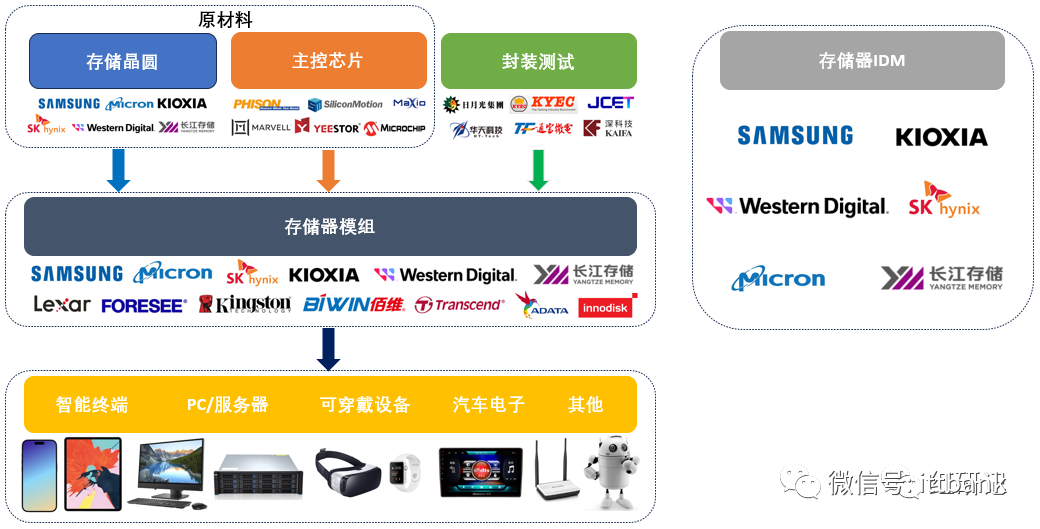
HBM产业链
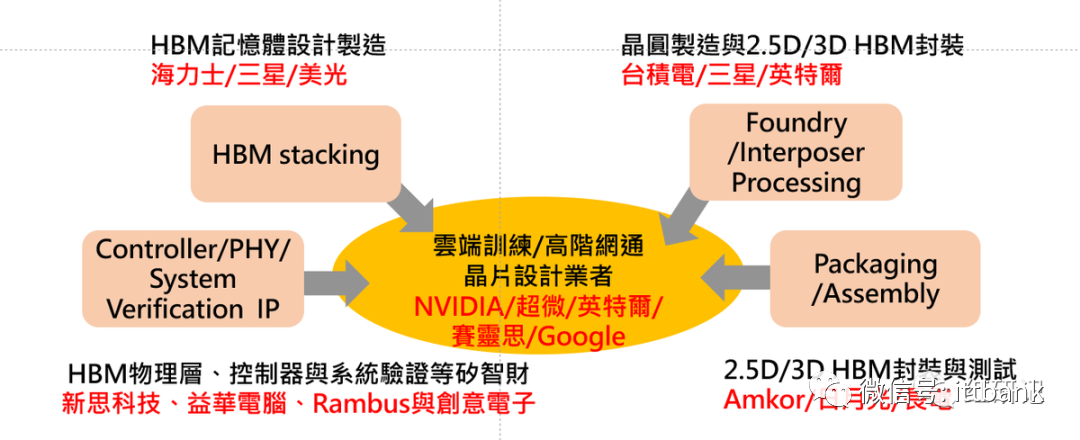
三大厂 HBM 产品规划总结
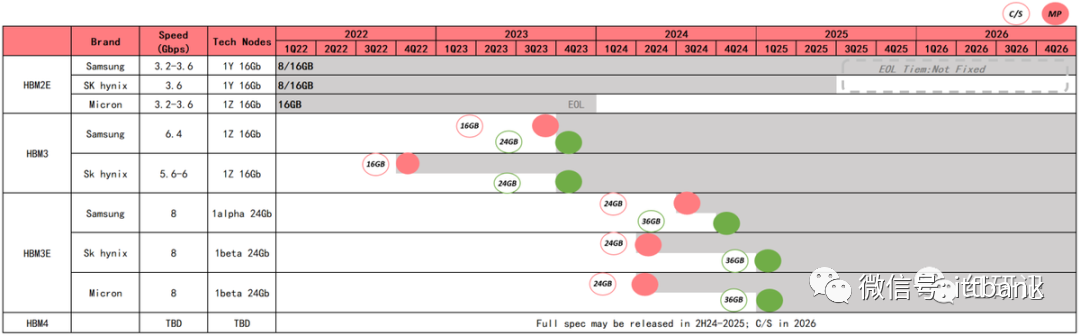
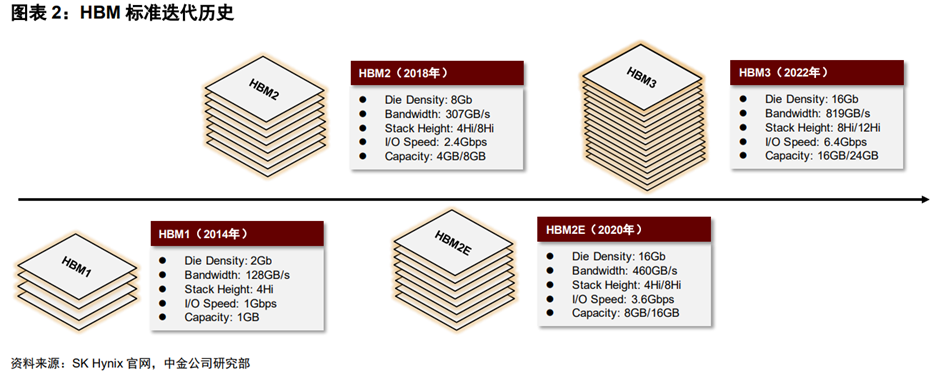
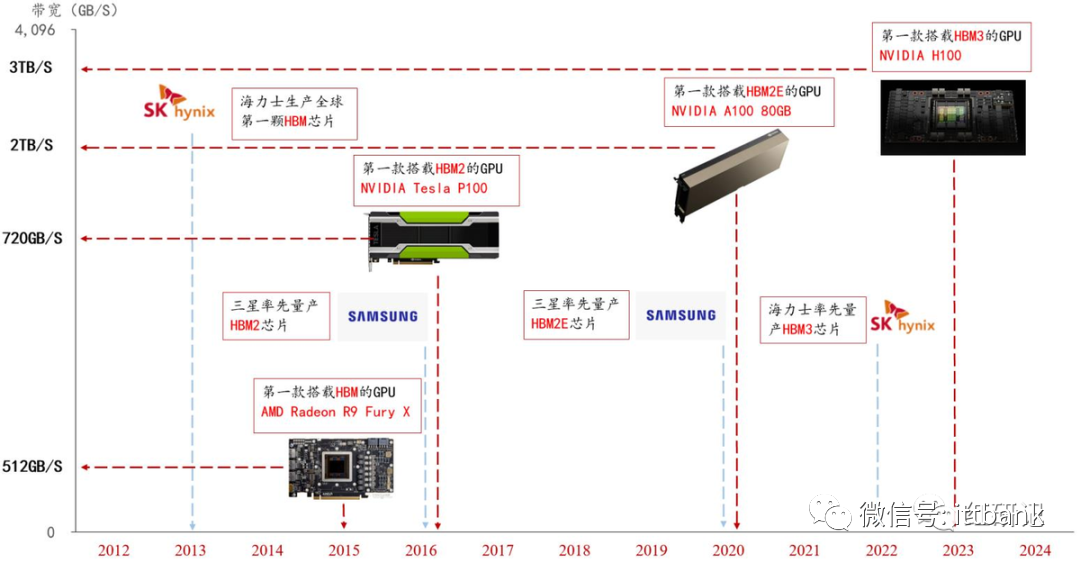
历代 HBM 性能持续提升,产品发布及量产时间线
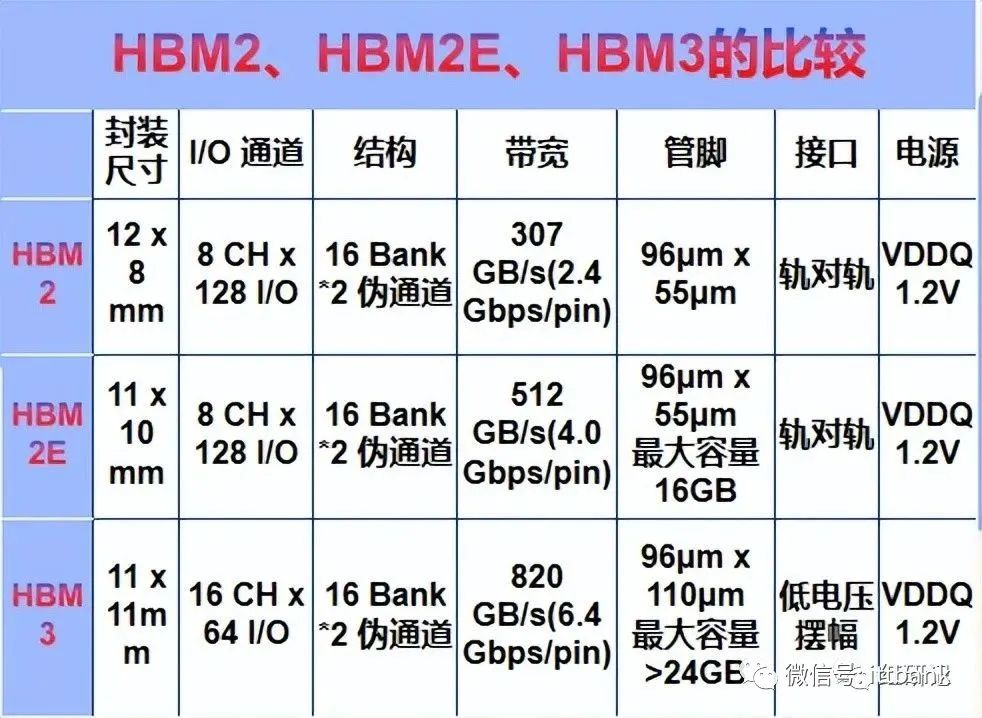

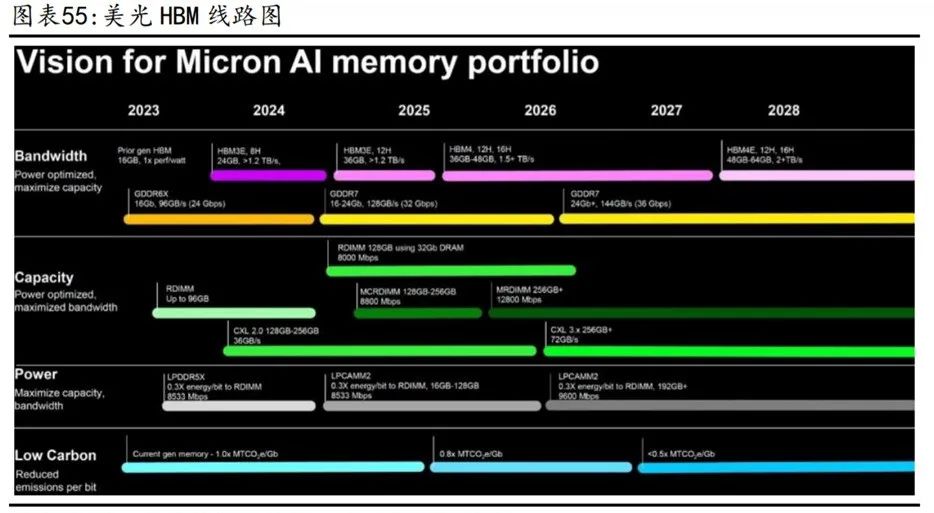
HBM发展线路图
历经多次迭代,性能多维提升。HBM拥有多达1024个数据引脚,显著提升数据传输能力。自2014年首款硅通孔HBM产品问世至今,HBM技术已经发展至第四代,HBM3带宽、堆叠高度、容量、I/O速率等较初代均有多倍提升。
HBM:2013年10月,JEDEC发布了第一个HBM标准JESD235A;2014年SK Hynix和AMD宣布联合开发TSV HBM产品;2015年6月,SK Hynix推出HBM1,采用4×2 Gbit 29nm工艺DRAM堆叠,该芯片被用于AMD GPU等产品。
HBM2:2018年11月,JEDEC发布了JESD235B标准,即HBM2技术,支持最多12层TSV堆叠;2018年Samsung率先推出Aquabolt(HBM2),数据带宽3.7GB/s。SK Hynix紧随其后推出HBM2产品,采用伪通道模式优化内存访问并降低延迟,提高有效带宽。
HBM2E:2020年1月,JEDEC更新发布HBM技术标准JESD235C,并于2021年2月更新为JESD235D,即HBM2E;2019年,三星推出Flashbolt(HBM2E),堆叠8个16 Gbit DRAM芯片。SK Hynix在2020年7月推出了HBM2E产品,是当时业界速度最快的DRAM解决方案。目前HBM2e是HBM市场的主流产品。
HBM3:2022年1月,JEDEC发布了HBM3高带宽内存标准JESD238,拓展至实际支持32个通道,并引入片上纠错(ECC)技术;SK Hynix在2021年10月开发出全球首款HBM3,容量为HBM2E的1.5x,运行带宽为HBM2E的2x。
