大模型作为企业转型与发展的强大动力,本次爱分析邀请行业实践专家,针对开源训练模型落地企业场景时,遇到的技术挑战、解决方式、以及演进路径的分析讲解。
分享嘉宾|郭峰 「DaoCloud 道客」联合创始人兼首席技术官
内容已做精简,如需获取专家完整版视频实录和课件,请扫码领取。

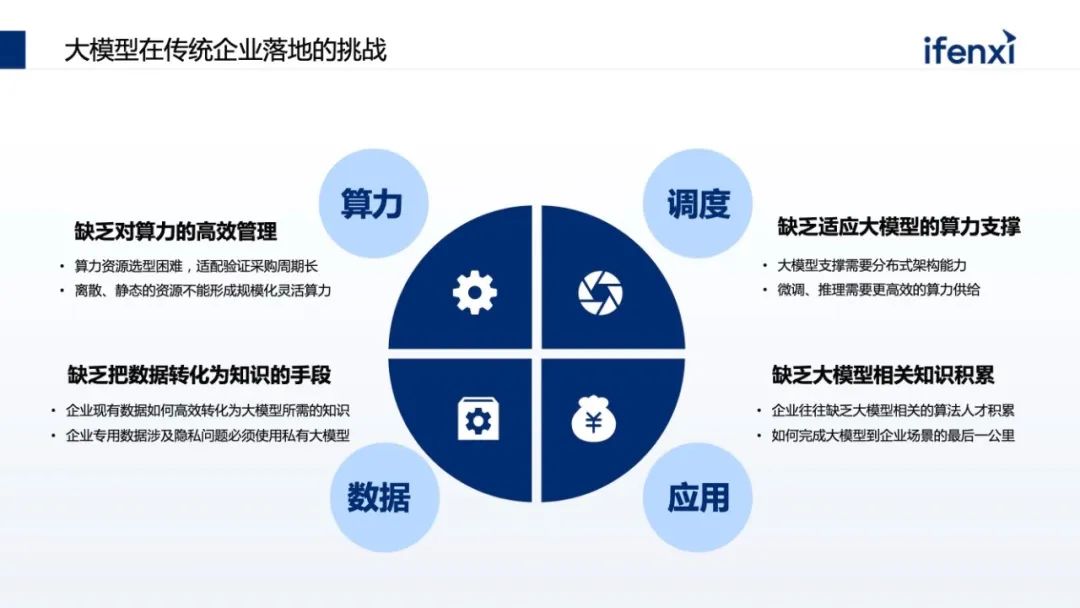
从目前来看,企业清楚大模型将引领全新的时代,是转型的全新动力。
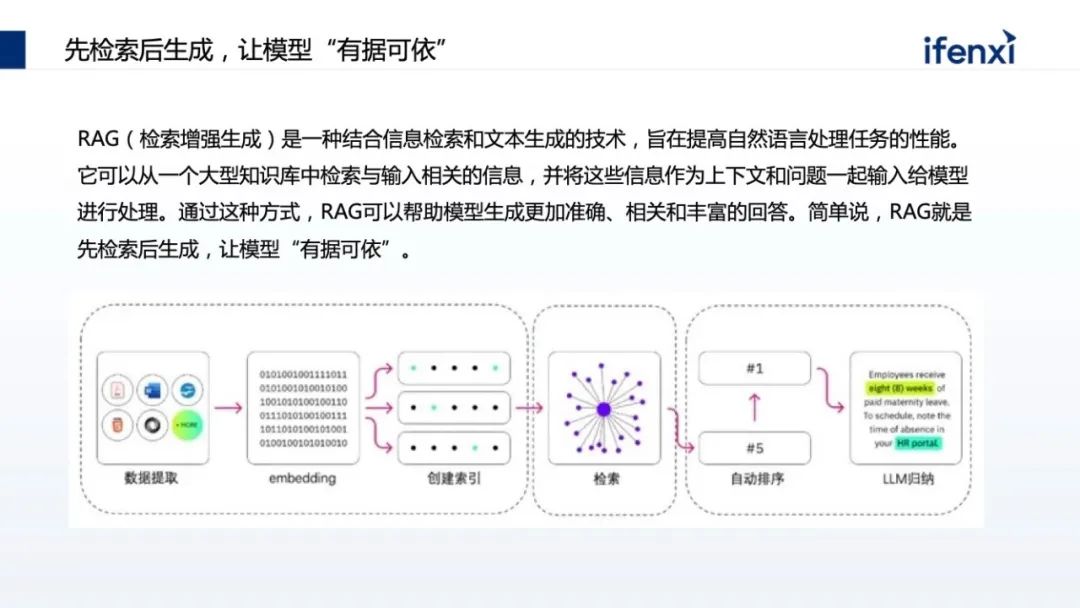
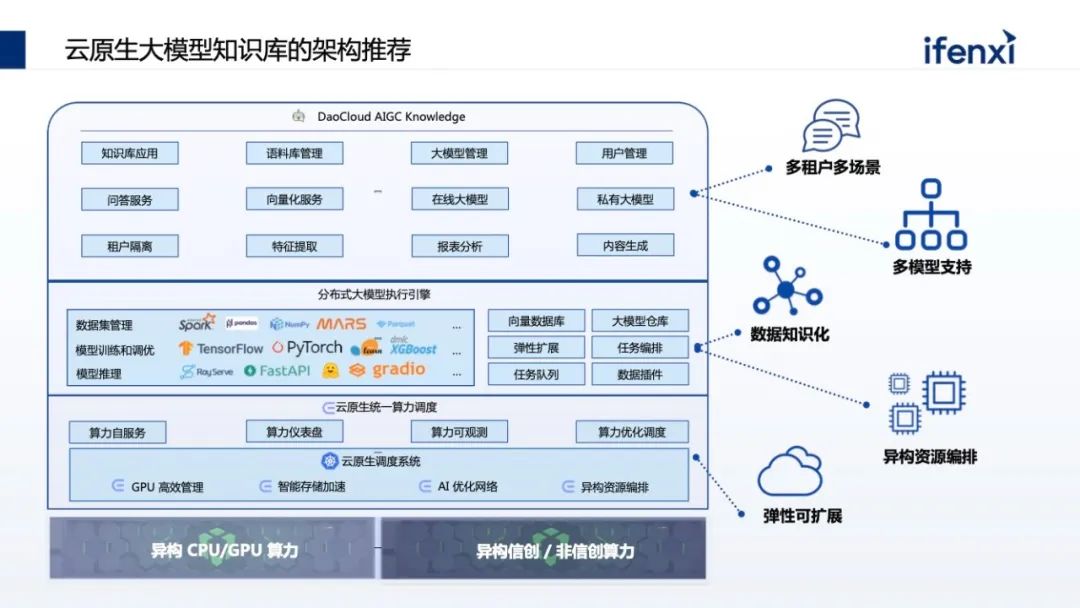
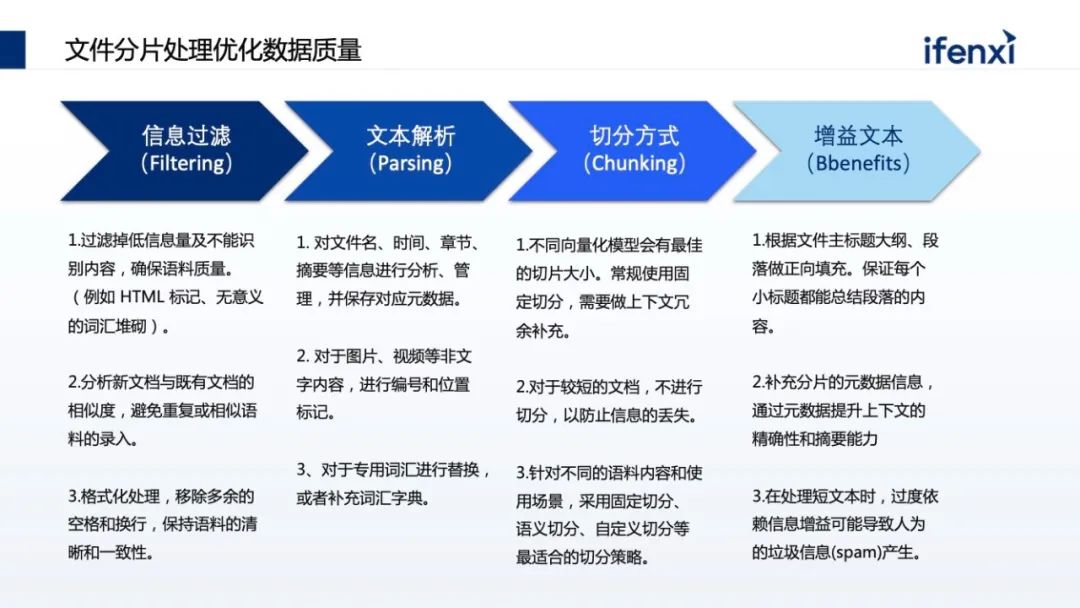
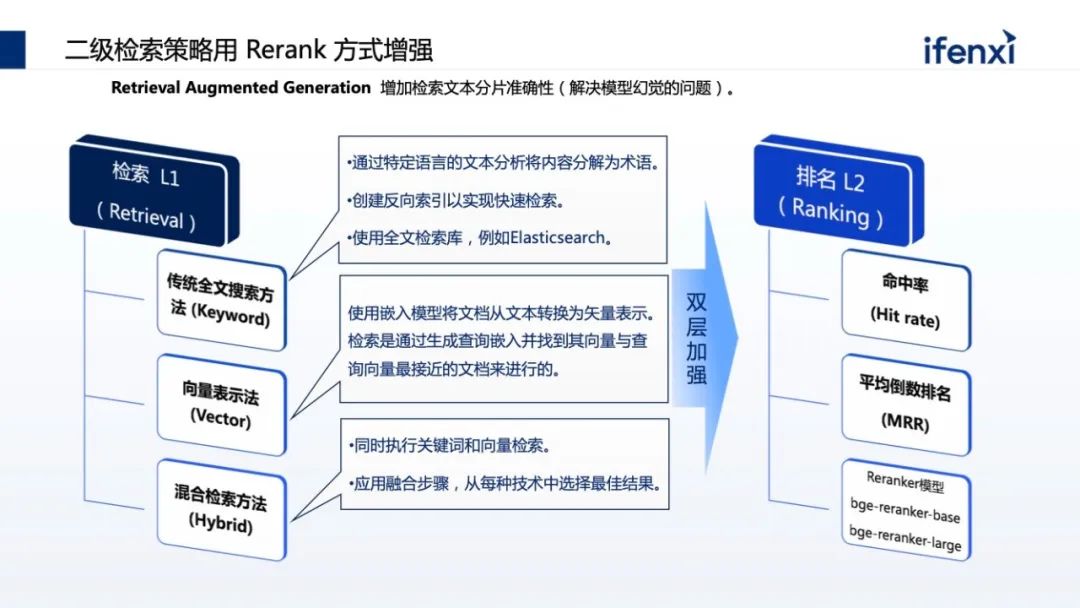
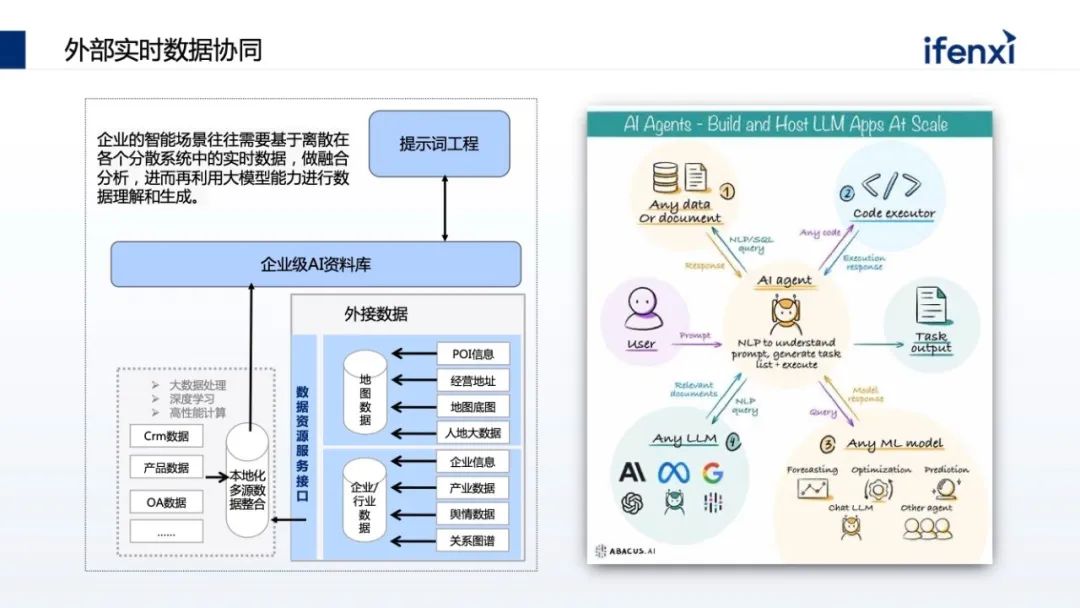
但在真正落地时,每个企业都有自己的考量,一方面企业没有GPU卡,买不到或者买到的只能是小卡。第二,企业有卡,但卡只能用于特定的项目组与业务,不能做复用,也无法更好地支撑大模型。第三,在应用方面,很多企业对大模型的认知是 OpenAI,认为因为网络或合规的问题,无法直接访问 OpenAI,不知道如何把 OpenAI 在企业落地。另外即使有 OpenAI 访问,但通用的问答不能和企业场景联动,这对企业的帮助不大,更多将它认为是 ToC 场景,和企业 ToB 场景不一样。同时,对企业来讲,企业需要懂自己的大模型,需要结合企业自己的数据、场景。在很多企业尤其传统金融机构,数据的隐私和合规非常重要,不会将数据透露到国外的 OpenAI。从以上几个方面,企业在应用大模型的时候其实都有考量。但我们发现有一些误区,一方面企业认为,大模型一定要大算力。