
未来时速
what Andy giveth, Bill taketh away.
每次英特尔提供更强大的计算能力,微软都能吃干抹净。
1990诞生的 Andy and Bill‘Law 依然有效,伴着随着数据量的指数级增长,在数据存储和处理领域愈演愈烈。“在未来的10年中,企业的变化会超过它在过去50年中的总变化。”这是比尔盖茨在1999年著作《未来时速》中的文字。我们很难逐一列举所有的关键变化,但在存储领域也遵循这个预测。比如最近一直提到的华为天才少年,张霁研究磁盘和数据库相关的智能优化,姚婷研究新型存储介质和键值存储系统,左鹏飞研究非易失性内存系统,都与存储领域有直接关系,似乎也说明存储领域的变化还在不断发生。
更高效的生产力势必替代原有的生产力和生产关系。从大型机和小型机的分区技术,再到x86虚拟化和现在风头正劲的容器和容器编排技术,都着力于提高应用的部署密度,提升计算资源的利用率,最终降低持有成本。存储领域也不例外,纵观Flash的历史:
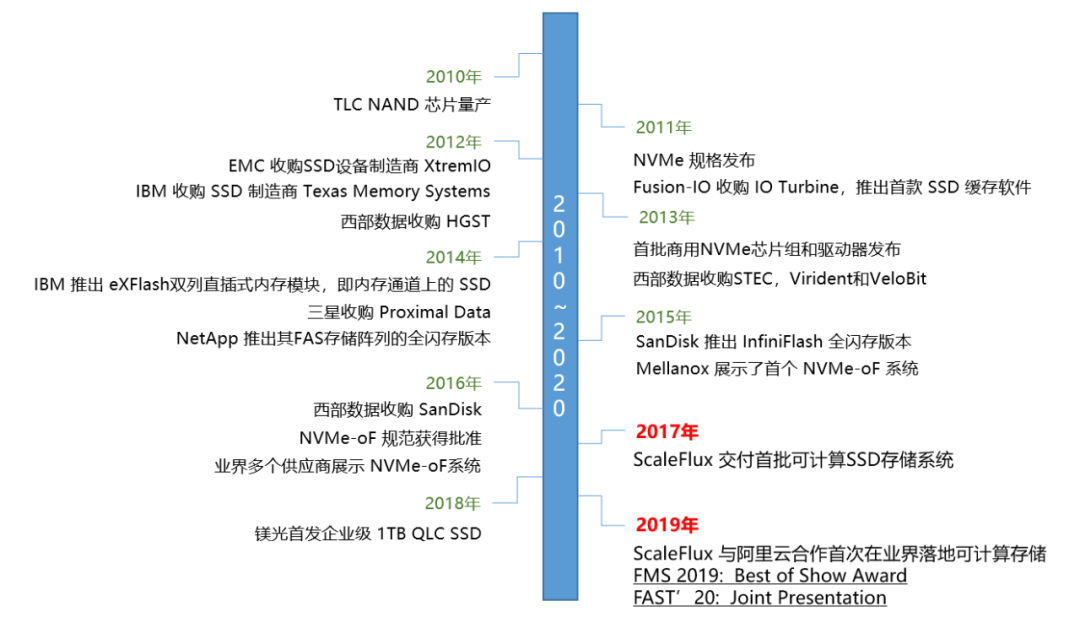
SSD持续在企业关键应用落地并大规模部署。从MLC,TLC再到QLC,容量逐渐增大成本逐渐降低,但基于SSD技术的实现原理,寿命问题也愈发突出。
写放大与寿命
SSD不能像内存和机械硬盘直接覆盖旧数据,只能擦除Block后再写入其中一个“干净”的Page。当SSD剩余空间变少,出现大量数据碎片时,就要读取整个Block数据,将有效数据重新写到已经擦除的Block。这个过程叫Garbage Collection (GC),导致写放大(Write Amplification)。其实,衡量写放大有更加量化的指标,叫做写放大因子(Write Amplification Factor简称WAF),JEDEC(固态技术协会,即推出SSD标准的组织)对于写放大因子WAF的定义:
