前面我们对MDK中的数据压缩相关操作和配置进行了介绍,本文进一步分析其算法。
随便创建一个工程这里创建的stm32的工程,代码如下(启动代码略),注意变量v要足够大,只有压缩省下的空间大于压缩代码本身大小链接器才会进行压缩。
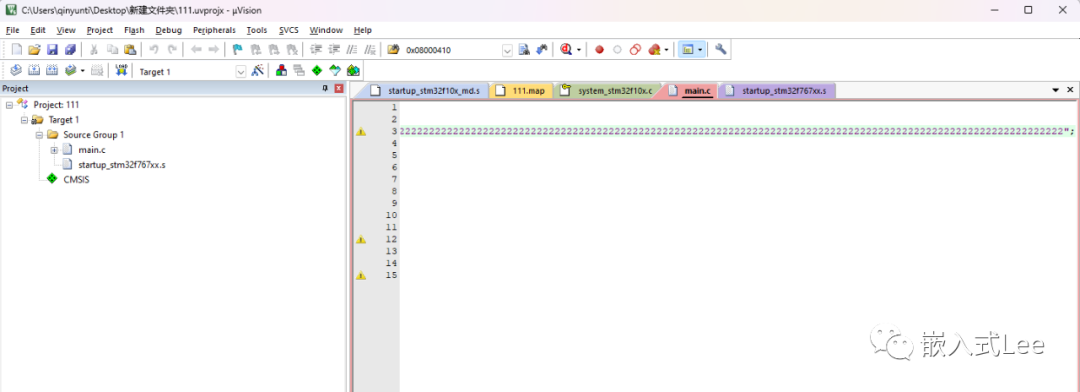
uint8_t v[]="1111122222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222";int main(void){printf("%s",v);}void SystemInit (void){}
我们可以通过map文件看到,实际是链接了cmprslib下的相关解压代码
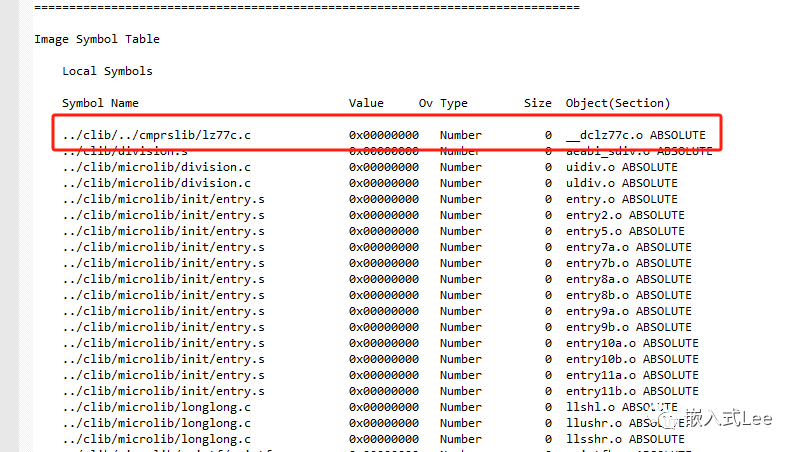
代码具体位置如下,即0x08000269处的94字节。
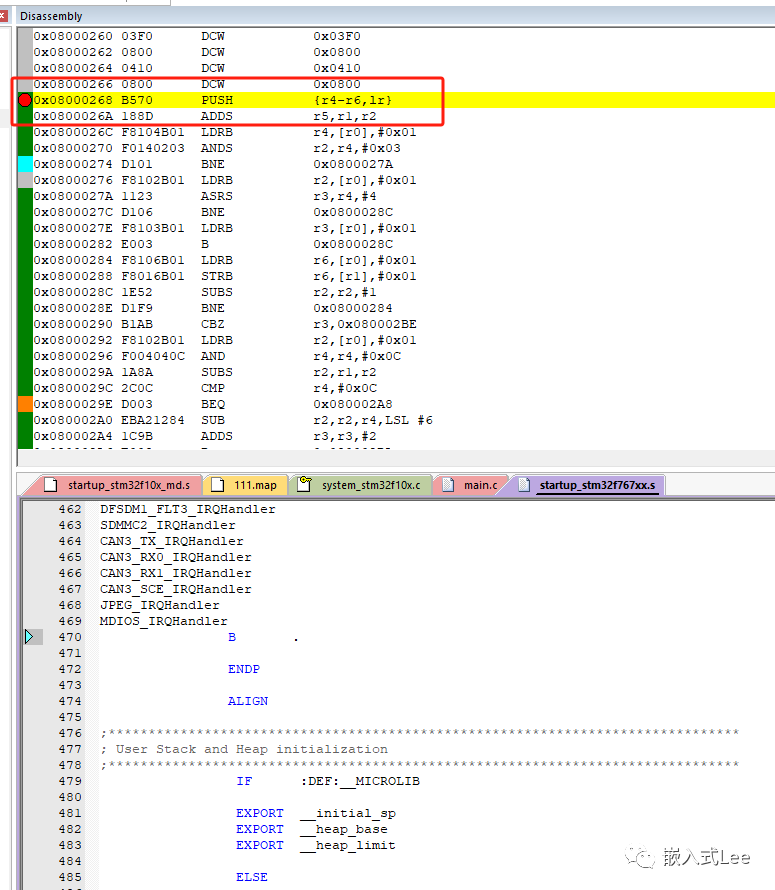
配置软件仿真
调出汇编窗口,在对应的代码处0x08000268打断点(注上面看到的时0x08000269是因为bit0=1表示是thumb指令)
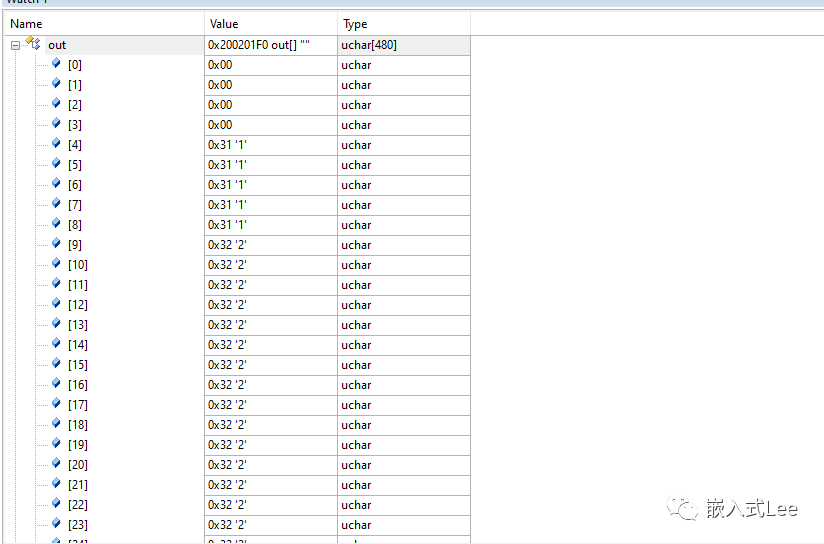
查看变量v的地址为0x20020004,大小是476字节
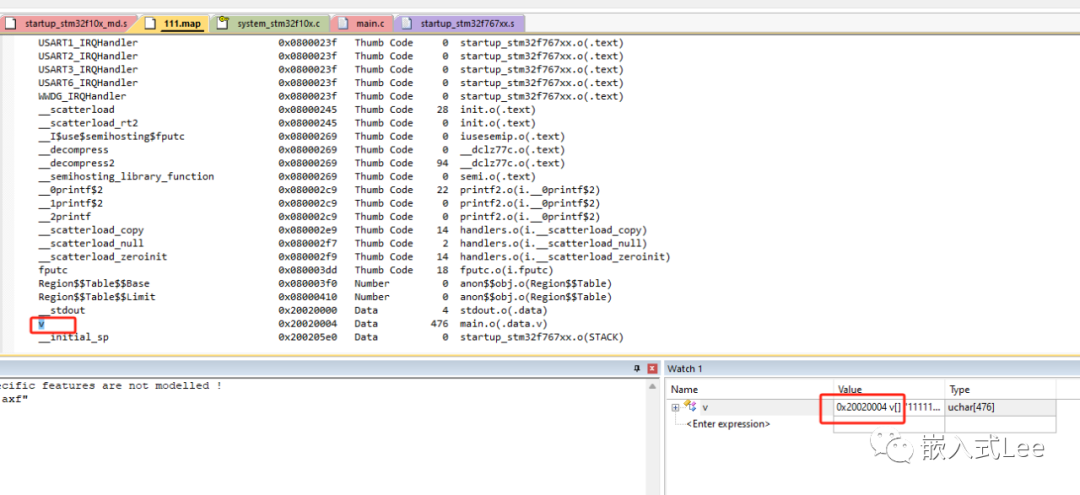
实际前面还有4字节的压缩数据是stdout用的。
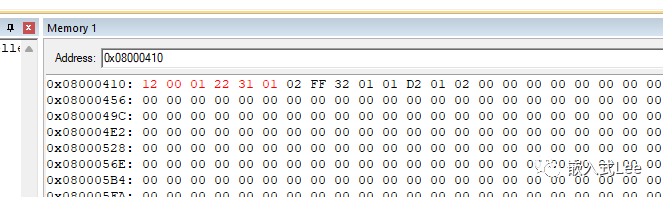
加载地址为0x08000410对应的是压缩数据,解压后为4+476字节,其中4字节是stdout中的全局变量,476字节是我们定义的v变量。
对应的压缩后的数据,即该部分数据要解压成4+476字节的数据
对应的代码如下
前面可以看到压缩是链接器完成的,所以这里程序中只有解压的代码。我们通过解压代码也可以分析其算法。
现在开始就进行”人工智能-手动反汇编”。将上述汇编代码改写为C代码。
为了方便描述把对应的汇编代码复制出来,并添加行号。
(1):0x08000268 B570 PUSH {r4-r6,lr}(2):0x0800026A 188D ADDS r5,r1,r2(3):0x0800026C F8104B01 LDRB r4,[r0],#0x01(4):0x08000270 F0140203 ANDS r2,r4,#0x03(5):0x08000274 D101 BNE 0x0800027A(6):0x08000276 F8102B01 LDRB r2,[r0],#0x01(7):0x0800027A 1123 ASRS r3,r4,#4(8):0x0800027C D106 BNE 0x0800028C(9):0x0800027E F8103B01 LDRB r3,[r0],#0x01(10):0x08000282 E003 B 0x0800028C(11):0x08000284 F8106B01 LDRB r6,[r0],#0x01(12):0x08000288 F8016B01 STRB r6,[r1],#0x01(13):0x0800028C 1E52 SUBS