
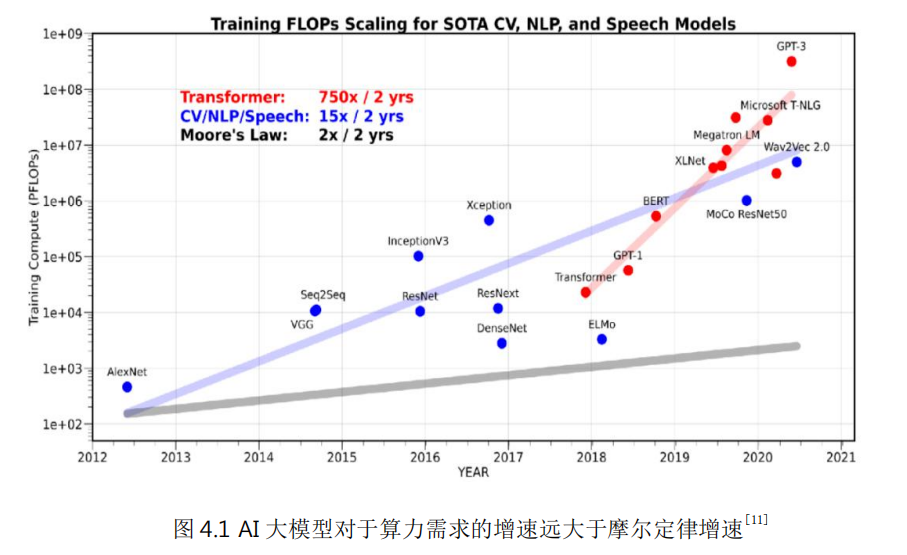
内容来源“数字基础设施技术趋势白皮书(2023)”。随着人工智能、隐私计算、AR/VR 以及基因测试/生物制药等新型高性能计算应用的不断普及,对算力的需求也不断持续增加。比如,以 ChatGPT 为代表的大模型需要巨大算力支撑。大模型对算力的需求增速远大于摩尔定律增速。
自微处理器诞生以来,算力的增长按摩尔定律发展,即通过增加单位芯片面积的门电路数量来增加处理器算力,降低处理器成本和功耗。但近年来这条路已经遇到越来越大的困难,通过持续缩微来提升性能已经无法满足应用的需求。
More Moore:继续追求更高的晶体管单位密度。比如晶体管工艺结构从鳍式结构FinFET 到环形结构 GAA,以及纳米片、纳米线等技术手段有望将晶体管密度继续提升 5 倍以上。但这条路在成本、功耗方面的挑战非常大。
Beyond CMOS:放弃 CMOS 工艺,寻求新材料和新工艺。比如使用碳纳米管、二硫化钼等二维材料的新型制备工艺,和利用量子隧穿效应的新型机制晶体管。但这条路径的不确定性较大,离成熟还需要很长时间。
芯片架构:DSA & 3D 堆叠 & Chiplet
DSA 针对特定领域的应用采用高效的架构,比如使用专用内存最小化数据搬移、根据应用特点把芯片资源更多侧重于计算或存储、简化数据类型、使用特定编程语言和指令等等。与 ASIC 芯片(Application Specific Integrated Circuit,专用集成电路)相比,DSA 芯片在同等晶体管资源下具有相近的性能和能效,并且最大程度的保留了灵活性和领域的通用性。
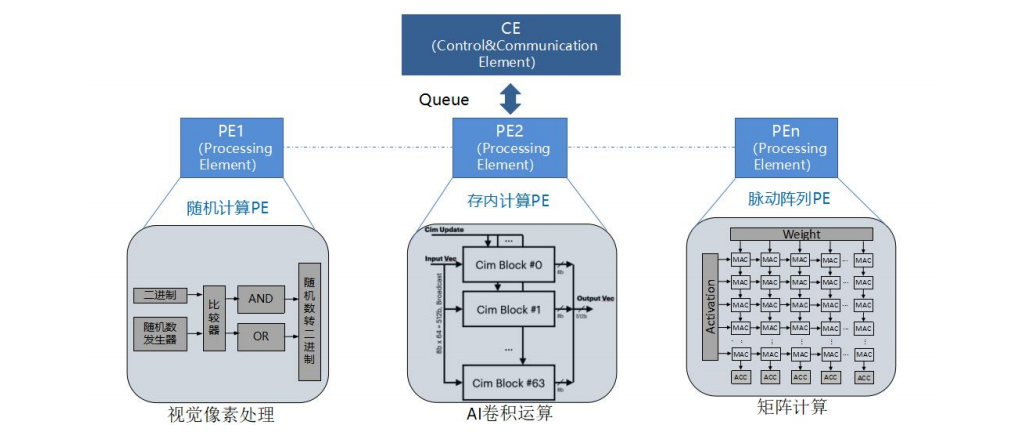
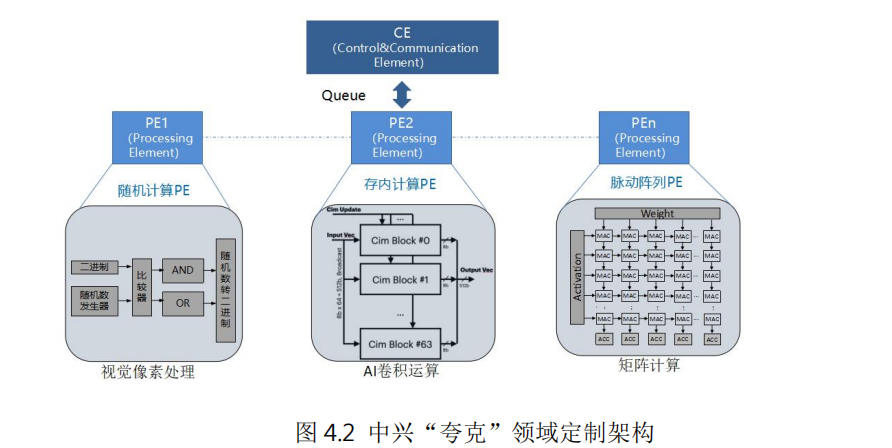
