本文简介
本文介绍Linux 2.6.32-rc7中,分级RCU的基础。
这不是一篇单独的文章,这是《谢宝友:深入理解Linux RCU》系列的第6篇。关注Linuxer公众号看前五篇:

作者简介
谢宝友,别名浪子燕青,在编程一线工作已经有20年时间,其中10年时间工作于Linux操作系统。
同时,他也是《深入理解并行编程》一书的译者。该书作者PaulE.McKeney是IBM Linux中心技术领导者,LinuxRCU Maintainer。《深入理解RCU》系列文章整理了PaulE.McKeney的相关著作,希望能帮助读者更深刻的理解Linux内核中非常难于理解的模块:RCU。
目前,他编写的Hot-Pot操作系统即使发布第一个版本。这个版本基于ARM 64多核系统,包含了调度、中断、定时器、内存管理、LEXT3文件系统、LWIP网络协议栈、一个精简版本的内核态C库、一些基本的Shell命令等等基本的操作系统功能。虽然目前代码还比较丑陋,仅仅算是Linux的一个小学生,但是也可以自豪的声称:Hot-Pot操作系统拥有了一个Good Start。今年,他将编写一本《Hot-Pot操作系统详解--迈向工业级服务器操作系统的实现》来详细阐述这个操作系统,并以GPL协议公布源代码,热切希望所有有兴趣的好汉一起参与。
联系方式:
mail:scxby@163.com
微信:linux-kernel

本文基于linux 2.6.32-rc7版本的源码, 因此请准备一份linux2.6.32-rc7代码。建议用如下两种方法获取源代码:
1、直接在linux.org上面下载源码包。
2、使用git从linux-next拉取最新代码,然后使用git checkout -b linux-2.6.32-rc7 v2.6.32-rc7检出2.6.32-rc7版本的源码。
虽然Linux更早版本中的经典RCU,其读端原语拥有出色的性能和扩展性,但是写端原语则需要判断预先存在的读端临界区在什么时候完成,它仅仅被设计用于数十个CPU的系统。经典RCU的实现,要求在每个优雅周期内,每个CPU必须获取一个全局锁,这使得它们的扩展性受到了限制。虽然在实际生产系统中,经典RCU可以运行在几百个CPU的系统中,甚至能够比较困难的使用到上千个 CPU的系统中,但是大型多核系统仍然需要更好的扩展性。
另外,经典RCU有一个不是最优的dynticks 接口,导致经典RCU在每一个优雅周期都要唤醒每一个CPU,即使这些CPU处于idle状态。我们考虑一个16核的系统,它只有四个CPU比较忙,其他CPU的负载都很轻。理想情况下,余下12个CPU可以一直处于深度睡眠模式以节约能源。然而不幸的是,如果四个忙的CPU频繁的执行RCU更新,这12个空闲CPU会被周期性的唤醒,浪费了重要的能源。因此,对于经典RCU的任何优化,都应当让这些睡眠状态的CPU继续处于睡眠状态。
经典RCU和分级RCU实现都有和经典RCU相同的语义和API。但是,原有的实现被称为“经典RCU”,新实现被称为“分级RCU”。
从最基本的方面来说,RCU 是一种等待事务完成的方法。当然,要等待事务完成,还存在很多其他方法,包括引用计数、读写锁、事件等等。RCU的一个大的优势是可以同时等待20,000个不同的事件,而不必具体的跟踪其中每一个事件,并且不用担心性能被降低,以及扩展性被限制,也不用担心复杂的死锁情况和内存泄漏的危险。
在RCU中,被等待的事件被称为“RCU 读端临界区”。RCU读端临界区以rcu_read_lock()原语开始,以相应的rcu_read_unlock() 原语结束。RCU读端临界区可以嵌套,也可以包含相当多的代码,只要这些代码不阻塞或者睡眠(当然,这是针对经典RCU来说的。有一种特殊的名为SRCU的可睡眠RCU,它允许在SRCU读端临界区中进行短期睡眠)。如果您遵从这些约束,您可以使用RCU来等待任何代码片段完成。
RCU通过间接的确定其他事务何时完成来实现这一点。但是,请注意:在特定的优雅周期之后开始的RCU 读端临界区能够、也必然会延长优雅周期的结束点。
经典RCU实现的关键原理是:经典RCU 读端临界区限制其中的内核代码不允许阻塞。这意味着在任意时刻,一个特定的CPU只要看起来处于阻塞状态、IDLE循环、或者离开了内核后,我们就知道所有RCU读端临界区已经完成。这些状态被称为“静止状态”,当每一个CPU已经经历过至少一次静止状态时,RCU优雅周期结束。