r2,r2,#1(14):0x0800028E D1F9 BNE 0x08000284(15):0x08000290 B1AB CBZ r3,0x080002BE(16):0x08000292 F8102B01 LDRB r2,[r0],#0x01(17):0x08000296 F004040C AND r4,r4,#0x0C(18):0x0800029A 1A8A SUBS r2,r1,r2(19):0x0800029C 2C0C CMP r4,#0x0C(20):0x0800029E D003 BEQ 0x080002A8(21):0x080002A0 EBA21284 SUB r2,r2,r4,LSL #6(22):0x080002A4 1C9B ADDS r3,r3,#2(23):0x080002A6 E008 B 0x080002BA(24):0x080002A8 F8104B01 LDRB r4,[r0],#0x01(25):0x080002AC EBA22204 SUB r2,r2,r4,LSL #8(26):0x080002B0 E7F8 B 0x080002A4(27):0x080002B2 F8124B01 LDRB r4,[r2],#0x01(28):0x080002B6 F8014B01 STRB r4,[r1],#0x01(29):0x080002BA 1E5B SUBS r3,r3,#1(30):0x080002BC D5F9 BPL 0x080002B2(31):0x080002BE 42A9 CMP r1,r5(32):0x080002C0 D3D4 BCC 0x0800026C(33):0x080002C2 2000 MOVS r0,#0x00(34):0x080002C4 BD70 POP {r4-r6,pc}
首先,(1)将r4~r6保存到栈中,因为后面要使用这几个寄存器,lr是函数返回地址也要保存。
(34)后面对应的POP即反过程,恢复这几个寄存器,并将lr寄存器恢复到PC即返回到调用该函数之前的位置。
(33)这里r0作为返回值,固定返回为0, 当然这里函数返回类型也可能是void,没有返回类型编译器只是固定将其置为0而已。
(1):0x08000268 B570 PUSH {r4-r6,lr}(33):0x080002C2 2000 MOVS r0,#0x00(34):0x080002C4 BD70 POP {r4-r6,pc}
可以看到r0~r3没有保存,这是因为r0~r2他们用于传参了,r3未用。所以我们在(1)时查看r0~的值可以确认其传输入的参数值。
实际还需要更往前一步,先看解压之前做了什么准备工作,解压函数的参数是怎么准备的。
这里往前看前面一段代码

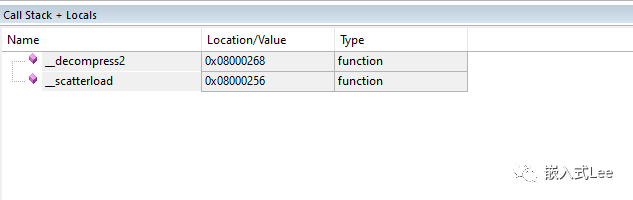
这个是_scatterload函数的入口,
其实这里定义了一个表格,表格的开始地址是后面的常数
0x08000260 03F0 DCW 0x03F00x08000262 0800 DCW 0x0800
结束地址是后面定义的常数
0x08000264 0410 DCW 0x04100x08000266 0800 DCW 0x0800
