熟悉MDK开发环境,且和其他工具对比过的开发者可能会注意到, MDK生成的代码镜像一般会小一些。这是因为MDK默认是会进行压缩处理的,尤其体现在对RW Data的压缩上。我们就来分析分析其原理,扒一扒其算法,以后可以借鉴到自己的项目当中。本文先介绍相关的操作和配置。
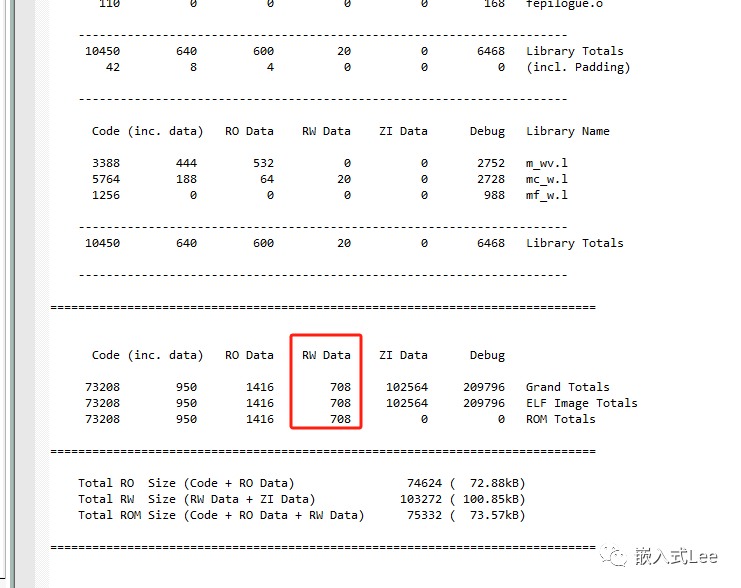
我们通过map文件可以看到如下信息
其中Grand Totals即原始各区域的大小,ELF Image Totals(compressed)即压缩后的各区域大小,如果没有压缩则没有(compressed)这个括号的内容。可以看到后者的RW Data要小一些,这时因为对RW Data数据进行了压缩。
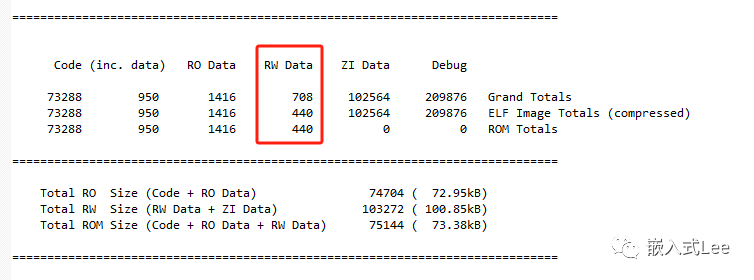
另外还可以看到ROM Totals一行也是要占用RW Data大小的ROM的,这里简单解释一下:
对于一个初始化的全局变量,比如
uint8_t v[10]=”111112222”