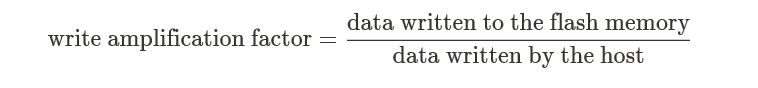
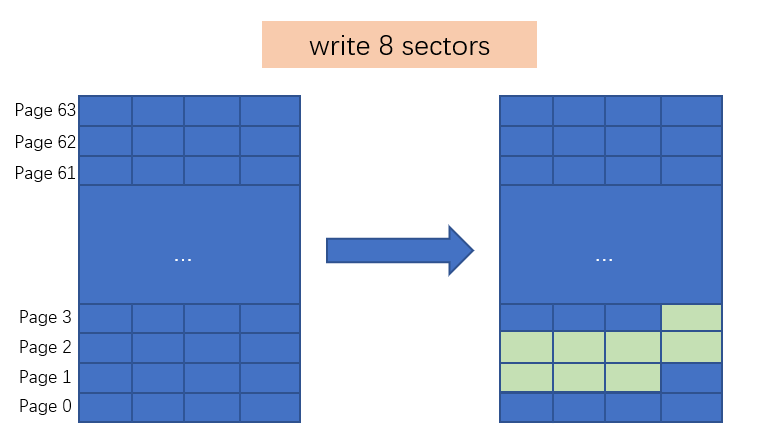
如图为JEDEC中描述WAF如何计算的例子,此Block包含64个Page(256 sectors),假设当需要更新Page1~Page3(8 sectors)数据,假设算法为:
拷贝所有page0~page63到DRAM;
DRAM中更新Page1~Page3;
擦除此Block并回写DRAM数据;
众所周知,闪存颗粒存在擦写次数的限制,所以在衡量SSD寿命时,通常会以TBW(或DWPD)为衡量依据。写放大导致了闪存颗粒擦写次数的“放大”,进一步降低寿命。有如下计算公式:
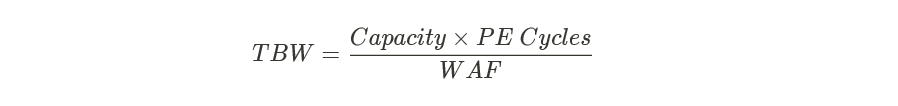
同时,随着写入量的增加,坏块的出现概率也会提升。对于可靠性,比较重要的衡量指标为UBER(不可修复的错误比特率),用来度量在应用错误纠正机制后依然产生的每比特读取的数据错误数量占总读取数量比。
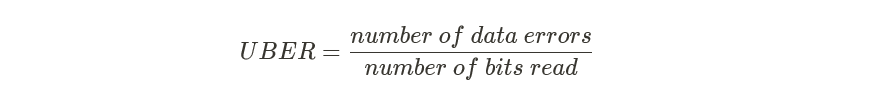
UBER描述的是出现数据读取错误的概率,该值越低越好。下图描述UBER随写入数据量增加的线性关系:
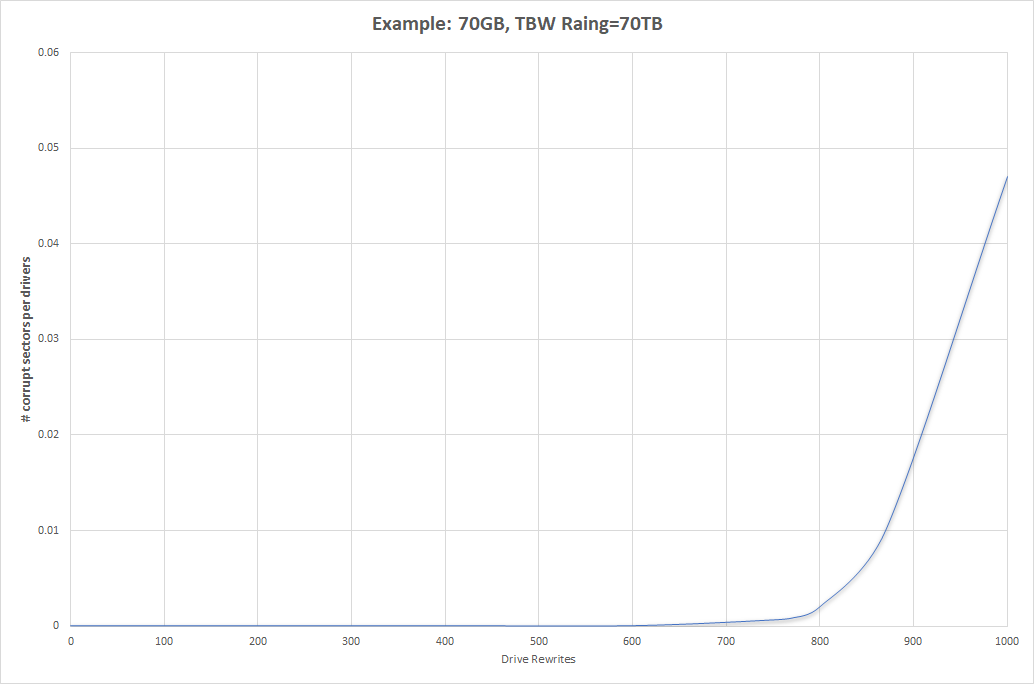
0~600,UBER一直为0
600~800,此时由于写入量的持续增加,形成少量坏块,UBER从0缓慢增加到0.003
800~1000,更多颗粒的失效与写放大对于颗粒擦写的叠加导致剩余NAND颗粒更容易形成坏块,从而导致增加不多的写入量,UBER也急剧增加,此时数据读取错误率陡增。
