

1、硬件角度
大家都曾经看过那个纸上打孔,记录数据的图片。

后来都知道出现了内存器,我们执行指令分为加载+运行。
最开始的程序运行时只能跑一个进程的,那就不需要复杂的内存管理,把我弄到固定的位置,然后这片区域都是我的。而且有多大的内存我就用多大的,一旦我进程想用的内存比拥有的物理内存大的时候,崩了就完事了。
特点:单进程 单操作系统 直接使用物理内存
这样的问题随着时代的发展问题就来了。
问题一 :单进程用不完资源那不是浪费?
问题二 :我要是物理内存不够,又没钱升级硬件怎么办?
问题三 :因为我的软件直接操作接触的物理内存,这个和硬件靠的太近,我们都知道移植性就查了?
随着发展单进程肯定是不符合要求的,那么怎么办?多进程(脑子里先把进程调度的事情放下,focu内存方面)。
多进程之间的这个内存怎么处理,总不能让腾讯的数据访问到快播的吧,想象你正在看剧,突然内容变成了学习内容,怕怕。为了解决这个问题,在操作系统编译的时候主存划分了很多的静态分区。有进程的时候,你就看看哪里能放下你,你去那里待着。
于是问题又来了
1、程序大小那不是必须和分区匹配,起码不能比分区小
2、这个进程的数目那就是固定了啊,那不是买电脑还得多一个电脑能跑多少个进程的参数
3、地址空间固定,进程不能膨胀啊。(想想咱们平时LOL,不运行的时候几个G,运行起来几百个,那肯肯定是玩不了了)
4、进程之间的边界真的能控制的很好吗?现在这么完备的内存管理下还经常出现内存踩踏时间。
解决方法就是前辈们整了个动态的分区,就是给操作系统整一个分区,剩下的有进程时,需要多大分割多大。这样一整,敏感的你就知道了,分割多了,那不是内存的这个空洞就多了,碎片就多了,那咋整呢。得规整内存,只能迁移进程了,迁移进程你不可能做,只能操作系统了,而这个过程很消耗时间(自己磁盘整理过的都知道哈),需要大量数据的换入换出。尤其是在进程运行的时候内存不够了,然后你得去迁移,等个一个小时,电脑我都想砸了。
迁移只有这个进程的位置也变了,这个寻址方式就算是相对寻址,那个相对的对象总是绝对的,因此程序编写你就说头疼不。(两数之和已经够头疼了,还有心情去管理内存重定位)