HBM3E:8月21日,SK海力士宣布,公司开发出面向AI的超高性能DRAM新产品HBM3E,并开始向客户提供样品进行性能验证。据介绍,SK海力士将从明年上半年开始投入HBM3E量产。此次产品在速度方面,最高每秒可以处理1.15TB(太字节)的数据,其相当于在1秒内可处理230部全高清级电影。

HBM下游应用市场
HBM的优缺点
(1)对比GDDR,HBM的优势
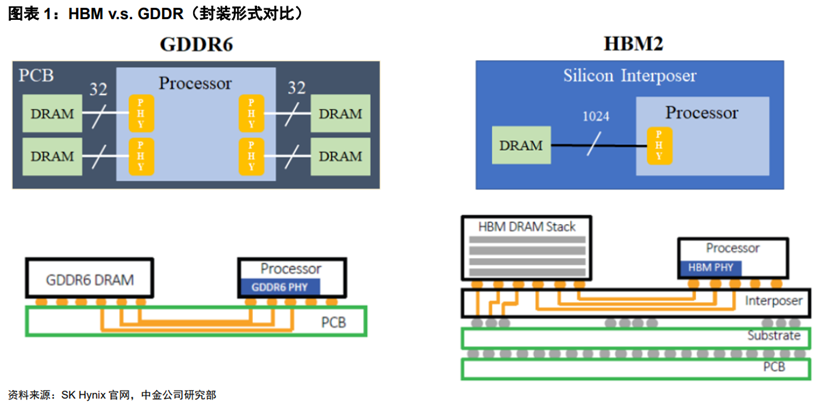
GPU的主流存储方案有GDDR和HBM两种。但图形芯片性能的日益增长,使其对高带宽的需求也不断增加。随着芯片制程及技术工艺达到极限,GDDR满足高带宽需求的能力开始减弱,且单位时间传输带宽功耗也显著增加,预计将逐步成为阻碍图形芯片性能的重要因素。
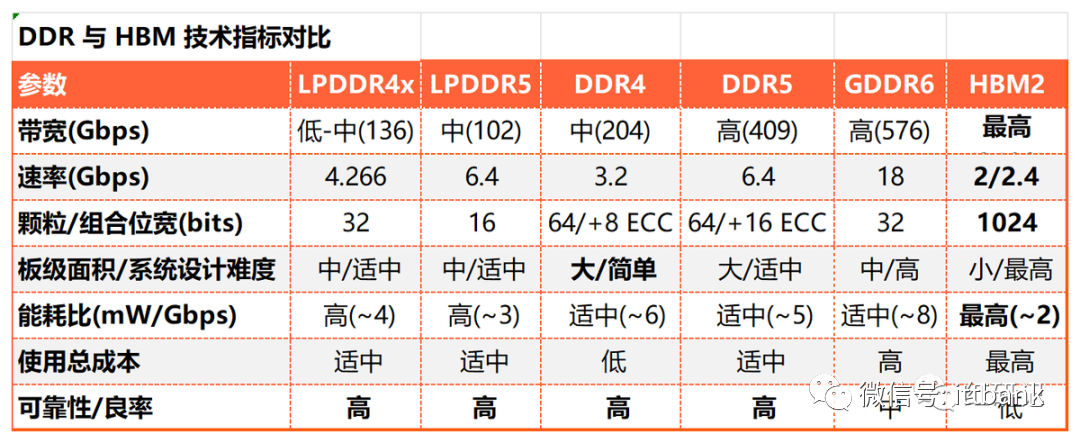
显存的重要性能指标有3个:显存频率(800MHz、1,200MHz、1,600MHz、2,200MHz)、显存位宽(32位、64位、128位、256位、512位、1,024位)、显存带宽(显存带宽=显存频率×显存额位宽/8bit)。通过TSV堆栈的方式,HBM能达到更高的I/O数量,使得显存位宽达到1,024位,几乎是GDDR的32x,HBM具有显存带宽显著提升,此外还具有更低功耗、更小外形等优势。显存带宽显著提升解决了过去AI计算“内存墙”的问题,HBM逐步提高在中高端数据中心GPU中的渗透比率。
(2)相较于其他种类的内存缺点
HBM相较于其他种类的内存也并非没有缺点,成本偏高、频率偏低使得其基本上目前只应用于中高端数据中心GPU及少数ASIC:
1)缺乏灵活性,HBM与主芯片通常封装在一起,不存在扩容可能。DDR产品形态稳定、标准化程度高,HBM封装的低灵活性对OEM厂商成本带来困难。虽然消费者市场对拓展性要求不搞(如Intel Lakefield、Apple M1),但目前HBM的成本使之望而却步。
2)HBM容量偏小,一些高阶的服务器DIMM达到96个,采用128GB RDIMM最多能达到12TB,HBM8层die也不过32GB,再结合成本考虑,更加无法满足数据中心要求。
3)访问延迟高,HBM的频率低于DDR/GDDR(由TSV封装决定,并行线路多时频率过高会有散热问题),CPU处理的任务具有较大的不可预测性,对延迟的敏感程度较高,而在GPU则对此并不敏感。
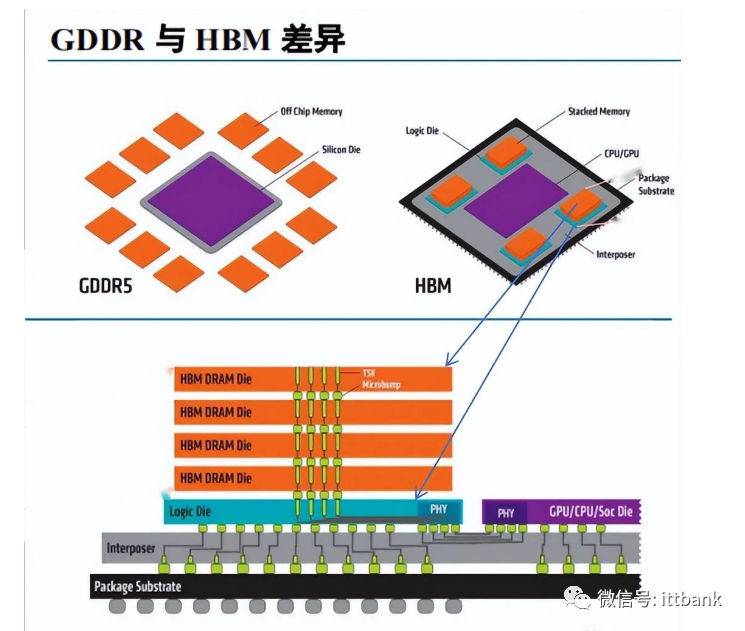