例如中兴通讯提出的计算和控制分离的人工智能领域定制芯片架构“夸克”,针对深度神经网络的计算特点,将算力抽象成张量、向量和标量引擎,通过独立的控制引擎(CE)对各种 PE 引擎进行灵活编排和调度,从而可以高效实现各种深度学习神经网络计算,完成自然语言处理、AI 检测、识别和分类等各种人工智能应用。由于采用软硬件协同设计的定制化方案,DSA 芯片在相同功耗下可以取得比传统 CPU 高数十倍甚至几百倍的性能。
摩尔定律本身是在 2D 空间进行评估的,随着芯片微缩愈加困难,3D 堆叠技术被认为是提升集成度的一个重要技术手段。3D 堆叠就是不改变原本封装面积情况下,在垂直方向进行的芯片叠放。这种芯片设计架构有助于解决密集计算的内存墙问题,具有更好的扩展性和能效比。
Chiplet 技术被认为是延续摩尔定律的关键技术。首先 Chiplet 技术将芯片设计模块化,将大型芯片小型化,可以有效提升芯片良率,降低芯片设计的复杂程度。其次,Chiplet 技术可以把不同芯粒根据需要来选择合适的工艺制程分开制造(比如核心算力逻辑使用新工艺提升性能,外围接口仍采用成熟工艺降低成本),再通过先进封装技术进行组装,可以有效降低制造成本。
与传统芯片方案相比,Chiplet 模式具有设计灵活性、成本低、上市周期短三方面优势。Chiplet 技术面临的最大挑战是互联技术,2022 年 3 月 2 日,“UCIe 产业联盟”成立,致力于满足客户对可定制封装互联互通要求。Chiplet 产业会逐渐成熟,并将形成包括互联接口、架构设计、制造和先进封装的完整产业链。
存算一体使得计算和存储从分离走向联合优化
存算一体技术就是从应用需求出发,进行计算和存储的最优化联合设计,减少数据的无效搬移、增加数据的读写带宽、提升计算的能效比,从而突破现有内存墙和功耗墙的限制。
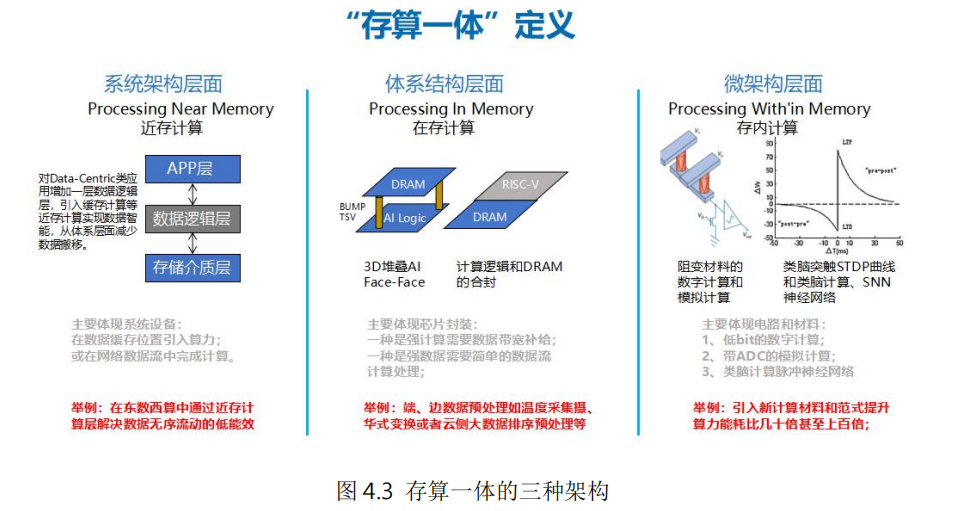