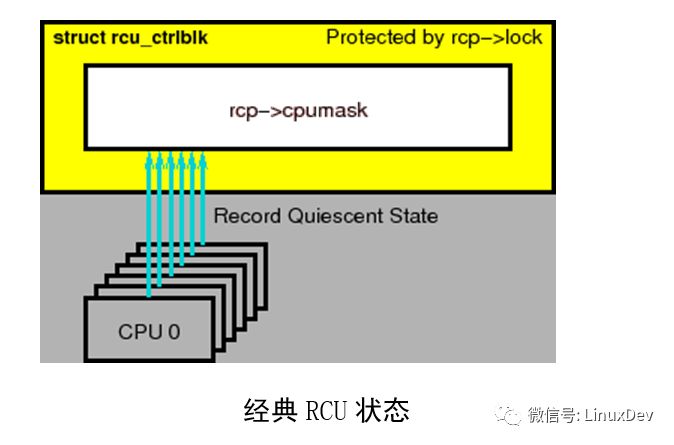
经典RCU最重要的数据结构是rcu_ctrlblk,它包含了->cpumask字段,每一个CPU在该字段中包含一位,如上图所示。当每一个优雅周期开始时,每一个 CPU相应的位被设置为1,每一个CPU经过一次静止状态时,必须清除相应的位。由于多个CPU可能希望同时清除它们的位,这将破坏->cpumask 字段,因此使用了一个->lock自旋锁来保护->cpumask。不幸的是,当超过几千个CPU时,这个自旋锁会遇到严重的竞争状态。更糟糕的是,事实上所有CPU必须清除它们的位,意味着在一个优雅周期内,CPU不允许一直睡眠。这削弱了LINUX节能的能力。
实时RCU迫切要解决的问题列表如下:
1. 延迟销毁。这样,直到所有已经预先存在的RCU读端临界区已经完成,一个RCU优雅周期才能结束。
2. 可靠性,这样RCU支持24x7运行。
3. 可以在IRQ处理函数中调用。
4. 包含内存标记,这样,如果有很多回调过程,这种机制将加快结束优雅周期。
5. 独立的内存块,这样RCU能够基于可信的内存分配器进行工作。
6. synchronization-free的读端,这样允许通常的非原子指令操作于CPU(或者任务)的本地内存。
7. 无条件的read-to-write提升,在LINUX内核中,有几个地方需要这样使用。
8. 兼容的API。
9. 抢占RCU读端临界区的要求可以被去掉。
10. 极低的RCU内部锁的竞争,从而带来极大的扩展性。RCU必须支持至少1,024个CPU,最好是至少4,096个CPU。
11. 节能:RCU必须能够避免唤醒低电压状态的dynticks-idle CPU,但是仍然能够判断当前的优雅周期何时结束。这已经在实时RCU中实现,但是需要大大的简化。
12. RCU读端临界区必须允许在NMI处理函数中使用,就如在中断处理函数中一样。
13. RCU必须很好的管理不停的CPU热插拨操作。
14. 必须能够等待所有事先注册的RCU回调完成,虽然这已经以rcu_barrier()的形式提供。
15. 检测失去响应的CPU是值得的,以帮助诊断RCU和死循环BUG及硬件错误,这能够防止RCU优雅周期不能结束的情况。
16. 加快RCU优雅周期是值得的,这样RCU优雅周期能够强制在数百微秒内完成。但是,这样的操作预期会带来严重的CPU负载。
最急迫的首要需求是:可扩展性。因此需要减少RCU的内部锁。
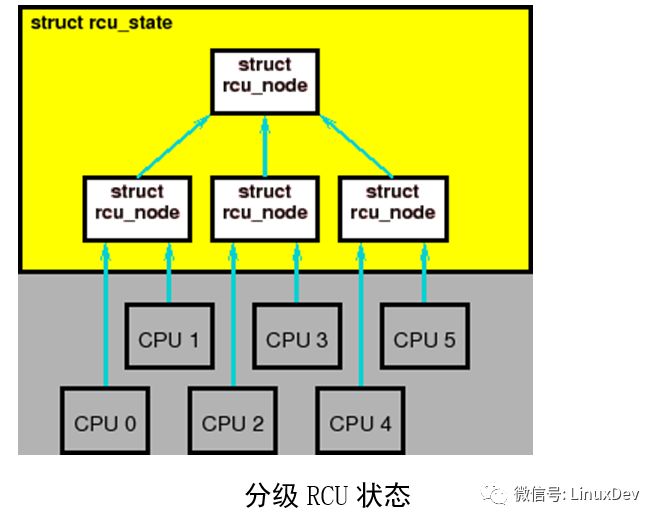
减少锁竞争的一个有效方法是创建一个分级结构,如上图所示。在此,四个rcu_node 结构中的每一个都有各自的锁,这样只有 CPU 0 和 1 会获取最左边的 rcu_node的锁, CPU 2 和 3 会获取中间的rcu_node的锁,CPU 4和5会获取右边的rcu_node的锁。在任一个优雅周期期间,仅仅某一个CPU节点会访问rcu_node 结构的上一层的rcu_node。也就是说,在上图中,每一对CPU(它们处于同一个CPU节点)中,最后一个记录静止状态的CPU才会访问上一层的rcu_node。
这样做的最终结果,是减少了锁的竞争。在经典RCU中,6个CPU在每一个优雅周期内竞争同一个全局锁,在上图中,仅仅是三个节点竞争最上层的rcu_node锁 (降低了50%)。
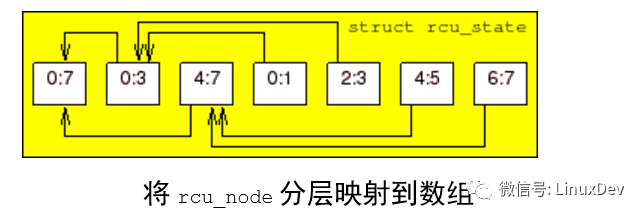
rcu_node结构树被嵌入到rcu_state 结构的一个线性数组,树根是结点0,如上图。它是一个8-CPU的、三层分级结构的系统。每一个箭头将一个rcu_node 结构链接到它的父结点,这对应着rcu_node结构的->parent 字段。每一个rcu_node都标示了它所覆盖的CPU范围,这样根结点覆盖了所有CPU,每一个二级结点覆盖了一半的CPU,每一个叶子结点覆盖了两个 CPU。这个数组在编译时基于NR_CPUS的值静态分配。
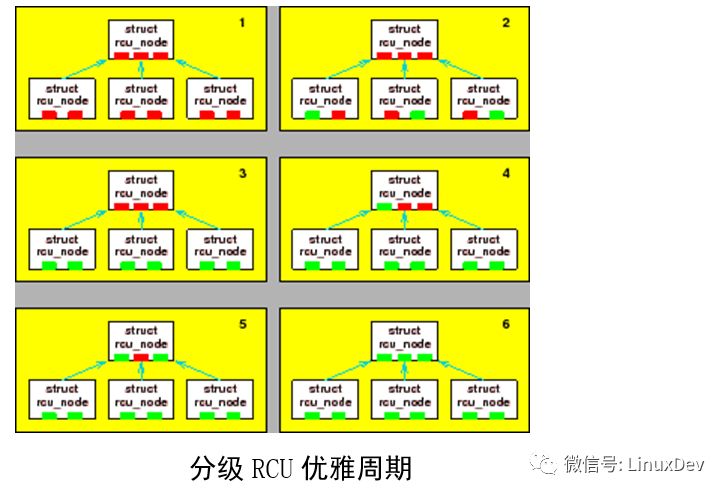
上图显示了如何检测优雅周期。在第一个图中,没有CPU经过静止状态,并用红块标示。假设所有6个CPU试图同时告诉RCU,它们已经经过一个静止状态。那么,在每一对CPU中,仅仅其中某一个CPU能够获得底层rcu_node结构的锁。第二个图中,假设CPU0、3、5比较幸运的获得了底层rcu_node结构的锁,在图中标识为绿色块。一旦这些幸运的CPU结束了,那么其他CPU将获得锁,如图3所示。这三个CPU中,每一个CPU将会发现它们是组内最后一个CPU,因此所有三个CPU尝试移到上层rcu_node。此时,仅仅其中一个能获得上层rcu_node 锁。我们假设CPU1、2、4依次获得了锁,则第4、5、6图显示了相应的状态。最后,第6图显示了所有CPU已经经过一次静止状态,因此优雅周期结束。