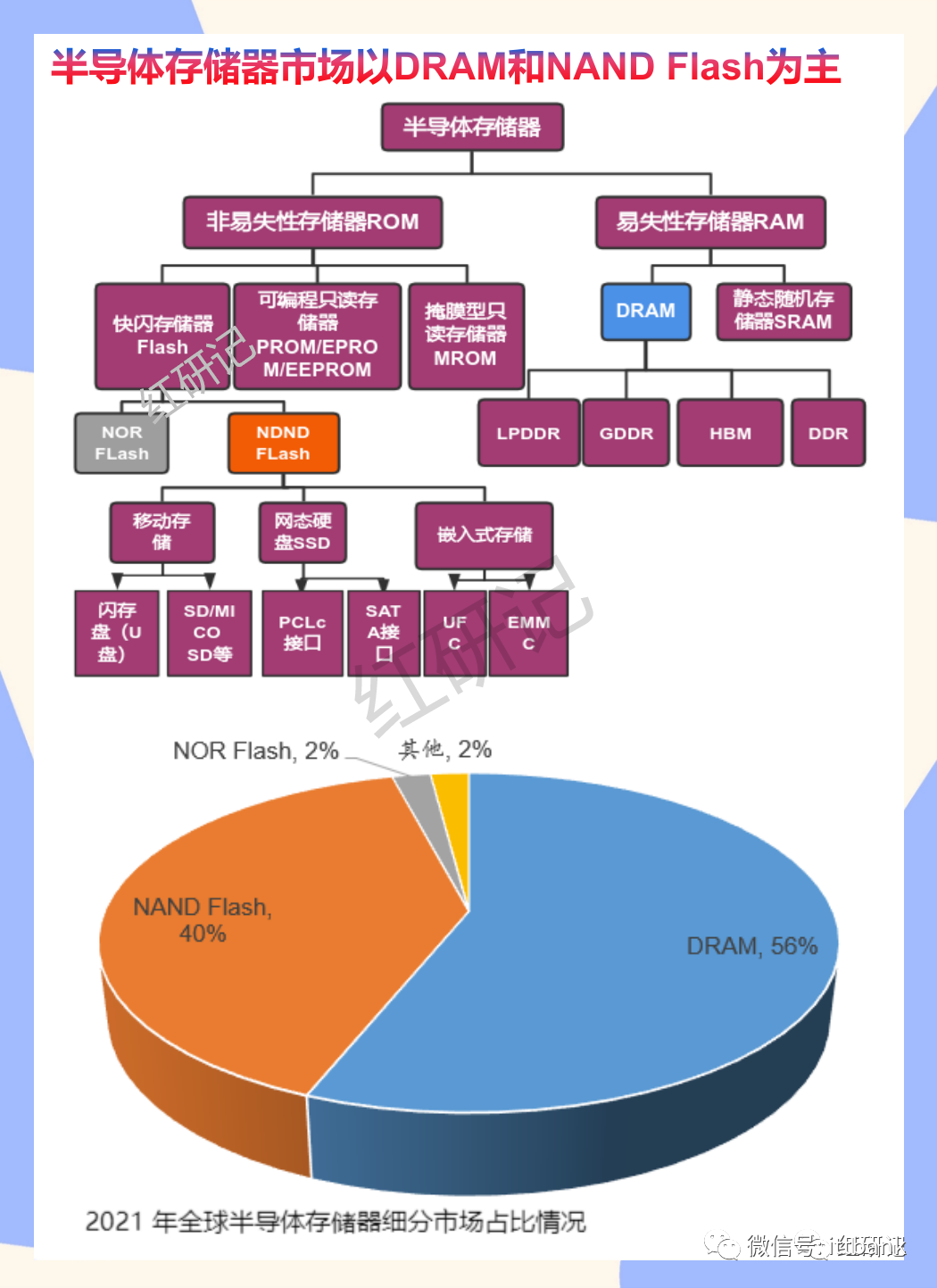
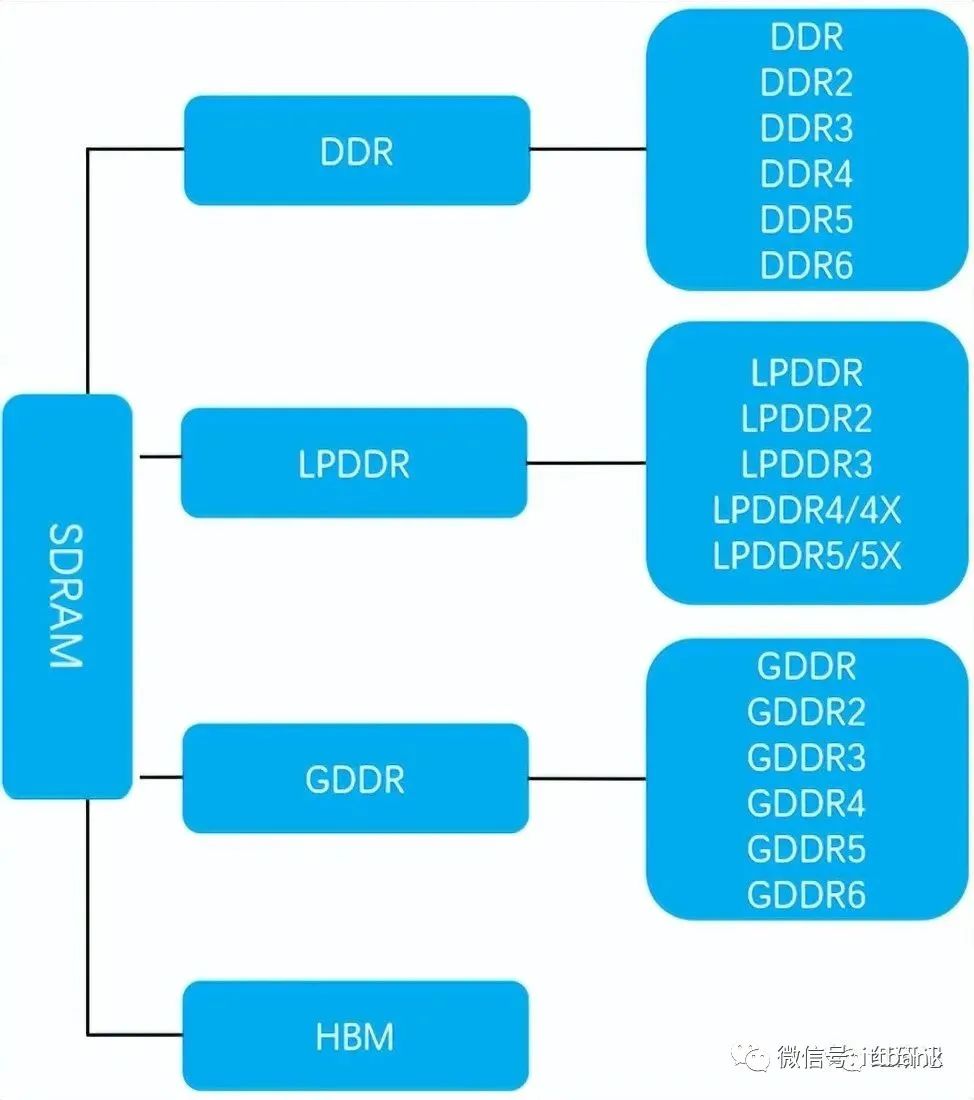
22年以前HBM在内储中,占比不到1%,所以,HBM其实是GDDR的替代品,是将DDR芯片堆叠在一起后和GPU封装在一起,实现大容量,高位宽的DDR组合阵列。听起来有点复杂,看下面这张图就一目了然了。
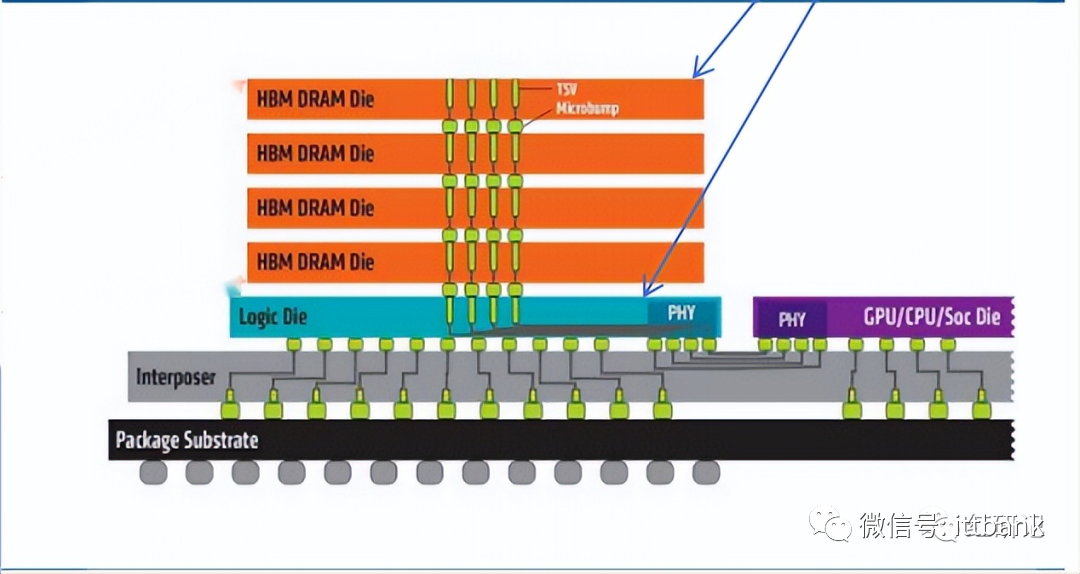
GDDR作为独立封装,在PCB上围绕在处理器的周围,而HBM则排布在硅中阶层(Silicon Interposer)上并和GPU封装在一起,面积一下子缩小了很多,举个例子,HBM2比GDDR5直接省了94%的表面积。并且,HBM离GPU更近了,这样数据传输也就更快了。
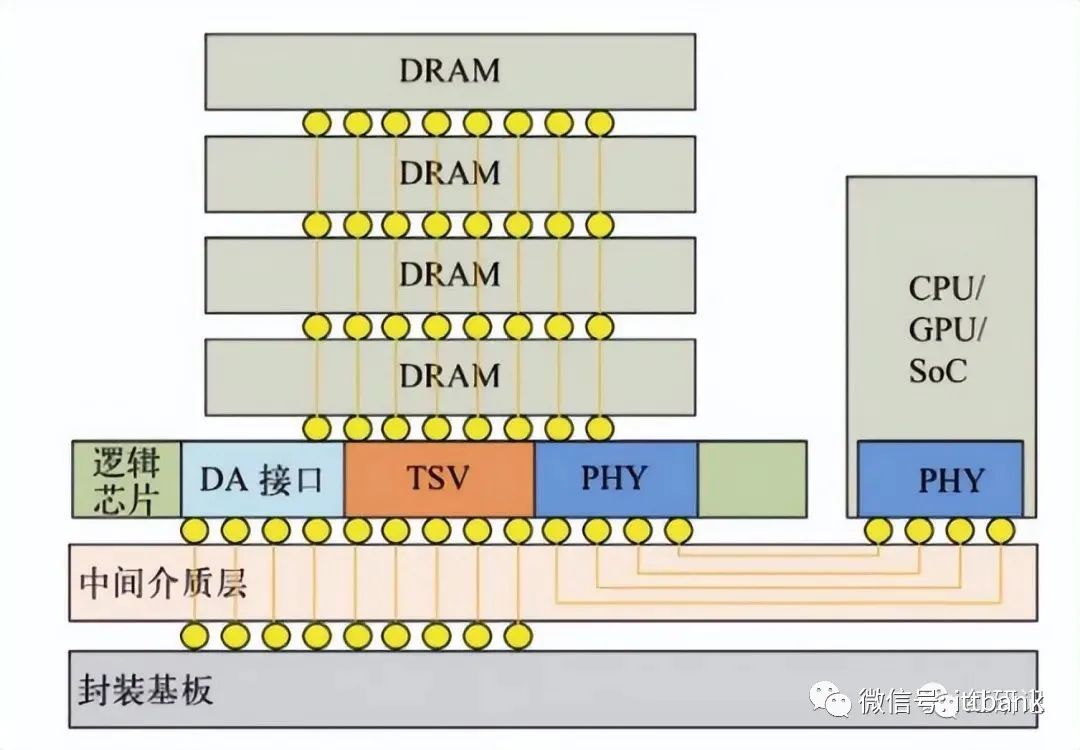
HBM堆叠结构

HBM实物剖面结构
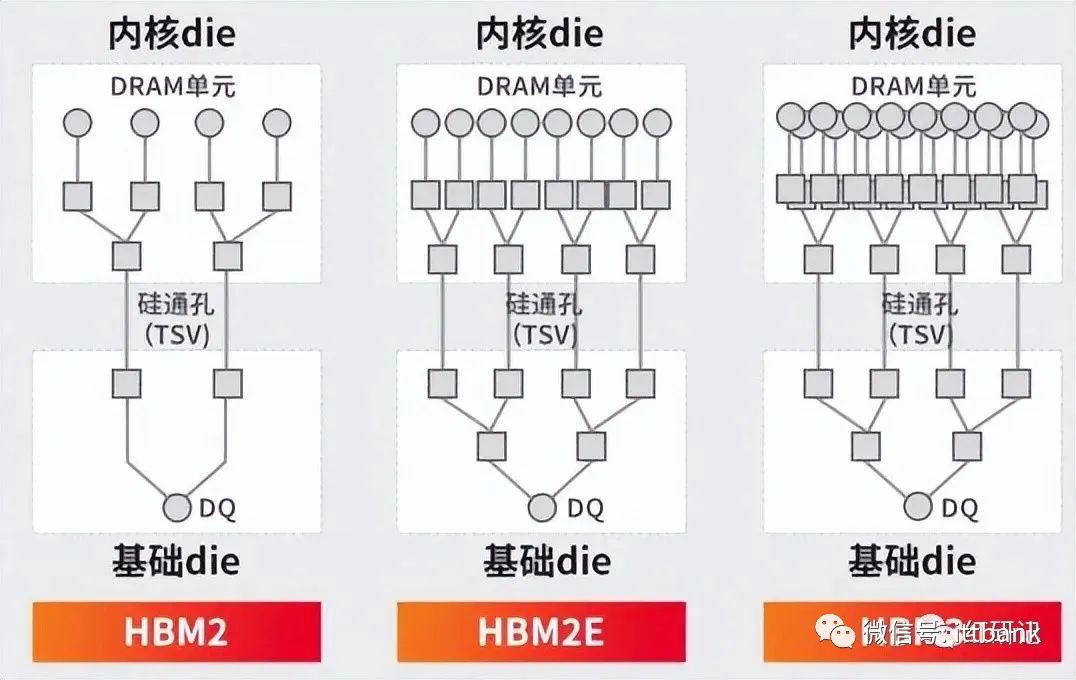
HBM 数据传输线路的数量大幅提升
DDR 与 HBM 技术指标对比
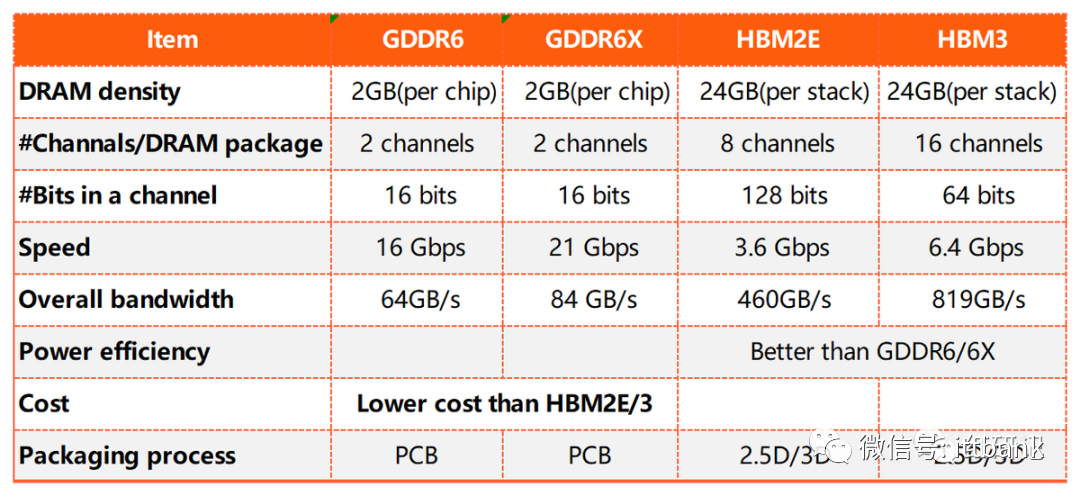
HBM与其他几种内存方案的参数对比

HBM 正在成为 AI 服务器 GPU 的标配。AI服务器需要在短时间内处理大量数据,对带宽提出了更高的要求,HBM 成为了重要的解决方案。AI 服务器 GPU 市场以 NVIDIA H100、A100、A800 以及AMD MI250、MI250X系列为主,基本都配备了 HBM。HBM 方案目前已演进为较为主流的高性能计算领域扩展高带宽的方案。
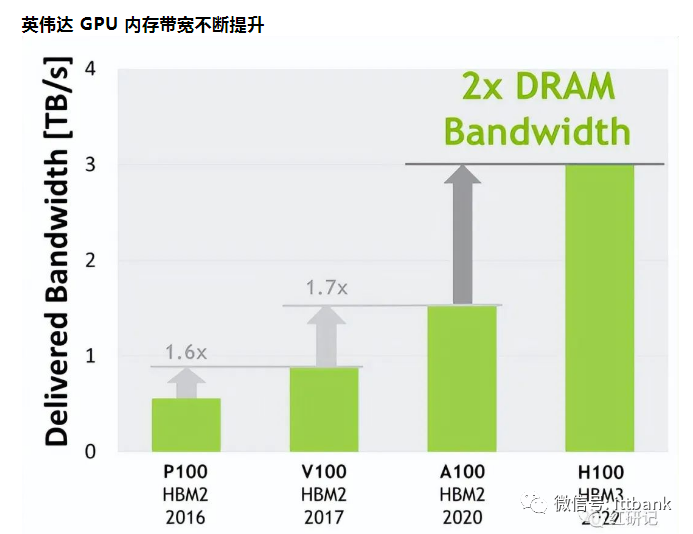
近日英伟达发布全新H200 GPU及更新后的GH200产品线。相比H100,H200首次搭载HBM3e,运行大模型的综合性能提升60%-90%。
H200 GPU内含6个HBM3e内存,总容量达141GB,总带宽为4.8 TB/s。

相比H100(采用HBM3,容量80GB,带宽为3.35 TB/s)H200在容量上提升76%,在带宽上提升+43%。同时,H200 GPU在FP16/32/64等算力性能无显著提升。在大模型的运行上,H200相比H100将带来60%(GPT3 175B)到90%(Llama 2 70B)的提升。H200性能提升主要由于存储端的架构优化,“存储墙”问题或为制约AI性能之短板。
