

视频云大模型算法「方法论」。
刘国栋|演讲者
在AI技术发展如火如荼的当下,大模型的运用与实践在各行各业以千姿百态的形式展开。音视频技术在多场景、多行业的应用中,对于智能化和效果性能的体验优化有较为极致的要求。如何运用好人工智能提升算法能力,解决多场景业务中的具体问题,需要创新地探索大模型技术及其应用方式。本文由LiveVideoStackCon2023深圳站演讲《AI新范式下,阿里云视频云大模型算法实践》整理而成,演讲者为阿里云智能高级算法专家刘国栋,分享阿里云视频云的大模型算法实践。
《AI新范式下,阿里云视频云大模型算法实践》主题分享,包含如下四个部分:

首先我们看第一部分:音视频AI发展趋势与业务对AI算法的要求。
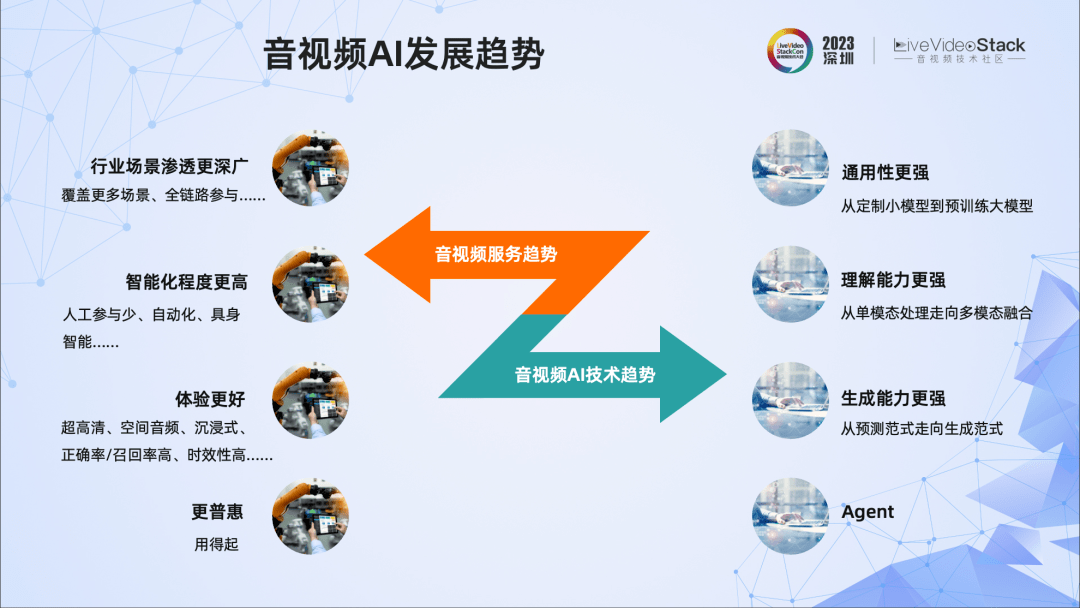
当下,音视频服务已广泛应用于互娱、广电传媒、教育、金融等各种行业,对场景的渗透也越来越深。这些行业、场景对智能化和体验的追求愈来愈高,同时用户希望用得起、更普惠。完成这样的目标,AI可以发挥重要作用,这已成为行业共识。
随着AIGC的发展,音视频领域的AI技术也呈现出了新的趋势,即对AI技术的通用性、理解能力、生成能力都提出了更高的要求。过去纯粹的定制小模型开发、单模态处理和预测范式有不少缺陷,触达到了能力上限,而目前音视频AI技术则走向了泛化能力非常强的预训练大模型、多模态信息融合、生成式等方向。还有值得提出的一点是AI Agent的能力,即要求AI有感知、决策、行动的能力,它目前已成为一个重要的研究方向。
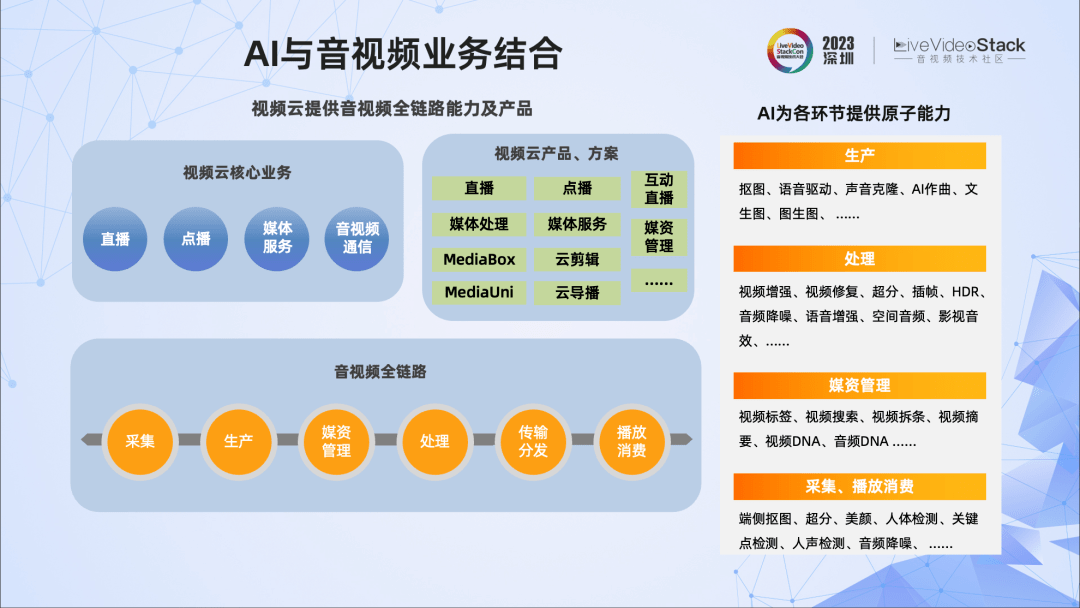
当前,阿里云视频云的核心业务包括直播、点播、媒体服务、音视频通信,形成了完整的产品、解决方案阵列。这些业务、产品覆盖音视频从采集、生产、处理、媒资管理、传输与分发、播放与消费的全链路。
目前AI为音视频全链路的各环节提供了算法原子能力。举例来讲,在处理环节,我们开发了多个AI算法,在视频方面包括视频增强、视频修复、超分、插帧,HDR等;在音频方面包括智能降噪、语音增强、空间音频、影视音效等。这些AI算法都集成到产品中,提升了产品的竞争力。
