 本文来源TJ雷达成像实验室
本文来源TJ雷达成像实验室
摘要
本文演示了如何利用雷达点云和相机图像的深度学习来实现三维目标检测。用人工标记的边界框训练一个深度卷积神经网络来检测汽车。并将研究结果与在激光雷达点云和摄像机图像上训练的深度神经网络进行了比较。采用平均精度(AP)来评价性能。雷达和摄像头的AP分别为0.45、0.48和0.61,而激光雷达和摄像头的雷达和摄像头的AP分别为0.33、0.35和0.46。与雷达数据相比,该网络的性能明显优于激光雷达数据。目前,利用雷达数据和摄像机图像进行的目标检测性能的主要限制是数据集,到目前为止数据集还相当小。然而,研究结果表明,深度学习通常是一种适合于雷达数据目标检测的方法。
1 绪论
自动驾驶车辆的主要感知任务之一是检测其周围环境中的物体。功能安全使得它需要有多个互补和冗余的传感器来同时执行目标检测。目前用于先进的驾驶员辅助系统的最常用的传感器是照相机、激光雷达和雷达。
对于相机图像,深度学习已经成为二维目标检测的最新方法[1],[2],[3]。结果表明,它是一种适用于激光雷达点云[4]、[5]中三维目标检测的方法。然而,研究才刚刚开始探索将深度学习技术应用于雷达数据的可能性。最近的出版物使用深度神经网络完成以下任务:距离-多普勒图像[6]的分类,雷达网格地图[7]中目标的分类,雷达点云[8]的语义分割。
当使用卷积神经网络对范围-多普勒图像进行分类时,它不能区分一幅图像中的多个对象,也不能定位对象。朗巴赫等人[7]将网格图中的每个单元划分,这意味着他们将雷达网格划分为汽车和无车类。这提供了有关对象位置的信息,但不提供有关网格单元格所属的对象实例的信息。因此,推断目标数量和目标大小都是不可能的。
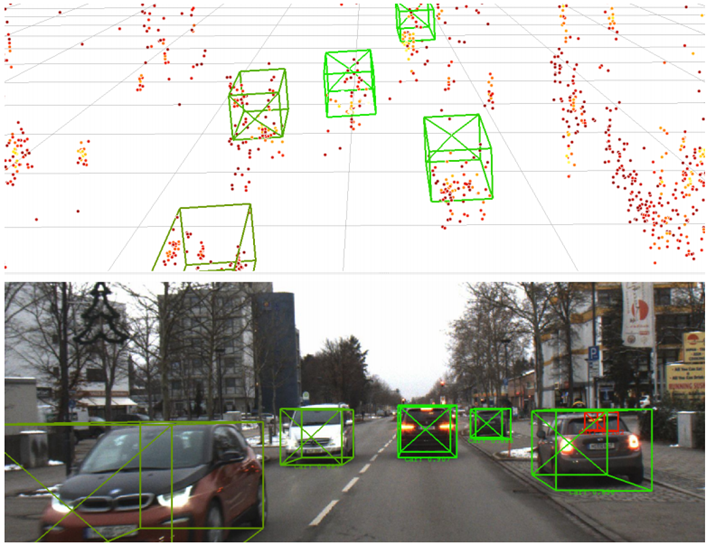
图1 对测试数据的三维检测结果的示例。这些点的颜色代表了其大小。被检测到的盒子的颜色表示被检测到的分数
许多现有的基于激光雷达和照相机的三维目标检测算法(如[9]、[10]、[11])。由于一些雷达传感器,如激光雷达传感器,输出3D点云(即使点云有完全不同的属性),人们可以对雷达和摄像机数据应用类似的网络。
同时,雷达-摄像机融合是可取的,因为传感器具有不同的特性,因此可以相互补充[12]。
直到最近,雷达传感器的输出过于稀疏,无法在原始数据水平上应用深度学习方法进行雷达-相机融合。据作者所知,目前雷达摄像机与基于深度学习的卷积神经网络(CNNs)的融合的文献较少。
本文利用深度神经网络对雷达点云和摄像机图像进行三维目标检测。该网络与Ku等人的[11]使用的网络相似。我们评估了网络的性能,并比较了雷达相机和激光雷达相机的性能。
2 方法