而作为加速计算领域追赶者的AMD,其最新发布的MI300X GPU搭载容量高达192GB 的HBM3 显存,为H100 的 2.4倍,其内存带宽达 5.2TB/s,为H100 的 1.6倍,HBM正成为HPC军备竞赛的核心。

从成本的角度来看,HBM 虽然价格远高于普通DRAM,但相对于同样靠近处理器的SRAM价格更低。特斯拉Dojo 的 D1 芯片拥有354 个核心440MB 的 SRAM,每 MB SRAM 成本约 15-20美元,仅此单项成本就接近9000 美元,而最新发布的AMD 的MI300X HBM 的成本约为5760-7680美元。
虽然 SRAM 带宽能够达到800GB/s,但由于容量太低,不适合 ChatGPT 这样的大模型,Dojo依然需要搭配 HBM 使用。
CPU 搭配 HBM 先河已开,配合 DDR 提供灵活计算方案。通常认为CPU 处理的任务类型更多,且更具随机性,对速率及延迟更为敏感,HBM 特性更适合搭配 GPU 进行密集数据的处理运算。2022年底,英特尔正式推出全球首款配备HBM 内存的x86 CPU:IntelXeon Max 系列。
该 CPU 具有 64GB 的 HBM2e 内存,分为4个16GB的集群,总内存带宽达1TB/s。在MLPerfDeepCAM 训练中,XeonMax 系列CPU 的AI 性能比AMD 7763 提升了 3.6倍,比NVIDIA 的 A100 提升了 1.2 倍。Xeon Max系列支持三种不同的运算模式:仅HBM 模式、HBM 平面(1LM)模式和 HBM 缓存模式,其中 HBM 平面模式和 HBM 缓存模式为搭配DDR5 的方案。考虑到HBM 的内存带宽大但容量相对小,而 DDR 一般容量相对大但内存带宽小,根据不同场景将 DDR和 HBM 搭配使用,可提供更为灵活的内存运算形式。
随着高端GPU需求的逐步提升,TrendForce集邦咨询预估2023年HBM需求量将年增58%,2024年有望再成长约30%。
除了AI服务器,汽车也是HBM值得关注的应用领域。汽车中的摄像头数量,所有这些摄像头的数据速率和处理所有信息的速度都是天文数字,想要在车辆周围快速传输大量数据,HBM具有很大的带宽优势。但是最新的HBM3目前还没有取得汽车认证,外加高昂的成本,所以迟迟还没有“上车”。不过,Rambus的高管曾提出,HBM绝对会进入汽车应用领域。