总之,对于常常承载企业关键业务的SSD来讲,考虑可靠性,不仅关注写入量,随着擦写次数增加,造成的读取错误也是企业级应用不可接受的。TBW和UBER不应该单独讨论,就像在数据库领域Recovery Time Objective (RTO) 和 Recovery Point Objective (RPO)总是同时出现,只谈数据服务的恢复时间,又或者一味强调数据零丢失,都是耍流氓。当然业界也在提高SSD存储颗粒的擦写次数、GC算法方面持续发力,同时,结合可计算存储的透明压缩,也为SSD寿命及稳定性的提升带来了新的方向。
压缩与寿命
定性而言,压缩势必减少数据写入,最终提升存储颗粒的写入寿命。但在工程领域,还需要获取更详尽的数据。要考虑压缩带来的寿命收益,首先以不影响业务(参见:可计算存储: 数据压缩和数据库计算下推)为前提。决定写入寿命的相关因素很多,比如存储颗粒的品质,数据模型,温度,湿度,可能还涉及玄学。写入模型一定是最重要因素的之一,这就要先回到SSD的企业级服务的重要业务场景。JESD219(JEDEC中专门介绍SSD寿命测试中分析工作负载的文档)分析了企业级SSD工作负载的特点,并在此基础上进行严格的数据负载模拟测试。借助JESD219这个事实标准,便于我们进一步验证数据压缩对于减少写放大的收益。
JESD219工作负载
含如下几点:
数据热度:数据集访问较为集中,5%的数据获得50%的访问频率,20%的数据获得80%的访问频率;
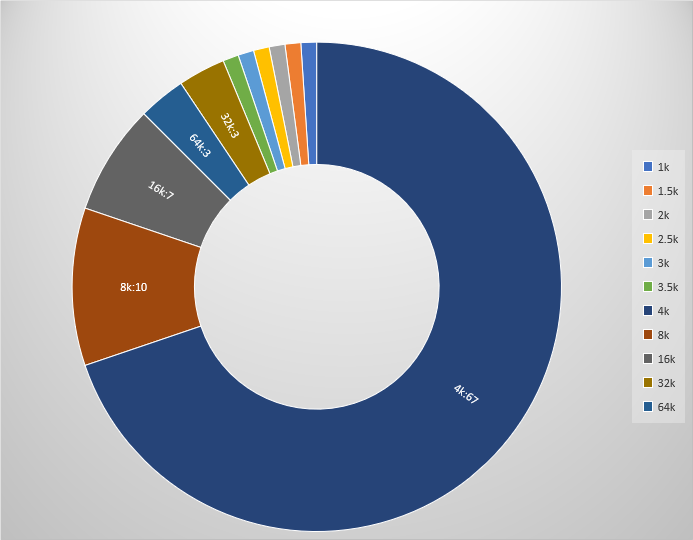
IO大小:以小块IO为主,67%的IO大小在4KB,过大的IO或者过小的IO都比较少,如下图,为不同I/O大小下所占的比例;