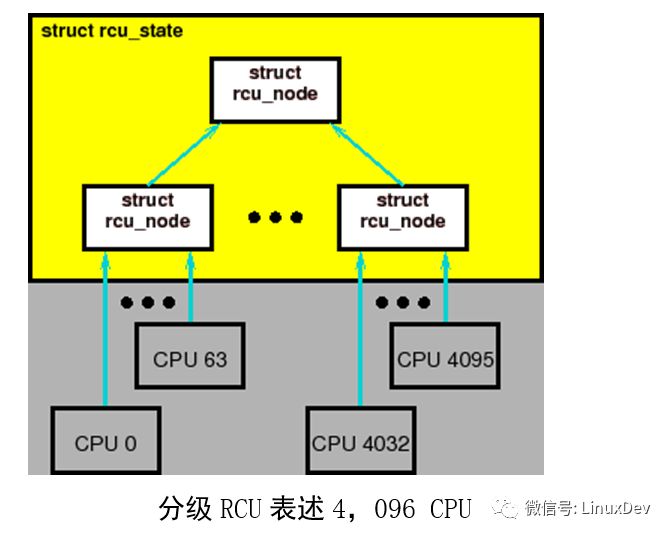
在上面的顺序中,没有超过3个CPU为同一个锁产生竞争,与经典RCU进行对比,我们会高兴的发现,经典RCU中,所有6个CPU都可能冲突。但是,对更多的CPU来说,可以再显著的减少锁之间的冲突。考虑有64个底层结构及64*64=4,096 CPU的分组结构,如图上图。
在此,每一个底层rcu_node 结构的锁被64个CPU申请,将从经典RCU的4096个CPU竞争一个单一的锁降为64个CPU竞争一个锁。在一个特定的优雅周期期间,仅仅一个底层rcu_node 中的某一个CPU会申请上级rcu_node 的锁。这样,与经典RCU相比,减少了64倍的锁竞争。
正如较早前提示的一样,这些努力的一个重要目的是使一个处于睡眠状态的CPU保持它的睡眠状态,以节约能源。与之相对的是,经典RCU至少会在一个优雅周期内唤醒每一个处于睡眠状态的CPU。当其他大多数CPU都处于空闲状态时,这些个别的CPU进行rcu写操作,会使得这种处理方法不是最优的。这种情形将在周期性的高负载系统中发生,我们需要更好的处理这种情况。
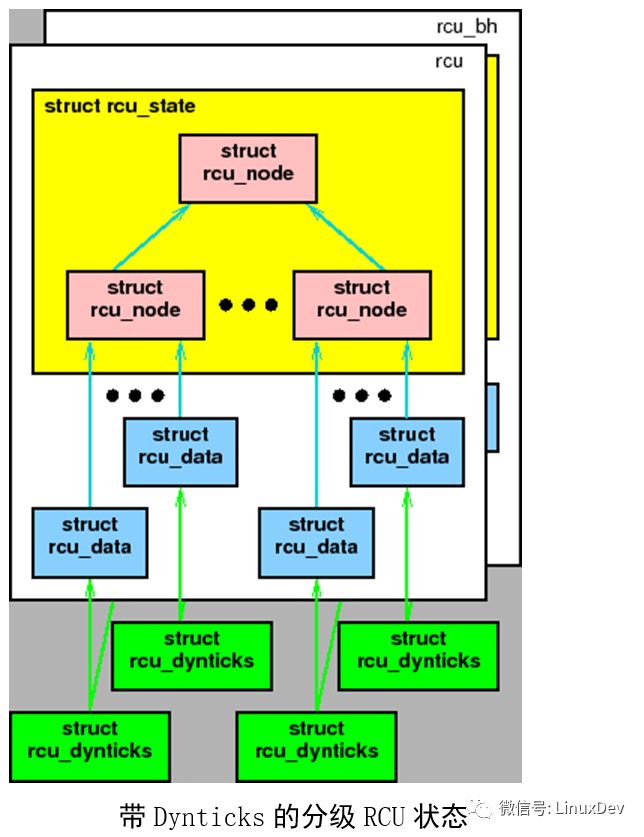
这是通过要求所有CPU操作位于一个每CPU rcu_dynticks 结构中的计数器来实现的。不是那么准确的说,当相应的CPU处于dynticks idle模式时,计数器的值为偶数,否则是奇数。这样,RCU仅仅需要等待rcu_dynticks 计数值为奇数的CPU经过静止状态,而不必唤醒正在睡眠的CPU。如上图,每一个每CPU rcu_dynticks结构被“rcu”和“rcu_bh”实现所共享。
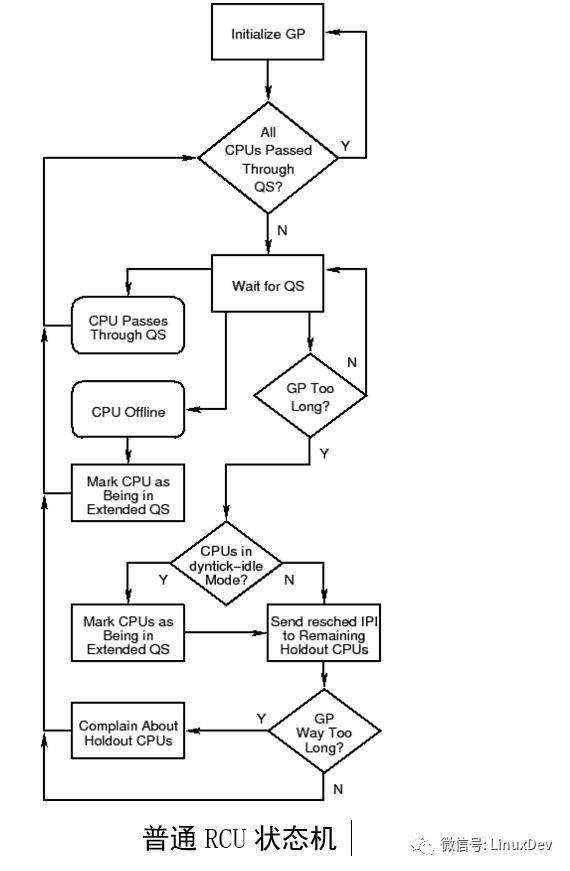
从十分高层的视角来看,Linux内核RCU 实现可以被认为是一个高级状态机,如上图。在一个很繁忙的系统上,通常的路径是最上面的两个循环。在每一个优雅周期(GP)开始时进行初始化,等待静止状态 (QS)。在一个特定的优雅周期中,当每一个CPU都经历过静止状态时,它其实什么都不用做。在这样一个系统中,经历如下事件表明产生一个静止状态:
1、每一次进程切换
2、在CPU进入idle状态
3、或者执行用户态代码时
CPU热插拨事件将使状态机进入“CPU Offline”流程。而“holdout”CPU(那些由于软件或者硬件原因导致迟迟不能经过一次静止状态的CPU)的出现,使得不能快速经历一次静止状态,这将使状态机进入“send reschedIPIs to Holdout CPUs”(发送重新调度IPI给Holdout CPUS)流程。为了避免不必要的唤醒处于dyntick-idle 状态的CPU,RCU 实现将标记这些CPU处于扩展的静止状态,通过“Y”分支离开“CPUs in dyntick-idle Mode?”(但是请注意,这些处于dyntick-idle模式的CPU将不会被发送重新调度IPI)。最后,如果CONFIG_RCU_CPU_STALL_DETECTOR打开了,过迟的到达静止状态将使状态机进入“Complain About Holdout CPUs”流程。
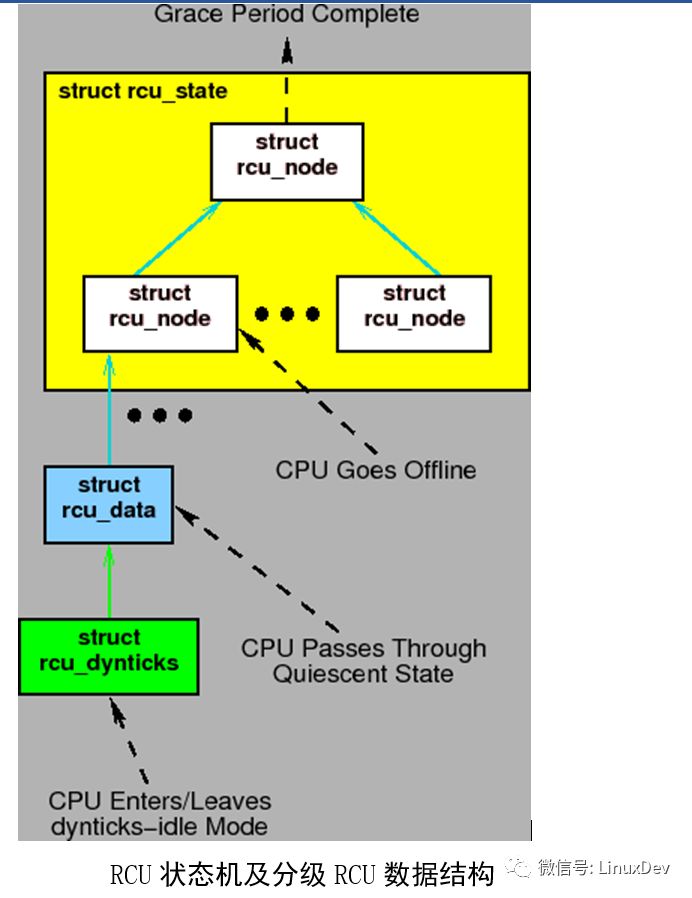
上面的状态图中,事件会与不同的数据结构交互。但是,状态图不会被任何RCU实现直接翻译为C代码。相反的,这些实现在内核中被编码为事件驱动的系统。我们通过一些用例来表示这些事件。
2.7. 用例
这些事件驱动的用例包括:
1. 开始一个新的优雅周期
2. 经历一个静止状态
3. 向RCU通告一个静止状态
4. 进入、退出Dynticks Idle 模式
5. 从Dynticks Idle 模式进入中断
6. 从 Dynticks Idle 模式进入NMI
7. 标记一个CPU处于Dynticks Idle 模式
8. CPU离线
9. CPU上线
10. 检测一个太长的优雅周期
2.7.1. 开始一个新的优雅周期