AR和VR也是HBM未来将发力的领域。因为VR和AR系统需要高分辨率的显示器,这些显示器需要更多的带宽来在 GPU 和内存之间传输数据。而且,VR和AR也需要实时处理大量数据,这都需要HBM的超强带宽来助力。
此外,智能手机、平板电脑、游戏机和可穿戴设备的需求也在不断增长,这些设备需要更先进的内存解决方案来支持其不断增长的计算需求,HBM也有望在这些领域得到增长。并且,5G 和物联网 (IoT) 等新技术的出现也进一步推动了对HBM 的需求。
不过,目前来讲,HBM还是主要应用于服务器、数据中心等领域,消费领域对成本比较敏感,因此HBM的使用较少。
可以肯定的是,对带宽的要求将不断提高,HBM也将持续发展。
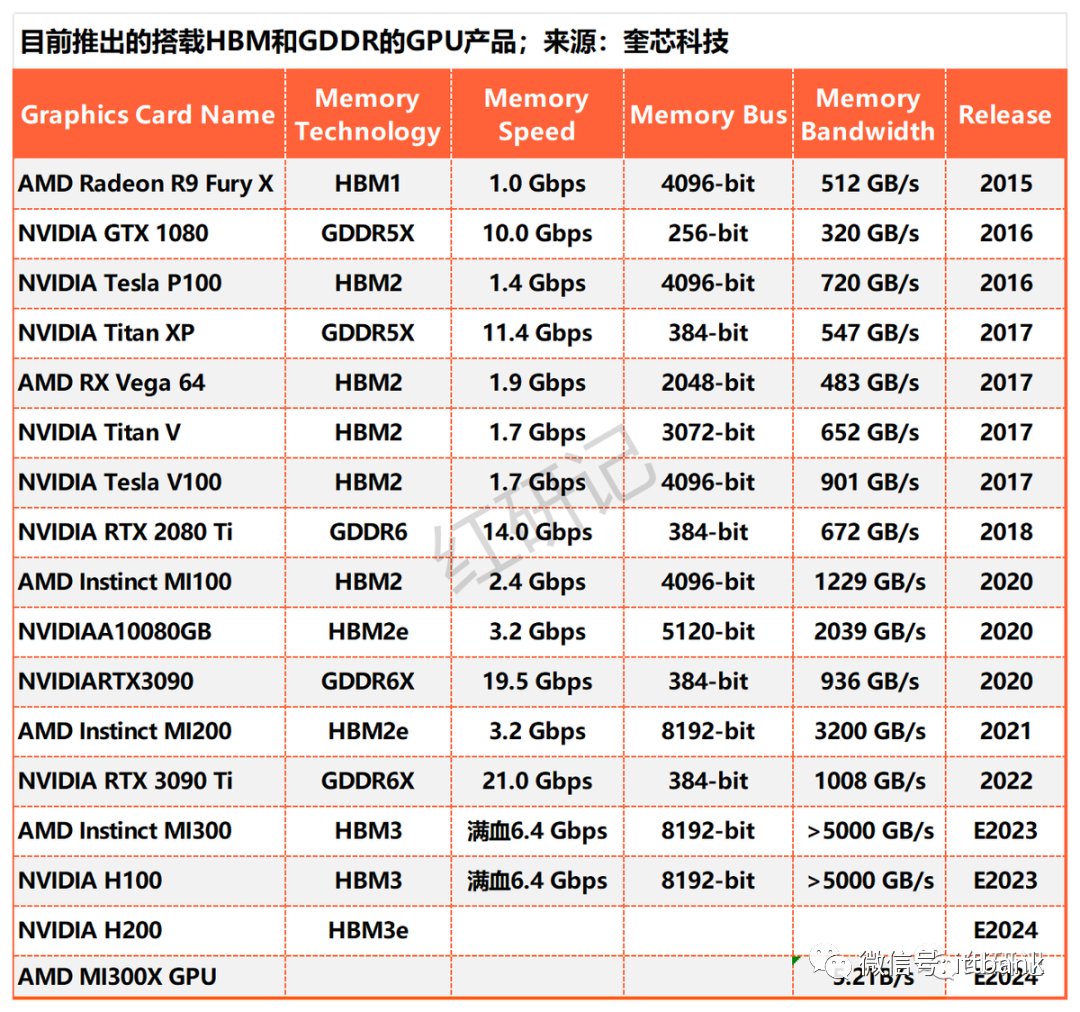
目前推出的搭载 HBM 和 GDDR 的 GPU产品
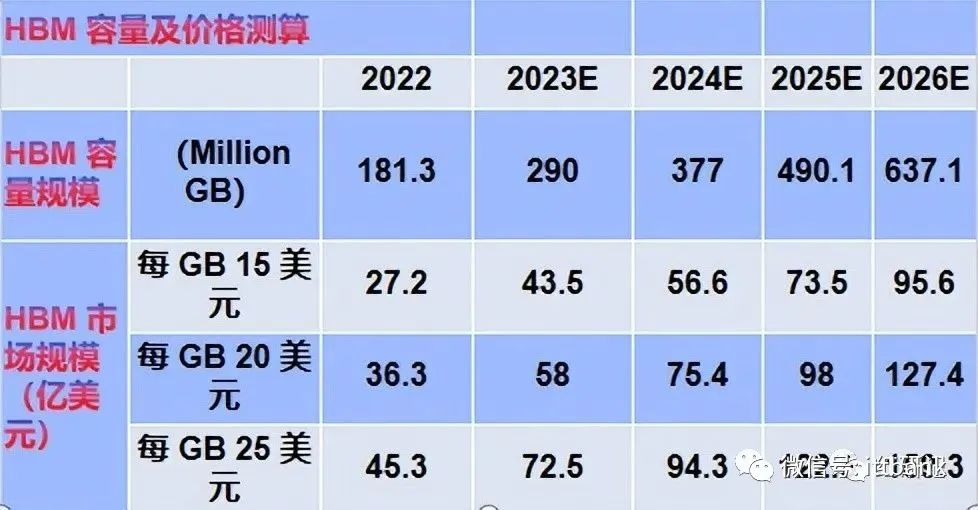
全球 HBM 市场规模预测
根据TrendForce,先进 AI服务器 GPU 搭载 HBM 芯片已成主流。根据TrendForce,2022年全球HBM容量约为1.8亿GB,2023年增长约60%达到 2.9亿GB,2024年将再增长30%。我们以HBM每GB售价20美元测算,2022年全球HBM 市场规模约为36.3 亿美元,预计至 2026年市场规模将达127.4亿美元,对应CAGR约37%。
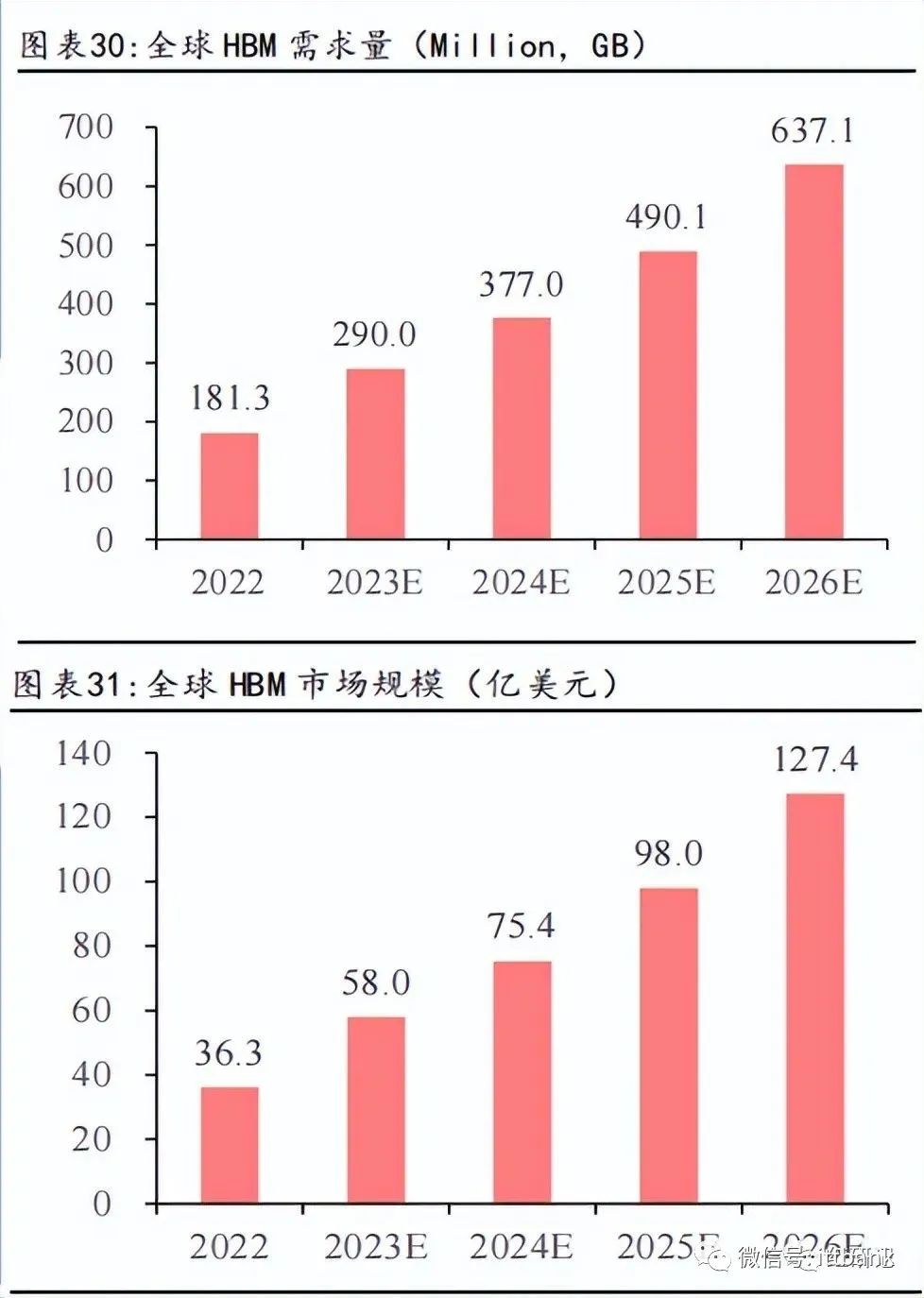
市场调研机构Omdia预测,2025年HBM市场的总收入将达到25亿美元。据新思界发布的分析报告显示,预计2025年中国HBM需求量将超过100万颗。(不同的机构预测不一样,有矛盾,我们主要还是看大趋势)
IDC数据显示,2019年中国AI加速服务器单机 GPGPU 搭载量最多达到20颗,加权平均数约为8颗/台。单颗 GPU 配套的 HBM 显存存储容量达到80GB,对应价值量约为800美元。
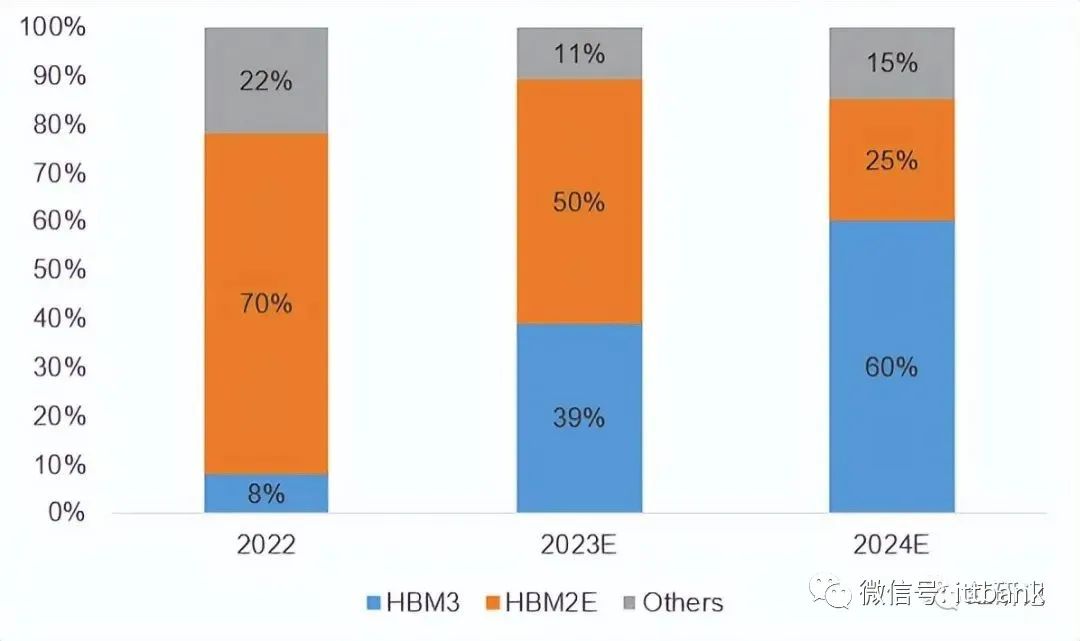
2022-2024 年各代 HBM 产品市场需求占比情况
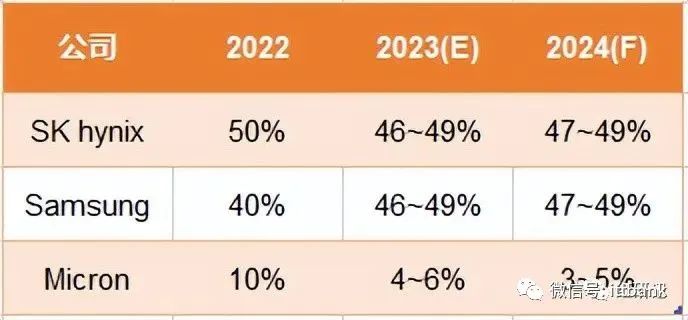
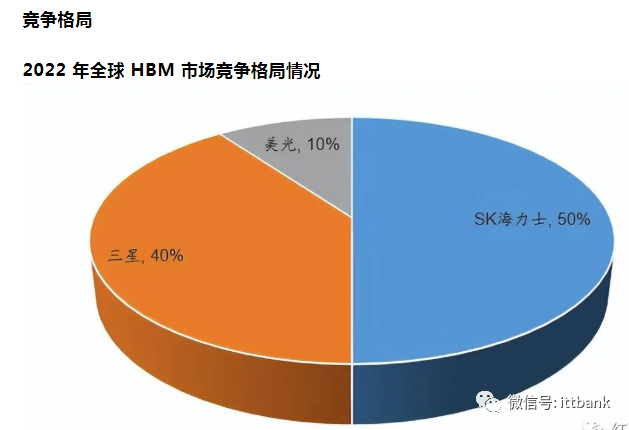
HBM主要供应商市占率变化预测