同时当这个程序是恶意的,那我不是就可以为所欲为,因为大家都是直接对应的物理内存,我偏不去我该去的地方,我就在你工作的时候来骚扰你一下,你就说怕不怕。
于是这几个问题:
内存保护、内存运行重定位、使用效率低下无法忍受懒惰是催促科技进步的源动力
1、解决办法 level1 - 分段机制
为了解决进程间内存保护的问题,提出了虚拟内存。通过增加一层虚拟内存,进程访问虚拟内存,虚拟内存由操作系统映射到物理内存。对于进程来说它就不需要关系实际的物理地址,当访问到没有映射的物理内存时,操作系统会捕捉到这个微法操作。同时进程是使用的虚拟内存,因为程序也具有移植性但是啊进程就算是操作虚拟内存但是最后也是映射到物理内存,如果给进程映射的物理内存不够的时候,那还是得迁移。换出到磁盘进行迁移,粒度是整个进程,这么大的io肯定很漫长。想想一个程序中的数据,在不断的运行使用的只有那么一部分,于是把常用的放在内存,不常用的放在磁盘中。那么换入换出的就是那么一少部分数据。然后这里就创建了更细的粒度–分页机制想想为什么你的电脑内存条才8个G却能跑几十G的游戏。
2、解决办法 level2 - 分页机制
现在我们知道分页粒度很细。进程的虚拟地址、硬件的物理地址都按照分页的粒度。常用的代码和数据以页留在内存,不常用的去磁盘,这样就节省了物理内存(内存那么贵)进程的虚拟内存页通过CPU的硬件单元映射到物理内存页物理页称为物理页面或者页帧进程空间的虚拟页面称为虚拟页操作系统为了管控这些物理页面,给页帧创建了编号页帧号 PFN现在的页表常见的4KB最常见,还有16K、64K。在某些特点的场景下,比如那种超大服务器系统TB量级,可能页面是M或者G级别。
到这里就说说那个CPU的硬件单元
其实虽然什么不想做的事情都扔给操作系统,但是做人不能这么狗,尤其是内存管理这么严重的事情,还有就是安全性(我这样认为),于是用过CPU的硬件单元–MMU来管控这个内存的映射。
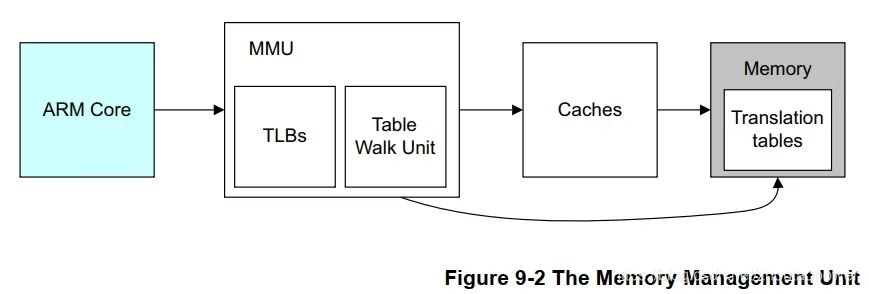