这不一定,比如 OpenAI 花了上千万美金去处理一次,但是它的场景更多是训练或微调大模型,但在企业真正使用时,更多的是推理,这对大模型的要求不那么高,并且现在有大量、优秀的小参数量大模型,只有十亿或者上百亿的小参数量大模型,也有很好的效果。另一方面,谷歌内部有声音传出来,无论是 OpenAI 还是谷歌,在大模型时代不一定有很强的“护城河”,更有可能在大模型时代取得胜利的是开源。这个背景是在 2023 年初时 LLaMa 开源出来,很快会发现每隔一两周就有一个更好、更厉害的开源大模型基于 LLaMa 出来。包括国内,无论是清华的 GLM,还是像百川、千问这样的模型,都是开源的预训练模型,这些模型可以拿到企业内部,结合企业内部数据,就可以做出专属企业的模型。基于国内开源的训练模型,我们可以探索出,如何把开源训练模型结合企业的数据和场景去落地。一般会有两种方式,一种叫检索增强生成 (RAG)。所谓检索增强生成就是不需要对大模型进行任何微调,也不需要用它的参数。只需要在问大模型问题的时候,对企业现有数据进行检索,同时结合问题一起喂给大模型。这样在问问题的同时,也给了大模型回答所需的相关知识。对大模型来说,只要能够理解问题、把问题以及答案进行组装,就是一个满足企业应用的大模型。第二种路会更难些,目前企业不会对大模型进行全参数微调,更多是在 Data 及补充参数上做微调,让大模型真正懂企业的数据。这也带来了更高的落地门槛,无论是算力还是算法的要求。今天讨论为什么落地大模型时企业要从知识库开始,因为知识库是 RAG 模式最好的应用场景,利用 RAG 能够很好地让大模型补充原本没有的企业知识,却又在算力和算法上没有特别高的门槛。RAG 其实在大模型之前就已经出现,它的核心能力是先汇集企业知识,再做索引。在提问时,根据问题在企业知识里找最相关的数据,进行有效排序,结果体现哪些最相关、哪些次相关,把一部分数据交给大模型,这是一个非常典型的让大模型有据可依的回答过程。