则v[10]这个数组本身是全局变量是在RW Data区域的即执行区域,但是他的初始化值”111112222”是存储在ROM中的即加载区域,毕竟这个初始化值不可能凭空产生必须存储在某个地方。由于有重复实际不需要完整的记录“111112222”这个串,记录5个1,4个2即(5,1)(4,2)这种形式即可,即可进行压缩。
过程概括来说就是:
链接时会对111112222压缩后放到ROM中,编译器自动产生的启动代码在main函数执行前__main执行时,读ROM中的数据解压,解压到执行区域RAM去。
上述压缩算法源码MDK是未公开的,后面我们会直接跟踪汇编代码来扒一扒其压缩算法,见下一篇。
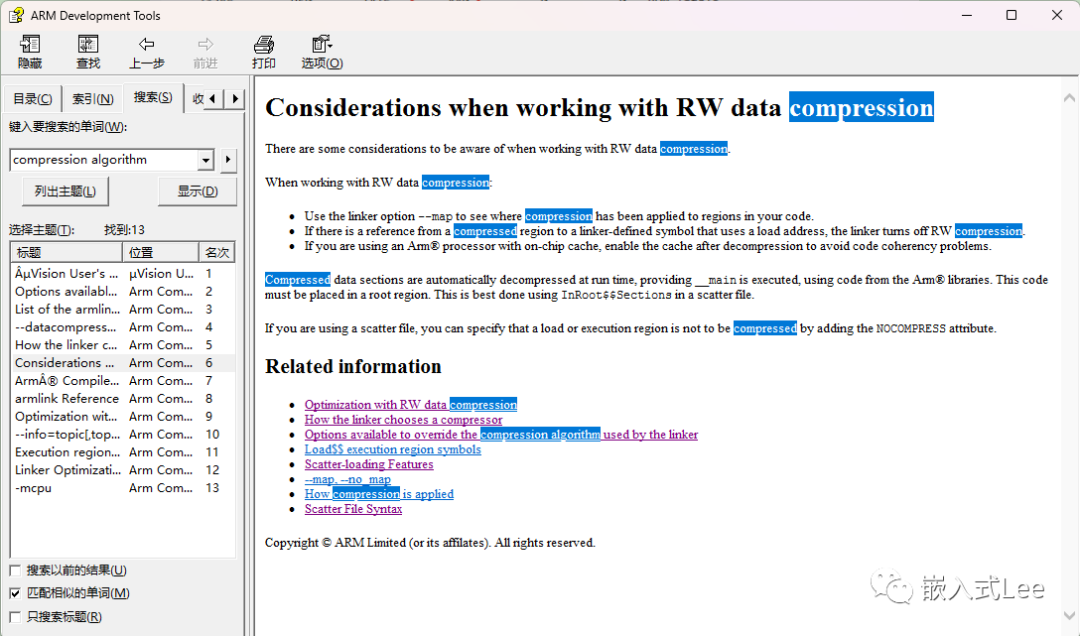
最好的资料肯定是来源于官方,所以我们去帮助文档中搜索compression algorithm
可以看到如下信息
这里是介绍使用RW data压缩时需要注意的地方
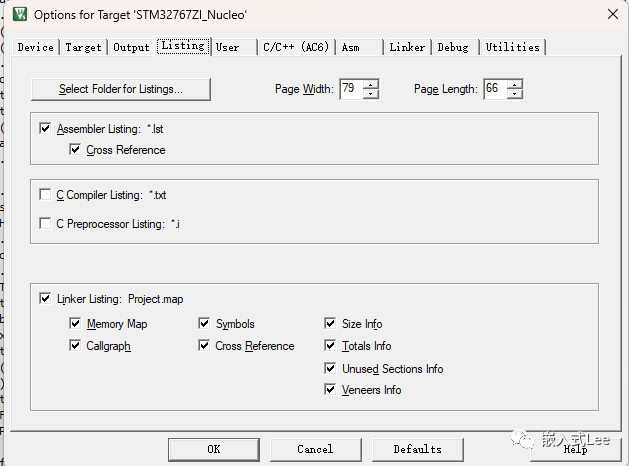
1.链接时使用--map(默认是使能的)可以查看哪些区域被压缩了,即上面看到的map文件中的RW Data区域。可以通过如下Linker Listing配置使能输出map文件,同时使能map文件包含的信息