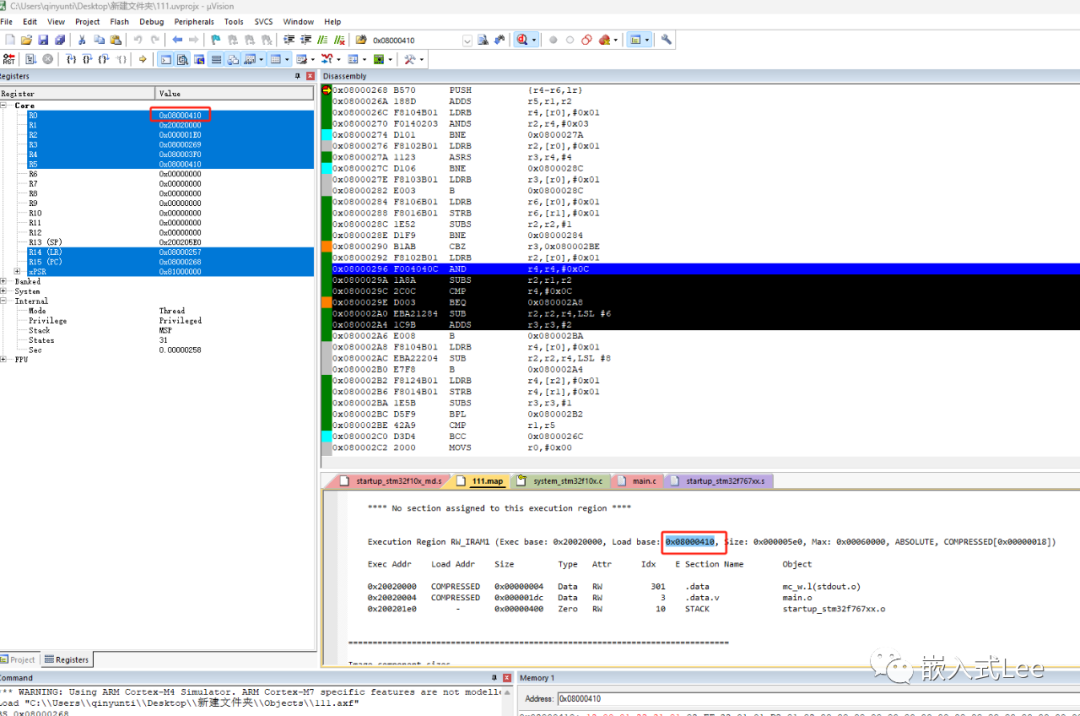
我们看到0x08000410即DATA的加载地址的前面
0x08000240 01F9 DCW 0x01F90x08000242 0800 DCW 0x08000x08000244 4C06 LDR r4,[pc,#24] ; @0x080002600x08000246 4D07 LDR r5,[pc,#28] ; @0x080002640x08000248 E006 B 0x080002580x0800024A 68E0 LDR r0,[r4,#0x0C]0x0800024C F0400301 ORR r3,r0,#0x010x08000250 E8940007 LDM r4,{r0-r2}0x08000254 4798 BLX r30x08000256 3410 ADDS r4,r4,#0x100x08000258 42AC CMP r4,r50x0800025A D3F6 BCC 0x0800024A0x0800025C F7FFFFD0 BL.W 0x08000200 __main_after_scatterload0x08000260 03F0 DCW 0x03F00x08000262 0800 DCW 0x08000x08000264 0410 DCW 0x04100x08000266 0800 DCW 0x0800
以下就是将上述定义的开始和结束常数加载到r4和r5(通过pc偏移24和28取得上述常数)。
如果不相等,说明开始和结束之间有数据项。然后跳到中间的0x0800024A开始处理数据
0x08000244 4C06 LDR r4,[pc,#24] ; @0x080002600x08000246 4D07 LDR r5,[pc,#28] ; @0x080002640x08000248 E006 B 0x08000258......0x08000258 42AC CMP r4,r50x0800025A D3F6 BCC 0x0800024A
如下即处理过程,先从r4即0x080003F0处偏移12的地址,取值放到r0中,此时r0的值为0x08000268,即解压缩处理函数的地址。而后面ORR r3,r0,#0x01是因为thunmb指令,地址bit0需要为1,后面的BLX r3即跳到该函数处执行。
x0800024A 68E0 LDR r0,[r4,#0x0C]0x0800024C F0400301 ORR r3,r0,#0x010x08000250 E8940007 LDM r4,{r0-r2}0x08000254 4798 BLX r30x08000256 3410 ADDS r4,r4,#0x100x08000258 42AC CMP r4,r50x0800025A D3F6 BCC 0x0800024A
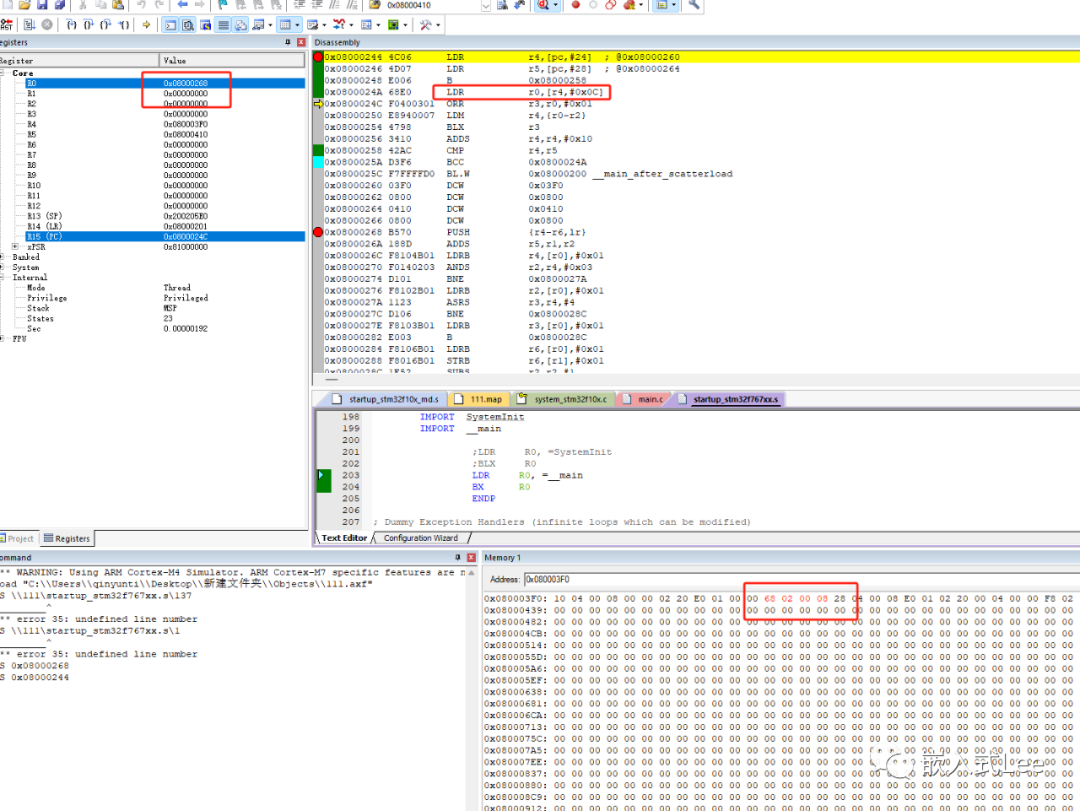
前面的LDM r4,{r0-r2}即从r4处(0x080003F0)加载值到r0~r2
所以r0~r2的值即为解压函数的参数,值分别为r0=0x083000410对应加载地址压缩前数据地址,r1=0x20020000即运行地址即解压后存放的地址,r2=0x000001E0即解压后大小480=4+476.
