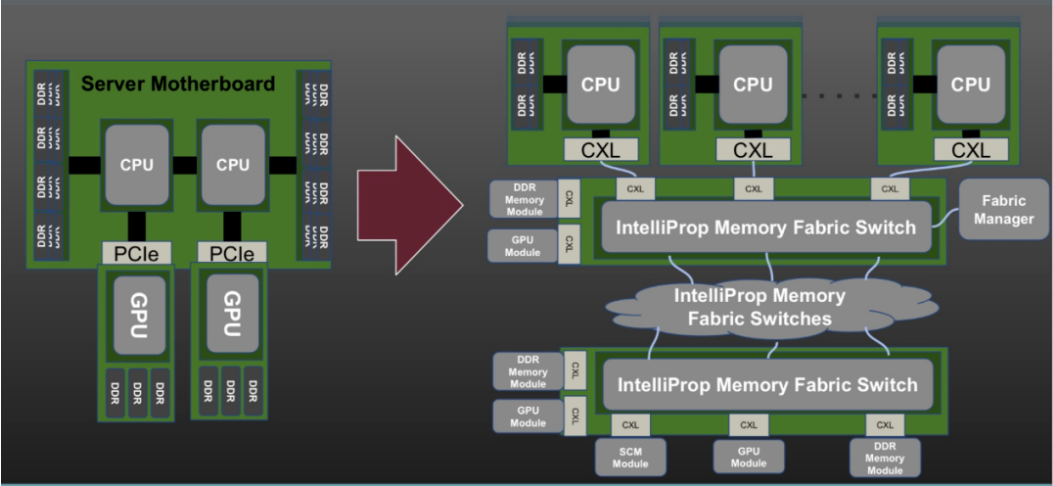
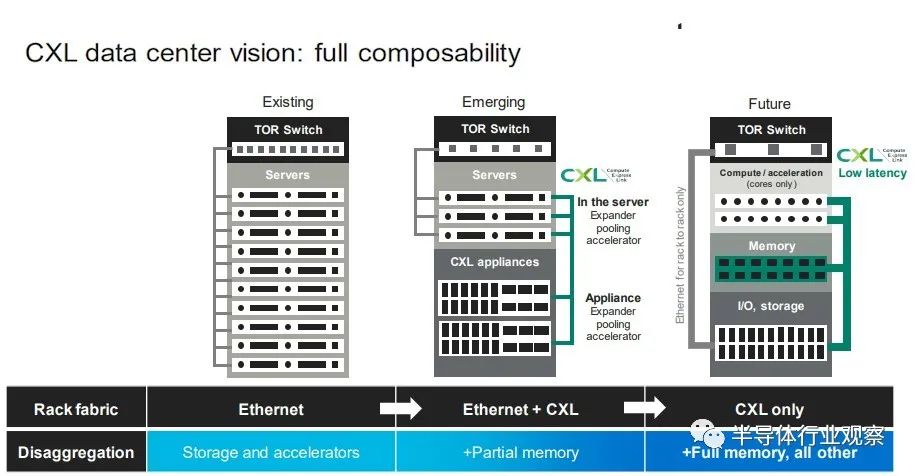
CXL是连接各种处理器的统一接口标准,例如中央处理单元(CPU)、图形处理单元(GPU)和存储设备。据市场情报公司 Yole Intelligence 称,全球 CXL 市场预计到 2028 年将增长至 150 亿美元。
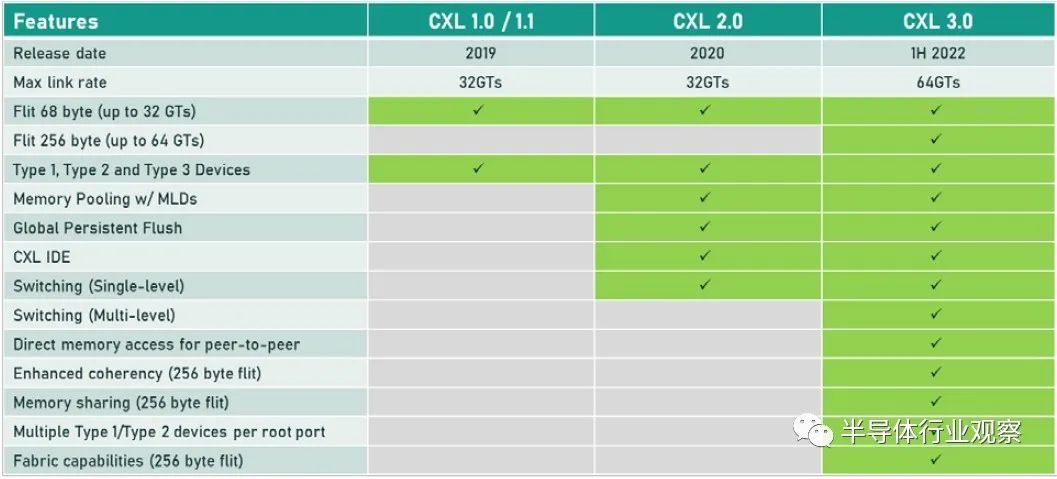
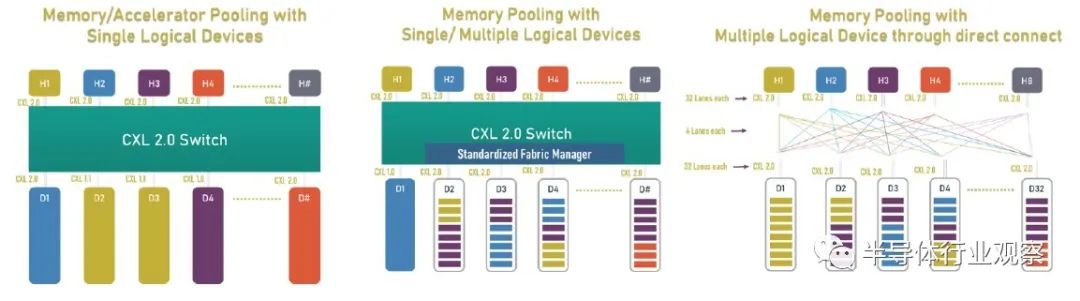
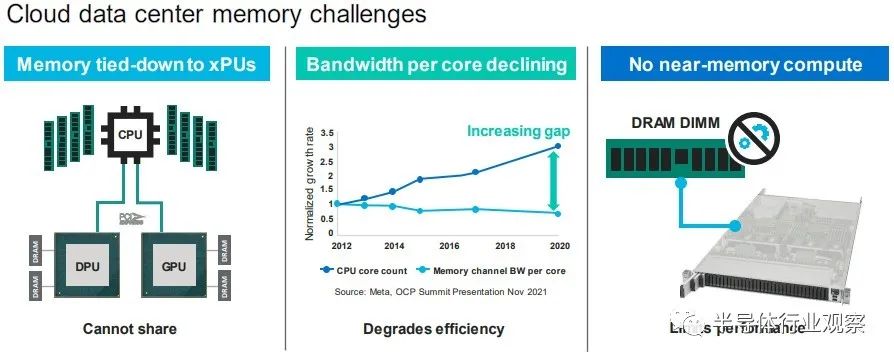
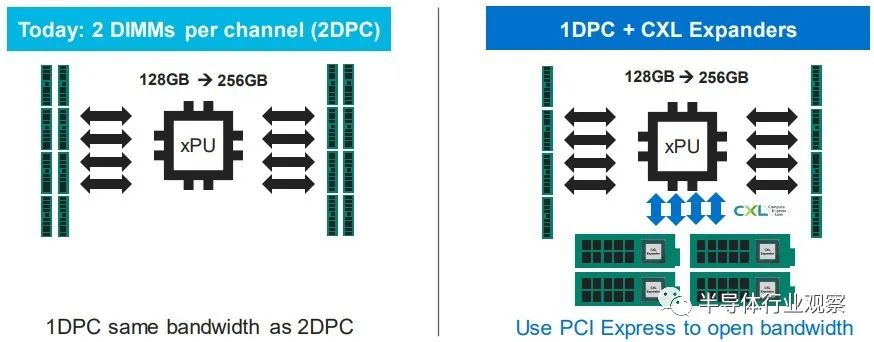
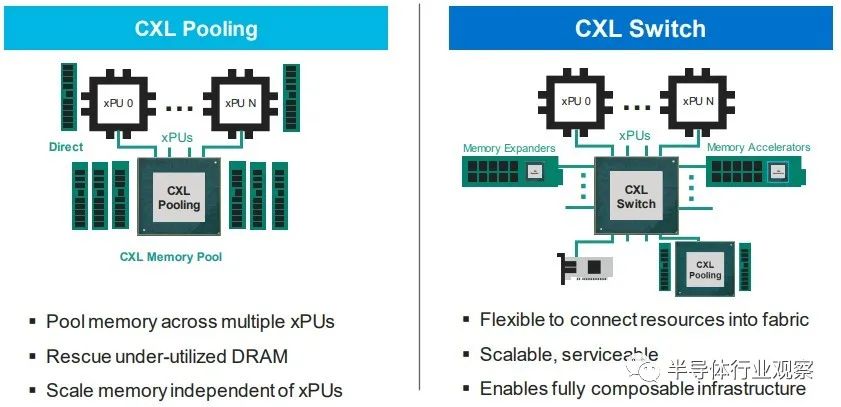
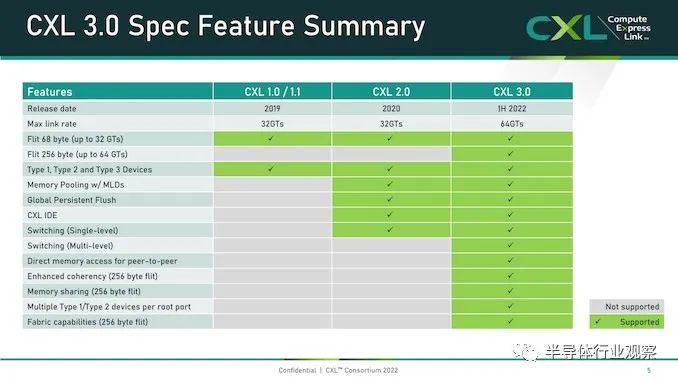
Hotchips 34 Intel CPU处理器合集2、CXL-Forum_CXL-Consortium.pdf3、CXL-Forum_Elastics_cloud.pdf 目前,即将出现的是在 PCI-Express 6.0 传输之上运行的 CXL 3.0,以下是 CXL 3.0 如何与之前的 CXL 1.0/1.1 版本和当前在 PCI-Express 之上的 CXL 2.0 版本叠加5.0 运输:当 CXL 协议在 I/O 模式下运行时——即所谓的 CXL.io——它本质上与用于 I/O 设备的 PCI-Express 外围协议相同。CXL.cache 和 CXL.memory 协议在 PCI-Express 传输之上添加缓存和内存寻址,并以 PCI-Express 协议的大约一半延迟运行。举例而言,就像我们在 2021 年 9 月与英特尔交谈时所做的那样,CXL 协议规范要求当缓存线丢失时对 snoop 命令的 snoop 响应必须低于 50 纳秒(引脚到引脚),而对于内存读取(引脚到引脚),延迟必须低于 80 纳秒。相比之下,在典型的 X86 服务器中,本地 DDR4 内存访问 CPU 插槽大约需要 80 纳秒,而 NUMA 访问相邻 CPU 插槽中的远程内存大约需要 135 纳秒。通过在 PCI-Express 6.0 传输之上运行 CXL 3.0 协议,所有三种类型的驱动程序的带宽都增加了一倍,而延迟没有任何增加。由于 256 字节流控制单元或 flit 固定数据包大小(大于 PCI-Express 5.0 传输中使用的 64 字节数据包),带宽增加到 256 GB/秒 x16 通道(包括两个方向) ) 和 PAM-4 脉冲幅度调制编码,可将 PCI-Express 传输上的每个信号的比特数加倍。PCI-Express 协议结合使用循环冗余校验 (CRC:cyclic redundancy check) 和三向前向纠错 (FEC :three-way forward error correction) 算法来保护通过线路传输的数据,这是一种比以前的 PCI-Express 协议更好的方法因此为什么选择 PCI-Express 6.0 和 CXL 3。