训练CNN基于点云和RGB图像作为输入,在三维空间中检测汽车。每个点云和图像都属于一个同步的“帧”,该数据集包含在德国南部[13]记录的公共道路。训练在数据集的一个分割上执行,评估在另一个分割上执行,这样用于训练的数据就不会用于评估。训练和评估一次雷达点云和摄像机图像,一次激光雷达点云和摄像机图像。
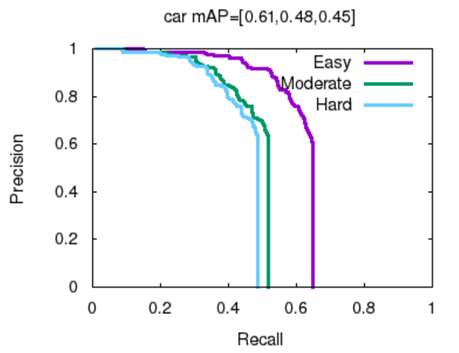
图2 测试数据集上雷达和相机的精确召回曲线
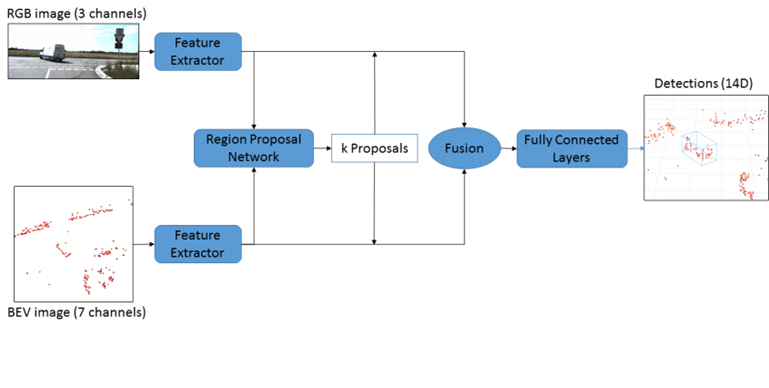
图3 网络的架构的方案。BEV图像由6个高度图和一个密度图组成。探测结果被编码为4个角和两个距离地面的高度偏移量
2.1 网络
将由N个点(x、y、z、Magnitude)和一个RGB图像组成的点云作为网络的输入,然后根据输入输出在三维空间中具有位置和维数的边界框预测。本文所使用的网络结构与[11]中描述的网络相似(见图3)。然而,与本文相比,在特征提取器中没有使用特征金字塔网络(FPN)。由于在本文中,网络只被训练来检测具有相对较大对象的类车,因此FPN就不那么相关了。
每一帧的点云用于生成具有六个高度图和一个密度图的鸟瞰视图(BEV)图像。不使用雷达数据中的多普勒信息。然后利用三维区域建议网络(基于网络VGG[14]的适应)基于雷达点云的摄像机图像和BEV图像生成建议。
这些建议用于预测通过四个角和两个高度(从地面到底部和顶部)编码的盒子。使用这种相当不直观的14维表示,因为它已经被证明可以产生最好的结果[11]。此外,一个角度被预测来确定四个角之间的哪一边属于被检测对象的前部。
2.2 数据集
为了训练和评估,使用[13]一个包含455帧同步摄像机、激光雷达和雷达数据的数据集。每个雷达点云包含大约1000 - 10000个点,使用Astyx 6455 HiRes传感器获得。每个点包含x、y、z位置、大小和多普勒信息(径向速度)。这些相机图像的大小为2048×618像素,是用点灰黑蝇相机拍摄的。激光雷达点云是用速差VLP-16获得的。
这些数据用4:1的比例被分成一个训练集和一个测试集。对于深度学习应用程序,这个数据集非常小。因此,在训练过程中使用了两种数据增强方法。第一种方法是水平翻转图像、点云和地面真相盒。第二种方法是用基于主成分分析的方法向相机图像中添加噪声,该方法被称为花式主成分分析,由克里热夫斯基在他著名的AlexNet论文[15]中介绍。
该网络经过22000次迭代的训练,学习速率为0.0001,小批量大小为16。在两台英伟达泰坦V图形处理器上的训练花了3小时24分钟。
3 结果