HBM三大原厂生产规划
1、SK海力士:技术领先,核心在于MR-MUF技术
SK海力士技术领先,核心在于MR-MUF技术。HBM2及之前代次产品,DRAM Die之间键合的主要方式是基于热压键合的TC-NCF,但受限于材料流动性以及bump数量限制存在导热以及其他工艺缺陷等问题。MR-MUF是海力士的高端封装工艺,通过将芯片贴附在电路上,在堆叠时,在芯片和芯片之间使用液态环氧树脂塑封填充并粘贴。对比NCF,MR-MUF能有效提高导热率,并改善工艺速度和良率。
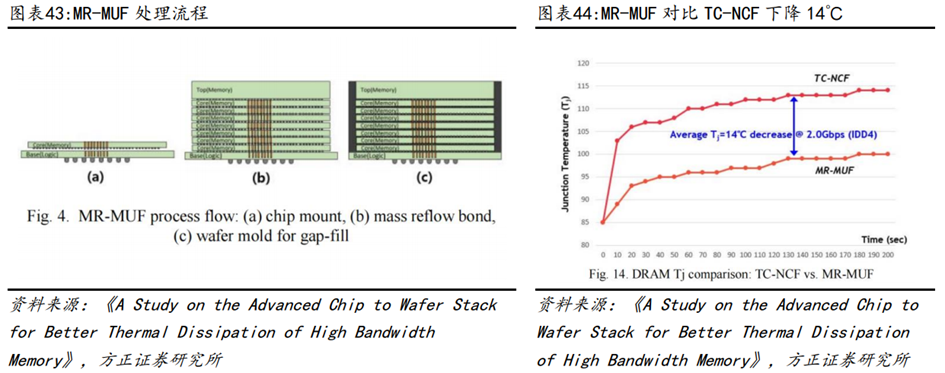
MR-MUF工艺的核心难点在于堆叠芯片过程中产生的热翘曲问题(LMC与硅片之间的热收缩差异导致),以及芯片中间部位的空隙难以填充。LMC是SK海力士HBM产品的核心材料,本身具备可中低温固化、低翘曲、模塑过程无粉尘、低吸水率以及高可靠性等优点,通过大量的材料配方调试及热力学验证解决热收缩差异问题。另一方面,通过改变EMC与芯片的初始对齐方式以及图案形状有效解决了填充存在缝隙的问题。
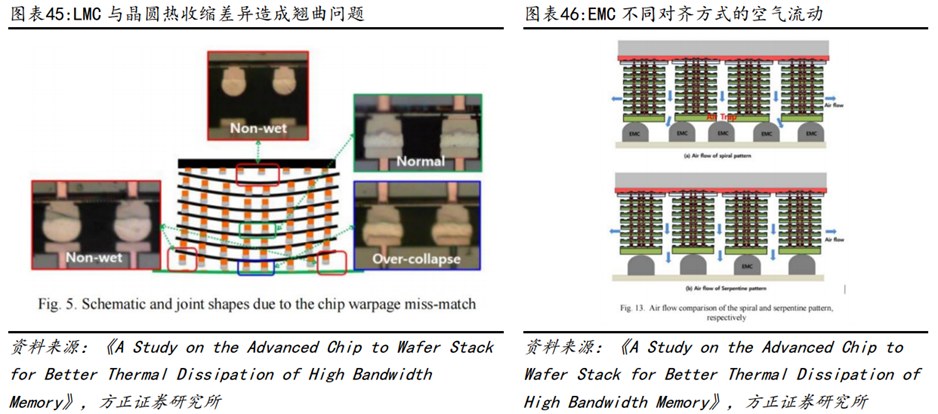
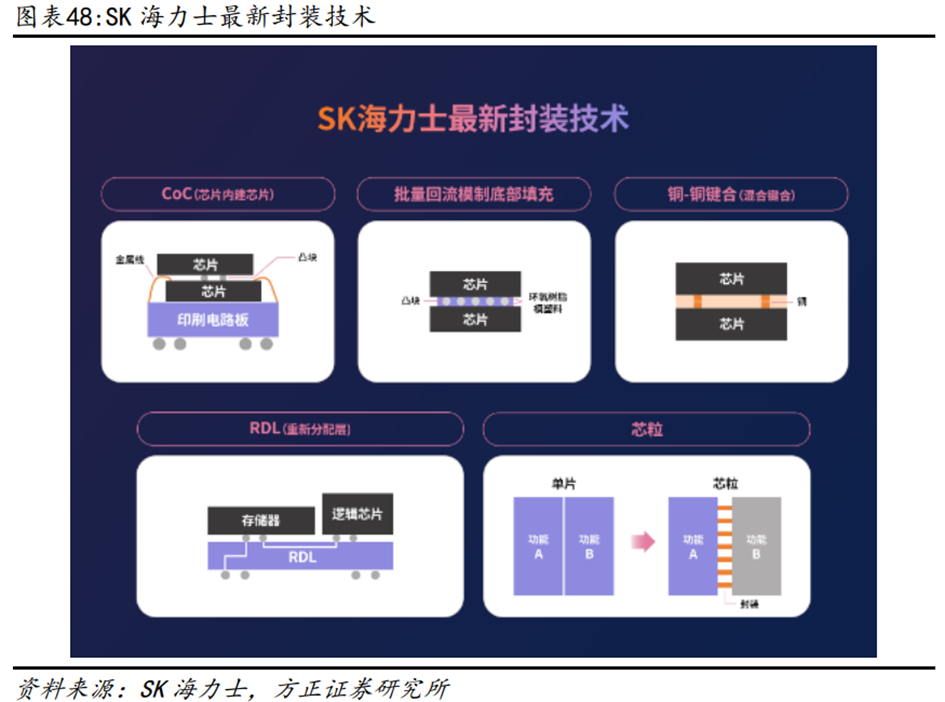
除了MR-MUF技术,SK海力士还在积极布局各种封装技术,包括混合键合(Hybrid Bonding)以及Fan-out RDL(扇出型重新分配层)等多项技术。其中,混合键合技术是指采用Cu-to-Cu(铜-铜)键合替代传统焊接,进一步缩小间距,同时作为一种无间隙键合(Gapless Bonding)技术,在芯片堆叠时不使用焊接凸块(Solder Bump),因此在封装高度上更具优势。扇出型RDL技术适用于多个平台,SK海力士计划将该技术用于Chiplet为基础的集成封装。线间距(Line Pitch)和多层(Multi-Layer)是扇出型技术的关键,SK海力士计划2025年将确保1微米以下或亚微米(Sub-micron)级水平的RDL技术。
SK海力士于21年10月即发布HBM3,并于2022年6月正式量产,23年4月,SK海力士实现了全球首创的12层硅通孔技术垂直堆叠芯片,容量达到24GB,比上一代HBM3高出50%,并且具备了ECC校检(On Die-ErrorCorrection Code)功能,可以自动修正DRAM单元(cell)传输数据的错误,从而提高了产品的可靠性。此外,SK海力士计划在今年年底前提供HBM3E样品,并在2024年开始量产,公司将HBM4的生产目标定在了2026年。