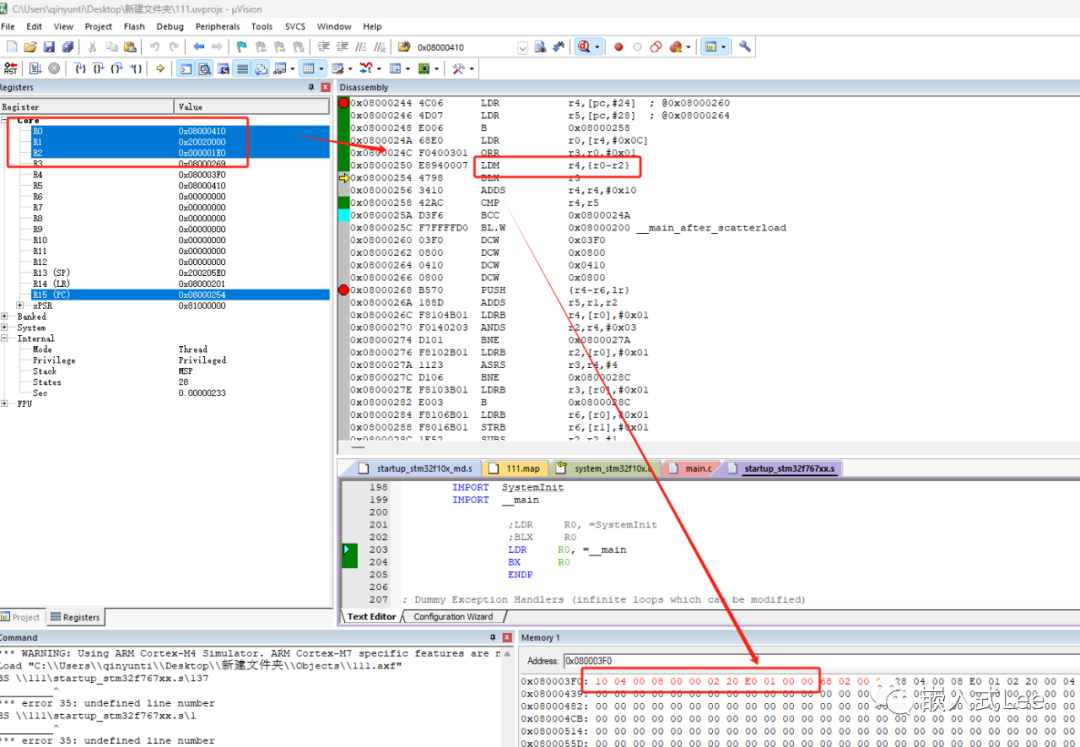
后面处理完数组中的一个结构如下红色16个字节,r4就增加16,继续比较r4和r5看是不是还有其他的.16是因为一个数据项是16字节(加载地址,运行地址,解压后大小,回调函数)
如果没有了就调用__main_after_scatterload。

0x08000256 3410 ADDS r4,r4,#0x100x08000258 42AC CMP r4,r50x0800025A D3F6 BCC 0x0800024A0x0800025C F7FFFFD0 BL.W 0x08000200 __main_after_scatterload
以上整个原理就完整的暴露出来了,为了方便理解,下面画出框图。
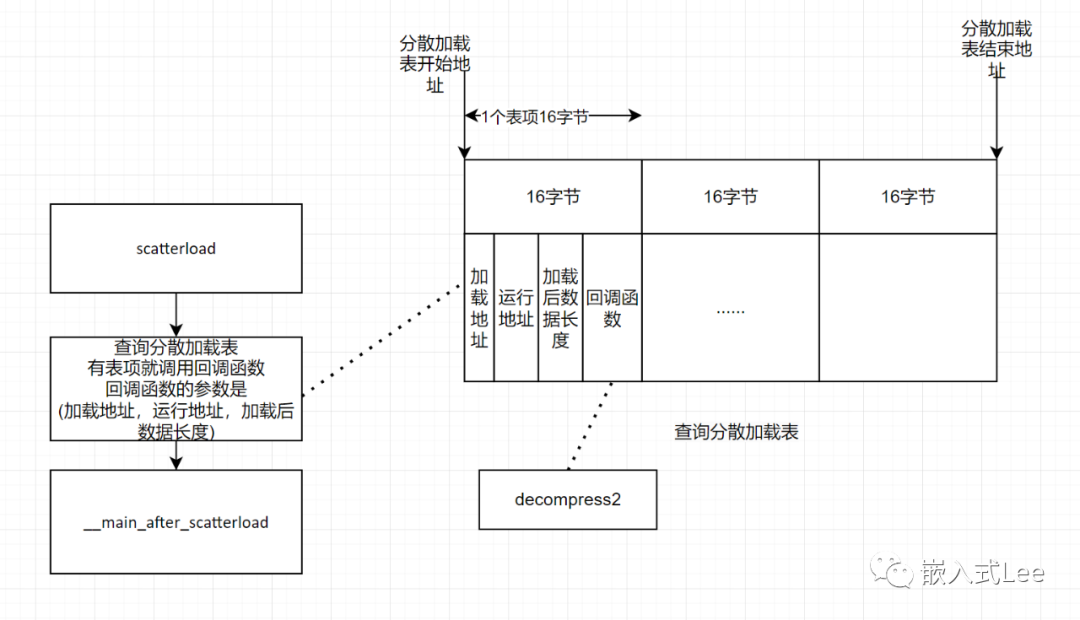
首先scatterload函数查询分散加载开始地址和结束地址之间是否有表项,
表项的结构是:
加载地址,即压缩前的数据地址
运行地址,即解压后数据的存放地址
加载后数据长度:解压后的数据长度
加载回调函数:解压回调函数。
注意上面实际是分散加载的处理过程,不一定是解压,也可以是任意的操作,由回调函数指定,所以理论上也可以插入自己的解压处理函数,甚至其他任意的自定义处理函数。
更进一步,实际上上面提供了一个用户钩子函数,可以有更多的玩法,比如解密,解混淆等等,可以发挥自己的想法玩出更多的花样,在具体产品开发时也可以考虑该特性去实现一些特殊的需求。
接下来正是进入正题,分析解压函数
上面实际已经分析了解压函数的入口和出口
即(1) (33) (34)已经分析了
(1):0x08000268 B570 PUSH {r4-r6,lr}(2):0x0800026A 188D ADDS r5,r1,r2(3):0x0800026C F8104B01 LDRB r4,[r0],#0x01(4):0x08000270 F0140203 ANDS r2,r4,#0x03(5):0x08000274 D101 BNE 0x0800027A(6):0x08000276 F8102B01 LDRB r2,[r0],#0x01(7):0x0800027A 1123 ASRS r3,r4,#4(8):0x0800027C D106 BNE 0x0800028C(9):0x0800027E F8103B01 LDRB r3,[r0],#0x01(10):0x08000282 E003 B 0x0800028C(11):0x08000284 F8106B01 LDRB r6,[r0],#0x01(12):0x08000288 F8016B01 STRB r6,[r1],#0x01(13):0x0800028C 1E52 SUBS r2,r2,#1(14):0x0800028E D1F9 BNE 0x08000284(15):0x08000290 B1AB CBZ r3,0x080002BE(16):0x08000292 F8102B01 LDRB r2,[r0],#0x01(17):0x08000296 F004040C AND