rcu_start_gp()函数开始一个新的优雅周期。当一个CPU存在回调,而该回调需要等待优雅周期时,就需要调用此函数。
rcu_start_gp()函数更新rcu_state和rcu_data结构中的状态,以标识开始一个新的优雅周期,获取->onoff 锁 (并关中断) 以防止任何并发的CPU热插拨操作,在所有的rcu_node结构中设置位,以标识所有CPU (包括当前CPU) 必须经历一次静止状态,最后释放->onoff 锁。
设置位操作分两个阶段进行。首先,在没有持有任何锁的情况下,非叶子节点rcu_node 的位被设置,然后,在持有->lock的情况下,每一个叶子节点的rcu_node 结构的位被设置。
2.7.2. 经历一次静止状态
rcu和rcu_bh有各自的静止状态集合。
RCU的静止状态是进程切换、IDLE (不管是dynticks 还是IDLE循环)、以及执行用户态程序。
RCU-bh的静止状态是在开中断状态下,退出软中断。
需要注意的是,rcu的静止状态也是rcu_bh的静止状态。rcu的静止状态通过调用rcu_qsctr_inc()来记录。而rcu_bh的静止状态通过调用rcu_bh_qsctr_inc()来记录。这两个函数将它们的状态记录到当前CPU的rcu_data 结构中。请注意:在2.6.32版本中,rcu_qsctr_inc和rcu_bh_qsctr_inc函数已经被更名。如何通过git查找它们被更名为什么名称,这个任务就留给作者当做练习了。
这些函数在调度器、__do_softirq()和rcu_check_callbacks()中被调用。后面这个函数在调度时钟中断中调用,并分析状态以确定中断是否发生在一个静止状态中,以确定是调用rcu_qsctr_inc()或者 rcu_bh_qsctr_inc()。它也触发RCU_SOFTIRQ软中断,并导致当前CPU在随后的软中断上下文中调用rcu_process_callbacks(),rcu_process_callbacks函数处理RCU在每个CPU上的回调函数以释放资源。
2.7.3. 向RCU宣告一次静止状态
前述的rcu_process_callbacks() 函数要完成几个事情:
1. 确定何时结束一个太长的优雅周期(通过force_quiescent_state())。
2. 当CPU检测到优雅周期结束时,采用适当的动作。(通过 rcu_process_gp_end())。“适当的动作”包括加快本CPU的回调,以及记录新的优雅周期。同一个函数也更新状态以响应其他CPU。
3. 向RCU核心机制报告当前CPU的静止状态。(通过 rcu_check_quiescent_state(),它会调用 cpu_quiet())。当然,这个过程也会标记当前的优雅周期结束。
4. 如果没有处理优雅周期,并且这个CPU有RCU回调等待优雅周期,则开始一个新的优雅周期(通过 cpu_needs_another_gp()和rcu_start_gp())。
5. 当优雅周期结束时,调用这个CPU的回调 (通过 rcu_do_batch())。
这些接口都经过精心实现,以避免BUG,如:错误的从上一个优雅周期向当前优雅周期报告静止状态这样的BUG。
2.7.4. 进入和退出 Dynticks Idle模式
调度器调用rcu_enter_nohz()进入dynticks-idle 模式,并调用 rcu_exit_nohz()离开此模式。rcu_enter_nohz() 函数递增每CPU dynticks_nesting变量,也递增每CPU dynticks计数器,然后,后者必然拥有一个偶数值。rcu_exit_nohz() 函数递减每CPU dynticks_nesting 变量,并且再一次递增每CPU dynticks计数器,后者将拥有一个奇数值。
dynticks 计数器可以被其他 CPU采样。如果其值是偶数,那么该CPU处于扩展静止状态。类似的,如果计数器在一个特定的优雅周期内发生了改变,那么CPU必然在优雅周期期间的某个时间点上处于扩展静止状态。但是,还需要采样另外一个dynticks_nmi每CPU变量,随后我们将讨论这个变量。
2.7.5. 从Dynticks Idle 模式进入中断
从dynticks idle 模式进入中断由rcu_irq_enter() 和 rcu_irq_exit()处理。rcu_irq_enter() 函数递增每CPU dynticks_nesting 变量,如果此变量为0,也递增dynticks每CPU变量 (它将拥有一个奇数值)。