2、三星:万亿韩元新建封装线,预计25年量产HBM4
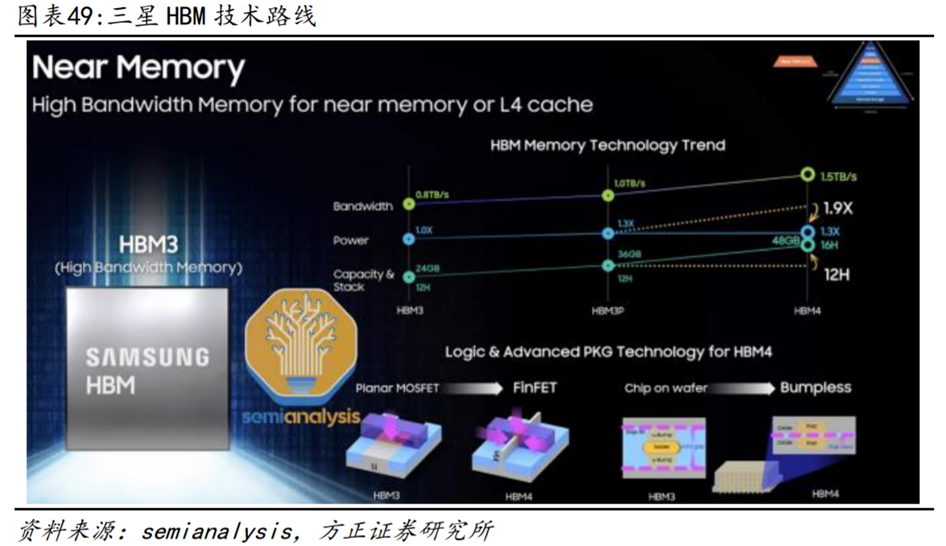
万亿韩元新建封装线,预计25年量产HBM4。为了应对HBM市场的需求,三星电子已从三星显示(Samsung Display)购买了天安厂区内的部分建筑物和设备,用于建设新的HBM封装线,总投资额达到7000-10000亿韩元。三星电子预计在新的封装线上大规模生产HBM,并且正在投入量产8层、12层的HBM3产品。三星预计将在2023年Q4开始向北美客户供应HBM3,HBM3销售额在三星DRAM总销售额占比预计将从2023年的6%提升到2024年的18%,并将在2023下半年推出具有更高性能和更大容量的HBM3P,目前已经开始向客户提供8层HBM3E的样品传输速率超过1.2TBps,并计划在2024Q1推出12层HBM3E的样品,在2025年实现HBM4的量产,进一步提升HBM的性能和容量。
三星展示的最新的路线规划中,除了带宽、能耗以及容量及堆叠数的规划,还计划在HBM4上使用FinFET节点替代平面型MOSFET来生产对应逻辑Die,并且封装方式将从基于Bump连接的CoW(Chip on Wafer)变为基于Pad连接Bumpless形式。
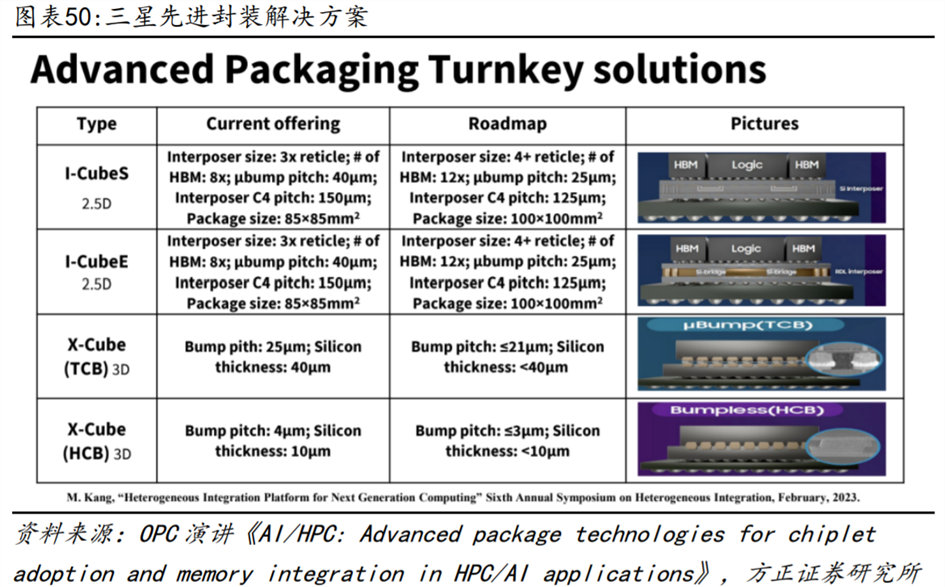
三星作为存储厂商和晶圆代工厂,既提供了HBM方案也提供了多HBM封装方案,一站式的方案有助于收获更多订单:
三星提供了2.5D和3D在内的丰富的先进封装交钥匙解决方案。包括I-CubeS、I-CubeE、X-Cube(TCB)和X-Cube(HCB)四个不同的封装类型:1)I-CubeS和I-CubeE都是2.5D封装技术的代表:它们的技术特点是,在一个85x85mm²的封装中,可以同时放置多个HBM(目前是8个),并且互连层的面积是一个标准光罩的三倍,即3x reticle。它们的微凸块间距和互连层C4间距分别是40µm和150µm。I-CubeS和I-CubeE的未来发展方向是,将互连层的面积扩大到4xreticle,将HBM的数量提升到12个,将微凸块间距和互连层C4间距缩小到25µm和125µm,以及将封装的尺寸增加到100x100mm²;