CXL 3.0 协议确实具有低延迟 CRC 算法,该算法将 256 B flit 分成 128 B 半 flit,并在这些子 flit 上进行 CRC 检查和传输,这可以将传输延迟减少 2 纳秒到 5 纳秒之间。CXL 3.0 带来的新功能是内存共享,这与 CXL 2.0 提供的内存池不同。这是内存池的样子:借助内存池,您可以在带有 CPU 的主机和带有自己内存的加速器的机箱之间使用 CXL 的 PCI-Express 交换机,或者只是原始内存块(有或没有结构管理器),然后分配加速器(及其内存) 或根据需要分配给主机的内存容量。如上图右侧所示,如果您想硬编码 PCI-Express 拓扑以供它们链接,您也可以在所有主机和所有加速器或内存设备之间进行点对点互连,而无需交换机。使用 CXL 3.0 内存共享,设备上的内存可以同时与多个主机同时共享。下图显示了 CXL 3.0 启用的设备共享内存和共享区域的一致副本的组合:系统和集群设计人员将能够将内存池和内存共享技术与 CXL 3.0 混合和匹配。CXL 3.0 也将允许多层交换机,这在 CXL 2.0 中是不可能的,因此您可以想象具有各种拓扑和层的 PCI-Express 网络能够将各种设备和存储器捆绑到交换机结构中。在超大规模和云构建者中常见的 Spine/Leaf 网络是可能的,包括仅共享其缓存的设备、仅共享其内存的设备以及共享其缓存和内存的设备。(即 CXL 设备命名法中的Type 1、Type 3 和Type 2。)CXL 结构将是真正有用的,并且在 3.0 规范中启用。使用结构,您可以获得支持 CXL 的设备的软件定义的动态网络,而不是使用链接特定 CXL 设备的特定拓扑设置的静态网络。以下是在 CXL 2.0 中无法实现的结构中实现的非树拓扑的简单示例:这是整洁的一点。CXL 3.0 结构可以扩展到 4,096 个 CXL 设备。现在,问问自己这个问题:世界上有多少大型iron NUMA系统和 HPC 或 AI 超级计算机拥有超过 4,096 台设备?没有你想的那么多。因此,正如我们多年来一直在说的那样,对于特定类别的集群系统,无论节点在其内存中是松散耦合还是紧密耦合,运行 CXL 的 PCI-Express 结构几乎就是它们联网所需的全部。以太网或 InfiniBand 将仅用于与外界对话。我们也希望看到 DRAM 前端的闪存设备作为存储集群下的硬件作为快速缓存。(傲腾 3D XPoint 持久内存不再是一个选项. 但对于某种形式的 PCM 存储器或另一种形式的 ReRAM,总是有希望的。)当我们坐在这里思考所有这些时,我们不禁思考内存共享如何简化 HPC 和 AI 应用程序的编程,特别是如果共享内存中有足够的计算来对数据进行一些集体操作处理,这就有各种有趣的可能性。.无论如何, CXL 结构将会很有趣,它将成为许多系统架构的核心。诀窍在于共享内存以降低 DRAM 的有效成本——微软 Azure的研究表明,在其云上,内存容量利用率平均仅为 40% 左右,而运行的虚拟机中有一半从未触及超过一半从底层硬件分配给他们的管理程序的内存——通过 CXL 切换和具有内存的设备和作为内存的设备的可组合性带来的灵活性。