当然,AI除了提供算法原子能力之外,也渗透到视频云的引擎层、调度层、业务层,进一步提升它们的智能化水平。
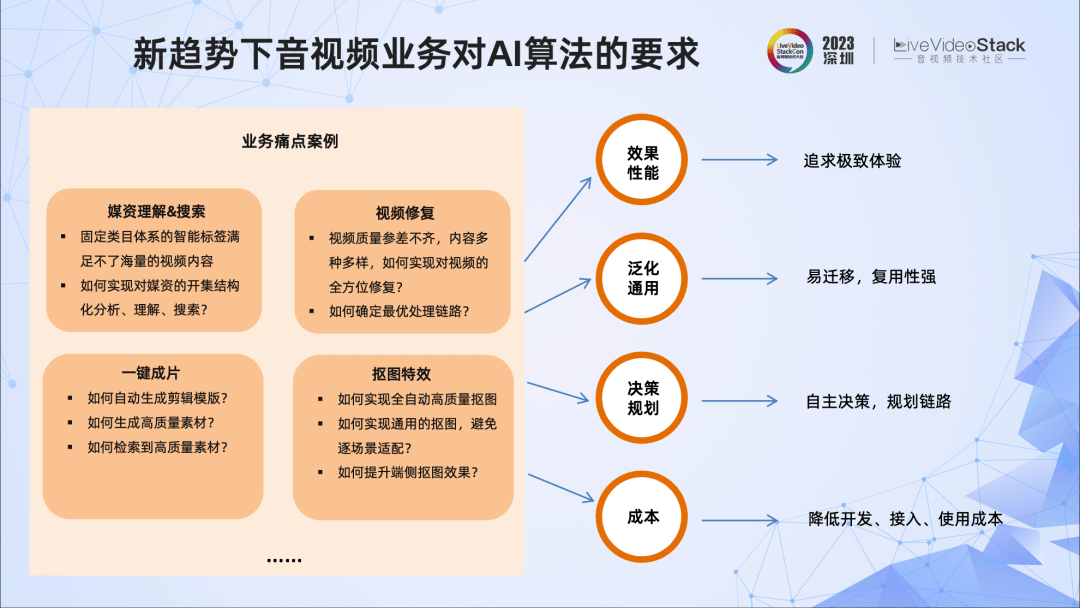
尽管AI已经大量融入业务,我们对业务做了深入分析后,还是发现了一些痛点问题。举例说明,云剪辑,很多时候还是需要指定剪辑模版,缺乏自动化,另外,获取高质量的素材也很难;在媒资管理中,视频检索的质量仍然存在不少提升空间。但同时,由于大模型、AIGC带来的巨大变革,我们认为解决这些业务痛点问题已成为可能。
我们总结出几点新趋势下视频云业务对AI算法的要求,包括追求效果性能上的极致体验,追求算法的泛化性、通用性,提升AI自主决策、规划处理链路的能力,以及降低开发、接入、使用的成本。
针对音视频业务对AI算法的更高要求,我们采用了大模型的技术,设计了一套基于视频云大模型算法开发的系统架构,并实践、提炼了一些关键技术,形成了一套较为通用的大模型算法落地业务场景的“方法论”。
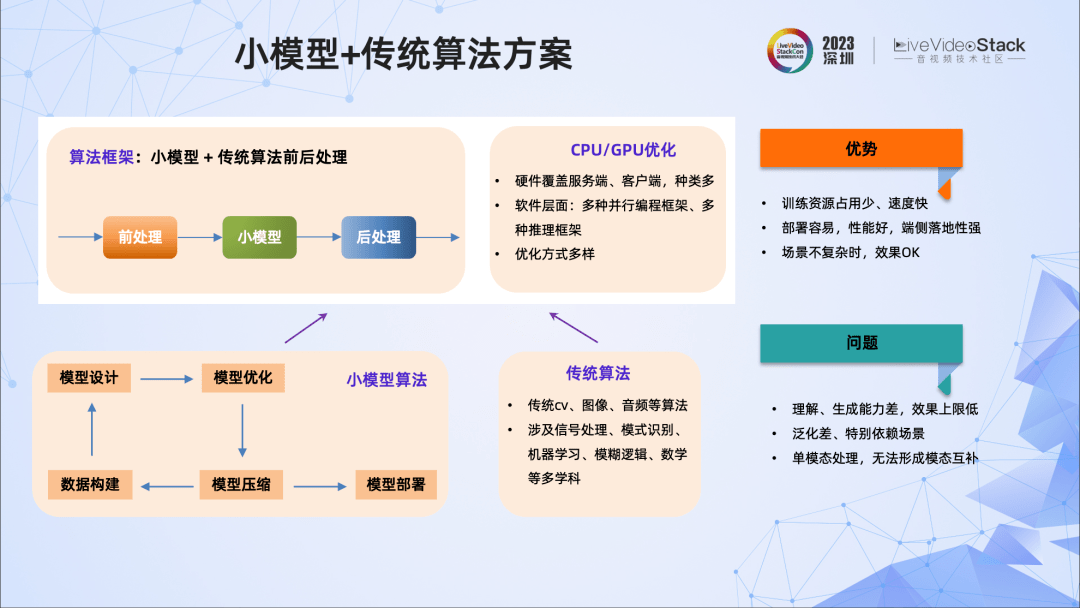
我们先看下大模型时代来临前,是如何设计算法的。
多数情况下,我们采用小模型、传统算法或者两者结合的方法。其优点是:小模型、传统算法在算法开发、工程优化方面已相对比较成熟,小模型的训练资源占用少且训练速度快,部署容易,端侧落地性强。但是问题也比较突出,比如模型的泛化能力差,效果上限比较低,理解、生成能力比较差等。
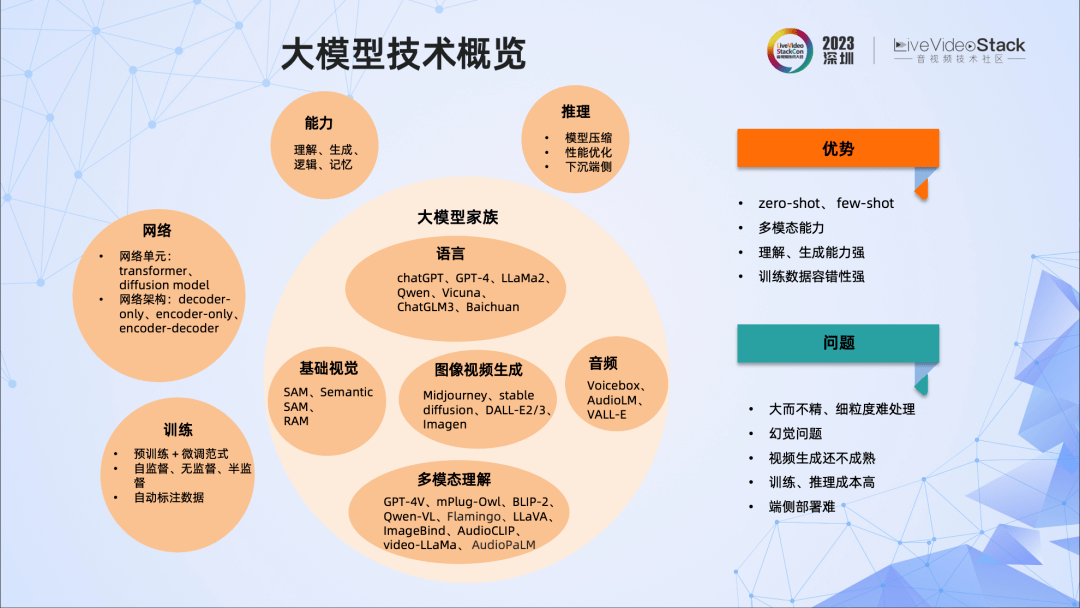
而大模型出现后,它的通用性、泛化性、多模态能力、强大的理解和生成能力等都让我们惊叹不已,这些正是小模型和传统算法所欠缺的。用大模型技术去解决之前的算法问题,甚至重做一遍,提高算法效果的上限,我们认为这是比较可行的做法。
不过我们也发现了大模型的一些通病,比如对细粒度的问题还不能完美处理、容易出现幻觉现象、推理训练成本都比较高等。如果要在实际业务中应用大模型,这些问题都应该要尽量避免甚至解决。
那我们是如何推进大模型算法演进的呢?