存算一体包含系统架构、体系结构和微架构多个层面。系统架构层面,在传统计算和存储单元中间增加数据逻辑层,实现近存计算,减少数据中心内、外数据低效率搬移,从系统层面提升计算能效比;体系架构层面,利用 3D 堆叠、异构集成等先进技术,将计算逻辑和存储单元合封,实现在存计算,从而增加数据带宽、优化数据搬移路径、降低系统延时;微架构层面,进行存储和计算的一体化设计,实现存内计算,基于传统存储材料和新型非易失存储材料,在存储功能的电路内同时实现计算功能,取得最佳的能效比。
(一)系统架构层面的近存计算(Processing Near Memory)
近存计算在数据缓存位置引入算力,在本地产生处理结果并直接返回,可以减少数据移动,加快处理速度,并提升安全性。通过对 Data-Centric 类应用增加一层数据逻辑层,整合原系统架构中的数据逻辑布局功能和应用服务数据智能功能,并引入缓存计算,从而减少数据搬移。在“东数西算”工程中,可以通过设置近存计算层,解决数据无序流动的低能效问题。
(二)体系架构层面的在存计算(Processing In Memory)
在存计算主要在存储器内部集成计算引擎,这个存储器通常是 DRAM。其目标是直接在数据读写的同时完成简单处理,而无需将数据拷贝到处理器中进行计算。例如摄氏和华氏温度的转换。在存计算本质上还是计算、存储分离架构,只是将存储和计算靠近设计,从而减少数据搬移带来的开销。目前主要是存储器厂商在推动其产业化。
(三)微架构层面的存内计算(Processing Within Memory)
存内计算是把计算单位嵌入到存储器中,特别适合执行高度并行的矩阵向量乘积,在机器学习、密码学、微分方程求解等方面有较好的应用前景。
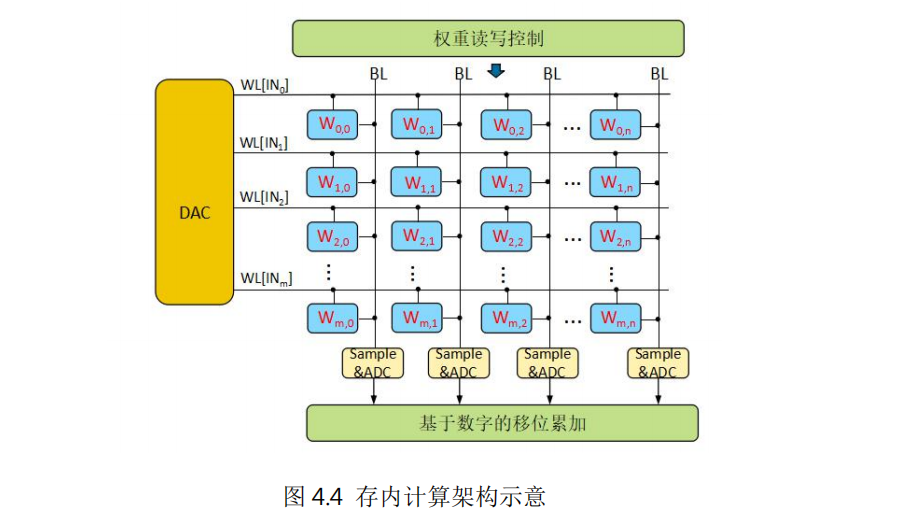
存内计算采用计算、存储统一设计的架构。以深度神经网络的矩阵向量乘加操作为例,由输入端的 DAC、单元阵列、输出端的 ADC 以及其他辅助电路组成。存储单元中存放权重数据,输入经过 DAC 转换后变成对存储数据的读写操作,利用欧姆定律和基尔霍夫定律,不同的存储单元输出电流自动累加后输出到 ADC 单元进行采样,转换成输出的数字信号,这样就完成了矩阵向量乘加操作。