ARM处理器的内存管理单元包括TLB和Table Walk Unit两个部件。
TLB是一块高速缓存,用于缓存页表转换的结果,从而减少内存访问的时间。就拿缓存的概念去理解。当TLB 没有,miss了。那我就只能去内存的转换页表中获取这个映射的结果,获取到对应的物理地址后再将我的虚拟地址换成物理地址去最终的目的地查看学习资料。(有没有中玩游戏闯关的感觉)
当然不是说有个这个玩意就什么不用做了。
一个完整的页表翻译和查找的过程叫作页表查询(Translation Table Walk),页表查询的过程由硬件自动完成,但是页表的维护需要软件来完成。
页表查询是一个相对耗时的过程,理想的状态是TLB里缓存有页表转换的相关信息。当TLB未命中时,才会去查询页表,并且开始读入页表的内容。(要是这个TLB整大点,不是可以加快,不考虑钱的话)
因此页表的维护是软件的,所以在Linux内核内存的学习中,后面会有内存初始化,创建页表这些东西。
3、虚拟内存到物理地址的转换
上面那个图里面,如果是TLBs命中后就直接拿到了物理地址,去兑换奖品,但是miss掉以后,那就得走Table Walk Uint就是得页表转换,VA–>PA(V:虚拟 P:物理 A:地址)
整个流程瞅瞅?
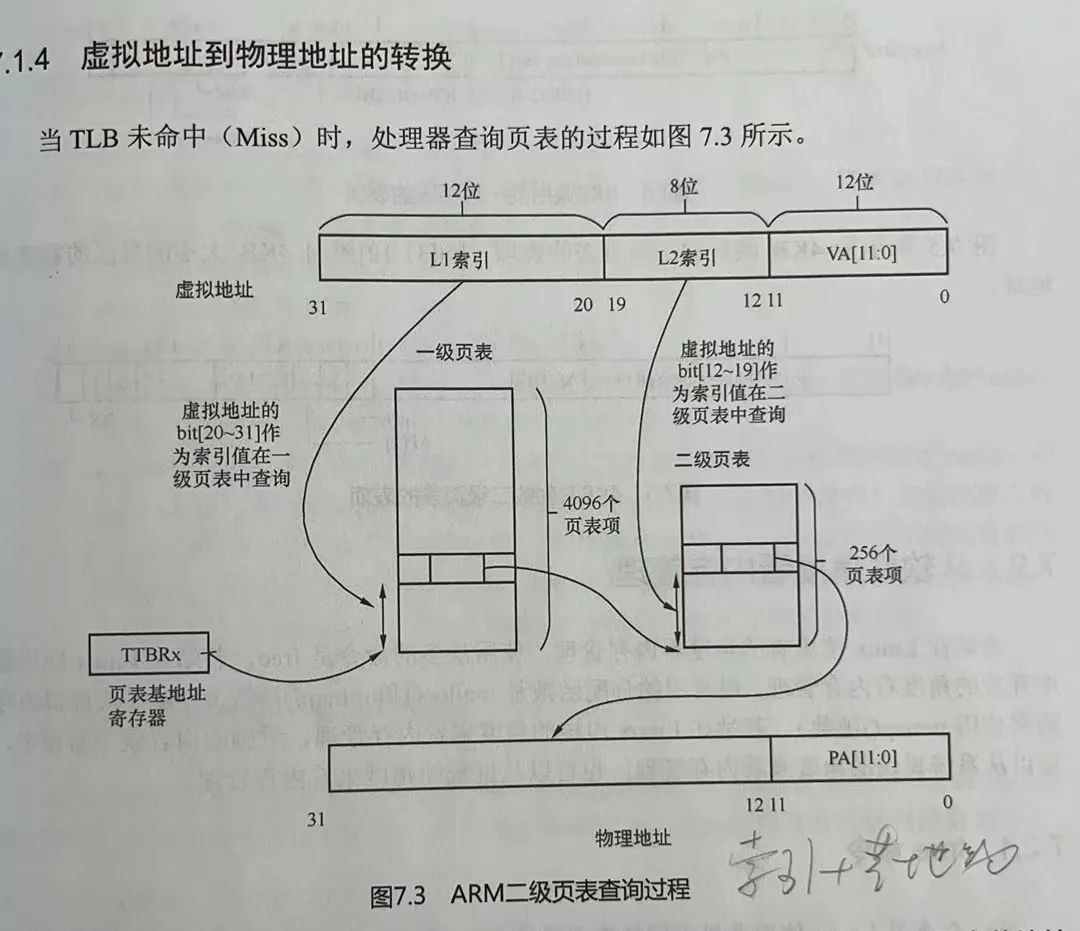
处理器根据页表基地址控制寄存器TTBCR和虚拟地址来判断使用哪个页表基地址寄存器,是TTBR0还是TTBR1。(一个基值是内核的,一个用户态的)
页表基地址寄存器中存放着一级页表的基地址。
处理器根据虚拟地址的bit[31:20]作为索引值()4K页表,在一级页表中找到页表项。一级页表一共有4 096个页表项。
第一级页表的表项中存放有二级页表的物理基地址。处理器将虚拟地址的 bit[19:12]作为索引值,在二级页表中找到相应的页表项。二级页表有256个页表项(2^12 * 2^8 * 4kb(2^12)==》32位)。
二级页表的页表项里存放有 4KB 页的物理基地址,加上最后的VA 12位,因此处理器就完成了页表的查询和翻译工作。