2.如果使用了压缩区域相关加载地址的链接符号则不能使用压缩,因为压缩和解压之后加载地址不一样了,因为大小都变了。
3.如果使用的是带片上cache的Arm®处理器,在解压缩后再启用cache,以避免代码一致性问题。
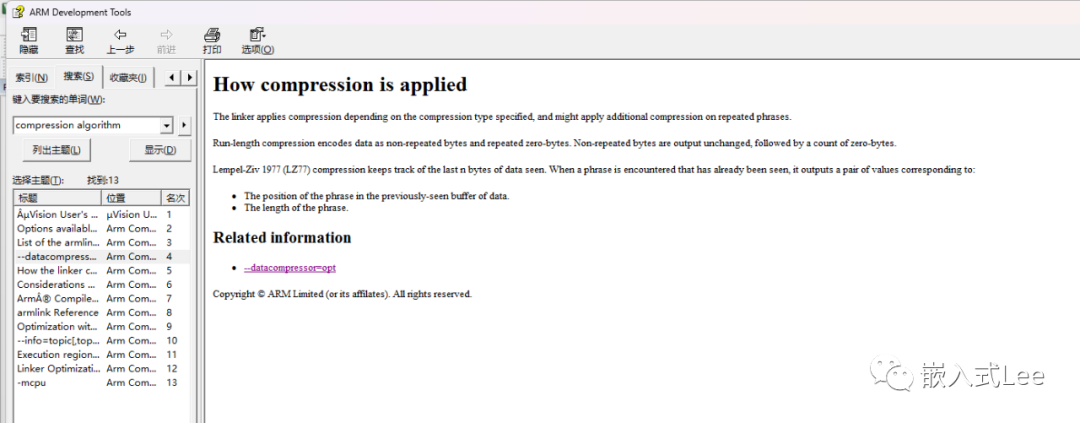
如下介绍了基本的压缩算法思想
1.链接器根据指定的压缩类型进行压缩,并可能对重复的内容应用额外的压缩。
2.使用RLE编码非重复字节和重复零字节,不重复的字节不变输出,后面跟着一个0字节计数。
3.使用Lempel-Ziv 1977 (LZ77)压缩算法,压缩最后n个字节的数据。当遇到一个已经见过的内容时,它记录以下信息:
在先前看到的该数据缓冲区中的位置。
该数据的长度。
如下介绍了,链接器如何自动选择是否压缩,压缩后的代码+解压代码本身小于压缩前代码时会自动压缩
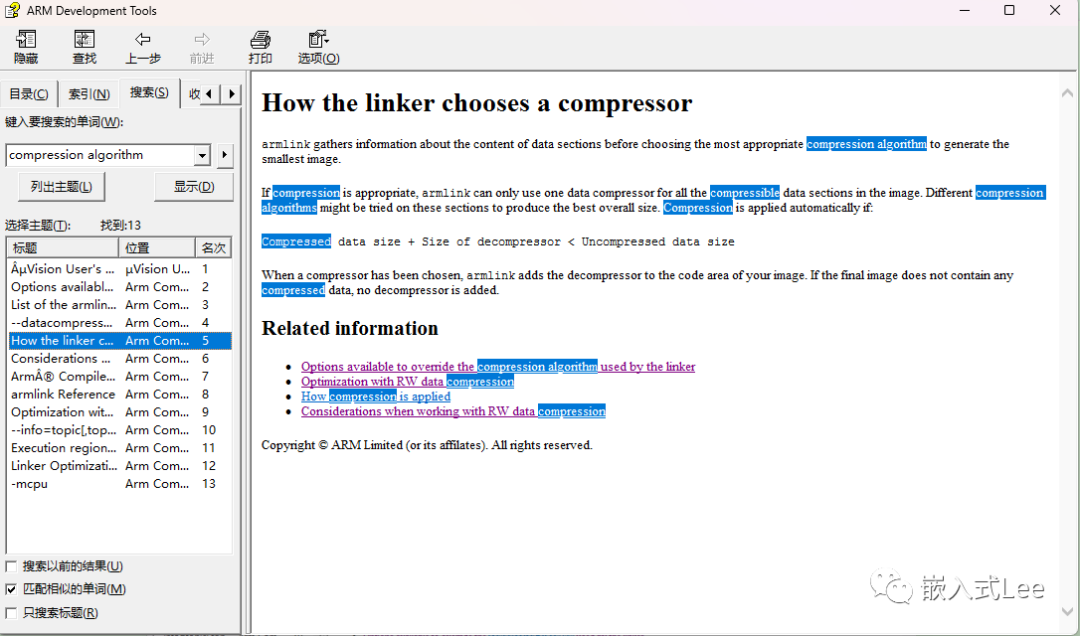
如下介绍了对RW Data的压缩