在实际落地时会更复杂,我们根据以往过程中的实践经验,总结了一套能够帮助企业快速落地的 RAG 体系的推荐架构。架构分为三层,最下面一层是算力调度层,把企业现有的例如 CPU 资源、GPU 资源、NV的卡,或者昇腾优秀的国产 GPU 卡,都管理和调度编排起来。中间是大模型的执行层,做 RAG 整体的流程,以及如何将大模型的推理与 RAG 流程结合起来。这个过程将企业现有数据变成大模型可认识的知识,进而跑通知识库的整个 RAG 流程。再往上是面向知识库场景建设,知识库看上去是统称的场景,但在企业落地时会有不同的使用场景。企业会有合规场景、运维管理、客服支持等,不同的场景在业务上也有不同。另外多租户的管理也是必然的,在不同场景里边,由于数据合规性,会涉及到不同租户数据的可见性,数据合规的检查以及租户的隔离。最后一块,尤其是私有化大模型都带有特殊性。比如我们常用的大模型,像百川、GLM、千问,每种大模型都有自己的特色。比如有些大模型在总结场景上比较有优势,但在分析和填空场景上,则是另外一些大模型更突出,所以需要针对不同场景的需求,找到最合适的大模型匹配。这其中也和并发相关,比如参数量特别大的,并发有可能会下降,因为参数量大势必会导致对显存和计算量的要求。在 RAG 过程中,第一件事是如何把数据变成知识,也叫数据或文本的分片。我们要把不同的文档,比如 PDS、word,把它做成一个个数据分片保存下来,作为搜索依据或最小的搜索单元。分片有很多优化点需要注意,一个分片分为 4 个步骤。第一是信息过滤阶段,将无效信息摘出。比如上传的 HT 文件,有些 HTML 标识要去掉,比如有些文件有大量空格回车、高度重叠的部分,上传了 5 份大体一样的文件,会发现搜索出回答知识的范围会减小,重复的文件会增加特定文件分片的优先级,导致需要更多范围去填充内容,无法搜索。