(将整个4MB分成了4096份* 256份*4KB)
(这就是为什么内存越大,页表项也得越大,不然页表项的内存就变大的)
(表项存的是基地址,而虚拟内存放的都是索引)

图 7.4 所示为 4KB 映射的一级页表的表项,bit[1:0]表示一个页映射的表项,bit[31:10]指向二级页表的物理基地址。
4KB是2^12
64位的ARM 一般常用的是48,那么只剩36位(其他的位干啥了呢,记住这个问题哈哈哈)
这里还是讨论32位

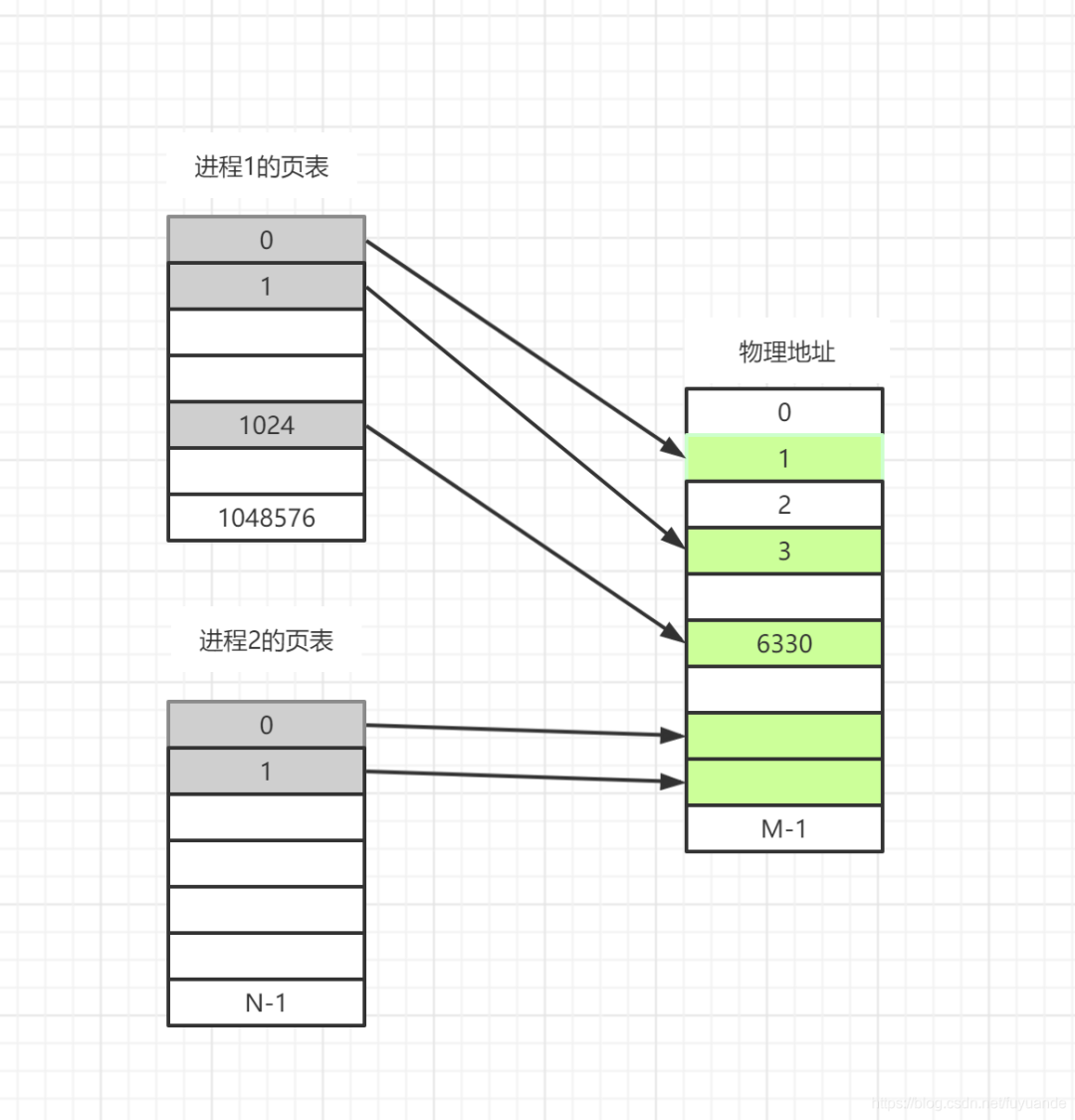
下图展示两个进程以及各自的页表和物理内存的对应关系图,这里假定页大小是4K,32位地址总线进程地址空间大小为(2^32)4G,这时候页表项有 4G / 4K = 1048576个,每个页表项为一个地址,占用4字节,1048576 * 4(B) /1024(M) = 4M,也就是说一个程序啥都不干,页表大小就得占用4M。如果每个页表项都存在对应的映射地址那也就算了,但是,绝大部分程序仅仅使用了几个页,也就是说,只需要几个页的映射就可以了,如下图,进程1的页表,只用到了0,1,1024三个页,剩下的1048573页表项是空的,这就造成了巨大的浪费,为了避免内存浪费,计算机系统开发人员想出了一个方案,多级页表。
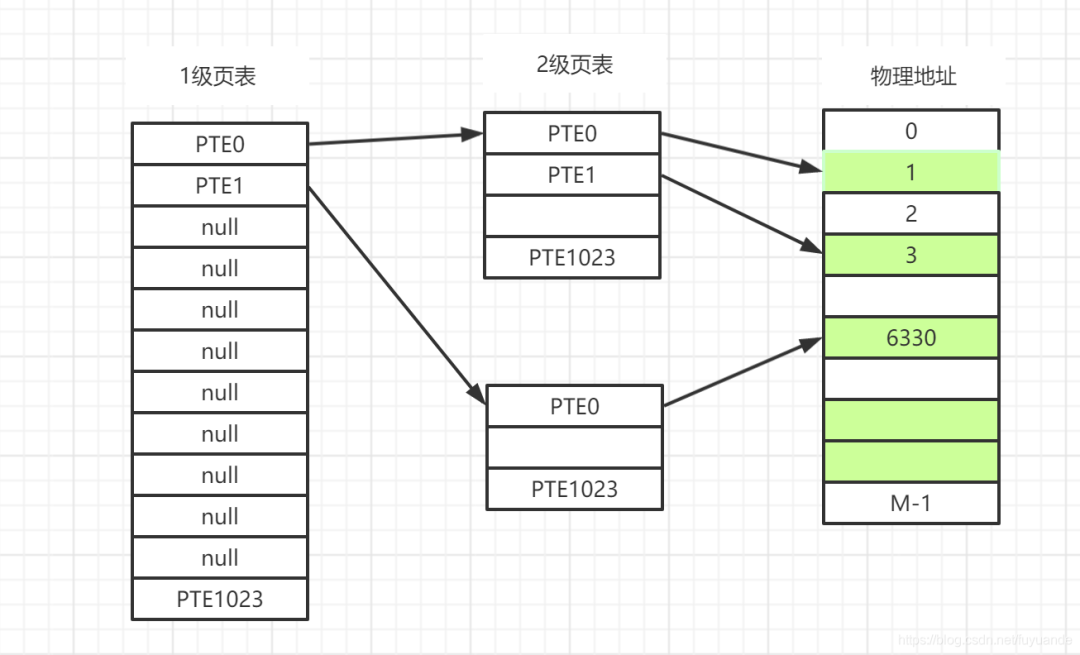
我们先看下图,这是一个两级页表,对应上图中的进程1。先计算下两级页表的内存占用情况。
一级页表占用= 1024 * 4 B= 4K,
2级页表占用 = (1024 * 4 B) * 2 = 8K。
总共的占用情况是 12K,相比一级页表 4M,节省了99.7%的内存占用。
我们来看下两级页表为啥能够节省这么大的内存空间,相比于上图单级页表中一对一的关系,两级页表中的一级页表项是一对多的关系,这里是1:1024, 这样就需要 1048576 / 1024 = 1024 个一级页表项。相当于把上图的单级页表分成1024份。