随着大语言模型(LLM)的功能日益强大,减少其计算需求的技术也日趋成熟,由此产生了两个引人注目的问题:能够在边缘运行和部署的最先进的 LLM 是什么?现实世界中的应用如何才能充分利用这些成果?
即使采用较低的 FP16 精度,运行像 Llama 270b 这样最先进的开源 LLM,也需要超过 140 GB 的 GPU 显存(VRAM)(700 亿参数 x 2 字节 = FP16 精度下的 140 GB,还要加上 KV 缓存所增加的显存需求)。对于大多数开发者和较小的公司来说,要获得这么大的 VRAM 并不容易。此外,无论是由于成本、带宽、延迟还是数据隐私问题,应用程序的特定要求可能会排除使用云计算资源托管 LLM 这一选项。
NVIDIA IGX Orin 开发者套件和 NVIDIA Holoscan SDK 可应对这些挑战,将 LLM 的强大功能带到边缘。NVIDIA IGX Orin 开发者套件可提供一个满足工业和医疗环境需求的工业级边缘 AI 平台。内置的 NVIDIA Holoscan 是一套能够协调数据移动、加速计算、实时可视化和 AI 推理的 SDK。
该平台让开发者能够将开源 LLM 添加到边缘 AI 流式传输工作流和产品中,为实时 AI 传感器处理带来了新的可能性,同时确保敏感数据保持在 IGX 硬件的安全边界内。
适用于实时流式传输的开源 LLM
近来开源 LLM 的快速发展已经改变了人们对实时流式传输应用可能性的看法。之前,人们普遍认为,任何需要类似人类能力的应用,都只能由数据中心规模的企业级 GPU 驱动的闭源 LLM 实现。但由于近期新型开源 LLM 的性能暴涨,Falcon、MPT、Llama 2 等模型现在已经可以替代闭源黑盒 LLM。
有许多可能的应用可以利用这些边缘的开源模型,其中大多都涉及到将流式传输传感器数据提炼为自然语言摘要。可能出现的应用有:让家属随时了解手术进展的手术实时监控视频、为空中交通管制员汇总最近的雷达交流情况,以及将足球比赛的实况解说转换成另一种语言。
随着强大开源 LLM 的出现,一个致力于提高这些模型准确性,并减少运行模型所需计算量的社群应运而生。这个充满活力的社群活跃在“Hugging Face 开放式 LLM 排行榜”上,该排行榜经常会更新最新的顶尖性能模型。
丰富的边缘 AI 功能
NVIDIA IGX Orin 平台在利用激增的可用开源 LLM 和支持软件方面具有得天独厚的优势。
强大的 Llama 2 模型有 NVIDIA IGX Orin 平台安全措施的加持,并可以无缝集成到低延迟的 Holoscan SDK 管道中,因此能够应对各种问题和用例。这一融合不仅标志着边缘 AI 能力的重大进步,而且释放了多个领域变革性解决方案的潜力。
其中一个值得关注的应用能够充分利用新发布的 Clinical Camel,这是一个经过微调的 Llama 2 70B 模型变体,专门用于医学知识研究。基于该模型创建本地化的医疗聊天机器人,可确保敏感的患者数据始终处于 IGX 硬件的安全边界内。对隐私、带宽或实时反馈要求极高的应用程序是 IGX 平台真正的亮点所在。
想象一下,输入患者的病历,并向机器人查询类似病例,获得有关难以诊断的患者的新洞察,甚至为医疗专业人员筛选出不会与当前处方产生相互作用的药物——所有这些都可以通过 Holoscan 应用实现自动化。该应用可将医患互动的实时音频转换成文本,并将其无缝地输入到 Clinical Camel 模型中。

图 1. Clinical Camel 模型
根据示例对话生成的临床笔记
NVIDIA IGX 平台凭借对低延迟传感器输入数据的出色优化,将 LLM 的功能扩展到纯文本应用之外。医疗聊天机器人已经足以展现出它的强大,而 IGX Orin 开发者套件更强大的地方在于,它能够无缝集成来自各种传感器的实时数据。
IGX Orin 专为边缘环境打造,可以处理来自摄像头、激光雷达传感器、无线电天线、加速度计、超声探头等的流信息。这一通用性使各种先进的应用能够无缝地将 LLM 的强大功能与实时数据流融合。
在集成到 Holoscan 操作系统后,这些 LLM 可显著增强 AI 传感器处理管道的能力和功能。具体示例如下:
多模态医疗助手:增强 LLM 的能力,使其不仅能够解释文本,还能解释医学影像,如 Med-Flamingo 等项目所验证的那样,它能解释核磁共振、X 射线和组织学影像。
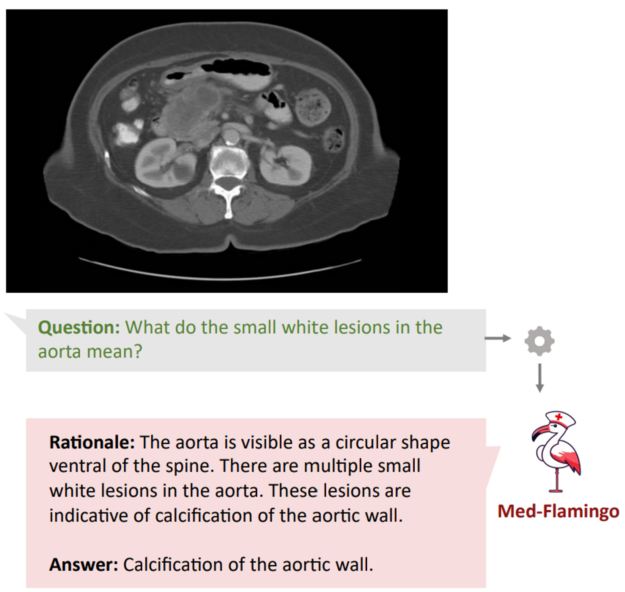
图 2. LLM 可解释文本
并从医学影像中获得相关洞察