第二块文本解析,文本解析会把文件常用的基础知识对应到源数据上。比如要总结同一个文件的不同分片,把它变为元信息存储下来。同时大模型擅长处理的是文本数据,当文档里带图片、视频时需要做预处理,处理后再传给大模型。以及有些专业的词汇大模型不一定知道,需要做简称的补充或者替换。第三是切分方式。大模型置换值过程会涉及到一个计算模型-- Embedding 模型,Embedding 通过把文件分片和问题进行向量化,计算之后找出和问题相关的文本,然后将文本整合作为提示词输送到大模型。Embedding 模型的选择会影响分片的大小。一般常用的是固定化分片,比如 Embedding 模型支持 512 或 1624,可以固定地去分片,但分片要留一定尺寸用作留上下文冗余补充。因此在做分片时,需要在这个分片上、下都要做补充,不至于将每个分片变成孤立的分片处理。其中包含更高级的,比如除了固定分片也做语义分片,也就是在特定一些语料,比如法律的语料,每一个法条就是一个适合的切片单元,这时就用法条去切。甚至有些语料是自定义的,比如 Markdown 格式有明显结构,通过结构划分切片。最后一点是针对切片做增益。比如分析了企业过去十年的年报,如果只做分片,可能只看到某一年报里的分片,损失了分片中来自于哪个公司、哪年的信息。这些信息其实可以作为元信息叠加到分片上,搜索会更快。包括有些分片是个段落,需要把段落的目录、摘要 pending 在分片之上,让这个分片更具有上下文。第一步预处理阶段,把图片提取出来,用编号替代原来文件的位置。同时告诉大模型在做内容组织的时候,希望保留图片的编号和标识,那在回复时,会保留原始文件的图片编号。第二步可以对图片进行 OCR 的识别,把图片有意义的内容拆解出来,补充回原来图片的占位符上。占位符不仅是一个编号,同时具备了一种文档的内容,这样在大模型的理解上会更有优势。