


在编程中,我们有时会使用到静态库和动态库,而静态库是链接到程序之中的,基本上静态库的优化与进程类似。但动态库是加载在内存空间中的,是在运行时链接的。它的优化方式比较不同,本文我们就简单地讲述一下动态库如何优化
对于 动态库 而言,它仅包括 2 个段:
只读的代码段
可修改的数据段。
堆段 和 栈段 只有进程中才有。所以,如果你在动态库的函数里分配了一块内存,这段内存将被算在调用该函数的进程的 堆段 中。
系统在处理 动态库 的 代码段、数据段 时和 程序 的 代码段、数据段 一样:
代码段 由于其内容是对每个进程都是一样的,它在系统中是唯一的,系统只为其分配一块内存,多个进程之间共享。
数据段 由于其内容对每个进程是不一样的,所以在链接到进程空间后,系统会为每个进程创建相应的数据段。
在 进程中 的 BSS 会被开辟在 堆段 中。但在 动态库 中则是另外开辟一段 内存段 来存放这些数据,我们看下面的代码:
/* test.c */#include#includeint bss[1024*128]={0};void funca(){printf("bss:%p\n",bss);return;}/* main.c */#include#include#include#include#include#include#includeint funca();int main(){int pid=getpid();printf("pid:%d\n",pid);funca();pause();return 0;}
动态库编译:arm-linux-gnueabihf-gcc -shared -fPIC test.c -o libtest.so
主程序编译:arm-linux-gnueabihf-gcc -L./ -ltest main.c -o main
编译完成后记得把 动态库和主程序 一起拷贝到嵌入式设备上,其中具体的动态库查找路径相信各位读者都有些许了解,我们运行后得到下面的结果:
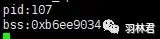
运行结果

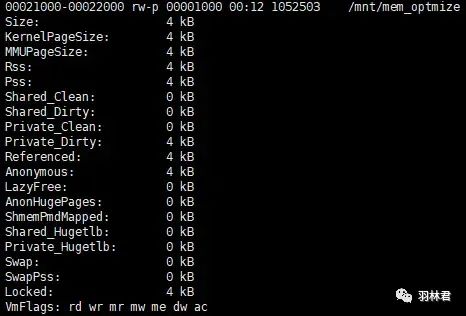
smaps.png
可以看到,我们的进程中有专门的内存段来存放 动态库 的数据,可以看到其中有 2 个段各自占据了 1 个物理页
再看看如果在进程中引用动态库中的数据的情况,代码如下:
/* test.c */#include#includeint bss[1024*128]={0};void funca(){printf("bss:%p\n",bss);return;}/* main.c */#include#include#include#include#include#include#includeextern int bss[1024*128];int funca();int main(){int pid=getpid();printf("pid:%d\n",pid);funca();pause();return 0;}

运行结果
smps
我们发现 地址不在动态库的段中,而是在程序的堆栈里面。这样来看,即使我们没使用该数据,但还是会占用我们的物理页。所以我们尽量少引用动态库中的全局变量。一旦引用,不论其是否使用,都将会占用物理内存。同时还会增加系统启动时,内存复制的代价,会导致性能的下降。
上一小节说了,如果全局变量声明在共享库中,在进程中使用,则该变量被复制到进程的数据段, 同时修改使用该变量的指向。那么接下来看看 动态库 的 数据段 会对 进程 的 数据段 产生什么影响?
我们通过 3 个实例来验证这个问题,每个实例都分别给出:代码、运行结果、文件大小、堆段信息、动态库数据段信息
声明在bss段,但在进程中使用
/* test.c */#include#includeint bss[1024*8]={0};void funca(){printf("dynamic bss = %p\n",bss);return ;}/* main.c */#include#include#include#include#include#include#includeextern int bss[1024*8]; //32KBint* funca();int main(){int pid=getpid();int i = 0;funca();for(i = 0; i < 1024*8; i++)bss[i] = 99;printf("program bss[0] = %d\n",bss[0]);printf("pid:%d bss:%p\n",pid,bss);pause();return 0;}
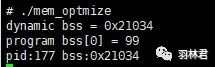
运行结果

文件大小

堆段信息
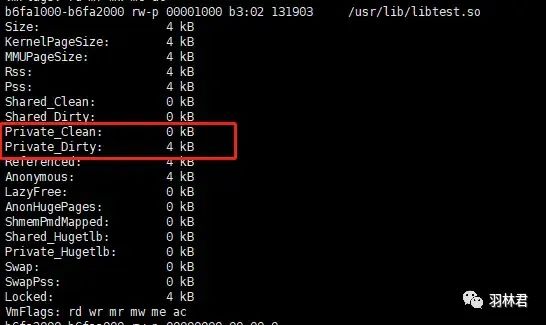
动态库数据段信息
我们可以看到,在 动态库的数据段 中并没有占用内存,仅仅是在 进程 的 堆段 中占用内存。
声明在bss段,但在进程中不使用
/* test.c */#include#includeint bss[1024*8]={0};void funca(){printf("dynamic bss = %p\n",bss);return ;}/* main.c */#include#include#include#include#include#include#includeextern int bss[1024*8]; //32KBint* funca();int main(){int pid=getpid();int i = 0;funca();printf("pid:%d bss:%p\n",pid,bss);pause();return 0;}