rcu_irq_exit()函数递减每CPU dynticks_nesting变量。并且,如果新值是0,也递增dynticks每CPU变量 (它将拥有一个偶数值)。
注意:进入中断会处理退出dynticks idle模式,反之也一样。进入、退出之间不一致可能导致一些混乱,不用警告你也应该想得到这一点。
2.7.6. 从Dynticks Idle 模式进入NMI
从dynticks idle模式进入NMI由rcu_nmi_enter()和rcu_nmi_exit()处理。这些函数同时递增dynticks_nmi计数器,但仅仅是在前述dynticks 计数是偶数时才进行递增。换句话说,如果NMI发生时,处于非dynticks-idle模式或者处于中断状态,那么 NMI将不操作dynticks_nmi计数器。
这两个函数之间唯一的差异在于错误检查,rcu_nmi_enter()必然使dynticks_nmi计数器为奇数值,rcu_nmi_exit()必然使这个计数器为偶数值。
2.7.7. 标记CPU处于Dynticks Idle模式
force_quiescent_state()函数实现一个三阶段的状态机。第一个阶段 (RCU_INITIALIZING)等待rcu_start_gp()完成对优雅周期的初始化。这个状态不是从force_quiescent_state()退出,就是从rcu_start_gp()退出。
在第二阶段(RCU_SAVE_DYNTICK),dyntick_save_progress_counter()函数扫描还没有报告静止状态的CPU,记录它们的每CPU dynticks 和dynticks_nmi 计数器。如果这些计数器都是偶数值,那么相应的CPU处于dynticks-idle 状态,因此标记它们为扩展静止状态(通过cpu_quiet_msk()报告)。
在第三阶段(RCU_FORCE_QS),rcu_implicit_dynticks_qs()函数再一次扫描仍然没有报告静止状态的CPU (既没有明确标示,也没有在RCU_SAVE_DYNTICK阶段隐含的标示),再一次检查每CPU dynticks 和 dynticks_nmi计数器。如果每一个值都变化,或者目前为偶数,那么相应的相应的CPU已经经过一次静止状态或者目前处于dynticks idle模式,也就是前述扩展静止状态。
如果rcu_implicit_dynticks_qs()发现特定CPU既没有处于dynticks idle模式,也没有报告一个静止状态,它调用rcu_implicit_offline_qs(),这个函数检查CPU是否处于离线状态,如果是,那么也报告一个扩展静止状态。如果CPU在线,那么rcu_implicit_offline_qs()发送一个重新调度IPI,尝试提醒该CPU应当向RCU报告一个静止状态。
请注意:force_quiescent_state() 既不直接调用dyntick_save_progress_counter(),也不直接调用rcu_implicit_dynticks_qs(),而是将它们传递给rcu_process_dyntick() 函数。这个函数抽象出扫描CPU、报告扩展静止状态的通用代码。
2.7.8. CPU离线
CPU离线事件导致rcu_cpu_notify()调用rcu_offline_cpu(),在rcu和rcu_bh上依次调用__rcu_offline_cpu()。这个函数清除离线CPU的位,这样,后面的优雅周期将不再期望这个CPU宣告静止状态,随后调用cpu_quiet(),以宣告离线扩展静止状态。这是在持有全局->onofflock锁的情况下执行的,这是为了防止与优雅周期初始化相冲突。
2.7.9. CPU上线
CPU上线事件导致rcu_cpu_notify()调用rcu_online_cpu(),用于初始化CPU的dynticks状态,然后调用rcu_init_percpu_data()初始化CPU的rcu_data 数据结构,也设置这个 CPU的位(同样通过全局->onofflock进行保护),这样后面的优雅周期将等待这个CPU的静止状态。最后,rcu_online_cpu()设置这个CPU的RCU 软中断向量。
2.7.10. 检测太长的优雅周期