测试时长:JESD219对于压缩比与写放大的测试也以此工作负载模型展开,并针对不同压缩比数据、不同预留空间大小、不同容量大小,进行测试,其中为了接近真实业务场景,保证测试持续时长是非常有必要的,为此我们采用以上IO pattern持续测试10000分钟;
记录方式:每分钟采样一次写放大因子;
先看看魔改后制造负载的脚本(截取部分):
最终完成记录如下图所示:
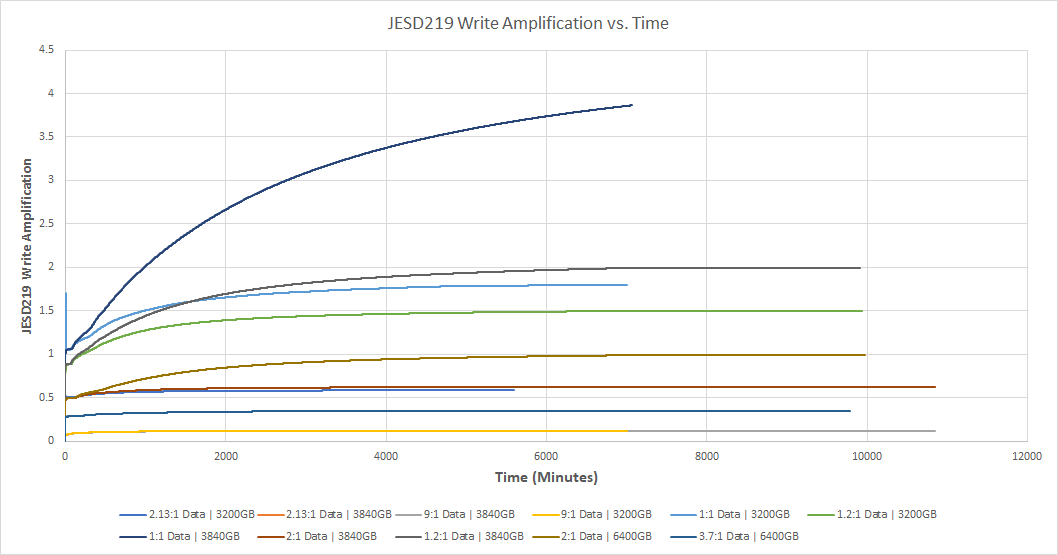
如图为JESD219,基于同样的负载模型,使用企业级常用的3.2TB/3.84TB/6.4TB SSD容量测试,数据压缩比1:1/1.2:1/2:1/2.13:1/3.7:1/9:1逐渐增大,持续10000分钟并记录写放大的数据。从测试结果可见
所有模型在持续测试一段时间后会到达稳态,此时写放大趋于稳定;
同为3.2TB SSD,数据压缩比从1:1/1.2:1/2.13:1/9:1,写放大骤减,3.84TB及6.4TB SSD结果类似;
选取典型的SSD容量配比,对比分析具体数据,如下图
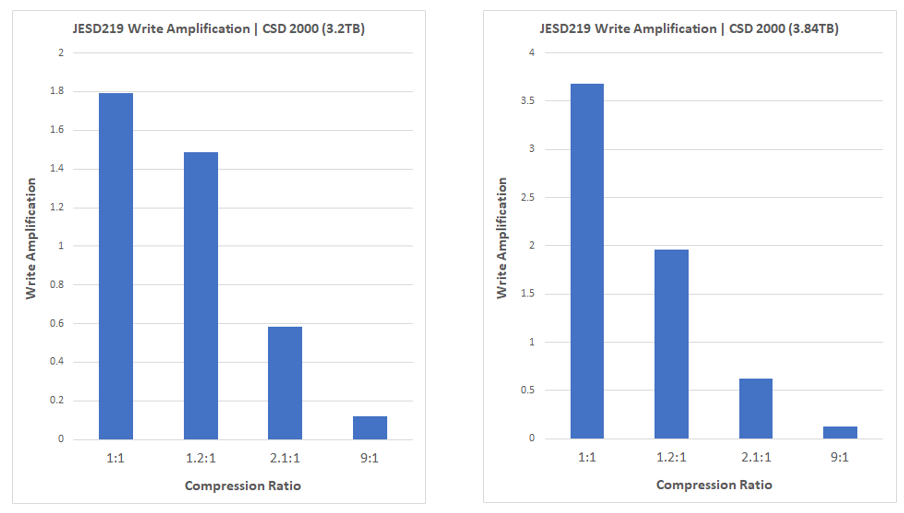
一般企业级SSD预留空间为28%(可用空间3.2TB),当数据压缩比1:1时,写放大因子为1.79,当数据压缩比为1.2:1时写放大因子降低为1.48(仅提升了20%的压缩写放大降低了17%)。当数据压缩比为2.1:1时,写放大因子为0.58,写放大降低67%。
一般消费级SSD预留空间为7%(可用空间3.84TB),当数据压缩比1:1时,写放大因子为3.67,当数据压缩比为1.2:1时写放大因子降低为1.95,仅仅做了20%的压缩写放大降低了49%,已经接近企业级SSD数据压缩比1:1时写放大因子1.79。当数据压缩比为2.1:1时,写放大因子为0.62,写放大降低83%。