r4,r4,#0x0C(18):0x0800029A 1A8A SUBS r2,r1,r2(19):0x0800029C 2C0C CMP r4,#0x0C(20):0x0800029E D003 BEQ 0x080002A8(21):0x080002A0 EBA21284 SUB r2,r2,r4,LSL #6(22):0x080002A4 1C9B ADDS r3,r3,#2(23):0x080002A6 E008 B 0x080002BA(24):0x080002A8 F8104B01 LDRB r4,[r0],#0x01(25):0x080002AC EBA22204 SUB r2,r2,r4,LSL #8(26):0x080002B0 E7F8 B 0x080002A4(27):0x080002B2 F8124B01 LDRB r4,[r2],#0x01(28):0x080002B6 F8014B01 STRB r4,[r1],#0x01(29):0x080002BA 1E5B SUBS r3,r3,#1(30):0x080002BC D5F9 BPL 0x080002B2(31):0x080002BE 42A9 CMP r1,r5(32):0x080002C0 D3D4 BCC 0x0800026C(33):0x080002C2 2000 MOVS r0,#0x00(34):0x080002C4 BD70 POP {r4-r6,pc}
我们先根据前面的分析写出函数的原型
void decompress(uint32_t len, uint8_t* vma, uint8_t* lma){}
其中lma通过r0传参,即加载地址(压缩数据地址),
vma通过r1为传参,运行地址(即解压后地址),
len通过r2传参即,解压后数据长度。
继续往下看
以下获取了vma的结束地址,即开始地址加上长度,用于判断结束条件。
(2)0x0800026A 188D ADDS r5,r1,r2以下用于判断是否结束,即r1从vma开始,表示写入vma地址,写完一个递增,直到递增到结束地址,表示写完。
比如如下指令用于将数据写入vma地址,每写入一个r1即递增
(28):0x080002B6 F8014B01 STRB r4,[r1],#0x01(31)(32)即比较当前写入vma的地址r1是否达到了vma的结束地址r5
(31):0x080002BE 42A9 CMP r1,r5(32):0x080002C0 D3D4 BCC 0x0800026C
Cmp实际是进行r1-r5操作,bcc表示前面的操作结果有进位(c即进位),即r1
所以可以写出如下代码,即最外面一层
void decompress(uint32_t len, uint8_t* vma, uint8_t* lma){uint8_t* end = vma + len;while(vma < end){}}
继续往下走
(3):0x0800026C F8104B01 LDRB r4,[r0],#0x01(4):0x08000270 F0140203 ANDS r2,r4,#0x03
(3)即从r0所在的地址处,即加载地址处读一个字节到r4,读完后r0递增,即指针递增。
