一个列表。也有许多在线工具可以完成这些工作。其中一个很好的在线工具是Roboflow Annotate。使用这项服务,你只需要上传你的图像,在上面画出边界框,并为每个边界框设置类。然后,该工具将自动创建注释文件,将你的数据分成训练数据集和验证数据集,将创建一个YAML描述符文件,然后你可以将注释的数据以ZIP文件的形式导出并下载。
在下一个视频中,我将展示如何使用Roboflow来创建 "猫和狗 "的微观数据集。
对于现实生活中的问题,这个数据库应该大得多。为了训练一个好的模型,你应该有成百上千的注释图像。
另外,在准备图像数据库时,尽量使其平衡。它应该有每一类物体的相等数量,例如,狗和猫的数量相等。否则,在此基础上训练出来的模型可以预测一个类别比另一个更好。
数据准备好后,将其复制到有Python代码的文件夹中,你将使用该文件夹进行训练,然后返回Jupyter笔记本开始训练过程。
数据准备好后,你需要将其传递给模型。为了使它更有趣,我们将不使用这个小的 "猫和狗 "数据集。我们将使用其他自定义数据集进行训练。它包含交通灯和路标。这是我从Roboflow Universe获得的免费数据集:https://universe.roboflow.com/roboflow-100/road-signs-6ih4y。按 "下载数据集 "并选择 "YOLOv8 "作为格式。
如果当你读到这几行时,Roboflow上没有它,那么你可以从我的Google Drive上获得它。这个数据集可以用来教YOLOv8检测道路上的不同物体,就像下一张截图中显示的那样。

你可以打开下载的压缩文件,并确保它的结构使用上述的规则。你也可以在档案中找到数据集描述符文件data.yaml 。
如果你从Roboflow下载的档案,它将包含额外的 "测试 "数据集,它不被训练过程所使用。你可以在训练后使用其中的图像进行额外的测试。
将存档解压到装有Python代码的文件夹中,执行train 方法,开始训练循环:
model.train(data="data.yaml", epochs=30)data 是唯一需要的选项。你必须把YAML描述符文件传给它。epochs 选项指定了训练循环的数量(默认为100)。还有其他一些选项,它们会影响到训练模型的过程和质量。
每个训练周期由两个阶段组成:训练阶段和验证阶段。
在训练阶段,train 方法做了以下工作:
从训练数据集中提取随机批次的图像(默认情况下,批次大小为16,但可以使用batch 选项来改变)。
将这些图像传递给模型,并接收所有检测到的物体及其类别的结果边界框。
将结果传递给损失函数,用于比较收到的输出和这些图像的注释文件的正确结果。损失函数计算出错误的数量。
损失函数的结果传递给optimizer ,根据正确方向的误差量来调整模型的权重,以减少下一周期的误差。默认情况下,使用SGD(随机梯度下降)优化器,但你可以尝试其他的优化器,如Adam,看看有什么不同。
在验证阶段,train ,做以下工作:
从验证数据集中提取图像。
将它们传递给模型,并接收这些图像的检测边界框。
将收到的结果与来自注释文本文件的这些图像的真实值进行比较。
根据实际结果和预期结果之间的差异,计算模型的精度。
在屏幕上显示每个阶段的进展和每个纪元的结果。这样你就可以看到模型是如何从一个又一个epoch中学习和改进的。
当你运行train 代码时,你会看到训练循环中的类似输出:

对于每个epoch,它显示训练和验证阶段的总结:第1行和第2行显示训练阶段的结果,第3行和第4行显示每个epoch的验证阶段的结果。
训练阶段包括计算损失函数的误差量,因此,这里最有价值的指标是box_loss 和cls_loss 。
box_loss 显示了检测到的界线盒的误差量。
cls_loss 显示了检测到的物体类别的错误量。
如果模型真的从数据中学习到了一些东西,那么你应该看到这些值会从历时中减少。在之前的截图中,box_loss 递减:0.7751,0.7473,0.742,cls_loss 也在减少:0.702,0.6422,0.6211。
在验证阶段,它计算了使用验证数据集的图像训练后的模型质量。最有价值的质量指标是mAP50-95,这是一个平均精度。如果模型得到了学习和改进,精度应该从历时到历时的增长。在之前的截图中,它缓慢增长:0.788, 0.788, 0.781.