训练是在测试数据集上进行评估。图1中来自网络的检测结果显示了来自测试数据集的一个示例性帧。为了进行评估,基本真相被分为简单、适度和困难三类。对于后者,所有的对象都被评估,而对于中等完全遮挡的对象被排除,而对于简单,只有完全可见的对象被评估。
平均精度(AP)是一种公认的三维目标检测评价[16]的评价指标。当联合上的地面真实对象的三维交集(IoU)超过0.5时,检测结果与地面真实对象相匹配。
对于雷达摄像机的精度-查全率曲线如图2所示。对于这类轿车,简单、中等和困难的平均精度分别为0.61、0.48、0.45。
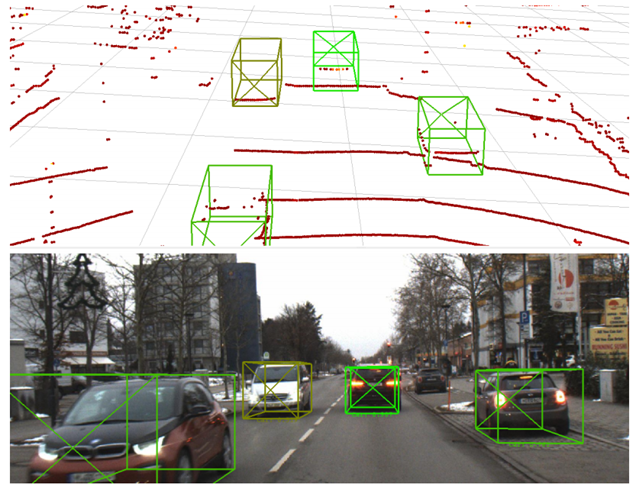
图4 在激光雷达和照相机数据上的检测示例
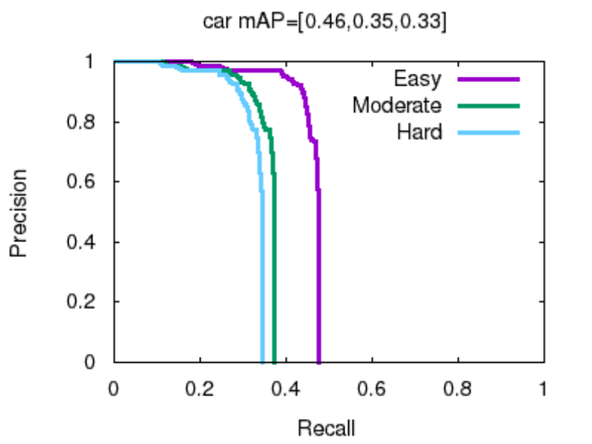
图5 在测试数据集上的激光雷达和照相机的精确召回曲线
为了对雷达和激光雷达进行有意义的比较,我们将用雷达和摄像机数据训练的网络的性能与用同一小数据集的激光雷达和摄像机数据训练时的性能进行了比较。所有的训练参数都保持不变。结果的精度查全曲线如图5所示。易、中、硬的平均精度分别为0.46、0.35、0.33。这意味着,当使用雷达数据代替激光雷达点云时,网络的AP明显更高。
图6中为雷达+摄像机和激光雷达+摄像机的圆条形图。可以注意到,到目前为止,大多数检测到的方向为0◦或180◦。这种效应在基于雷达的探测中更加明显。
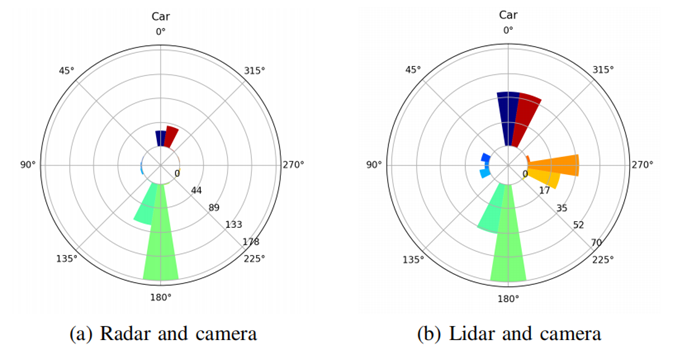
图6 测试数据集上检测边界框方向的圆条形图
4 讨论
对于小数据集,具有雷达点云和摄像机图像的网络AP表现良好。然而,它远远低于在激光雷达和摄像机上训练的目标检测算法的最新结果。目前,在激光雷达和照相机上训练的KITTI 3D目标检测基准[16]上报告的最佳性能为0.68。但是KITTI数据集包含了近20倍的训练数据量,因此这些结果并不真正具有可比性。利用本文中使用的小数据集,当使用雷达时的结果明显更好。
激光雷达给出了一个空间上非常精确的点云。因此,当使用雷达数据作为输入而不是激光雷达点云时,目标检测性能会更好,这可能会令人惊讶。此外,当使用雷达数据时,该网络在检测被遮挡物体方面相对较好。在非八极物体上,雷达的性能好15%,而在被遮挡物体上,性能仅好12%。所以,尽管使用雷达的网络在遮挡物体检测上表现很好,但在无遮挡物体检测方面表现不佳。这可以解释为,尽管激光雷达在空间上比雷达更精确,但点云的密度并不是均匀分布的。点云在靠近激光雷达传感器时非常密集,而远离时非常稀疏。因此,遥远的物体即使没有被遮挡,也并不总有激光雷达点。点云中没有远距离的点,目标自然不太可能被检测到(见图7)。这些可能是部分被遮挡的物体,但一般未被遮挡的物体的表面上也没有激光雷达点。当然,这种影响可以通过使用具有更多线的激光雷达传感器来减轻。然而,这只会把问题转移到一个更大的范围,因为点的不均匀分布是激光雷达传感器特征固有的缺陷。