我们想要的,也是我们一直想要的,是以内存为中心的系统架构,它允许各种计算引擎在内存中共享被操作的数据,并尽可能少地移动这些数据。至少在理论上,这是提高系统能效的途径。几年之内,我们将在实践中对这一切进行测试,这确实令人兴奋。我们现在需要的只是两年前的 PCI-Express 7.0,我们可以享受一些真正的乐趣。超大规模制造商和云构建者在其 X86 服务器中投入的最昂贵的组件是什么?它是 GPU 加速器,正确。因此,让我们以另一种方式问这个问题:在构成其大部分服务器机群的更通用、非加速服务器中,最昂贵的组件是什么?存储。如果你计算一下随着时间推移的成本,大约十年前,CPU 曾经占数据中心基础设施工作负载基本服务器成本的一半左右;HPC 系统在内核上的强度更高,在内存上的强度更低。内存约占系统成本的 15%,主板约占 10%,本地存储(即磁盘驱动器)约占 5% 到 10%,具体取决于您想要该磁盘的容量或速度。其余部分由电源、网络接口和机箱组成,在很多情况下,网络接口已经在主板上,因此除了公司想要更快的以太网或 InfiniBand 接口的情况外,成本已经捆绑在一起。随着时间的推移,闪存被添加到系统中,服务器的主内存成本飙升至顶峰(但相对于其他组件的价格有所下降),随着 AMD 的重新进入,X86 CPU 又回到了竞争。因此,通用服务器的服务器成本饼中的相对切片大小在这里和那里扩大和缩小。根据配置,CPU 和主内存各占系统成本的三分之一左右,而如今,内存通常比 CPU 更昂贵。对于超大规模和云建设者来说,内存绝对是最昂贵的项目,因为 X86 CPU 上的竞争更加激烈,从而降低了成本。有趣的是:据英特尔称,CPU 仍占 IT 设备功耗预算的 32% 左右,内存仅消耗 14%,外围设备成本约为 20%,主板约为 10%,磁盘驱动器约为 5%。(我们推测,闪存是功耗预算派的外围部分)。包括计算、存储和网络在内的IT 设备消耗的功耗不到一半,而电源调节、照明、安全系统和其他方面数据中心设施消耗了一半多一点,这给出了相当可怜的 1.8 的电源使用效率。典型的超大规模和云构建者数据中心的 PUE 约为 1.2。可以这么说,内存是一个很大的成本因素,并且由于许多应用程序受到内存带宽和内存容量的限制,将主内存与 CPU 以及实际上任何计算引擎分离,是我们所写的可组合数据中心的一部分很多在下一个平台。原因很简单:我们希望来自芯片的 I/O 也是可配置的,这意味着,从长远来看,融合内存控制器和 PCI-Express 控制器,或者提出通用传输和控制器它可以根据插入端口的内容说出 I/O 或内存语义。IBM在 Power10 处理器上使用其 OpenCAPI 内存接口完成了后者,但我们认为随着时间的推移英特尔和其他公司将使用在 PCI-Express 传输之上运行的 CXL 协议执行前者。芯片制造商 Marvell 不再试图将其 ThunderX 系列 Arm 服务器 CPU 销售到数据中心,但仍希望参与 CXL 内存游戏。为此,早在 5 月初,它就收购了一家名为 Tanzanite Silicon Solutions 的初创公司,用于其智能逻辑接口连接器,这是 CPU 和内存之间的 CXL 桥,将帮助打散服务器,并将其重新组合在一起方式——自下一个平台建立之前我们就一直在谈论的事情。