2)3D封装技术X-Cube(TCB)和X-Cube(HCB):区别在于是否使用凸块连接技术。X-Cube(TCB)的微凸块间距和硅片厚度分别为25µm和40µm,而X-Cube(HCB)则展现了更高的技术水平,其微凸块间距和硅片厚度仅为4µm和10µm,这反映了其在精度上的提升。

展望未来,为解决封装越来越大的问题,三星提出了两种解决方案:1)在一个logic die上堆叠DRAM Die,提升功耗效率40%,降低延迟10%;2)将Cash DRAM堆叠在logic die上,提升功耗效率60%,降低延迟50%。

在内部互联的技术上,如果Bump pitch超过20μm,可以采用基于TCB的微凸块连接技术。但未来若使用基于HCB的铜对铜连接技术,可以实现更小的bump size和bump pitch,将密度提高100倍,带宽提高150倍,功耗效率提高30%。

光互连将发挥重要作用,使用光学I/O的优势是可以实现非常高的带宽密度和非常低的功耗。三星有两种光学I/O的构想:一种是直接用光学I/O连接逻辑和存储(包括HBM);另一种是用光学I/O连接逻辑封装和存储封装。
3、美光:24年量产HBM3E,多代产品研发中
24年量产HBM3E,供应英伟达下一代GPU。美光在此前的财报电话会议上表示将在2024年通过HBM3E实现追赶,预计其HBM3E将在2024Q3或者Q4开始为英伟达的下一代GPU供应。11月6日美光在台湾台中四厂正式开工,宣布将集成先进的探测和封装测试功能,生产HBM3E等产品,以应对人工智能、数据中心、边缘计算和云端等各种应用的需求不断增加。美光也公布了最新的HBM产品及规划,在技术层面进行多项变革和创新,以进行追赶并期望于实现领先。首先是将硅通孔(TSV)数量比目前的HBM3产品提升两倍,并将互连尺寸缩小了25%,更密集的金属TSV互连有助于改善器件各层之间的热传递,从而降低热阻。美光还缩小了HBM3Gen2堆栈中DRAM设备之间的距离,封装的这两项变化显提高了热传递效率。
根据存储线路图,除了即将推出的HBM3Gen2产品之外,美光还宣布已经在开发HBM Next内存,预计在2026年推出,该HBM将为每个堆栈提供1.5TB/s–2+TB/s的带宽,容量范围为36GB至64GB。美光计划在2026年至2027年期间推出36GB至48GB的12-Hi和16-Hi堆栈,HBM4E将在2028年量产。HBM4的增强版本预计将获得时钟,将带宽提升到2+TB/s,并将每个堆栈的容量提升到48GB至64GB。