当配置了CONFIG_RCU_CPU_STALL_DETECTOR内核参数时,record_gp_stall_check_time() 函数记录当前时间,以及3秒以后的时间戳。如果当前优雅周期到期后仍然没有结束,那么check_cpu_stall函数将检测罪魁祸首。并且如果当前CPU是造成延迟的CPU,则调用print_cpu_stall(),如果不是,则调用print_other_cpu_stall()。两个jiffies的时间差有助于确保其他CPU在可能的情况下报告它的状态,利用这个时间差,CPU能够做一些事情,例如跟踪它自己的堆栈。
2.8. 测试
RCU是基本的同步代码,因此RCU的错误导致的后果是随机的、难于调试的内存错误。因此,高可靠的RCU是非常重要的。这些可靠性来自于小心的设计,但是最终还是需要依赖于高强度的压力测试。
幸运的是,虽然有一些关于覆盖性方面的争论,但是仍然可以对软件进行一些压力测试。实际上,进行这些测试是被强烈建议的,因为不对你的软件进行折磨性测试的话,它就会反过来折磨你,这种折磨来自于:它在不合时宜的时候崩溃掉。
因此,我们使用rcutorture模块来对RCU进行压力测试。
但是,根据通常情况下的RCU用法来对RCU进行测试,显得还不是很充分。也有必要针对不常用的情况进行压力测试。例如,CPU并发的上线或者离线,CPU并发的进入及退出dynticks idle模式。Paul使用了一个脚本CodeSamples,并向模块rcutorture使用test_no_idle_hz 模块参数对dynticks idle模式进行压力测试。有时作者也比较疑神疑鬼,因此尽量在测试时运行一个kernbench负载测试程序。在128路的机器上运行10个小时的压力测试,看起来是足够测试出几乎所有BUG了。
实际上这还不算完。Alexey Dobriyan和Nick Piggin早在2008年就证明过,以所有相关内核参数组合对RCU进行压力测试是必要的。相关的内核参数可以使用另外一个脚本CodeSamples进行标识。
1. CONFIG_CLASSIC_RCU:经典 RCU。
2. CONFIG_PREEMPT_RCU:可抢占 (实时) RCU。
3. CONFIG_TREE_RCU:用于大型SMP系统的经典 RCU。
4. CONFIG_RCU_FANOUT:每一个rcu_node 的子结点数量。
5. CONFIG_RCU_FANOUT_EXACT:平衡rcu_node 树。
6. CONFIG_HOTPLUG_CPU:允许 CPU上线、离线。
7. CONFIG_NO_HZ:打开dyntick-idle 模式。
8. CONFIG_SMP:打开 multi-CPU选项。
9. CONFIG_RCU_CPU_STALL_DETECTOR:当CPU进入扩展静止状态时进行RCU检测。
10. CONFIG_RCU_TRACE:在debugfs中生成 RCU跟踪文件。
我们忽略CONFIG_DEBUG_LOCK_ALLOC 配置变量,因为我们假设分级RCU不能打断 lockdep。仍然有10个配置变量,如果它们是独立的布尔值,则导致1024种组合。幸运的是,首先,其中前三个是互斥的,这样可以将组合数量减少到384个,但是CONFIG_RCU_FANOUT可以取值2-64,将组合数量增加到12,096。这么大量的组合是不可能都实施的。
关键的一点是:如果CONFIG_CLASSIC_RCU或者CONFIG_PREEMPT_RCU有效时,预期仅仅CONFIG_NO_HZ 和 CONFIG_PREEMPT 可能会改变其行为。这几乎减少了三分之二的组合。
而且,并不是这些所有可能的CONFIG_RCU_FANOUT值都会产生显著有效的结果,实际上仅仅一部分情况需要分别测试:
1. 单结点“tree”。
2. 两级平衡树。
3. 三级平衡树。
4. 自动平衡树,当 CONFIG_RCU_FANOUT 指定一个不平衡树,但是没有配置CONFIG_RCU_FANOUT_EXACT 时,进行自动平衡。
5. 非平衡树。
更进一步说,CONFIG_HOTPLUG_CPU仅仅在指定CONFIG_SMP 时才有用,CONFIG_RCU_CPU_STALL_DETECTOR是独立的,因此仅仅需要测试一次(然而有些人比我还多疑,他们可能决定在有CONFIG_SMP和没有CONFIG_SMP 时,都测试它)。类似的,CONFIG_RCU_TRACE也仅仅需要测试一次。但是象我一样多疑的人,会选择在有CONFIG_NO_HZ 和没有CONFIG_NO_HZ 时,都测试一下它。