Tanzanite 成立于 2020 年,去年展示了第一个使用 FPGA 的服务器 CXL 内存池,因为它正在对其 SLIC 芯片进行最后润色。“今天,内存必须通过内存控制器连接到 CPU、GPU、DPU,”Marvell 闪存业务部副总裁 Thad Omura 告诉The Next Platform。“这有两个问题。一是非常昂贵的内存要么未被充分利用,要么更糟糕的是,未被使用。在某些情况下,还有更多的未充分利用,而不仅仅是内存。如果您需要更多内存来处理大型工作负载,有时您会在系统中添加另一个 CPU 以提高内存容量和带宽,但该 CPU 也可能未得到充分利用。这实际上是第二个问题:这种基础设施无法扩展。如果不添加更多 CPU,就无法向系统添加更多内存。所以问题是这样的:你如何让内存成为可共享和可扩展的?”正如 Omura 在上表中指出的那样,另一个问题是 CPU 上的内核数量比内存带宽增长得更快,因此内核的性能与为其供电的 DIMM 之间的差距越来越大,正如上面的 Meta Platforms 数据所示. 最后,除了一些科学项目之外,没有办法聚合内存并将计算移近它以便可以就地处理,这限制了系统的整体性能。来自 Hewlett Packard Enterprise 的Gen Z 、来自 IBM 的 OpenCAPI 以及来自 Xilinx 和 Arm 阵型的 CCIX 都是融合内存和 I/O 传输的竞争者,但从长远来看,显然英特尔的 CXL 已成为每个人都将支持的标准,且他已经获得了Gen Z和OpenCAPI 的支持。“CXL 获得了很大的吸引力,并且基本上与所有主要的超大规模厂商合作,帮助他们弄清楚如何部署这项技术,”Omura 说。因此,对Tanzanite的收购(其价值未披露)于 5 月底完成。借助 SLIC 芯片,Marvell 将能够通过 CXL 扩展控制器以及比 DIMM 尺寸更大的更胖更高的扩展内存模块,帮助行业创建标准 DIMM 尺寸。(IBM 已经用它的几代 Power Systems 服务器和他们自己开发的“Centaur”:缓冲内存控制器完成了后者。)Omura 说,CXL 内存要做的第一件事就是打开现代处理器上 DRAM 和 PCI-Express 控制器的内存带宽,我们同意这个观点。如果您现在有一个系统并且您在其内存插槽中设置了带宽,您可以通过为每个内存通道添加两个 DIMM 来增加容量,但是每个 DIMM 获得一半的内存带宽。但是随着使用 SLIC 芯片向系统添加 CXL 内存 DIMM,您可以使用大部分 PCI-Express 总线为系统添加更多内存通道。诚然,来自 PCI-Express 5.0 插槽的带宽没有芯片上的 DRAM 控制器那么高,延迟也没有那么低,但它可以工作。在某些时候,当 PCI-Express 6.0 推出时,某些类别的处理器可能不需要 DDR5 或 DDR6 内存控制器,DDR 控制器可能会变成奇特的部件,就像 HBM 堆叠内存是奇特的并且只用于特殊的用例。希望 CXL 内存超过 PCI-Express 5.0 和 6。0 不会比通过 NUMA 链接到多插槽系统中的相邻插槽更糟糕(如果有的话),而且一旦 CXL 端口实际上是系统和 DDR 上的主内存端口,它可能更不麻烦和 HBM 是专用的、奇异的内存,仅在必要时使用。