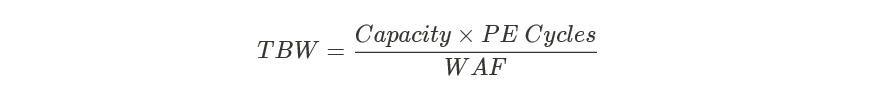
回顾TBW和UBER,可以总结:
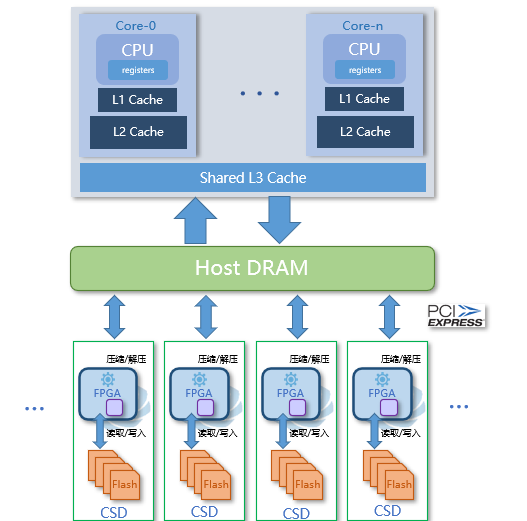
除了考虑压缩本身,结合企业级业务还需要考虑很多方面,如是否对业务透明、是否零拷贝不带来额外开销、可扩展性等等,可参考可计算存储: 数据压缩和数据库计算下推,如下图基于可计算存储的透明压缩供参考。
JESD219考虑的已经很充分,但如果想要更接近应用负载,还需要更进一步。以数据库场景为例,使用MySQL,借助Sysbench制造读写压力(OLTP混合读写oltp_read_write、数据集2TB),可以观测到其IO模型(基于eBPF跟踪IO)和JESD219还存在较大差异:
I/O大小,73%的I/O集中在16~31kbytes,其原因为InnodDB数据页默认为 16KB。15%的I/O集中在1KB以下是由于redolog默认以512 bytes 进行I/O操作;
数据热度,在sysbench测试中,以离散I/O为主,尽量均衡访问完整2TB数据集;

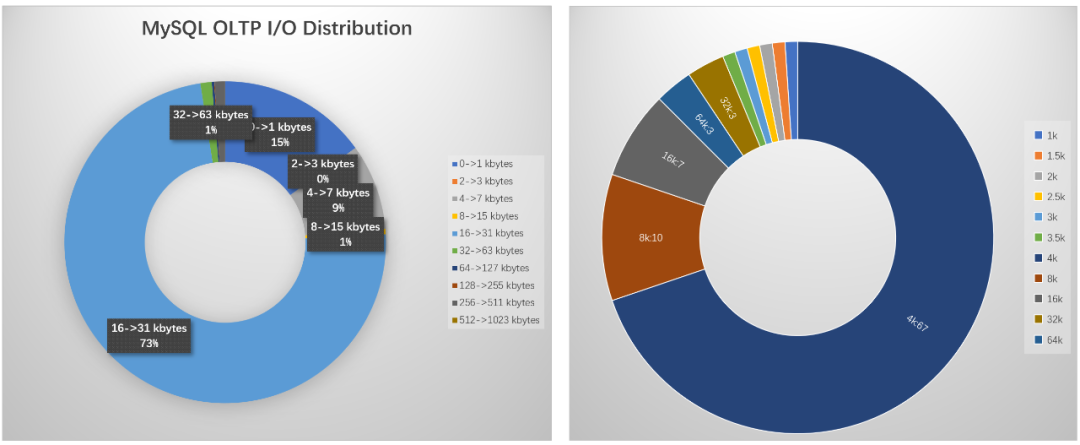
当然,这完全可以通过魔改JESD219脚本更有针对性的模拟应用负载,这里不做展开。
十倍速变化
物理学家理查德·费曼 (Richard P. Feynman)在1959年12月的美国物理学年会上发表了题为“There's plenty of room at the bottom”(“底层还大有可为”)的演讲,对未来物理学的发展起到深远的影响。可计算存储技术作为应用的“bottom” 也将对应用架构产生更大的影响。
参考
可计算存储: 数据压缩和数据库计算下推