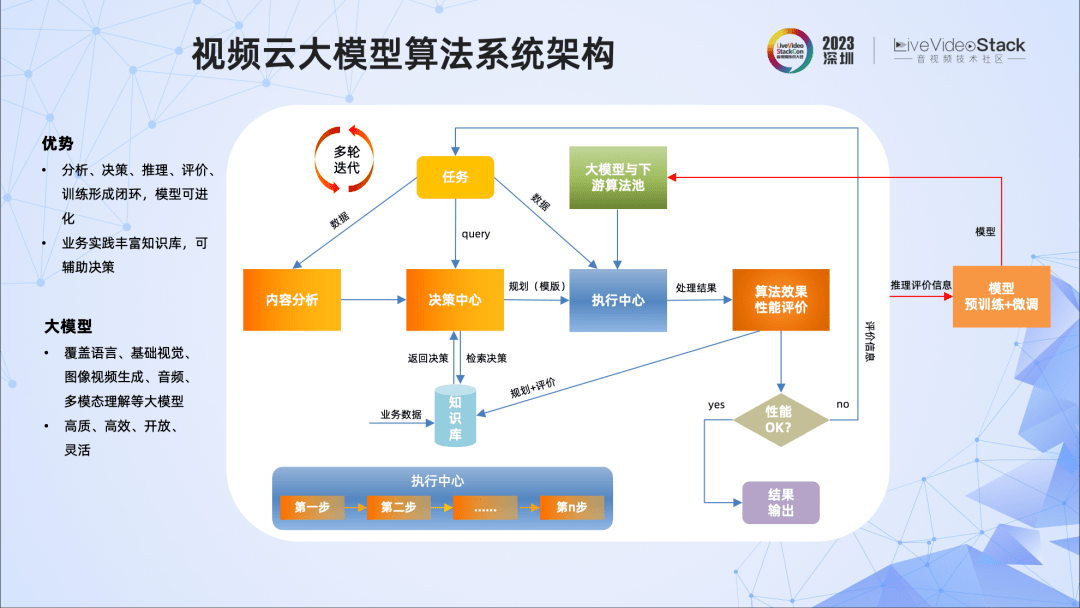
首先,我们根据视频云的业务特点,设计和搭建了一套基于视频云大模型算法开发的系统架构。整个系统涵盖了分析、规划、推理、评价、训练与微调的全链路,并且是可进化、可决策的。
可决策主要体现在,系统会根据客户需求和自身的分析,结合视频云知识库及LLM做出决策,制定合适的处理链路和选择模型去完成任务。
可进化主要体现在两个方向,一方面,系统会通过推理、评价、训练不断迭代,完善模型;另一方面,知识库也是不断更新的,比如说好的解决方法和评价信息以及业务反馈、沉淀的数据等都会送入知识库,确保知识的新鲜度、准确度。
基于大模型算法系统框架,我们不断地在业务中实践、演进,提炼出一套通用的大模型算法开发的“方法论”,使其能高质量地解决业务中的实际问题。
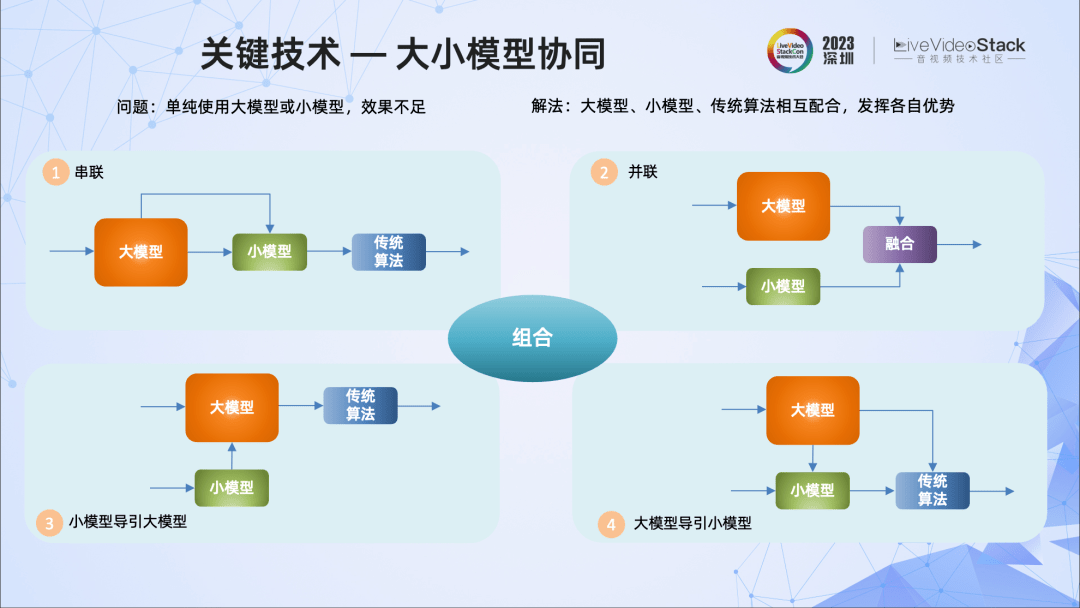
第一,大小模型协同技术。
针对前面指出的大模型、小模型或传统算法各自存在的问题,我们提出几种大小模型、传统算法协同的方法,包括三者的串联、并联,用小模型特征引导大模型或者大模型引导小模型,以及它们的组合。目前,我们在实践中已经采用了大小模型协同的方法,比如实景抠图、声音克隆等算法,已经取得了比较好的效果。

第二,大模型微调。
目前音视频领域的大模型往往针对通用场景,在实际业务中效果不太好,当然这并不是讲这些模型完全不可用。在一些情况下,我们针对自己的业务场景,筛选出相对高质量的大模型,再结合我们的数据、知识库进行大模型的微调。
整个过程会涉及到训练数据的制作、微调的具体方法、幻觉和灾难性遗忘的应对、以及训练策略和效果评价方法等一系列问题。
我们在实践中主要采用了参数高效的微调方法,对调整哪些网络结构层也做了大量实验。训练策略上采用模型解耦,多步训练的策略。比如在视频搜索中,我们就采用了类似的方案,使得模型准确度有了大幅提升。
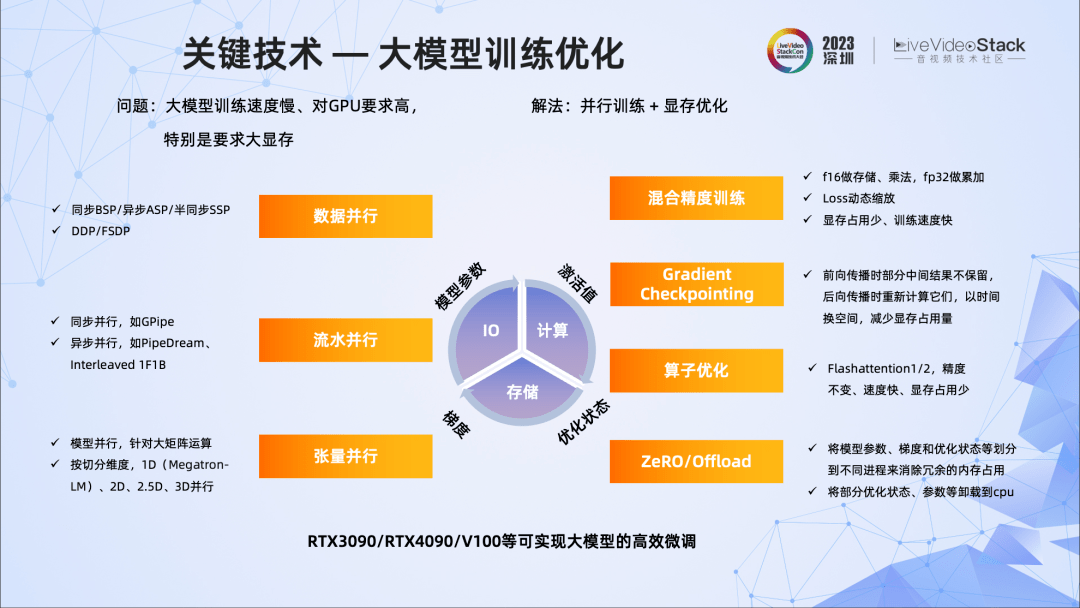
第三,大模型的训练优化。
大模型训练的计算量巨大,显存的占用也非常大,这导致训练周期很长,算法迭代速度很慢,影响算法的落地。