前面的分片是把企业的现有数据变成知识库的知识,怎样查询结果,这里分三个阶段渐进式的检索:第一个阶段是预处理策略,把常见的行业术语、同义词术语、简称维护到行业术语库,利用术语库在做预处理时提升检索质量或提前替换。替换有两种方式,一种是在问问题的时候在词库里做替换。另一种在向上做检索时,提前告诉这里有类似的让它理解。第二阶段是检索,分了两级,第一级是 QA 级监测。知识库是典型的问答,如果已经有了整理好的、高质量问答的语料,当客户提到新问答,又与整理过的问题高度匹配,那答案一定是最精确的。在一级缓存里要尽量命中原来积累的 QA 库。OpenAI 也用了这个方式,因为 OpenAI 背后算力太贵,看上去它会实时回答,实际上背后也积累了一级缓存 QA 库。二级检索使用综合排序。常见的二级监测里,大家往往把知识先存到向量数据库里,在向量数据库里找近似的。但有个问题,向量数据库更多是在语义的近似度或相近语义的场景找,某种程度上会丢失一些隐秘信息。过去在全文检索里做了优化,像关键词查询,这些优化能力在数据库里会丢失掉,所以使用了综合查询。从数据库里找到语义相近的,同时到权威检索库里根据关键字找出最相近的,然后去做重新排序的过程,把不同的结果,根据特定的算法重新排序。企业很多数据是离散在系统上,甚至有些需要实时数据,这会导致大模型知识库本身的语料建设出现滞后性。这需要从企业系统里找到实时数据进行组装,这里涉及 Agent 的方式。所以在讲大模型使用时,大家会使用两种方式同时叠加,一方面用 RAG 做检索内容增强,另外一方面通过 AI agent 拿到实时数据,把实时数据补充到原来的生成上。
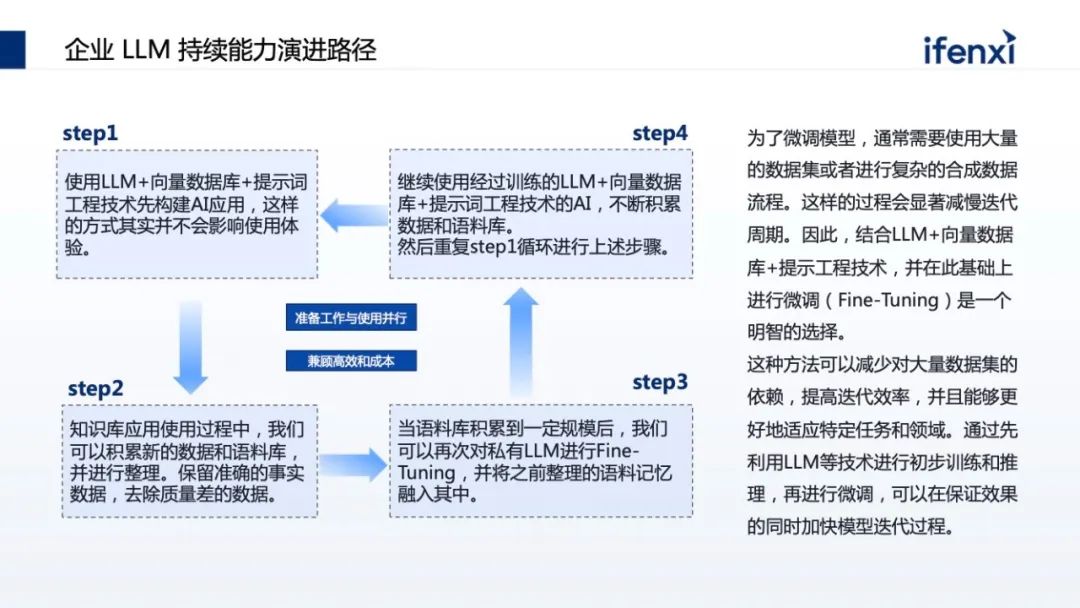