On the Impact of Garbage Collection on flash-based SSD Endurance
Write Amplification Analysis in Flash-Based Sold State Drives
QZFS: QAT Accelerated Compression in File System for Applicaton Agnostic and Cost Efficient Data Storage
Improving Performance and Lifetime of Solid-State Drives Using Hardware-Accelerated Compression
Zoned Namespaces (ZNS) SSDs
JESD219
|
高端微信群介绍 |
|
|
创业投资群 |
AI、IOT、芯片创始人、投资人、分析师、券商 |
|
闪存群 |
覆盖5000多位全球华人闪存、存储芯片精英 |
|
云计算群 |
全闪存、软件定义存储SDS、超融合等公有云和私有云讨论 |
|
AI芯片群 |
讨论AI芯片和GPU、FPGA、CPU异构计算 |
|
5G群 |
物联网、5G芯片讨论 |
|
第三代半导体群 |
氮化镓、碳化硅等化合物半导体讨论 |
|
存储芯片群 |
DRAM、NAND、3D XPoint等各类存储介质和主控讨论 |
|
汽车电子群 |
MCU、电源、传感器等汽车电子讨论 |
|
光电器件群 |
光通信、激光器、ToF、AR、VCSEL等光电器件讨论 |
|
渠道群 |
存储和芯片产品报价、行情、渠道、供应链 |

< 长按识别二维码添加好友 >
加入上述群聊

带你走进万物存储、万物智能、
万物互联信息革命新时代