如果在最后一个epoch之后,你没有得到可接受的精度,你可以增加epoch的数量并再次运行训练。此外,你可以调整其他参数,如batch,lr0,lrf 或改变使用的optimizer 。这里没有明确的规则,但有很多建议可以写成一本书。但是用几句话来说,需要实验和比较结果。
除了这些指标外,train 在磁盘上工作时还会写下大量的统计数据。当训练开始时,它在当前文件夹中创建了runs/detect/train 子文件夹,在每个 epoch 之后,它向其中记录不同的日志文件。
此外,它在每个历时后将训练好的模型导出到/runs/detect/train/weights/last.pt 文件,将精度最高的模型导出到/runs/detect/train/weights/best.pt 文件。因此,在训练结束后,你可以得到best.pt 文件,在生产中使用。
观看这个视频,看看训练过程是如何进行的。我使用Google Colab,这是一个云版本的Jupyter Notebook,以获得具有更强大的GPU的硬件来加速训练过程。该视频显示了如何在5个历时上训练模型,并下载了最终的best.pt 。在现实世界的问题中,你需要运行更多的epochs,并准备好等待几个小时甚至几天,直到训练结束。
训练结束后,是时候在生产中运行训练好的模型了。在下一节中,我们将创建一个网络服务,在网络浏览器中在线检测图像上的物体。
这是一个我们在Jupyter笔记本中完成模型实验的时刻。接下来,你需要使用任何Python IDE,如VS Code或PyCharm💚,把代码写成一个单独的项目。
我们要创建的网络服务将有一个网页,其中有一个文件输入栏和一个HTML5画布元素。当用户使用输入栏选择一个图像文件时,界面将把它发送到后台。然后,后端将通过我们创建和训练的模型传递图像,并将检测到的边界框阵列返回给网页。当接收到这个信息时,前端将在画布元素上绘制图像,并在上面绘制检测到的边界框。该服务的外观和工作方式将如该视频所演示的那样:
在视频中,我使用了经过30个历时训练的模型,但它仍然没有检测到一些交通灯。你可以尝试更多的训练来获得更好的结果。然而,提高机器学习质量的最好方法是加入越来越多的数据。因此,作为一个额外的练习,你可以把数据集文件夹导入Roboflow,然后在其中添加和注释更多的图像,然后用更新的数据继续训练模型。
首先,为一个新的Python项目创建一个文件夹,并在其中为前台网页创建index.html 文件。下面是这个文件的内容
YOLOv8 Object Detection
HTML部分非常小,只包括带有 "uploadInput "ID的文件输入栏和它下面的canvas元素。然后,在Javascript部分,我们为输入栏定义了一个 "onChange "事件处理程序。当用户选择一个图像文件时,处理程序使用fetch ,向/detect 后台端点(我们将在后面创建)发出POST请求,并将这个图像文件发送给它。
后台应该检测这个图像上的对象,并以JSON的形式返回一个带有boxes 数组的响应。然后这个响应被解码,并与图像文件本身一起传递给 "draw_image_and_boxes "函数。
draw_image_and_boxes "函数从文件中加载图像,并在加载后立即将其画在画布上。然后,它在画布上画出带有类标签的每个边框和图像。
所以,现在让我们为它创建一个带有/detect 端点的后台。
我们将使用Flask]创建后端。Flask有自己的内部网络服务器,但正如Flask的开发者所说,它对于生产来说不够可靠,所以我们将使用Waitress网络服务器在其中运行Flask应用。
另外,我们将使用一个Pillow库来读取上传的二进制文件作为图像。在继续之前,请确保所有软件包都已安装到你的系统中:
pip3 install flaskpip3 install waitresspip3 install pillow
进入全屏模式 退出全屏模式
后台将是一个单一的文件。让我们把它命名为object_detector.py :
from ultralytics import YOLOfrom flask import request, Response, Flaskfrom waitress import servefrom PIL import Imageimport jsonapp = Flask(__name__)@app.route("/")def root():"""Site main page handler function.:return: Content of index.html file"""with open("index.html") as file:return file.read()@app.route("/detect", methods=["POST"])def detect():"""Handler of /detect POST endpointReceives uploaded file with a name "image_file",passes it through YOLOv8 object detectionnetwork