在让大模型做一件事时调哪个 API,这是筛选的过程。首先把企业现有的 API 放到向量数据库里,通过问题在向量数据库里找到最相近的 API 为候选者,再把问题以及候选者一起交给大模型,选择最合适被调用的 API,这就是通过向量数据库快速找到潜在 API,让大模型在理解问题的情况下去选定 API。基于大模型选好的 API,让大模型找到合适的参数填充,进行程序化调用。以上是在 API agent 上做的两步调用:第一步,通过向量缩小 API的范围,第二步,让大模型选择特定 API,下一步让大模型告诉什么参数是最合适的。从企业知识库找到数据,甚至从实施系统里找实施数据后,需要把数据作为上下文传给大模型,但传递过程有很多技巧,如何发问进而得到更准确的答案,这在大模型领域叫提示词工程,有几个点供大家参考。第一点是设定领域,给大模型圈定个范围。在这个领域里找更好的答案。比如让大模型回答问题时,首先告诉大模型是一个金融的合规专家,这时它知道问题在金融领域并且非常严谨。第二是明确任务。大模型擅长处理复杂问题,但也比较容易自己发挥。所以为了让大模型更好地回答高质量问题,要给它明确的任务指示。比如告诉他,一步一步地分析原因,并且基于原因提出解决方案,这时它明确知道要做的事,首先分析原因,并且基于原因总结方案,这是明确的任务。如果给到大模型不明确的任务,大模型会做不可控的发挥。第三块是限定风格。比如在客服场景里要更加平缓,在合规场景里要更加严谨。最后可以表达更直接的期望。比如限定回复的量、格式,甚至要求回复的格式。其实是一个更好的整理数据的表达,也是更精确地告诉大模型,基于上下文的问题怎样更好地分析处理给出答案。大模型知识库里还有一个非常重要的能力:反馈数据,尤其企业场景中数据是海量的。一方面会有实时性的问题。比如说今年和去年的数据,政策会有一些重叠和差异,但审理可能会忽略。在使用中不断让客户反馈问题,也可以不断提升和优化语料,使它更健康。如果语料质量越高,那回复质量也越高。语料反馈是大模型知识库里面非常重要的建设能力。前面讲的是大模型业务能力建设,但企业建设知识库时需要扎实的地基。