至少这是我们认为可能发生的事情。CXL 内存扩展只是这一演变的第一阶段。不久之后,像 Marvell 的 SLIC 之类的 CXL 芯片将被用于创建跨多种(通常是不兼容的)计算引擎的共享内存池,甚至更进一步,我们可以期待 CXL 交换基础设施创建一个不同类型的存储设备和不同类型的计算引擎之间的可组合结构。像这样:在 Marvell 的完整愿景中,有时 XPU 上会有一些本地内存——X 是指定 CPU、GPU、DPU 等的变体——而 PCI-Express 上的 CXL ink将连接到内存模块它已在其上集成计算以执行专门的功能——您可以打赌,Marvell 希望使用其定制处理器设计团队来帮助超大规模、云构建者和其他任何拥有合理容量的人将计算放在内存上并将其链接到 XPU。Marvell 显然也热衷于使用它通过 Tanzanite 收购获得的 CXL 控制器来创建具有原生 CXL 功能和可组合性的 SmartNIC 和 DPU。然后,几年后,正如我们多次谈到的那样,我们将在数据中心机架内获得真正的可组合性,而不仅仅是 GPU 和通过 PCI-Express 工作的闪存。但跨越各种计算、内存和存储。Marvell 已经拥有数据中心服务器和机架架构所需的计算(Octeon NPU 和定制的 ThunderX3 处理器)、DPU 和 SmartNIC、电光、重定时器和 SSD 控制器,现在 Tanzanite 为其提供了一种供应方式CXL 扩展器、CXL 光纤交换机和其他芯片共同构成了 Omura 所说的“数十亿美元”的机会。这是 Tanzanite 被创造出来追逐的机会,以下是它在 Marvell 交易之前设想的原型用例:我们认为,只要 DRAM 内存的价格稍微下降一点,上述这些机器中的每一台都会卖得很好。内存还是太贵了。虽然在技术上仍然是新事物,但用于主机到设备连接的 Compute Express Link (CXL) 标准已迅速在服务器市场占据一席之地。据报道,该标准旨在提供建立在现有 PCI-Express 标准之上更丰富的 I/O 功能集,其最显著的是优势在于设备之间的缓存一致性。从相关组织处获悉,CXL的主要应用方向是把CPU连接到服务器中的加速器,但希望能够在物理上仍然是通过 PCIe 接口上连接 DRAM 和非易失性存储。这是一个雄心勃勃但得到广泛支持的路线图,在短短三年内使,CXL 便成为事实上的先进设备互连标准,这就导致竞争对手标准 Gen-Z、CCIX 以及截至昨天的 OpenCAPI 都退出了竞争。虽然 CXL 联盟在赢得互连战争后快速取得胜利,但联盟及其成员还有很多工作要做。假如在产品方面,第一批带有 CXL 的 x86 CPU 几乎没有出货——这很大程度上取决于你所说的英特尔 Sapphire Ridge 芯片所处的边缘状态。来到功能方面,设备供应商要求获得比比 CXL 的原始 1.x 版本更多的带宽和更多的功能。赢得互连战争使 CXL 成为互连之王,但在此过程中,这意味着 CXL 需要能够解决竞争对手标准设计的一些更复杂的用例。为此,在本周的 2022 年闪存峰会上,CXL 联盟在展会上宣布了 CXL 标准的下一个完整版本 CXL 3.0。这是继2020 年底发布 2.0 标准并引入了内存池和 CXL 开关等功能之后的一次重要更新。报道指出,CXL 3.0 侧重于互连的几个关键领域的重大改进。第一个是物理方面,CXL 将其每通道吞吐量翻了一番,达到 64 GT/秒。同时,在逻辑方面,CXL 3.0 大大扩展了标准的逻辑能力,允许复杂的连接拓扑和结构,以及在一组 CXL 设备内更灵活的内存共享和内存访问模式。CXL 3.0:建立在 PCI-Express 6.0 之上