我们从IO、计算、存储等角度出发,实践了一些并行训练、显存优化的方法,包括多种并行,混合精度训练,梯度检测点等,以及采用Zero、Offload、Flashattention等工具。这些方法使得我们可以在一些性能不高的GPU上,如RTX3090/RTX4090/V100,完成多机多卡的训练,从而降低算法的开发周期。
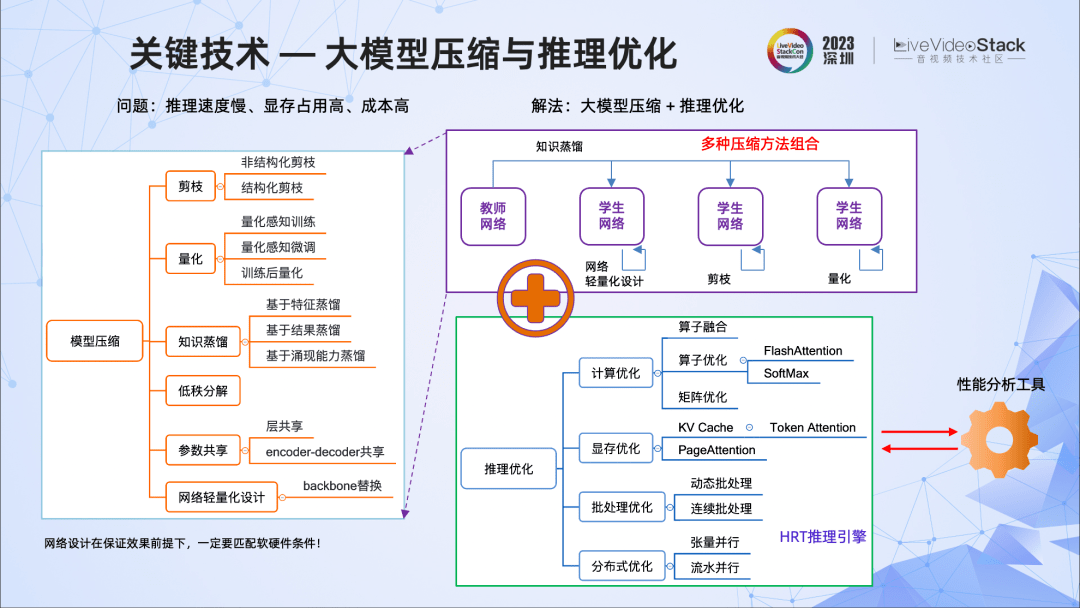
第四,大模型压缩和推理优化。
实际业务对成本的要求是比较高的,我们希望在保证模型效果的前提下,尽量提升推理的性能。
实践中,我们对模型做了多轮的压缩,交替使用多种压缩方法,包括使用轻量的backbone,低秩分解,以及剪枝,知识蒸馏、量化等。比如在抠图中,我们采用多种压缩方式的组合,使模型大小有了显著下降,参数减少30%以上。
此外,我们也做了很多推理层面的优化,比如算子融合、算子优化、矩阵优化,显存优化,批处理优化等,并借助阿里云神龙团队的HRT推理引擎,使得大模型推理性能得到进一步提升。

接下来介绍当前阿里云视频云在大模型方面的进展。在过去近一年的时间内,阿里云视频云在大模型方面做了深入探索,开发了多个算法,所做工作涉及音视频采集、生产、处理、媒资管理、传输分发、播放消费全链路的多个环节。
正如上图所示,在生产制作环节,我们开发实景抠图、声音克隆、文生图、图生图、AI作曲等多个基于大模型的算法;在媒资管理环节,开发了基于大模型的视频搜索、视频标签、视频概要等技术;在处理环节,我们开发了基于大模型的视频修复、语音增强等算法。
目前我们已经初步形成了较为完整的视频云大模型算法阵列。这些算法中很多都已集成进产品,并服务客户。在这里,我将从生产制作、媒资管理、处理方面分别介绍一项典型算法实践,即实景抠图、视频检索、视频修复。
实景抠图是一项非常重要的底层技术,它的应用面非常广,比如我们熟知的数字人制作、虚拟演播厅、影视特效、视频剪辑、视频会议等都会用到它。
阿里云视频云在抠图方面有多年的积累,已开发多种抠图算法,可以应对客户端、服务器等的不同需求,也已在多种业务场景落地。
这里重点介绍的是面向服务器的基于大模型的抠图技术。

一般情况下,想要得到高质量的抠图结果,都要采用搭建绿幕的方式。因为这种情况对光照、设备、去溢色等都有非常专业的要求,在一定程度上限制了绿幕抠图的应用范围。
而在实际业务中,往往需要对实景拍摄的视频,抠出前景来。由于拍摄环境多变、内容多种多样,用算法自动进行抠图实现难度比较大。