这允许我们在15种测试情形下,得到一个覆盖率较好的RCU测试。所有这些测试情形都指定如下配置参数以运行rcutorture,这样CONFIG_HOTPLUG_CPU=n会产生实际的效果:
CONFIG_RCU_TORTURE_TEST=m
CONFIG_MODULE_UNLOAD=y
CONFIG_SUSPEND=n
CONFIG_HIBERNATION=n
15个测试用例如下:
1. 强制单节点“树”,用于小型系统:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=8
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
2. 强制两级节点树用于大型系统:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=4
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=n
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
3. 强制三级节点树,用于非常大型的系统:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=2
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
4. 测试自动平衡:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=6
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
5. 测试不平衡树:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=6
CONFIG_RCU_FANOUT_EXACT=y
CONFIG_RCU_CPU_STALL_DETECTOR=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
6. 禁止CPU延迟检测:
CONFIG_SMP=y
CONFIG_NO_HZ=y
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
7. 禁止 CPU延迟检测及dyntick idle 模式:
CONFIG_SMP=y
CONFIG_NO_HZ=n
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
8. 禁止 CPU延迟检测及CPU热插拨:
CONFIG_SMP=y
CONFIG_NO_HZ=y
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
9. 禁止 CPU延迟检测,dyntick idle 模式,及CPU热插拨:
CONFIG_SMP=y
CONFIG_NO_HZ=n
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
10. 禁止SMP、CPU延迟检测、dyntick idle 模式、及CPU热插拨:
CONFIG_SMP=n
CONFIG_NO_HZ=n
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
这个组合有一些编译警告。
11. 禁止SMP、禁止CPU热插拨:
CONFIG_SMP=n
CONFIG_NO_HZ=y
CONFIG_RCU_CPU_STALL_DETECTOR=y
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
12. 有dynticks idle 但是没有抢占的情况下,测试经典RCU:
CONFIG_NO_HZ=y
CONFIG_PREEMPT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=y
CONFIG_TREE_RCU=n
13. 有抢占但是没有dynticks idle时,测试经典RCU:
CONFIG_NO_HZ=n
CONFIG_PREEMPT=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=y