于是写出如下c代码
void decompress(uint32_t len, uint8_t* vma, uint8_t* lma){uint8_t* end = vma + len;uint_t tmp4;while(vma < end){tmp4 = *lma++;}}
(4)(5)将上述读出来的值取低2位,看是不是0.
不为0即跳到(7) 相同即执行后面的(6)
其中(6)即读出lma后面一个数据,
(6):0x08000276 F8102B01 LDRB r2,[r0],#0x01因为此时r0已经递增1了,并且读完后继续递增1.
而(7)是将最开始读到到的值右移4位,赋值给r3,然后紧接着是(8)看结果是不是0,
如果不是0则跳到(13)否则执行后面的(9)即读lma的后续一个数据。
上面可以看到是连续的if else判断。
先判断最低2位,表示是否需要读一个字节到r2
然后判断高4位,表示需要读一个字节到r3,
此时代码可以写为如下
void decompress(uint32_t len, uint8_t* vma, uint8_t* lma){uint8_t* end = vma + len;uint8_t tmp4;uint8_t tmp2;uint8_t tmp3;while(vma < end){tmp4 = *lma++;tmp2 = tmp4 & 0x03;if(tmp2 == 0){tmp2 = *lma++;}tmp3 = tmp4 >> 4;if(tmp3 == 0){tmp3 = *lma++;}}}
继续往下走来到,前面不管是if还是else都来到了0x0800028C
该处是一个循环,代码块如下
(11):0x08000284 F8106B01 LDRB r6,[r0],#0x01(12):0x08000288 F8016B01 STRB r6,[r1],#0x01(13):0x0800028C 1E52 SUBS r2,r2,#1(14):0x0800028E D1F9 BNE 0x08000284
转化成c代码如下,这里是先到0x0800028C即先减1再比较所以是---tmp2
while(--tmp2){*vma++ = *lma++;}
上述代码块执行完后,执行
(23):0x080002A6 E008 B 0x080002BA都跳到了0x080002BA处执行,
这里也可看出是一个循环
接下来来到了如下代码块
(15):0x08000290 B1AB CBZ r3,0x080002BE先判断r3是否位0,为0就直接跳到0x080002BE去,否则执行下面代码块
(16):0x08000292 F8102B01 LDRB r2,[r0],#0x01(17):0x08000296 F004040C AND r4,r4,#0x0C(18):0x0800029A 1A8A SUBS r2,r1,r2
对应c
tmp2 = *lma++;tmp4 = tmp4 & 0x0C;p = vma - tmp2
如下又是一个if else