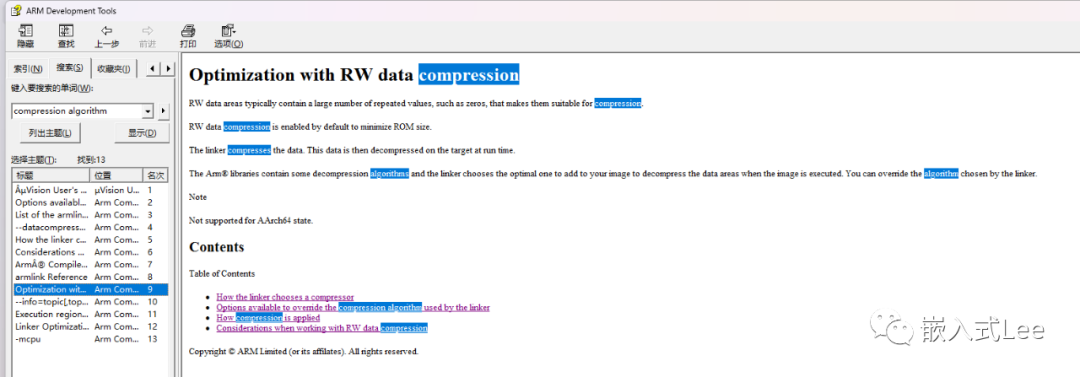
如下介绍了
如何关闭压缩:即使用链接选项--datacompressor off
如何指定压缩算法:即使用链接选项 --datacompressor 算法编号
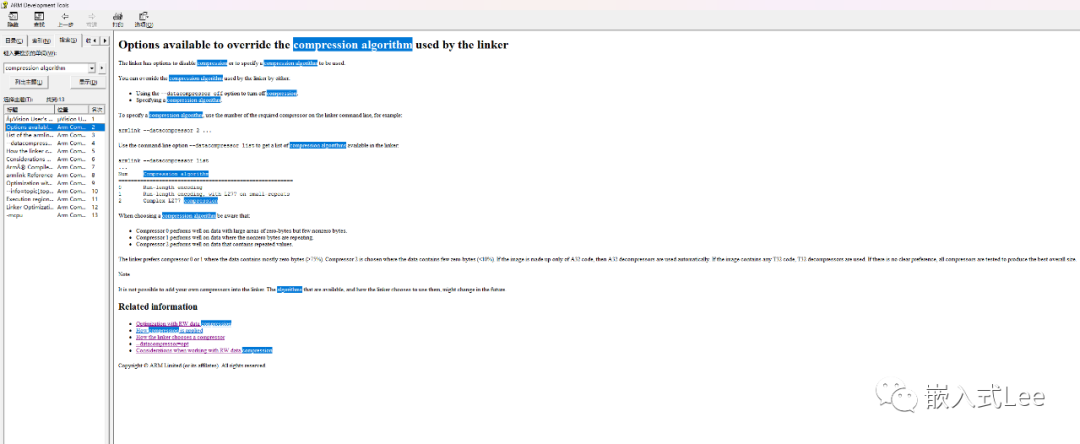
可以使用armlink --datacompressor list
查看支持的压缩算法
armlink位于D:\Keil_v5\ARM\ARMCLANG\bin
可以直接在该目录下执行命令./armlink.exe --datacompressor list查看
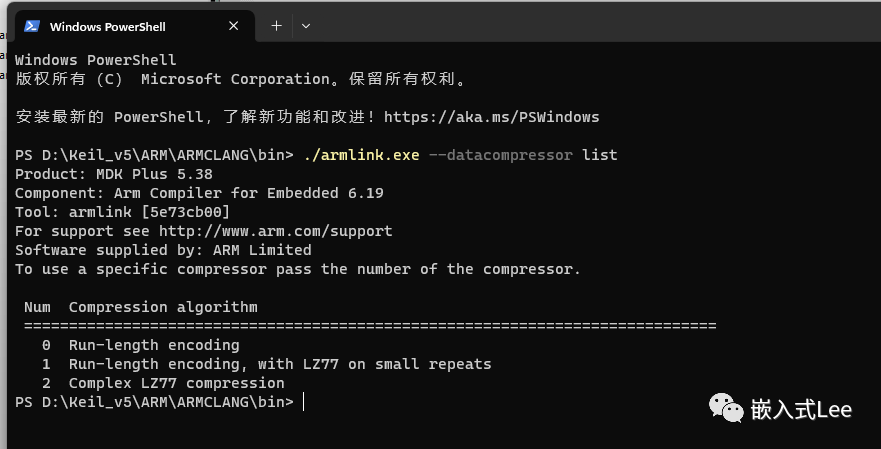
其中0适用于大量的0的情况,算法最简单
1适用于于有大量重复的数据,算法比前者复杂,使用了LZ77算法
2适用于随机的情况,使用了LZ77压缩算法
正常我们使用1即可,因为一般都是重复数据多,这样算法简单,满足大部分场景,效果也还可以。如果追求压缩效果可以使用2,但是注意2不一定比1压缩后更小的.