比如 13B 的大模型,一个 A6000 的卡可能只能支撑 5- 10 个并发,但如果下放给企业,就不止这么多人同时用,甚至不同场景并发可能会更高。它一定需要底层能力随着并发和场景的扩展,要更多的算力汇聚起来,横向扩展能力需要更强。另一方分布式编排能力要更强,大模型在知识库里更多的是推理能力,比如向量化推理、大模型推理,需要更精确的分布式编排,让不同卡差分使用,包括异构 GPU 的管理。不同卡之间能够统一管理也非常重要,包括如何让卡变得更高效。这里和分布式编排有关,通过编排可以极大地提升卡的使用效率。数据表明,大量企业虽然没卡,但 GPU 的利用率不超过 30%。接下来就是网络,面向大模型场景,网络比较特别。需要将能力透传到大模型知识库里,包括需要的中间件,如何用更高效的方式支撑中间件。通过大模型知识库,企业可以低门槛落地大模型。在落地过程中大模型知识库支持数据反馈,过程中不断优化和积累企业自己的语料,积累到一定语料,基于语料结合企业的预训练模型,微调企业专用的模型,进而推动到更多的场景上。这其实就是企业落地大模型的三步骤,第一步就是去走 RAG,落地低门槛的知识库,第二步 RAG 积累数据,第三步有了数据然后去微调模型。以上就是关于云原生的大模型知识库,在落地过程中遇到的一些技术挑战和建议,希望给到大家一些参考。⩓

同济大学计算机硕士,曾就职于 EMC 全球 CTO 办公室、中国研究院,担任云计算首席架构师、主任研究员。曾深度参与 OpenStack、CloudFoundry 等分布式调度平台的早期研发与设计,对分布式系统、虚拟化和容器技术有深入研究,在相关技术领域拥有 15 项美国专利、16 项国内专利。同时也是精益研发和微服务架构在国内最早的布道者之一,并作为领域专家深度参与了多个企业的数字化转型实践。
注:点击左下角“阅读原文”,领取专家完整版实录和分享课件。