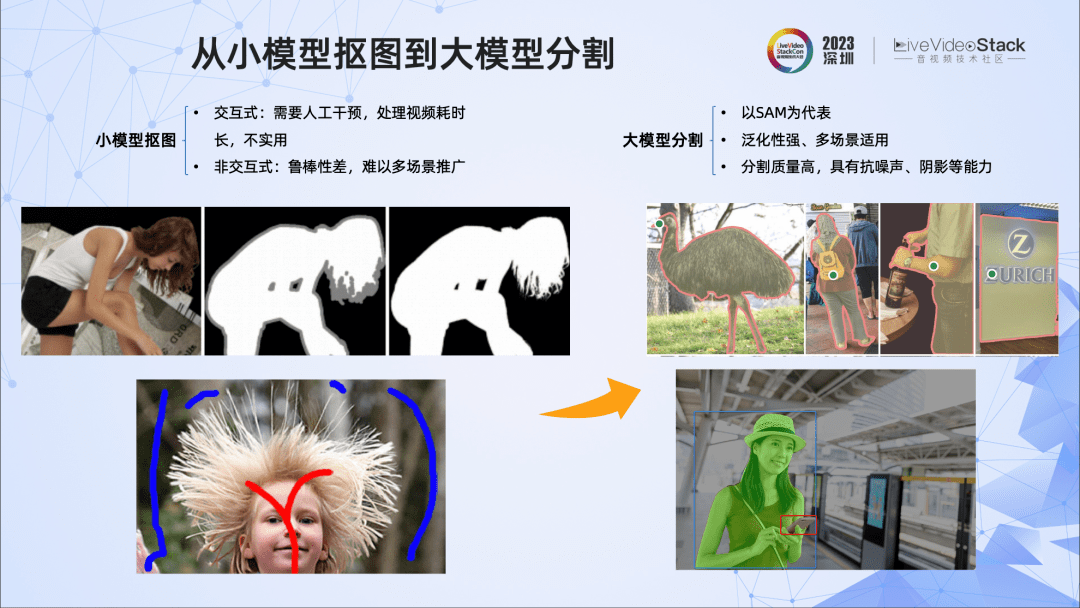
如何对实景视频实现高质量抠图呢?这涉及到算法选型的问题。
我们先看下小模型方法能否实现高质量抠图。经过深入调研,我们发现很多抠图效果好的方法都采用人工干预的方法,这种方式对单帧图像比较友好,但对于视频,往往处理耗时久,不太实用。而采用非交互式方式的抠图,鲁棒性则较差,往往只能较好地抠人像,难以在多场景推广。
大模型分割算法的出现,让我们看到了采用大模型提升抠图效果的可能性。以SAM为例,它的分割泛化能力非常强,分割质量高,对噪声、阴影等也能做到很好的处理。
我们希望借助大模型分割的能力来实现高质量的抠图。
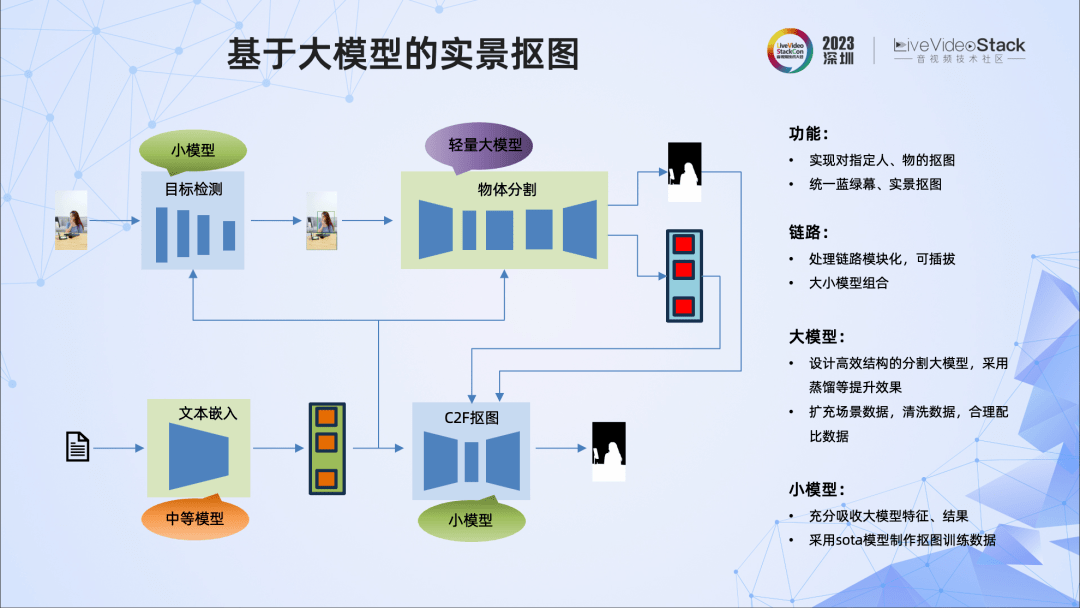
我们提出了一种基于大模型的实景抠图方案。它能统一处理蓝绿幕与实景抠图,所以实际处理中不用再区分背景是蓝绿幕还是实景。此外,该方案不仅可以抠人像,还可以抠与人连带的附属物,并且抠图的质量都非常高。
它的整体流程如下:首先用户提供一些抠图所需的信息,这些信息以文本形式嵌入,然后输入图像与文本嵌入向量逐步经过目标检测、基于轻量化大模型的物体分割、基于小模型的抠图网络。
在这个框架中,模块是可插拔的,而且采用的是大小模型结合的方式。小模型会充分吸收大模型的信息,比如这里的抠图网络,它吸收来自分割模型的特征,提高了抠图的效果。
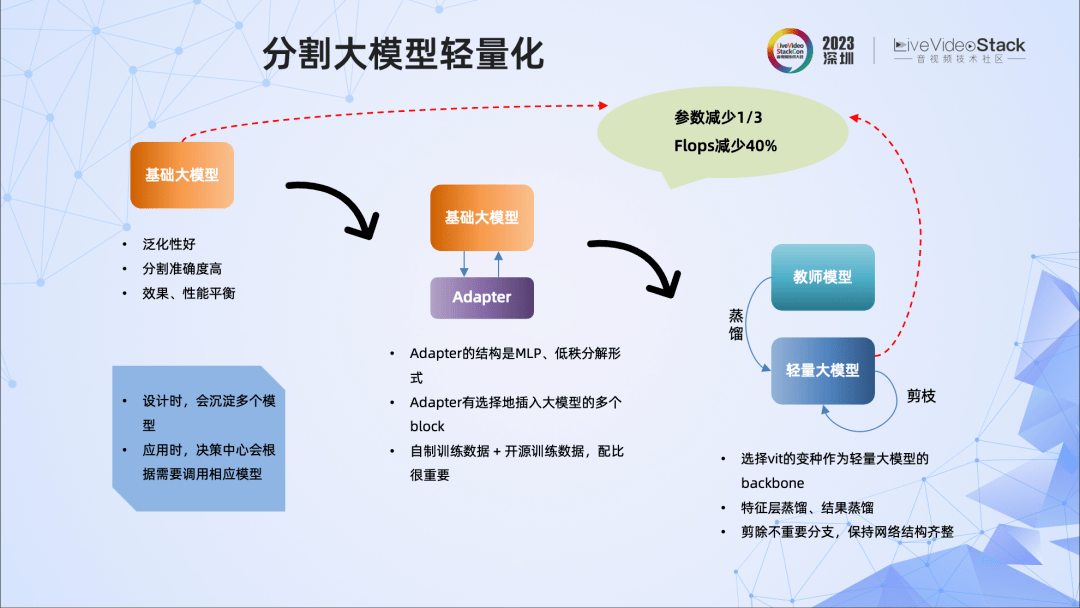
我们重点看下分割大模型是如何做到轻量化的。
首先选择一个各方面都表现比较好的基础大模型(泛化性好、分割准确度高、效果和性能平衡)。
接下来的工作是调整它,解决其适配业务场景的问题,使它在业务场景下表现得比较完美。这里会进行微调,我们设计了Adapter结构,实践中采用了MLP和低秩分解组合的形式。另外,Adapter的插入位置也进行了很多尝试。还有一点是训练数据的制作,以及数据配比等等都非常重要。
有了一个效果比较好的大模型,我们开始设计轻量化的大模型,这个模型采用轻量化的vit结构作为backbone,使用前面训练好的大模型对它进行蒸馏,使用剪枝等技术进行优化。
经过这些操作,轻量化模型的参数下降到基础大模型的2/3。在这个过程中,我们也沉淀了多个不同复杂度、不同抠图能力的模型,把它们的能力送到知识库中。实际业务使用时,决策中心会根据要求调用合适的模型。