and returns an array of bounding boxes.:return: a JSON array of objects boundingboxes in format[[x1,y1,x2,y2,object_type,probability],..]"""buf = request.files["image_file"]boxes = detect_objects_on_image(Image.open(buf.stream))return Response(json.dumps(boxes),mimetype='application/json')def detect_objects_on_image(buf):"""Function receives an image,passes it through YOLOv8 neural networkand returns an array of detected objectsand their bounding boxes:param buf: Input image file stream:return: Array of bounding boxes in format[[x1,y1,x2,y2,object_type,probability],..]"""model = YOLO("best.pt")results = model(buf)result = results[0]output = []for box in result.boxes:x1, y1, x2, y2 = [round(x) for x in box.xyxy[0].tolist()]class_id = box.cls[0].item()prob = round(box.conf[0].item(),2)output.append([x1, y1, x2, y2, result.names[class_id], prob])return outputserve(app, host='0.0.0.0', port=8080)
首先,我们导入所需的库:
ultralytics,用于YOLOv8模型。
flask用来创建一个Flask 网络应用程序,从前端接收requests ,并将responses 送回给它。
waitress运行一个web服务器,并在其中serve Flask webapp 。
PIL将上传的文件加载为Image 对象,这是YOLOv8所要求的。
json,在返回给前端之前,将边界框阵列转换为JSON。
然后,我们定义两个路由:
/ 作为网络服务的根。它只是返回 "index.html "文件的内容。
/detect 响应前台的图片上传请求。它将RAW文件转换为Pillow图像对象,然后,将此图像传递给 函数。detect_objects_on_image
detect_objects_on_image 函数创建一个模型对象,基于我们在上一节中训练的best.pt 模型。确保这个文件存在于你写代码的文件夹中。
然后它调用图像的predict 方法。predict 返回检测到的边界盒。然后,对于每个盒子,它以一种方式提取坐标、类名和概率,就像我们在教程的开头所做的那样,并将这些信息添加到输出数组中。最后,该函数返回检测到的物体坐标及其类别的数组。
之后,将数组编码为JSON并返回给前端。
最后,最后一行代码启动8080端口的网络服务器,为app Flask应用程序服务。
要运行该服务,请执行以下命令:
python3 object_detector.py如果代码写得没有错误,并且安装了所有的依赖项,你可以在网络浏览器中打开http:///localhost:8080 。它应该显示index.html 页面。当你选择任何图像文件时,它将对其进行处理,并显示所有检测到的对象周围的边界框(如果没有检测到任何东西,则只显示图像)。
我们刚刚创建的网络服务是通用的。你可以在任何YOLOv8模型中使用它。现在,它检测交通灯和路标,使用我们创建的best.pt 模型。然而,你可以改变它来使用其他的模型,比如之前用来检测猫、狗和其他物体类别的yolov8m.pt 模型,预训练的YOLOv8模型可以检测。
在本教程中,我指导你创建一个人工智能驱动的网络应用程序,该程序使用YOLOv8--用于物体检测的最先进的卷积神经网络。我们涵盖了创建模型、使用预训练的模型、准备数据以训练自定义模型等步骤,最后创建了一个带有前端和后端的网络应用,使用自定义训练的YOLOv8模型来检测交通灯和路标。
你可以在这个GitHub仓库中找到这个应用程序的源代码:https://github.com/AndreyGermanov/yolov8_pytorch_python
祝你编码愉快,永远不要停止学习!
原文链接:
https://juejin.cn/post/7225524569506709565?searchId=20240106150752E35173D7879ADB1AC8BC
来源:新机器视觉
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