一级页表项PTE0表示虚拟地址页01023,PTE1表示虚拟地址页10242047。如果对应的1024个虚拟地址页存在任意一个真实的映射,则一级页表项指向一个二级页表项,二级页表项和虚拟地址页一一对应,在上图中,进程1的虚拟页0,1,1024存在映射,0,1虚拟页属于这里的PTE0,1024属于PTE1。一级页表项中如果为null,表示对应的1024个虚拟页没有使用,所以就不需要二级页表了,节省了空间。当然,如果虚拟地址页完全映射的话,多级页表的占用=一级页表项(1024 * 4B) + 二级页表项(1024 1024 4B) = 4M + 4K,比单级映射多了4K,不过这种情况基本上没有可能,因为进程的地址空间很少有完全映射的情况。正是因为省却了大量未映射的页表项使得页表的空间大幅减少。
其实这个差异就是我以前一来就把全部的虚拟页表和物理页表建立了映射关系,那我这个页表就需要4M。
现在我将这个4M的页表分成了1024份,需要几份就申请创建几份页表,而不是一来就把所有的页表都和物理页面挂上钩。
然后分成了这1024个,我需要在抽象一层4kb的页表去指向这1024个页表各自的基地址。
因为从物理内存层面一层一层的提到最上层的时候,也方便我们对于这个虚拟地址的组成:
一级页表索引+二级页表索引+VA(每次页表的内容都是下一基的基地址)
(这个图片稍微有点理想,一般都是4096 + 256的组合,而不是1014 + 1024的组合,不过大概这个道理就行)
那几个特殊的位是内存的属性。这个后面再补充。这个是ARM硬件架构上针对安全内存、设备内存的一些位。
参考资料:
内容参考来自《奔跑吧 linux内核》
https://blog.csdn.net/fuyuande/article/details/117616433
————————————————
版权声明:本文为CSDN博主「安全-Hkcoco」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_45264425/article/details/126438470