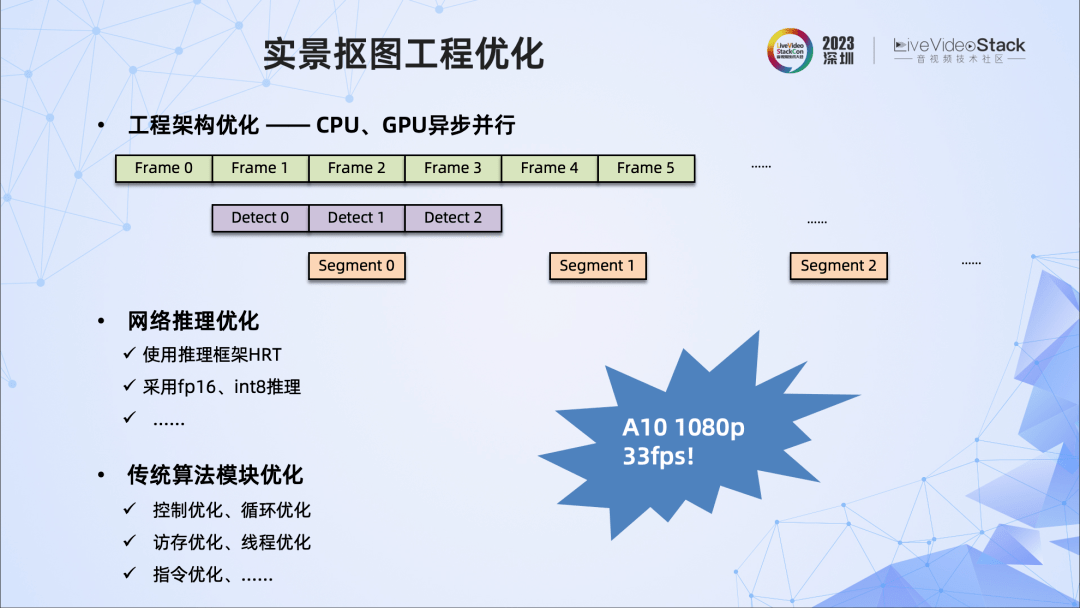
除了算法层面的优化,我们还进行了一些工程侧的优化,主要包含三方面:
1、工程架构的优化,这里采用了CPU、GPU异步并行;
2、网络推理方面的优化,如使用推理框架HRT,采用fp16、int8推理;
3、传统算法模块的优化,如控制优化、循环优化、访存优化、线程优化等。
经过算法、工程两方面的优化,对于输入的1080p视频,我们在A10上实现了33fps的高质量抠图。

我们看下抠图的效果。对于输入图像,我们实现了抠人像、以及抠人像加桌子/化妆品/手机等附属物的效果。这个抠图质量还是比较高的,特别是发丝抠图效果非常细腻,人物、物体的抠图边缘都很精细。
另外,我们也开发了前背景和谐化的技术,解决了抠出的前景与被贴入背景在光照、对比度、色彩等方面不协调的问题。

在刚刚过去的云栖大会,我们也展示了一个抠图的应用,在开放环境中,实现异地多人实时连麦+虚拟背景的功能。右图是现场演示的图像。

我们再看下媒资管理中的视频搜索。它的应用也非常广,包括广电传媒、云导播、云盘管理、短视频内容推荐、视频监控等。
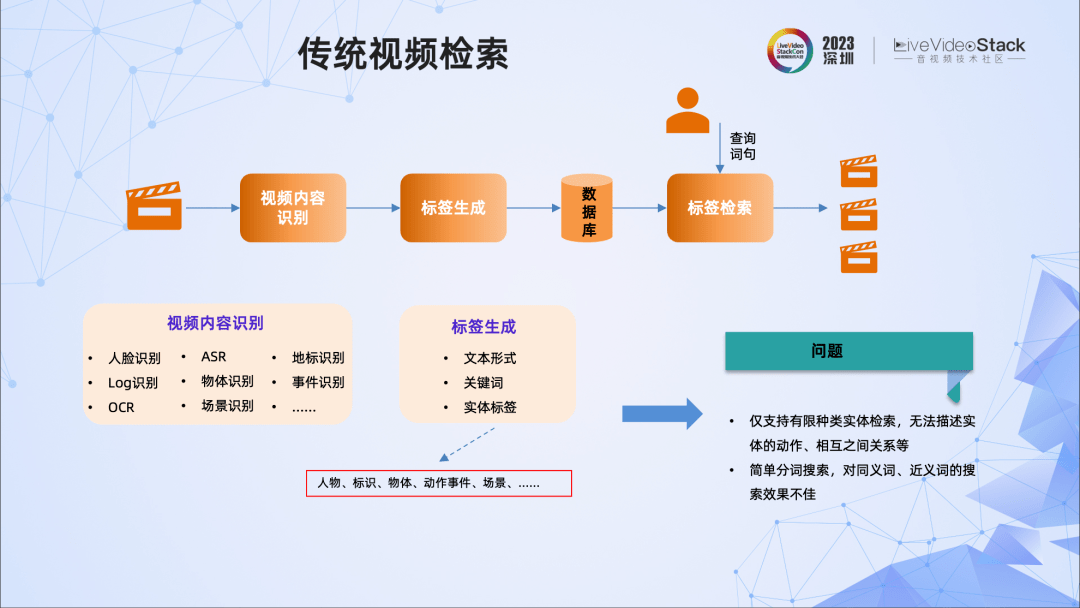
这里先介绍下传统的视频检索方法。
它通常采用小模型方法对视频内容进行识别,包括人脸识别、物体识别、Log识别、OCR、ASR等等,然后生成标签,这些标签是文本关键词形式的,且大部分是实体标签。这些标签都会送到数据库中。对于用户输入的查询语句,进行标签的查询,并返回对应视频的片段。
这里存在一个比较大的问题,即搜索往往是实体的搜索,而对于实体的动作、相互之间关系等很难检索到正确的视频,另外,搜索往往对查询词很敏感。
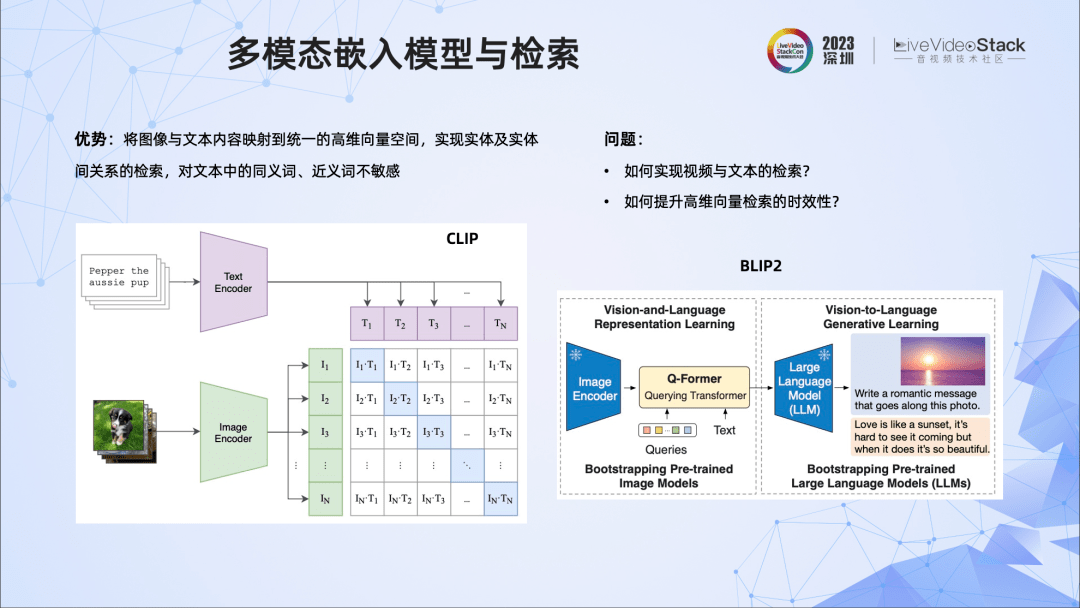
我们看到多模态表征技术将图像和文本映射到统一的高维空间中,实现了实体、实体关系等的高质量检索,并对文本中的同义词、近义词不敏感。这些典型的表征技术包括CLIP、BLIP技术等,还有针对中文的ChineseCLIP、TEAM等。但这些技术是针对单帧图像的,而我们的场景都是视频。那如何实现视频的检索?如何提升高维向量检索的时效性呢?
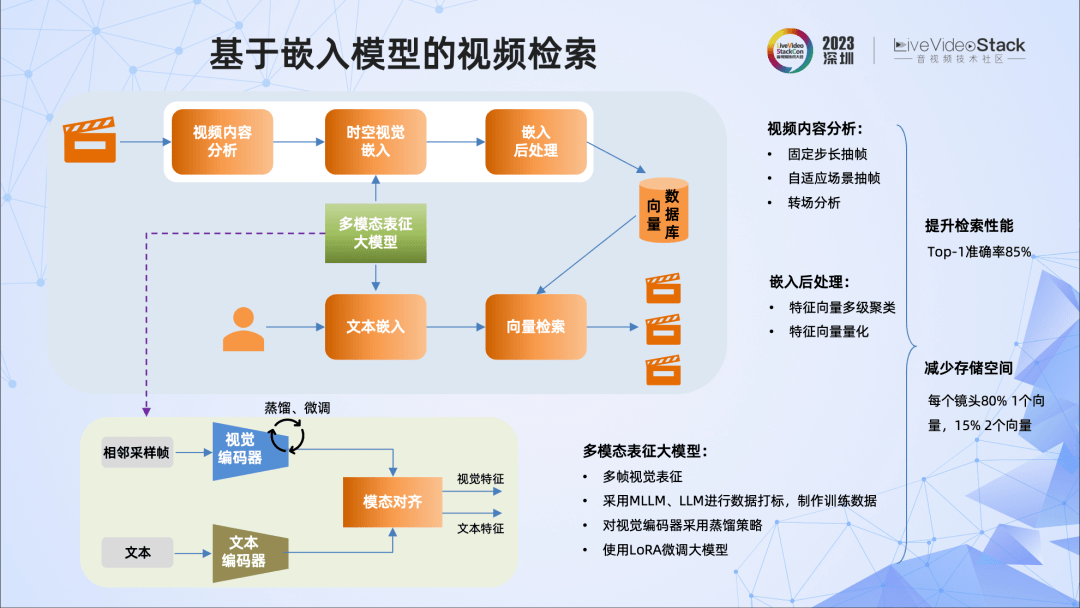