运行结果

文件大小
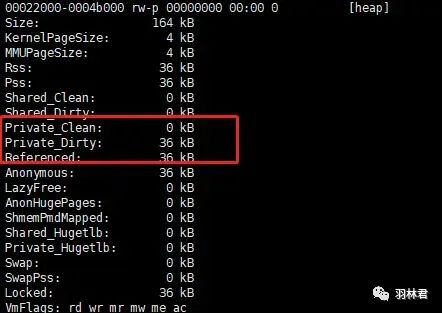
堆段信息

动态库数据段信息
该实例在主程序中引用了 动态库的数据,但没有修改数据的内容。可以看到其结论与第一个实例相同,也就是说明 在动态库中的数据一旦被主程序引用,那么主程序就会在堆段开辟内存并将动态库中的内容拷贝到堆段内存中
声明在data段
/* test.c */#include#includeint bss[1024*8]={1};void funca(){printf("dynamic bss = %p\n",bss);return ;}/* main.c */#include#include#include#include#include#include#includeextern int bss[1024*8]; //32KBint* funca();int main(){int pid=getpid();int i = 0;funca();printf("program bss[0] = %d\n",bss[0]);printf("pid:%d bss:%p\n",pid,bss);pause();return 0;}
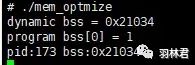
运行结果

文件大小
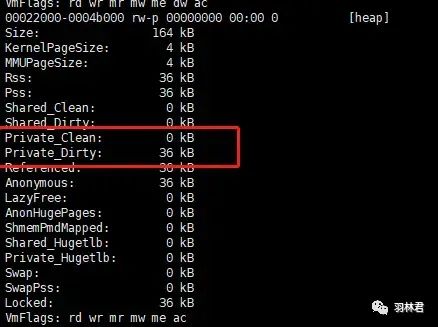
堆段信息
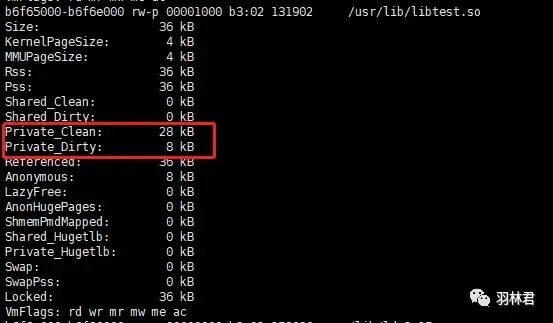
动态库数据段信息
该实例就有点不同了,动态库数据被初始化了。我们可以看到 动态库 的文件大小比前 2 个实例的都要 大,而且 动态库数据段 也占了内存,且内存大小与 动态库数据一样大。这说明了 动态库数据段如果不是定义在BSS段,则会在动态库中也占用物理内存,同时程序也会引用动态库的数据,导致一份数据使用了 2 次
1. 动态库的代码段是如何在装载时需要链接到程序之中的呢?
答案是这个过程是通过 .rel.dyn(.relocation.dynamic) 和 .rel.plt((.relocation.prosedure linkage talbe)) 这 2 个 节区 来完成的。
下面是代码:
/* main.c */#include#include#include#includevoid a();extern int b;int main(){a();pid_t pid=getpid();printf("pid:%d b=%d %p\n",pid,b,&b);pause();return 0;}/* test.c */#include#includeint b=10;int c=1;void a(){printf("function a b:%p c:%p\n",&b,&c);b++;return;}
将它们编译之后使用 readelf -r main 来读取 主程序 的重定位信息:
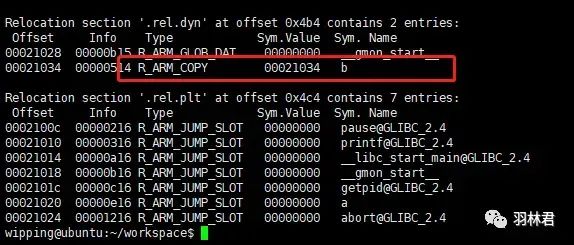
main重定位信息
我们可以看到 变量b 在 .rel.dyn节区,而 外部引用函数 比如printf 和 函数a 则是在 .rel.plt节区 。
在看看 动态库 的重定位信息:
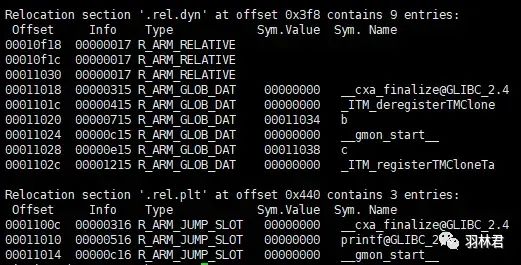
在 动态库 的 .rel.dyn 和 .rel.plt 也有对应的符号信息,这样 程序 和 动态库 之间可以通过这些信息完成内存的分配和数据的装载。这里不展开讨论该过程,有兴趣的读者请查阅其他资料了解
2. 程序运行结果分析
下面是程序的运行结果及相关信息:

程序运行结果

maps信息
我们发现 变量b 是在 进程 的 数据段 中。而 变量c 则是在 动态库 的 数据段 中。
在前面 主程序 的 重定位信息中,我们发现 变量b 有 R_ARM_COPY 属性。
引用原文就是说:
符号表索引规定符号应该既存在于当前目标文件中,也存在于某个共享目标中。在执行过程中,动态链接器把与共享目标的符号相关的数据复制到由偏移给出的位置。其意思就是说在加载 动态库 后,主程序 会将具有该 属性 的变量拷贝到自己的 数据段,并 修改动态库中该数据的指向。
所以原文有以下结论:
如果全局变量声明在共享库中,在进程中使用,则该变量被复制到进程的数据段,同时修改使用该变量的共享库的指向
如果该变量在共享库中声明,在共享库中使用,则该变量位于声明它的共享库的数据段中。
在 动态库 中定义函数,默认是会导出该函数的符号,导出符号需要一些代价,下面表格列出了导出符号是所增加的影响:
| 节区类型 | 代价(单位字节) |
|---|---|
| hash | 4 |
| .dynsym | 16 |
| dynstr | 函数名长度+1 |
| gnu.version | 2 |
| text | 仅针对函数来说,按函数代码长度增长 |
| data | 仅针对变量来说,按数据长读增长 |
为了避免导出多余的符号,我们可以通过 --version-script 选项来指 脚本,通过编写脚本来定义导出的符号。
PS:有关链接脚本的编写及使用,因为篇幅原因这里不展开讲述,请感兴趣的读者自行查阅
动态库 的 代码段 是共享的,所以不会随着 依赖进程 的增加而增加。但 动态库数据段 是随着 依赖进程 的增加而线性增长,所以我们把重点放在 数据段 的优化上。
loader 在加载动态库时需要做很多事情,
代码段:做重定位工作,至少占用一个物理页面;
数据段:首先要做重定位的工作。映射数据段时要在后一个页面将未填充完的剩余字节填充为 0,其少要占用一个物理页面。
综上所述,链接一个无用的共享库至少损失了 8k 的物理内存。对于每个不管是直接依赖还是间接依赖该动态库的进程,都将损失 8K 的物理内存。
如何检测无用的动态库?
使用 readelf 读取 动态库 的 dynamic节,获取其所直接依赖的动态库。(如果使用 ldd,结果会包含 间接依赖 的动态库,对我们的结果 有害无异) 。
读取 动态库 中所有 weak 和 undefine 的符号。
读取该 动态库 直接依赖的其他动态库 所有已经定义的符号。
将上面的结果 2 种符号取个交集,剔除一些系统的符号,如果交集不为空,我们就认为两个库有 实际的依赖关系,否则就是链接了无用的动态库。
假设 动态库A 的数据段为 1K,动态库B 的数据段也是 1K。进程加载这两个动态库就需要 2 个页面 8K 内存。如果将这两个动态库合并到一起,那么合并后动态库的数据段所占内存为 2K,进程加载后置需要 1个页面4K内存。这样节省出一个 物理页面。
对于 C语言 来说,合并后进程可能会因此引入很多无用的内容,但在加载动态库时只为 数据段 分配了一块虚存,没有用到的全局变量并不会占用更多的内存。因此,对于 C语言 写的动态库来讲,动态库的合并会通过 合并数据段 来节省内存。
原文的总结如下:
对于 C语言 编写的动态库,合并可以达到优化 数据段 的目的。
对于 C++语言 编写的动态库,可以考虑将一些不常用的功能分拆,使用 dlopen 的方式加 载,来节省内存。防止由于动态库之间的合并,导致进程加载很多无关的内容。
对于 经常一同出现的动态库,可以合并。
假设 动态库A 只被 动态库B 或 进程B 所依赖,那么说明 动态库A 和 动态库(或进程)B 是 同时出现的,那么可以将 动态库A 做成一个静态库,然后将其与 动态库(或进程)B 进行合并,从内存的角度来讲这是有益无害的。
如何查找仅使用一次的动态库?
使用 readelf 读取动态库的 dynamic节,找到其所有直接依赖的动态库。
为每一个 动态库 建立一个 依赖于它的动态库和进程表。
如果 表长度 为 1 的动态库,即是是仅被依赖一次的动态库。
在启动程序后,会发现进程加载了很多的库。但有些动态库是很少用到的,甚至可能只用 1 次。而进程在启动后就全部加载进来,每个库至少 8k(4k 代码段,4K 数据段)内存。这样会浪费内存,而且动态的数据段一旦 加载跟使用 后将伴随整个进程的声明周期。
linux 提供了 dlopen机制 来解决动态库的动态加载问题,其流程为:
进程会加载该共享库的 代码段 和 数据段,同时为这个 共享库计数加 1。
进程查找该共享库的 dynamic节,查看其所依赖的共享库。
检查 所依赖库 是否已经被加载。如果已被加载,则为这个 共享库计数 加 1。如果未被加载,则加载其 代码段 和 数据段,然后为这个 共享库计数 加 1。
接着递归查找 依赖库 所依赖的库并执行前面的操作,最终进程会为每个加载的共享库维护一个依赖的计数。
同时,linux 也提供了 dclose 来卸载动态库,其流程为:
首先将该 共享库的计数 减 *18,如果该 共享库依赖计数 为 0,则 卸载 该共享库。
在 dynamic节 中,查找其 所依赖的共享库。
为每个 依赖的共享库 的计数减 1,如果该共享库依赖计数为 0,则卸载该共享库。
重复上面的步骤。
PS:dlopen的使用方法请各位读者自行查阅。
dlopen 的优点如下在于:
可以在程序启动的时候,减少加载库的数量 以加快进程的 启动速度 和 减少加载库的内存。
为进程提供了卸载共享库的机会,以此动态回收共享库 代码段和数据段所占用的内存。
但 dlopen 本身也有 动态库嵌套 的问题,下面举个例子来说明。
假设有 进程P、共享库 liba.so、libb.so、libc.so 和 libd.so
它们的依赖关系为:
liba.so 依赖 libb.so
libc.so: 依赖 libd.so
流程如下:
进程P 通过 dlopen 加载 liba.so。此时 liba.so 和 libb.so 都会被加载到进程中。
进程P 调用 liba.so 的库函数,该库函数会调用 dlopen 加载 libc.so。此时会将 libc.so 和
libd.so 加载到进程中。
进程P 调用 dlclose 来关闭 liba.so。但dlclose 查找其所依赖的库时只能查到 libb.so,所以它将关闭 libb.so 以及 liba.so。
进程P 关闭了 liba.so,如果 liba.so 没有关闭 libc.so* 和 libd.so 的函数,那么 libc.so* 和 libd.so 将会一直存在内存中,导致共享库没有完全卸载。
所以我们需要一个时机,在我们 dlclose 动态库时,将该动态库调用 dlopen 打开的动态库关闭。其实有点类似于 C++ 的构造函数和析构函数。如果我们可以为动态库实现一个 析构函数,在卸载动态库时会去自动卸载其所依赖的库,那么就可以解决这个嵌套问题。
linux 的动态库为我们提供了这样的功能:
动态库在加载时会执行 void attribute ((constructor)) open_func(void),其中 open_func 为函数名,可自行定义。
动态库在卸载时会执行 void attribute ((destructor)) close_func(void),其中 close_func 为函数名,可自行定义。
PS:在编译时不能使用 "-nonstartfiles" 或 "-nostdlib" 选项,否则,构建与析构函数有可能不能正常执行
下面提供一段比较简单例程
/* libfunc.c */int _add(int a,int b){return (a + b);}int _sub(int a, int b){return (a - b);}int _mul(int a, int b){return (a * b);}int _div(int a, int b){return (a / b);}/* libtest.c */#include#include#define SO_LIB_PATH "/usr/lib/libfunc.so"typedef int (*func)(int, int);static void* so_handle = NULL;static func add_func = NULL;static func sub_func = NULL;static func mul_func = NULL;static func div_func = NULL;void __attribute__ ((constructor)) open_func(void){printf("[%s](%d)constructor share object now\n", __func__, __LINE__);so_handle = dlopen(SO_LIB_PATH, RTLD_NOW);if(NULL == so_handle){printf("[%s](%d)error: %s\n", __func__, __LINE__, dlerror());}else{add_func = dlsym(so_handle, "_add");if(add_func == NULL){printf("[%s](%d)open add error:%s\n", __func__, __LINE__, dlerror());}sub_func = dlsym(so_handle, "_sub");if(sub_func == NULL){printf("[%s](%d)open sub error:%s\n", __func__, __LINE__, dlerror());}mul_func = dlsym(so_handle, "_mul");if(mul_func == NULL){printf("[%s](%d)open mul error:%s\n", __func__, __LINE__, dlerror());}div_func = dlsym(so_handle, "_div");if(div_func == NULL){printf("[%s](%d)open div error:%s\n", __func__, __LINE__, dlerror());}}}void __attribute__ ((destructor)) close_func(void){printf("[%s](%d)destructor share object now\n", __func__, __LINE__);dlclose(so_handle);}int add(int a,int b){return add_func(a, b);}int sub(int a, int b){return sub_func(a, b);}int mul(int a, int b){return mul_func(a, b);}int div(int a, int b){return div_func(a, b);}/* main.c */#include#include#include#includeint add(int a,int b);int main(){printf("[%s](%d)result = %d\n", __func__, __LINE__, add(1, 4));return 0;}
使用下面的语句进行编译:
arm-linux-gnueabihf-gcc -L./ -ltest main.c -o mainarm-linux-gnueabihf-gcc -shared -fPIC -ldl libfunc.c -o libfunc.soarm-linux-gnueabihf-gcc -shared -fPIC -ldl libtest.c -o libtest.so
将动态库拷贝到设备的 /usr/lib 目录下再运行主程序,就可以看到下面的运行结果:

运行结果
可能在编写程序时会遇到 内存泄露 或者 大量使用内存 的情况。我们也有一些手段来解决这个问题,比如使用 mtrace。mtrace 的使用方法在前面的文章有说过,但这种方法有 2 个缺点:
程序需要把 log 写到 flash 文件中,读写 flash 是比较慢的
mtrace 中试图根据调用 malloc 的代码指针,解析出对应的函数,这会导致进程的速度变 得很慢
以上的缺点导致 mtrace 无法调试大型项目的内存问题,所以我们需要另外找方法来调试。幸好 libc 提供了 malloc和free 的钩子函数,这样我们就可以自己来实现对内存的调试
在 glibc 中,提供了 malloc、free、realloc、memalign 的 钩子函数 。你可以按照 钩子函数 的原型定义自己的函数,并在 glibc 中设置相应的钩子函数,这样 glibc 在处理函数时,会调用你的钩子函数,从而获得相应的信息。
利用这个机制,我们可以从 钩子函数中 获取一些信息以帮助我们进行内存调试。先看看 钩子函数 的原型:
extern void (*__MALLOC_HOOK_VOLATILE __free_hook) (void *__ptr, const void*caller)
extern void *(*__MALLOC_HOOK_VOLATILE __malloc_hook)(size_t __size, const void *caller)
可以看到 钩子函数 会获取 调用者caller 的 函数指针,根据这个特性就这个进行内存调试跟分析了。
下面我们直接看一段代码:
#include#include#include#includestatic void* (* old_malloc_hook) (size_t,const void *);static void (* old_free_hook)(void *,const void *);static void my_init_hook(void);static void* my_malloc_hook(size_t,const void*);static void my_free_hook(void*,const void *);static void my_init_hook(void){old_malloc_hook = __malloc_hook;old_free_hook = __free_hook;__malloc_hook = my_malloc_hook;__free_hook = my_free_hook;}static void* my_malloc_hook(size_t size, const void *caller){void *result;__malloc_hook = old_malloc_hook;result = malloc(size);old_malloc_hook = __malloc_hook;printf("%p + %p %#x\n", caller, result, (unsigned long int)size);__malloc_hook = my_malloc_hook;return result;}static void my_free_hook(void *ptr, const void *caller){__free_hook = old_free_hook;free(ptr);old_free_hook = __free_hook;printf("%p - %p\n", caller, ptr);__free_hook = my_free_hook;}char *p[10];int func1(){int i = 0;for(i = 0; i < 10; i++){p[i] = (char *)malloc(i);}return 0;}int func2(){int i = 0;for(i = 0; i < 9; i++){free(p[i]);}return 0;}int main(){my_init_hook();func1();func2();return 0;}
上面的代码在编译时可能会出现大量的 警告,可以使用编译选项 -Wno-deprecated-declarations 来屏蔽这些警告。
代码先在 func1 中连续开辟 10 块内存,在 func2 中释放 9 块内存,遗漏了一块。我们打印的 log 分别罗列出了:调用者、+/-号(表示开辟/释放)、 开辟结果 以及 内存块大小。我们等下回根据这些信息来获取 内存泄露 的地方。
注意:钩子函数的返回值就是原函数的返回值,所以我们必须在钩子函数里面实现于原函数一样的功能,一般情况下我们可以直接在钩子函数里面调用原函数,但是在调用之前我们必须把钩子函数给还原回去,不然会陷入无条件终止的递归,最终程序崩溃
我们看看运行结果:
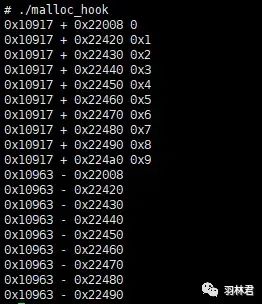
运行结果
上面的运行结果是在调用 mallo/free 少的情况下进行的。如果在多的情况下我们可以手动编写脚本来帮助我们进行分析。原书中使用的是 perl 脚本,但笔者使用的是 python 脚本。所以笔者在模糊看懂原文的脚本的基础上使用 python 重新编写。下面为笔者所写的脚本:
import osimport sysif __name__ == '__main__':file_name = sys.argv[1]bin_name = sys.argv[2]file = open(file_name)mem_dict = {}caller_dict = {}while True:line = file.readline()if not line:breakitems = line.split()index = items[2]if '+' is items[1]:size = int(items[3], 16)mem_dict[index] = sizecaller_dict[index] = int(items[0], 16)elif '-' is items[1]:mem_dict.pop(index)caller_dict.pop(index)for key in mem_dict.keys():print("caller=", hex(caller_dict[key]), "addr =", key, "size =", mem_dict[key])
使用上面的脚本时我们需要传入参数:打印的log,所以再运行 执行文件时 记得把 log 重定向到文件。下面是脚本运行结果:

运行结果
如图所示,使用脚本可以更加快速地帮助我们筛选出结果,这样我们就可以简单明了的看出是哪里开辟的内存没有释放掉。
脚本的原理是:每个 caller 都有对应的 +(开辟) 和 -(释放),如果有一个 caller 的 -号 没有被消掉,那么就根据这个 内存块 的 地址 找到相应的 caller。
我们除了获取 调用者指针 外,还可以再借助 nm工具 获取调用者的函数名,这样我们就可以更加清晰地知道是哪个函数开辟的内存没有被释放,我们再看看下面修改的脚本代码:
import osimport sysdef getsym(caller_addr, bin_name):bin_file = open(bin_name)bin_file.close()nm_return = os.popen("arm-linux-gnueabihf-nm -n " + bin_name)caller_name_dict = {}while True:nm_line = nm_return.readline()if nm_line:nm_items = nm_line.split()if 2 == len(nm_items):continueif caller_addr > int(nm_items[0], 16):result = abs(caller_addr - int(nm_items[0], 16))caller_name_dict[result] = nm_items[2]else:breaksort_result = sorted(caller_name_dict.items(), key = lambda item: item[0])symbol = sort_result[0][1]return symbolif __name__ == '__main__':file_name = sys.argv[1]bin_name = sys.argv[2]file = open(file_name)mem_dict = {}caller_dict = {}while True:line = file.readline()if not line:breakitems = line.split()index = items[2]if '+' is items[1]:size = int(items[3], 16)mem_dict[index] = sizecaller_dict[index] = int(items[0], 16)elif '-' is items[1]:mem_dict.pop(index)caller_dict.pop(index)for key in mem_dict.keys():print("caller=", hex(caller_dict[key]), "addr =", key, "size =", mem_dict[key])caller_name = getsym(caller_dict[key], bin_name)print("leak caller =", caller_name)
使用上面的脚本时我们需要传入 2 个参数:
打印log
执行文件路径
脚本的原理在上一小节的基础上加入下面的条件:
小于 caller 并且距离 caller 最近的函数地址就是函数,我们可以通过 nm工具 获取每个函数所处的位置,找到满足上述条件的函数就是目标函数了。
我们看一下运行结果:

运行结果
确定调用的函数后,我们再更加一步可以获取到代码的 行数。这一步骤要求 我们需要在编译的时候使用 -g 选项加入调试信息
从上一小节我们知道调用的 caller地址 是 0x10917。那么我们可以使用 addr2line 的工具来获取到具体函数,如下图所示:

从图中可知,在代码的 145行 开辟的内存没有进行释放。
在 实际环境 中,并没有如此简单的 函数调用层次。我们可能是在调用了 4、5 次才最终开辟内存空间的,那么我们就需要获取逐层的 调用者 以方便我们定位内存。
要知道多个 调用者 的信息,我们就需要使用 backtrace 函数。该函数可以打出多个 函数调用处的纸质恩,其原理是 函数栈帧,有兴趣的同学可以自行了解一下。
下面我们看一段代码:
#include#include#include#include#includestatic void* (* old_malloc_hook) (size_t,const void *);static void (* old_free_hook)(void *,const void *);static void my_init_hook(void);static void* my_malloc_hook(size_t,const void*);static void my_free_hook(void*,const void *);static void my_init_hook(void){old_malloc_hook = __malloc_hook;old_free_hook = __free_hook;__malloc_hook = my_malloc_hook;__free_hook = my_free_hook;}static void* my_malloc_hook(size_t size, const void *caller){void *result;__malloc_hook = old_malloc_hook;result = malloc(size);void *array[10];size_t size1;size1 = backtrace(array, 10);switch(size1){case 1:printf("%p + %p %#x %p\n",caller,result,(unsigned int)size,array[0]);break;case 2:printf("%p + %p %#x %p %p\n",caller,result,(unsigned int)size,array[0], array[1]);break;case 3:printf("%p + %p %#x %p %p %p\n",caller,result,(unsigned int)size,array[0],array[1],array[2]);break;case 4:printf("%p + %p %#x %p %p %p %p\n",caller,result,(unsigned int)size,array[0],array[1],array[2],array[3]);break;case 5:printf("%p + %p %#x %p %p %p %p %p\n",caller,result,(unsigned int)size,array[0],array[1],array[2],array[3],array[4]);break;}__malloc_hook = my_malloc_hook;return result;}static void my_free_hook(void *ptr, const void *caller){__free_hook = old_free_hook;free(ptr);old_free_hook = __free_hook;printf("%p - %p\n", caller, ptr);__free_hook = my_free_hook;}char *p[10];int func1(){int i = 0;for(i = 0; i < 10; i++){p[i] = (char *)malloc(i);}return 0;}int func2(){int i = 0;for(i = 0; i < 10; i++){free(p[i]);}return 0;}void func3(){func1();}int main(){my_init_hook();func1();func2();func3();return 0;}
注意:使用 backtrace 函数要注意下面 2 点:
按照笔者理解,backtrace函数也会调用 malloc,所以在调用 backtrace之前我们需要将malloc的钩子函数还原回原来的
如果是在 ARM 架构下运行程序,需要在编译时使用-rdynamic -funwind-tables -ffunction-sections 选项,不然无法使用backtrace
编译时不能使用 -O 优化选项
上面的代码中 func1 开辟的内存块会在 func2 中被释放掉,但在最后 func3 会调用 func1 在开辟多 10 块内存
根据上面的代码,我们在打印是就可以获取到多个 调用者 的信息了,我们看一下运行结果:

运行结果
我们可以看到最后的 caller地址 比较不一样,我们可以使用 maps 来查看这个指针所在的段,这里笔者就不赘述了。
我们继续修改一下脚本,使用 python 来帮助我们获取 调用者 的 函数名,如下所示:
import osimport sysdef getsym(caller_addr, bin_name):bin_file = open(bin_name)bin_file.close()nm_return = os.popen("arm-linux-gnueabihf-nm -n " + bin_name)caller_name_dict = {}while True:nm_line = nm_return.readline()if nm_line:nm_items = nm_line.split()if 2 == len(nm_items):continueif caller_addr > int(nm_items[0], 16):result = abs(caller_addr - int(nm_items[0], 16))caller_name_dict[result] = nm_items[2]else:breaksort_result = sorted(caller_name_dict.items(), key = lambda item: item[0])# print(sort_result[0])symbol = sort_result[0][1]return symbolif __name__ == '__main__':file_name = sys.argv[1]bin_name = sys.argv[2]file = open(file_name)mem_dict = {}caller_dict = {}while True:line = file.readline()if not line:breakitems = line.split()index = items[2]if '+' is items[1]:size = int(items[3], 16)mem_dict[index] = lineelif '-' is items[1]:mem_dict.pop(index)for key in mem_dict.keys():leak_line = mem_dict[key]caller = getsym(int(leak_line.split()[0], 16), bin_name)print("caller=", caller, "addr =", key, "size =", mem_dict[key].split()[3])for key in mem_dict.keys():leak_line = mem_dict[key]items_list = leak_line.split()print("==========================split line==========================")for i in range(4, len(items_list)):leak_func = getsym(int(items_list[i], 16), bin_name)print("func =", leak_func, "addr =", items_list[i])
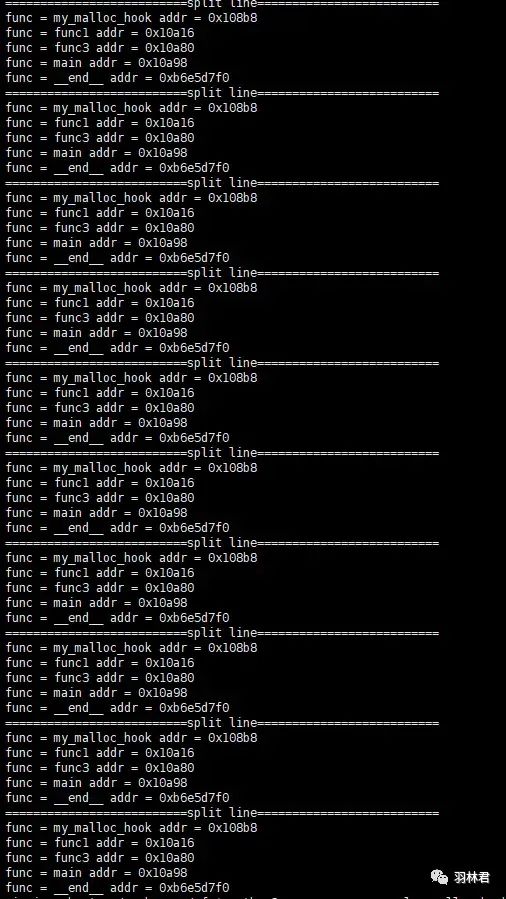
运行结果
运行结果中 caller地址 为 0xb6e627f0 的,其 调用函数名 是错的。因为该 调用地址 与 my_malloc_hook 并不在同一个 代码段。同理,我们可以使用 maps 来确定该地址所在的 代码段
如果 caller 是在动态库中,我们需要结合其他工具来查看。
先看下面一段代码:
/* libtest.c */#include#includechar *p[10];int func1(){int i = 0;for(i = 0; i < 10; i++){p[i] = (char *)malloc(i);}return 0;}int func2(){int i = 0;for(i = 0; i < 10; i++){free(p[i]);}return 0;}void func3(){func1();}/* main.c */#include#include#include#include#includestatic void* (* old_malloc_hook) (size_t,const void *);static void (* old_free_hook)(void *,const void *);static void my_init_hook(void);static void* my_malloc_hook(size_t,const void*);static void my_free_hook(void*,const void *);int func1();int func2();static void my_init_hook(void){old_malloc_hook = __malloc_hook;old_free_hook = __free_hook;__malloc_hook = my_malloc_hook;__free_hook = my_free_hook;}static void* my_malloc_hook(size_t size, const void *caller){void *result;__malloc_hook = old_malloc_hook;result = malloc(size);void *array[10];size_t size1;size1 = backtrace(array, 10);switch(size1){case 1:printf("%p + %p %#x %p\n",caller,result,(unsigned int)size,array[0]);break;case 2:printf("%p + %p %#x %p %p\n",caller,result,(unsigned int)size,array[0], array[1]);break;case 3:printf("%p + %p %#x %p %p %p\n",caller,result,(unsigned int)size,array[0],array[1],array[2]);break;case 4:printf("%p + %p %#x %p %p %p %p\n",caller,result,(unsigned int)size,array[0],array[1],array[2],array[3]);break;case 5:printf("%p + %p %#x %p %p %p %p %p\n",caller,result,(unsigned int)size,array[0],array[1],array[2],array[3],array[4]);break;}__malloc_hook = my_malloc_hook;return result;}static void my_free_hook(void *ptr, const void *caller){__free_hook = old_free_hook;free(ptr);old_free_hook = __free_hook;printf("%p - %p\n", caller, ptr);__free_hook = my_free_hook;}int main(){my_init_hook();func1();func2();printf("pid = %d\n", getpid());pause();return 0;}
注意:这里为了使用 backtrace,在编译动态库和主程序的时候都需要加入前面所讲编译选项,不然backtrace会出现无效的现象
我们看一下运行结果:

运行结果
我们再使用 nm工具 查看 动态库:如下所示:
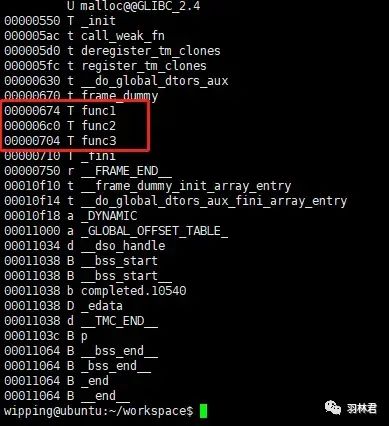
nm结果
我们发现其中的 caller(0xb6fc5690) 与调用函数的地址相去甚远。这主要是 因为进程在加载动态库时,其基地址是随机 的,所以导致具体函数地址的变化。
我们再根据 进程ID 查看 maps属性,如下所示:
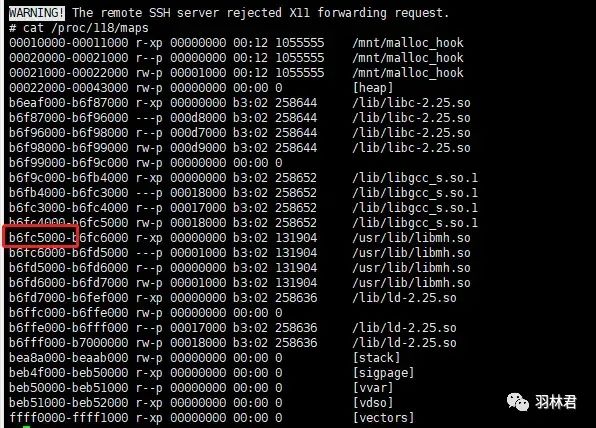
maps属性
可以看到 动态库 的 起始地址 是 b6fc5000,我们将我们的 caller(0xb6fc5690) 减去该值就是 0x690,再对比 nm工具 的结果就发现是 func1函数
通过 malloc和free的钩子函数,我们可以清晰的找到每一块内存是在哪里开辟和释放,我们通过这些信息来过滤掉那些 在开辟后会被释放掉的内存块,余留下来的则是一些 未经释放, 一直存在的内存块。但是由于程序或者业务的原因,我们有时需要让一些内存块常驻于内存,这也将加大我们的分析难度。同理我们还是可以通过获取 log,通过调用信息来找到常驻内存块,以此解决问题。
前面我们使用了 backtrace 来回溯各个调用函数,那么这里面的原理就是 栈帧回溯 了。
在讲述 栈帧结构 之前,我们需要先讲述一下 APCS(ARM Procedure Call Standard)。这是 ARM汇编 一种编译约定,可以简单地理解为它规定了 函数调用的过程使用什么寄存器存放什么变量,比如 规定 r0 - r3 作为前四个参数的传入寄存器外。APCS 也规定了 栈帧 的结构。
再次之上我们在说一下 ARM体系 的几个功能性寄存器:
PC:程序指针,寄存器 r15
LR:链接寄存器,寄存器为 r14,在栈帧中存放返回值
SP:堆栈寄存器,寄存器为 r12
FP:堆栈寄存器,寄存器为 r11
栈帧的结构如下图所示:
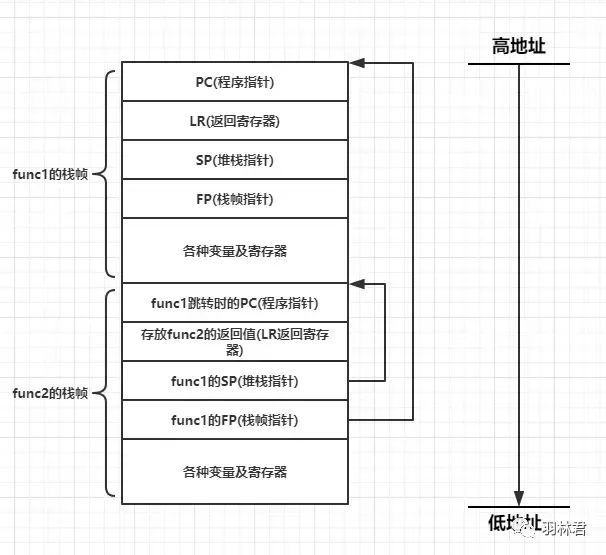
栈帧结构
以 SP 和 FP 所指的内存段即为一个栈帧。比如在图中,func2 的 栈帧 中有 SP 和 FP 分别存放了 func1 的 *栈帧起点 和 栈帧终点,这段内存就是 funct1的栈帧
我们知道 栈是向下增长的。所以从图可知,当 func1 函数调用 func2 时。func2 会先将 PC、LR、SP、FP 四个寄存器先压入栈。
其中 SP 和 FP 的值分别指向 func1函数栈帧的两个边界。
LR 的值保存的是 func2 调用结束之后的返回值。
PC 的值表示的是当前 func1 执行到的指令地址。按照笔者的理解,即放置的是 返回func1后开始执行的指令地址。
通过这种 栈帧结构 ,我们可以很容易就追溯到每个函数的调用地址了,所以它提供了一种 追溯程序的方式,可以来反向跟踪调用的函数。
dlopen用法:https://www.cnblogs.com/qianqiannian/p/11762646.html
采用dlopen、dlsym、dlclose加载动态链接库:https://www.cnblogs.com/Anker/p/3746802.html
汇编中.word的具体用途:https://blog.csdn.net/weixin_42108004/article/details/84593201
ARM Linux BackTrace:https://www.veryarm.com/29007.html
ARM下C语言栈帧机制:https://www.jianshu.com/p/91c5dc0a8bb9
来源:https://www.jianshu.com/p/00f1ee273956
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