对于雷达点云和相机图像,对于如此小的数据集,平均精度惊人地高。仅从测试数据集上的AP值,就可以得出结论,训练数据的量几乎足以使网络进行泛化。然而,一旦考虑到测试数据上的检测方向,很明显,训练数据或测试数据(或两者)中的方向方差是不够的。测试数据集上几乎所有的检测盒都平行于自我车辆的视图轴。如果这些框架的基本真相确实有这些方向,这将是可取的。不幸的是,事实并非如此。训练该网络来检测汽车是成功的,但该网络还不能准确地预测车辆的角落。基于这些结果,我们猜测,增加数据集的大小和使用方向分布更均匀的训练数据将会得到显著更好的结果。
很难得出结论,为什么雷达网络的AP更好,而方向探测略差。一种可能性是,这只是由于本文中使用的激光雷达数据来自一个16线的激光雷达传感器,它较低的线数导致它遗漏了很多物体。另一种解释是,由于车辆角度的不同,车辆在雷达网络中更容易分类。这意味着该网络能够更容易泛化雷达数据,同时能够更好地预测激光雷达点云中的方向。我们还需要进一步的研究来回答这个问题。
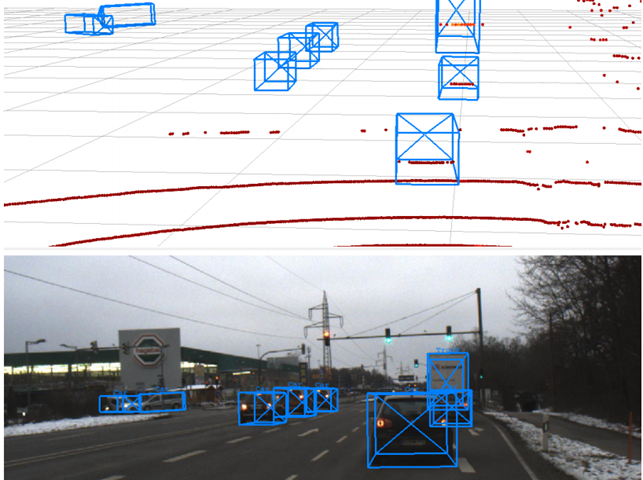
图7 真值示例,显示了激光雷达传感器的主要缺点。左边的五辆车的表面都没有激光雷达点
本文的研究表明,深度cnn是一种适用于雷达点云和摄像机图像的低水平传感器融合的方法。在雷达点云和摄像机图像的测试数据集中,完全可见的汽车被检测到的平均精度为0.61。
雷达数据在空间上不如激光雷达点云准确。结果表明,这在目标检测任务中没有任何问题。该网络似乎能够模拟雷达数据中固有的噪声。这并不奇怪,因为它已经证明,用有噪声的数据训练神经网络可以有利于性能[17]的鲁棒性。
即使多普勒信息是雷达点的一个强大特征,但不包含在网络的输入中,结果是相当可以接受的。在未来的工作中,点云的多普勒信息将被包含在网络的输入中。此外,网络还将预测不确定性,以改进网络[18]的训练过程。
此外,将基于雷达和摄像机的目标检测结果与摄像机和使用相同数据集训练的64层激光雷达的结果进行比较。
数据集的大小也将会增加,这可能会显著提高性能。本文认为,数据集的大小是目前对雷达点云和摄像机图像的三维目标检测性能的最关键的限制。

本文译自:Deep Learning Based 3D Object Detection for Automotive Radar and Camera
作者:Michael Meyer, Georg Kuschk
原文链接:ttps://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8904867
END