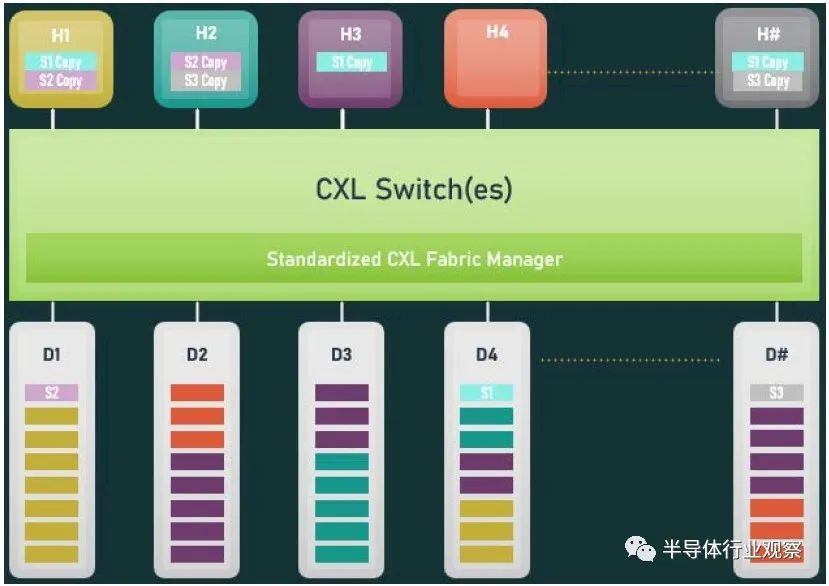
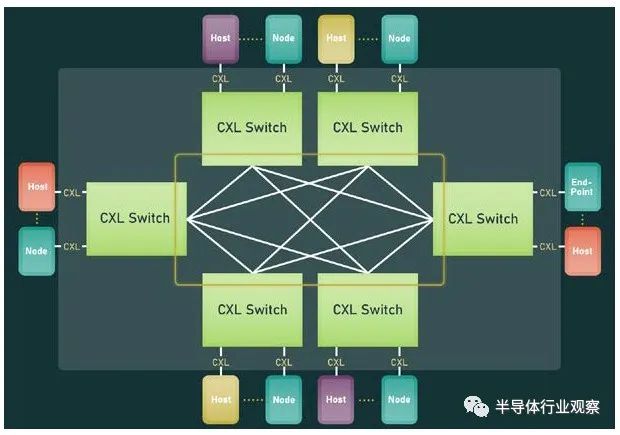
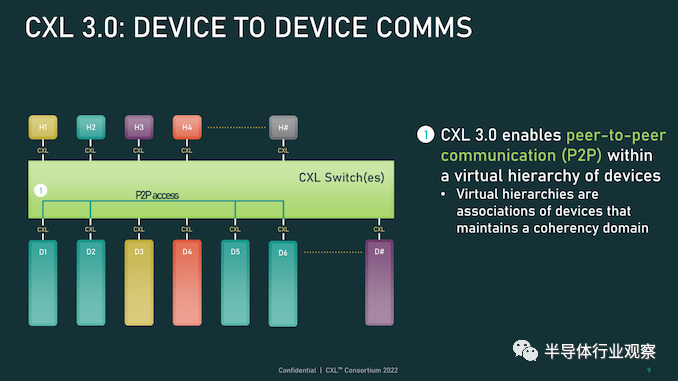
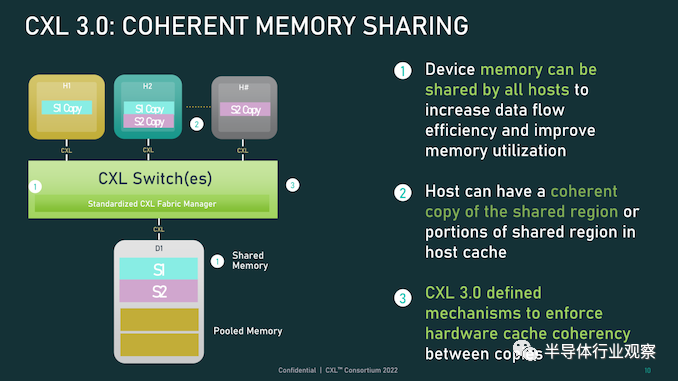
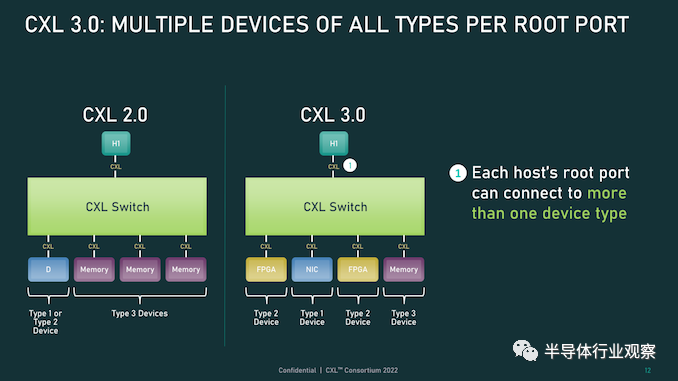
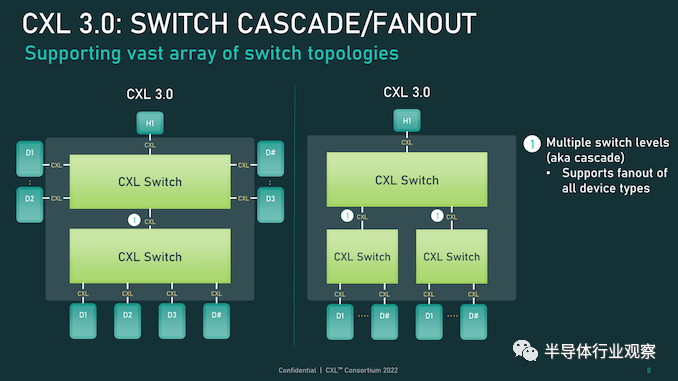
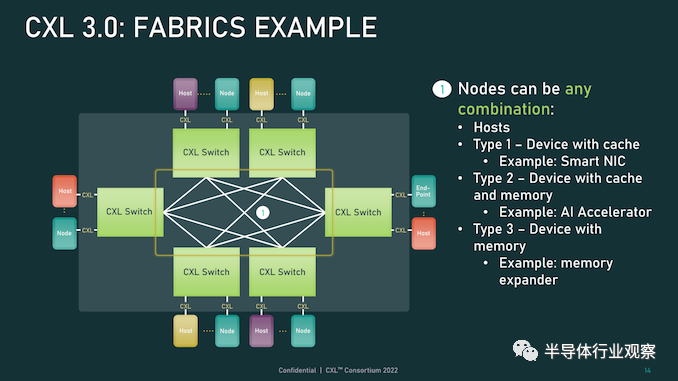
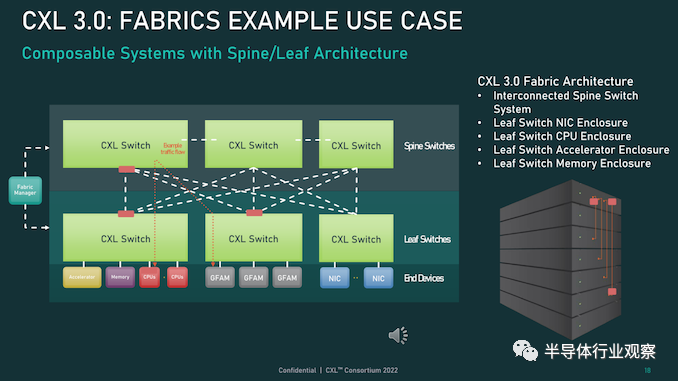
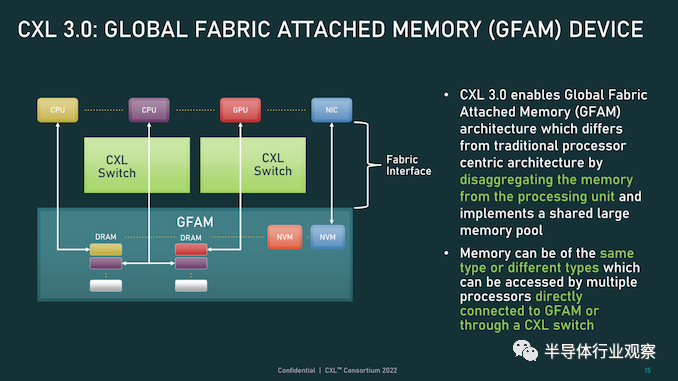
首先,我们从物理方面开始了解新版本的CXL 技术。资料显示,新版本的标准提供了期待已久的更新,以合并 PCIe 6.0。CXL 之前的两个版本,也就是 1.x 和 2.0,都是建立在 PCIe 5.0 之上的,所以这是自 2019 年 CXL 推出以来,其物理层的首次更新。PCIe 6.0本身是对 PCI-Express 标准内部工作的重大更新,它再次将总线上的可用带宽量翻了一番,达到 64 GT/秒,对于 x16 卡来说,这可以达到 128GB/秒。据报道,这个速度是通过将 PCIe 从使用二进制 (NRZ) 信号转换为四态 (PAM4) 信号并结合固定数据包 (FLIT) 接口来实现的。借助这种方法,能使其速度翻倍而不会在更高频率下运行的缺点。由于 CXL 反过来构建在 PCIe 之上,这意味着需要更新标准以应对 PCIe 的操作变化。CXL 3.0 的最终结果是它继承了 PCIe 6.0 的全部带宽改进——以及前向纠错 (FEC) 等所有有趣的东西——与 CXL 2.0 相比,CXL 的总带宽增加了一倍。值得注意的是,根据 CXL 联盟的说法,他们能够在不增加延迟的情况下完成所有这些工作。这是 PCI-SIG 在设计 PCIe 6.0 时面临的挑战之一,因为必要的纠错会增加进程的延迟,导致 PCI-SIG 使用低延迟形式的 FEC。尽管如此,CXL 3.0 在尝试减少延迟方面更进了一步,导致 3.0 具有与 CXL 1.x/2.0 相同的延迟。除了基本的 PCIe .60 更新之外,CXL 联盟还调整了他们的 FLIT size。CXL 1.x/2.0 使用了一个相对较小的 68 字节数据包,而 CXL 3.0 将其增加到了 256 字节。更大的 FLIT size是 CXL 3.0 的关键通信变化之一,因为它在header FLIT 中为标准提供了更多位,而这些位又是启用 3.0 标准引入的复杂拓扑和结构所必需的。