信号情报(SIGINT):从通信系统和雷达捕获的实时电子信号中获得自然语言摘要,提供衔接技术数据与人类理解的深入洞察。
手术病例记录生成:将内窥镜视频、音频、系统数据和患者记录传输到多模态 LLM 中,生成综合全面的手术病例,并自动上传到患者的电子病历中。
智慧农业:使用土壤传感器监测 pH 值、湿度和营养水平,使 LLM 能够为优化种植、灌溉和病虫害防治策略提供可操作的深入洞察。
用于教育、故障诊断或提高生产力的软件开发助手是 LLM 的另一个新颖用例。这些模型可以帮助开发者开发更高效的代码和详尽的文档。
Holoscan 团队最近发布了 HoloChat,这个 AI 驱动的聊天机器人在 Holoscan 的开发过程中充当开发者的“助手”。它能对有关 Holoscan 和编写代码的问题做出类似人类的回答。详情请访问 GitHub 上的 nvidia-holoscan/holohub:https://github.com/nvidia-holoscan/holohub/tree/main/applications/holochat_local
HoloChat 的本地托管模式旨在为开发者提供与常见的闭源聊天机器人相同的优势,同时杜绝了将数据发送到第三方远程服务器处理所带来的隐私和安全问题。
通过模型量化
实现最佳精度与内存使用
随着大量开源模型通过 Apache 2、MIT 和商业许可发布,任何人都可以下载并使用这些模型权重。但对绝大多数开发者来说,“可以”并不意味着“可行”。
模型量化提供了一种解决方案。通过用低精度数据类型(int8 和 int4)来表示权重和激活值,而不是高精度数据类型(FP16 和 FP32),模型量化减少了运行推理的计算和内存成本。
然而,从模型中移除这一精度确实会导致模型的准确性下降。但研究表明,在内存预算既定的情况下,当参数以 4 位精度存储时,使用尽可能大且与内存匹配的模型才能实现最佳的 LLM 性能。更多详情,参见 4 位精度案例:k 位推理缩放法则:https://arxiv.org/abs/2212.09720
因此,Llama 2 70B 模型在以 4 位量化实施时,达到了精度和内存使用之间的最佳平衡,将所需的 RAM 降低至 35 GB 左右。对于规模较小的开发团队甚至个人来说,这一内存需求是可以达到的。
开源 LLM 打开新的开发机遇
由于能够在商用硬件上运行最先进的 LLM,开源社区中出现了大量支持本地运行的新程序库,并提供能够扩展这些模型功能的工具,而不仅仅是预测句子的下一个单词。
您可以通过 Llama.cpp、ExLlama 和 AutoGPTQ 等程序库量化自己的模型,并在本地 GPU 上快速运行推理。不过,是否量化模型完全取决于您自己的选择,因为 HuggingFace.co/models 中有大量量化模型可供使用。这在很大程度上要归功于像 /TheBloke 这样的超级用户,他们每天都会上传新的量化模型。
这些模型本身就带来了令人兴奋的开发机会,更不用说还能使用大量新建程序库中的附加工具来对其进行扩展,使它们更加强大。例如:
LangChain:一个在 GitHub 上获得 58,000 颗星评分的程序库,提供从实现文档问答功能的矢量数据库集成,到使 LLM 能够浏览网页的多步骤代理框架等所有功能。
Haystack:支持可扩展的语义搜索。
Magentic:可将 LLM 轻松集成到您的 Python 代码中。
Oobabooga:一个用于在本地运行量化 LLM 的网络用户界面。
只要您有 LLM 用例,就可以使用一个开源库来提供您所需的大部分功能。
开始在边缘部署 LLM
使用 NVIDIA IGX Orin 开发者套件在边缘部署最先进的 LLM,可以解锁尚未被挖掘的开发机会。如要开始部署,请先查看"使用 IGX Orin 在边缘部署 Llama 2 70B 模型"综合教程,其详细介绍了在 IGX Orin 上创建简单聊天机器人应用:https://github.com/nvidia-holoscan/holohub/tree/main/tutorials/local-llama
该教程演示了如何在 IGX Orin 上无缝集成 Llama 2,并指导您使用 Gradio 开发 Python 应用。这是使用本文中提到的任何优质 LLM 库的第一步。IGX Orin 提供的弹性、非凡性能和端到端的安全性,使开发者能够围绕在边缘运行的先进 LLM,构建创新的 Holoscan 优化应用。
GTC 2024 将于 2024 年 3 月 18 至 21 日在美国加州圣何塞会议中心举行,线上大会也将同期开放。点击 “阅读原文” 或扫描下方海报二维码,立即注册 GTC 大会。