我们提出了一种基于嵌入模型的视频检索算法。
对于视频而言,同一个镜头,最好用同一个或少数几个embedding vector表示。这样做的好处是减少了embedding向量的数量,也就减少了存储的空间和检索的计算量,同时,由于是对镜头进行处理,表征的质量更高,检索的质量也就更高。我们通过三步达到这个目标:
1、首先,对视频内容分析,结合固定步长抽帧和自适应抽帧,初步过滤掉一些信息冗余的帧;
2、其次,采用相邻采样帧,进行时空维度的特征编码;
3、最后,对嵌入向量,从检索角度,进行多级聚类和量化。
经过这三个过程,在同一镜头内,得到的最终向量只有非常少数,大大降低了向量的存储空间,提升了检索的效率,而且也提高了检索质量。
这里我们设计了多帧的视觉编码器,采用微调、蒸馏等方法保证了它的效果,并实现了它与文本的对齐。
在前面方法的基础上,我们又提出了一种信息融合的视频检索算法。这里解决的问题是:
一是实现视觉+声音与文本间的检索,比如检索出小鸟在树上叫的视频片段,二是实现更细粒度的检索,比如某位名人在某个著名景点的活动。
针对这两个问题,我们分别设计了时空视听嵌入模块和关键实体识别模块,分别提取不同粒度的表征信息。在检索阶段,我们会分别对两种粒度的嵌入向量进行检索,再对二者的信息进行融合,最终实现更好的检索效果。
此算法发挥了不同模型优势,融合了多模态的信息,并提升了检索的适用范围。

我们再看下多模态融合是如何实现的。整个过程如上图所示。
它实现了同一场景视觉与听觉的特征融合,也实现了视听特征与文本的模态对齐。我们借鉴了ImageBind的方法,把音频、文本都对齐到了视觉空间。

目前,该功能已经集成进媒体服务产品中。这里展示了一些视频搜索的效果,我们可以看到新方法的一些效果,它对动作、时间、数量等都有比较好的检索能力。
最后看下处理方面的视频修复算法。视频修复的应用场景非常广泛,比如体育赛事、综艺节目、影视剧、纪录片、动漫、老歌MV等场景。
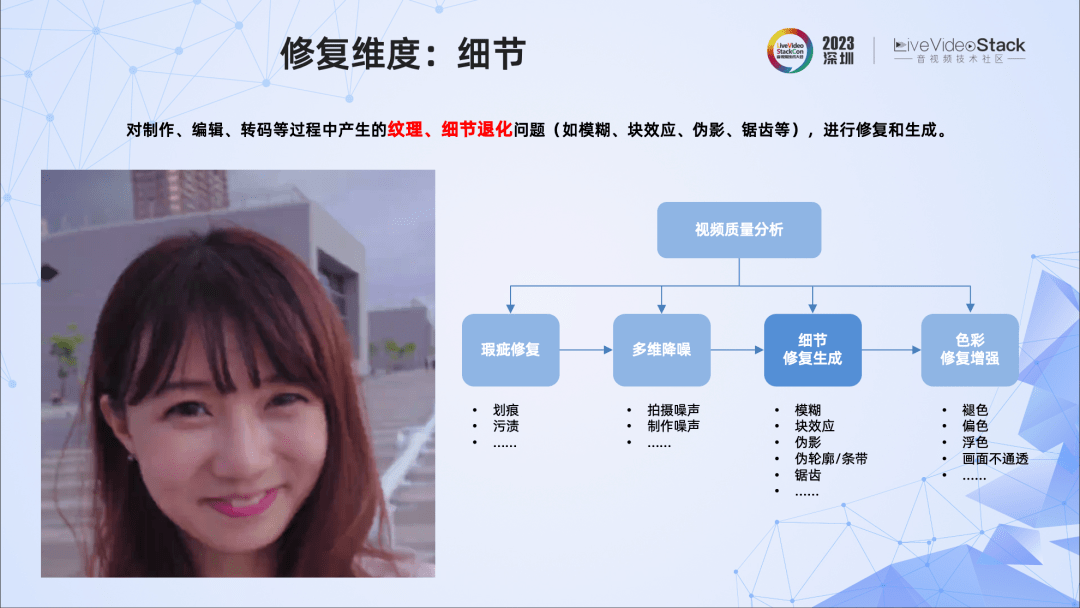
视频修复的维度非常多样,比如针对瑕疵、拍摄或制作中的噪声、细节、色彩等,都可以进行修复。这里讲的视频修复针对的是直播、点播等场景中,在制作、编辑、转码中引入的细节退化问题。如左图所示,我们能看到明显的细节退化,比如模糊、块效应、边缘锯齿等。