尽管作为一项附加功能,CXL 3.0 还提供了一种低延迟“变体”FLIT 模式,该模式将 CRC 分解为 128 字节“sub-FLIT granular transfers”,旨在减轻物理层中的存储和转发开销.值得注意的是,256 字节的 FLIT 大小使 CXL 3.0 与 PCIe 6.0 保持一致,后者本身使用 256 字节的 FLIT。和它的底层物理层一样,CXL 不仅支持在新的 64 GT/秒传输速率下使用大型 FLIT,而且还支持 32、16 和 8 GT/秒,本质上允许新协议功能以更慢的传输速率使用.最后,CXL 3.0 完全向后兼容早期版本的 CXL。因此,设备和主机可以根据需要降级以匹配硬件链的其余部分,尽管在此过程中会失去更新的功能和速度。CXL 3.0 特性:增强的一致性、内存共享、多级拓扑和结构除了进一步提高整体 I/O 带宽外,上述针对 CXL 的协议更改也已实施,以支持标准内的新功能。CXL 1.x 是作为(相对)简单的主机到设备标准而诞生的,但现在 CXL 是服务器的主要设备互连协议,它需要扩展其功能以适应更高级的设备,并最终适应更大的用例。从特性级别开始,这里最大的新闻是该标准更新了具有内存的设备的缓存一致性协议(Type-2 和 Type-3,用 CXL 的说法)。正如 CXL 所说,增强的一致性允许设备支持使主机缓存的数据无效。这取代了 CXL 早期版本中使用的基于偏差的一致性方法,为了保持简洁,保持一致性不是通过共享内存空间的控制,而是通过让主机或设备负责控制访问。相比之下,Back invalidation更接近真正的共享/对称方法,允许 CXL 设备在设备进行更改时通知主机。包含Back invalidation也为设备之间的新对等连接打开了大门。在 CXL 3.0 中,设备现在可以直接访问彼此的内存,而无需通过主机,使用增强的一致性语义来通知彼此它们的状态。从延迟的角度来看,跳过主机不仅速度更快,而且在涉及交换机的设置中,这意味着设备不会通过请求占用宝贵的主机到交换机带宽。虽然我们稍后会进入拓扑,但这些变化与更大的拓扑密切相关,允许将设备组织成虚拟层次结构,其中层次结构中的所有设备共享一个一致性域。除了调整缓存功能外,CXL 3.0 还对主机和设备之间的内存共享进行了一些重要更新。CXL 2.0 提供了内存池,其中多个主机可以访问设备的内存,但必须为每个主机分配自己的专用内存段,而 CXL 3.0 引入了真正的内存共享。利用新的增强一致性语义,多个主机可以拥有一个共享段的一致副本,如果设备级别发生变化,可以使用反向失效来保持所有主机同步。然而,应该注意的是,这并不能完全取代池化。在某些用例中,CXL 2.0 风格的池更可取(保持一致性需要权衡取舍),并且 CXL 3.0 支持根据需要混合和匹配这两种模式。CXL 3.0 进一步增强了这种改进的主机设备功能,消除了之前对可以连接到单个 CXL 根端口下游的 Type-1/Type-2 设备数量的限制。CXL 2.0 只允许这些处理设备中的一个出现在根端口的下游,而 CXL 3.0 则完全解除了这些限制。现在,CXL 根端口可以支持 Type-1/2/3 设备的完全混合匹配设置,具体取决于系统构建者的目标。