CONFIG_TREE_RCU=n
14. 在dynticks idle情况下,测试可抢占RCU:
CONFIG_NO_HZ=y
CONFIG_PREEMPT=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=y
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=n
15. 在没有 dynticks idle时,测试可抢占RCU:
CONFIG_NO_HZ=n
CONFIG_PREEMPT=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=y
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=n
对于每一次大的影响RCU核心代码的变化,都应当以上面的组合运行rcutorture,并且在CONFIG_HOTPLUG_CPU时,并发的进行CPU热插拨。对小的变化,在每一种情况下运行kernbench就行了。当然,如果变化仅仅限于配置参数的部分子集,就可以减少测试用例的数量。
作者强烈推荐压力测试软件:Geneva Convention!
2.9. 结论
这个分级RCU实现减少了锁竞争,避免了不必要的唤醒dyntick-idle睡眠状态的CPU,因此有助于调试Linux CPU热插拨代码。这个实现被设计用于处理数千个CPU的大型系统,并且在64位系统上,CPU数量限制是250,000,在今后一段时间内,这个限制是没有问题的。
这个RCU实现当然也有一些局限:
1. force_quiescent_state()可能在关中断下扫描整个CPU集。这在实时RCU实现中,是一个重大缺陷。因此,如果需要在可抢占RCU中加入分级,则需要其他方法。在4096个CPU的系统中,它可能会产生一些问题,但是需要在实际的系统中进行测试以证明真的有问题。
在繁忙的系统中,不能指望force_quiescent_state()扫描会发生,CPU将在开始一个静止状态后,在三个jiffies内经历一次静止状态。在半繁忙的系统中,仅仅处于dynticks-idle模式的CPU需要扫描。其他情况下,例如,在一个dynticks-idle CPU扫描过程中,处理一个中断时,后继的扫描是需要的。但是,这样的扫描是分别在相应的CPU上执行的,因此相应的调度延迟仅仅影响该扫描过程所在的CPU负载。
如果扫描被证明确实有问题,一个好的方法是进行递增扫描。这将稍微增加一点代码复杂性,也增加一点结束优雅周期的时间,但是这也确实算是一个好的方案。
2. rcu_node分级在编译时创建,因此其长度是最大的CPU数量NR_CPUS。但是,即使在4,096 CPU的系统中,在64位系统上,rcu_node 分级也仅仅消耗65个缓存行。(即使在32位系统上包含4,096 CPUs也是这样!)。当然,在一个16 CPU的系统中,配置NR_CPUS=4096将使用一个二级树,实际上在这种情况下,单节点树也会运行得很好。虽然这个配置会增加锁的负载,但是实际上不会影响经常执行的读端代码,因此事实上不会有太大的问题。
3. 这个补丁会稍微增加内核代码及数据尺寸:在NR_CPUS=4的系统中,从经典RCU的1,757字节内核代码、456字节数据,共2213字节的内核尺寸,而分级RCU则增加到4,006字节的内核代码、624字节的内核数据,共计4,630字节尺寸。即使对大多数嵌入式系统来说,这也不是一个问题。这些系统通常有上百兆主内存。但是对特别小的系统来说,这可能就是一个问题了,需要提供两种类型的RCU实现以满足这样的嵌入式系统。不过有一个有趣的问题,在这样的系统中,也许仅仅包含一个CPU,这样的系统完全可以用一个特别简单的RCU实现。
即使有这些问题,相对于经典RCU来说,在数百个CPU的系统中,这个分级RCU实现仍然是一个巨大的进步。最后需要说明一下,经典RCU设计用于16-32个CPU的系统。
在某些地方,在可抢占RCU实现中使用分级是有必要的。
后续章节将继续分析分级RCU的代码,以及Linux中其他一些RCU的实现。也许还会讨论实现RCU这类复杂并行软件的开发方法及其形式化验证。
近期精彩文章:
EMC潘国林: 大话存储系列之磁盘娶亲(RAID)
ARM刘永康: 浅谈Android数字版权管理之视频保护
宋宝华:是谁关闭了Linux抢占,而抢占又关闭了谁?
...