(19):0x0800029C 2C0C CMP r4,#0x0C(20):0x0800029E D003 BEQ 0x080002A8(21):0x080002A0 EBA21284 SUB r2,r2,r4,LSL #6(22):0x080002A4 1C9B ADDS r3,r3,#2(23):0x080002A6 E008 B 0x080002BA(24):0x080002A8 F8104B01 LDRB r4,[r0],#0x01(25):0x080002AC EBA22204 SUB r2,r2,r4,LSL #8(26):0x080002B0 E7F8 B 0x080002A4
改为c
if(tmp4 != 0x0C){p = p - (tmp4<<6);tmp3 += 2;}else{tmp4 = *lma++;p = p - (tmp4<<8);}
最后又是一个循环赋值
前面都来到了(23):0x080002A6 E008 B 0x080002BA
(23):0x080002A6 E008 B 0x080002BA先减少1再判断BPL,注意BPL是非负跳转,即r3每次减少1,大于等于0,都会跳到0x080002B2
(27):0x080002B2 F8124B01 LDRB r4,[r2],#0x01(28):0x080002B6 F8014B01 STRB r4,[r1],#0x01(29):0x080002BA 1E5B SUBS r3,r3,#1(30):0x080002BC D5F9 BPL 0x080002B2
改成c代码如下
while(tmp3--){*vma++ = *p++;}
以上就完成了整个代码
void decompress(uint32_t len, uint8_t* vma, uint8_t* lma){uint8_t* end = vma + len;uint8_t tmp4;uint8_t tmp2;uint16_t tmp3;uint8_t* p;while(vma < end){tmp4 = *lma++;tmp2 = tmp4 & 0x03;if(tmp2 == 0){tmp2 = *lma++;}tmp3 = tmp4 >> 4;if(tmp3 == 0){tmp3 = *lma++;}while(--tmp2){*vma++ = *lma++;}if(tmp3 != 0){tmp2 = *lma++;tmp4 = tmp4 & 0x0C;p = vma - tmp2;if(tmp4 != 0x0C){p = p - (tmp4<<6);tmp3 += 2;}else{tmp4 = *lma++;p = p - (tmp4<<8);}while(tmp3--){*vma++ = *p++;}}}}
测试代码如下,将上面的压缩数据,再用我们反汇编后的代码进行解压,看是否正确
uint8_t out[480];uint8_t in[]={0x12,0x00,0x01,0x22,0x31,0x01,0x02,0xff,0x32,0x01,0x01,0xd2,0x01,0x02,0x00,0x00};uint8_t v[]="1111122222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222";void decompress(uint32_t