那用什么方法来解决细节退化呢?这里牵扯到算法选型的问题。
从我们之前积累的经验看,GAN方法对一些垂直领域的、退化不是非常严重的场景,可以有比较好的效果。但当片源或流的质量比较差时,GAN方法的细节恢复就显得不够了,而且此时生成的效果也不太自然。此外RealESRGAN的效果,一定程度上也印证了我们的结论。
我们发现,基于SD预训练模型的StableSR可以取得更好的细节生成效果,具体表现为:它对源质量适应性强,效果自然、稳定,细节恢复质量高。因此我们选择SD来应对这样的修复场景。
下面介绍我们的方案。该算法借鉴了StableSR的一些想法,网络层面也是由UNet和VAEFGAN组成的。我们结合业务场景进行深入的设计和调整,特别是针对badcase的处理做了大量工作。这里简单介绍几方面:
1、在训练数据方面,采用了离线和在线结合的数据降质模拟策略;
2、针对VAEGAN中编码器处理后有信息损失的问题,我们采用了编码器特征导引解码器的网络形式,并对他们进行联合微调;
3、在训练策略上,通过引入HR编码器特征,把扩散模型与VAEGAN解耦;
4、此外我们也采用了多阶段训练策略。

这里展示了SD修复的效果。从图中不难看出,新方法对人像和自然物都有很好的修复,比如,头发上的很多细节都恢复出来了,人的五官变得更清晰了,远处船上及绳索上的细节、建筑物的细节也恢复出来了。

关于音视频大模型的思考,这里介绍四个方面:
第一是端侧智能。随着终端芯片对大模型支持的力度越来越大,比如apple、高通等公司都发布了大模型终端芯片,大模型在端侧落地已是必然趋势。目前我们从端侧大模型设计、推理优化两方面入手,针对高端机型,进行了端侧大模型落地的探索。
第二是云端一体。从技术层面讲,需要解决两方面的问题,第一个是如何划分大模型云、端的计算负载,第二个是大模型的特征编码。
第三是模型的统一。这里重点强调两个统一,视觉模型backbone的统一、以及多模态encoder的统一。在有了统一的基座模型之后,可以针对业务场景对下游任务进行finetune。
第四是大模型的决策能力。我们希望大模型不仅能解决单点问题,还希望它有规划、行动的能力,也就是Agent的概念。现在在算法层面,我们已经做了一些工作,接下来我们希望用大模型来提升引擎、调度、业务层的智能化水平。
我的分享就到这里,谢谢!