值得注意的是,这意味着能够将多个加速器连接到单个交换机,提高密度(每个主机更多的加速器),并使新的点对点传输功能更加有用。CXL 3.0 的另一大特性变化是支持多级切换。这建立在 CXL 2.0 的基础上,该版本引入了对 CXL 协议交换机的支持,但仅允许单个交换机驻留在主机及其设备之间。另一方面,多级交换允许多层交换机——也就是说,交换机馈入其他交换机——这极大地增加了所支持的网络拓扑的种类和复杂性。即使只有两层交换机,这也足以实现非树状拓扑结构,例如环形、网状结构和其他结构设置。并且各个节点可以是主机或设备,对类型没有任何限制。同时,对于真正奇特的设置,CXL 3.0 甚至可以支持主干/叶架构,其中流量通过顶级主干节点路由,其唯一工作是将流量进一步路由回包含实际主机的低级(叶)节点/设备。最后,所有这些新的内存和拓扑/结构功能都可以在 CXL 联盟所称的全球结构附加内存 (GFAM) 中一起使用。简而言之,GFAM 通过进一步分解来自给定主机的内存,将 CXL 的内存扩展板(Type-3)理念提升到了一个新的水平。在这方面,GFAM 设备在功能上是它自己的共享内存池,主机和设备可以根据需要访问它。GFAM 设备可以同时包含易失性和非易失性存储器,例如 DRAM 和闪存。反过来,GFAM 将使 CXL 能够有效地支持大型多节点设置。正如 Consortium 在他们的一个示例中使用的那样,GFAM 允许 CXL 3.0 为在 CXL 连接的机器集群上实施 MapReduce 提供必要的性能和效率。当然,MapReduce 是一种非常流行的用于加速器的算法,因此扩展 CXL 以更好地处理集群加速器常见的工作负载是标准的下一步明显(并且可以说是必要的)。尽管它确实模糊了 CXL 等本地互连的结束位置和 InfiniBand 等网络互连的开始位置之间的界限。最终,最大的区别可能是支持的节点数量。CXL 的寻址机制,联盟称之为基于端口的路由 (PBR),最多支持 2^ 12(4096) 个设备。因此,CXL 设置只能扩展至此,尤其是当加速器、附加内存和其他设备迅速占用端口时。总结一下,完整的 CXL 3.0 标准将于今天,即 FMS 2022 的第一天向公众发布。官方上,该联盟没有提供任何关于何时期望 CXL 3.0 出现在设备中的指导——这取决于设备制造商- 但有理由说它不会马上。随着 CXL 1.1 主机刚刚交付——更不用说 CXL 2.0 主机——CXL 的实际产品化比标准落后几年,这对于这些大型行业互连标准来说是典型的。
https://www.kedglobal.com/korean-chipmakers/newsView/ked2023122700162、半导体行业系列报告(二)碳化硅:衬底产能持续扩充,渗透加速国产化 3、半导体行业系列报告(三)先进封装:先进封装大有可为,上下游产业链将受益芯片未来可期:数据中心、国产化浪潮和先进封装(精华)1、半导体行业系列报告(一):道阻且长,行则将至
2、半导体行业系列报告(二)碳化硅:衬底产能持续扩充,渗透加速国产化
3、半导体行业系列报告(三)先进封装:先进封装大有可为,上下游产业链将受益本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。