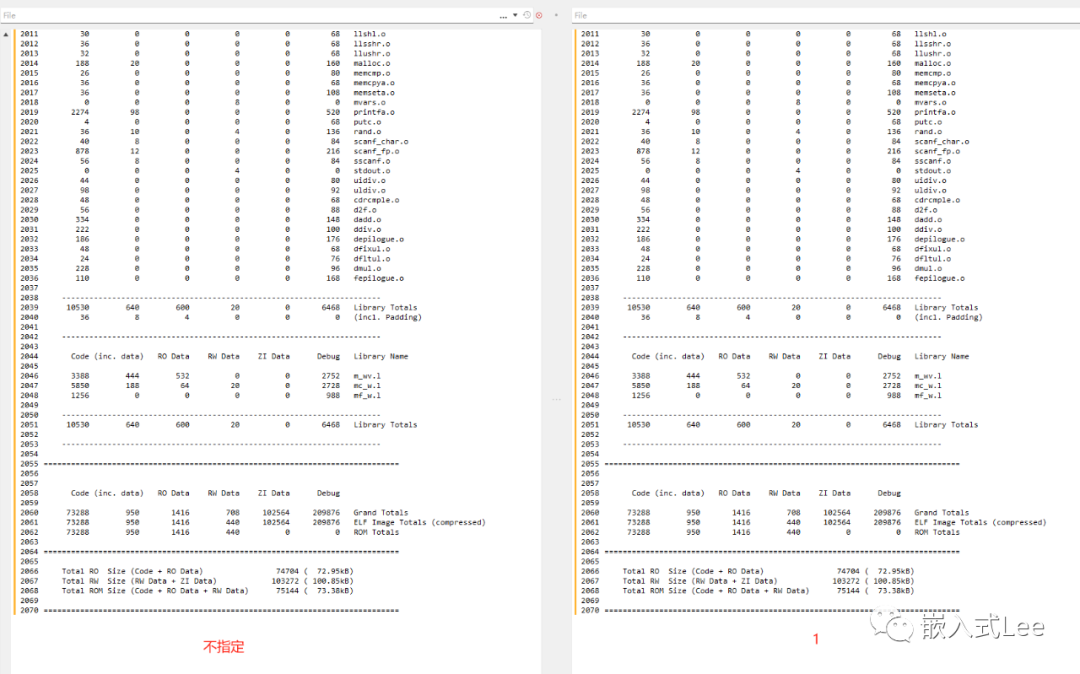
我们关闭压缩,看到RW Data就没有压缩了
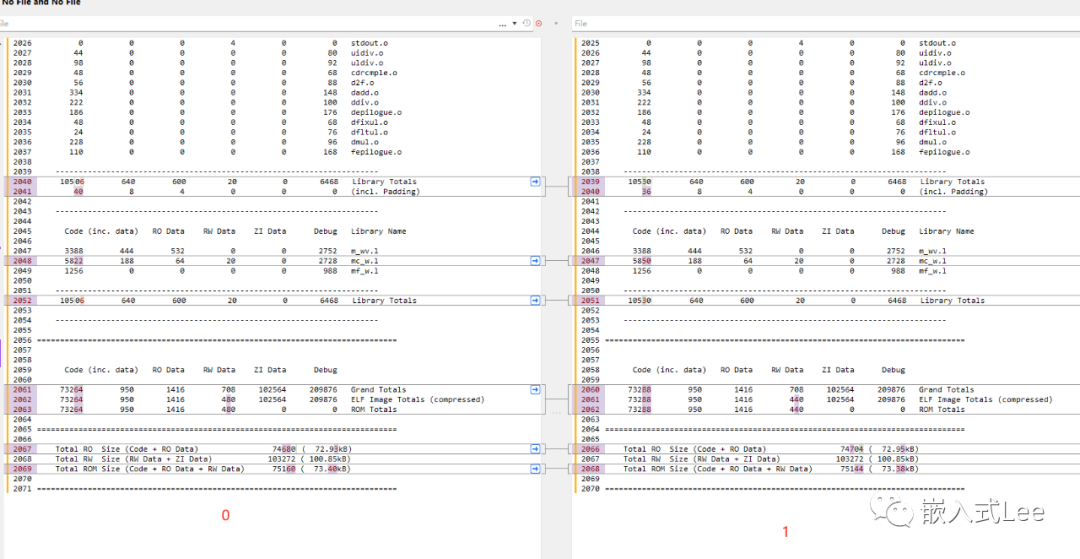
对比打开和关闭压缩
可以看到code变小了因为删除了解压代码,但是RW Data变大了。

我们设置不同的压缩算法
对比压缩算法0和1可以看到解压函数变了

对比镜像,压缩1算法和压缩0算法,代码增加,RW Data减小,整体镜像大小减小了。
对比压缩算法2和1,可以看到算法源码变了

可以看到算法2代码量变大了,但是RW Data也大了,所以不一定说算法2比算法1压缩后更小。
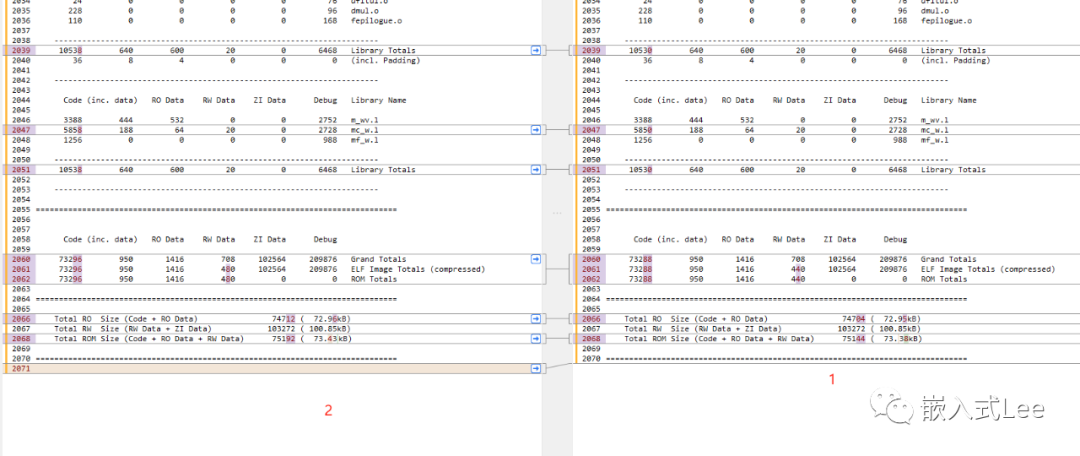
不手动指定压缩算法--datacompressor=n让连接器自己选
可以看到和--datacompressor=1完全一样,可以看到工具其实会自动选择最优的算法。
以上也可以看出算法1实际是能满足大部分情况且比较简单的。
上面介绍了基本思想
我们留在下一篇进行详解
1.MDK可以选择压缩算法优化镜像大小
2.压缩自动开,可以手动关,工具会自动选择最优算法。
3.MDK支持3种算法,分别针对简单的很多0的情况,很多重复值的情况,和一般情况,后两者基于LZ77算法。
其中方法1其实很有借鉴意义,满足大部分情况,效果还可以。前面在xmodem实现一文中预告了我们要实现自定义高效的文件传输协议,我们就会考虑借鉴该算法实现帧压缩来提高传输效率,此时需要综合考虑压缩大小和算法执行效率,不能选择复杂算法,否则在性能低的平台运行时间,反而大于压缩带来的减少的传输时间,这个后面再单独分享。