len, uint8_t* vma, uint8_t* lma){uint8_t* end = vma + len;uint8_t tmp4;uint8_t tmp2;uint16_t tmp3;uint8_t* p;while(vma < end){tmp4 = *lma++;tmp2 = tmp4 & 0x03;if(tmp2 == 0){tmp2 = *lma++;}tmp3 = tmp4 >> 4;if(tmp3 == 0){tmp3 = *lma++;}while(--tmp2){*vma++ = *lma++;}if(tmp3 != 0){tmp2 = *lma++;tmp4 = tmp4 & 0x0C;p = vma - tmp2;if(tmp4 != 0x0C){p = p - (tmp4<<6);tmp3 += 2;}else{tmp4 = *lma++;p = p - (tmp4<<8);}while(tmp3--){*vma++ = *p++;}}}}int main(void){decompress(480, out, in);printf("%s",v);}
运行后查看输出,完全正确

前面C代码出来之后,就好理解整个编码了。
通过前面的if和else也可以看出,
首先编码数据的第一个字节不同字段决定了后续字节的含义,
位域 | Bit[7:4] | Bit[3:2] | Bit[1:0] |
含义 | 有压缩重复数据的个数,如果bit[3:2]!=11则这个+2代表真正的个数。 该值不为0才有重复的数据。 如果bit[7:4]不为0, 则后续一个编码数据代表,重复数在当前已经解码数据往前的偏移位置。
| 如果bit[7:4]不为0, ,bit[3:2],表示偏移算法。
在后续一个编码偏移的基础上,如果bit[3:2]不为11则偏移bit[3:2]*64. 否则是在此基础上再偏移下一个编码数据的值*256.
最后根据上面偏移地址找到该重复数据,复制重复个数到当前解压区。 | 后续未压缩数据的个数-1 如果为0,则需要读后续一个字节的编码代表未压缩数据的个数 |
比如
0x12,0x00,0x01
0x12的最低两位为2,所以未压缩数据个数是2-1=1.
所以需要复制0x12后面的一个数据0x00到解压区。
此时解压后的数据是0x00.
0x12而高4位为1,所以有重估数据,而0x12的bit[3:2]为0,所以重复个数药+2,即1+2=3.
且偏移是后续一个编码数据0x01.
所以要找重复数据即要先偏移0x01,然后再偏移bit[3:2]*64,由于bit[3:2]=0,所以即偏移1,
即解压位置往前偏移1就是已经解压的数据0x00的位置。
然后从这个位置复制这个重复的0,复制3次追加到原来的0x00后面,
最终得到0x00 0x00 0x00 0x00.
即上面的stdout的4个数据。
其他解压过程类似。
以上是解压过程,比较简单,压缩的实现要复杂很多。 后面我们再继续分享。
以上通过手动反汇编,分析了解压算法的实现。我们可以借鉴其思想,实现我们自己一个超级精简的可移植的压缩,解压算法,作为我们的代码库积累。 之前也预告了,在我们的高效的文件传输协议中也将会引入压缩以提高传输效率。详见后面一期超级精简系列。