基于对等系统的分布式计算架构
传统的计算系统以 CPU 为中心进行搭建,业务的激增对于系统处理能力要求越来越高,摩尔定律放缓,CPU 的处理能力增长越来越困难,出现了算力墙。通过领域定制(DSA)和异构计算架构可以提升系统的性能,但是改变不了以 CPU 为中心的架构体系,加速器之间的数据交互通常还是需要通过 CPU 来进行中转,CPU 容易成为瓶颈,效率不高。
基于 xPU(以数据为中心的处理单元)为中心的对等系统可以构建一个新型的分布式计算架构。如图 4.5 所示,对等系统由多个结构相似的节点互联而成,每个节点以 xPU 为核心,包含多种异构的算力资源,如 CPU、GPU 及其它算力芯片。xPU 主要功能是完成节点内异构算力的接入、互联以及节点间的互联,xPU 内部的通用处理器核可以对节点内的算力资源进行管理和二级调度。节点内不再以 CPU 为中心,CPU、GPU 及其它算力芯片作为节点内的算力资源处于完全对等的地位,xPU 根据各算力芯片的特点及能力进行任务分配。
对等系统的节点内部和节点之间采用基于内存语义的新型传输协议,即,采用read/write 等对内存操作的语义,实现对等、无连接、授权空间访问的通信模式,通过多路径传输、选择性重传、集合通信等技术提高通信效率。与 TCP、RoCE 等现有传输协议相比,基于内存语义的传输协议基于低延时、高扩展性的优势。节点内 xPU、CPU、GPU 及其他算力芯片之间通过基于内存语义的低延时总线直接进行数据交互。节点间通过 xPU 内部的高性能转发面实现基于内存语义的低延时 Fabric,从而构建以节点为单位的分布式算力系统。同时 xPU 内置安全、网络、存储加速模块,降低了算力资源的消耗,提高了节点的性能。
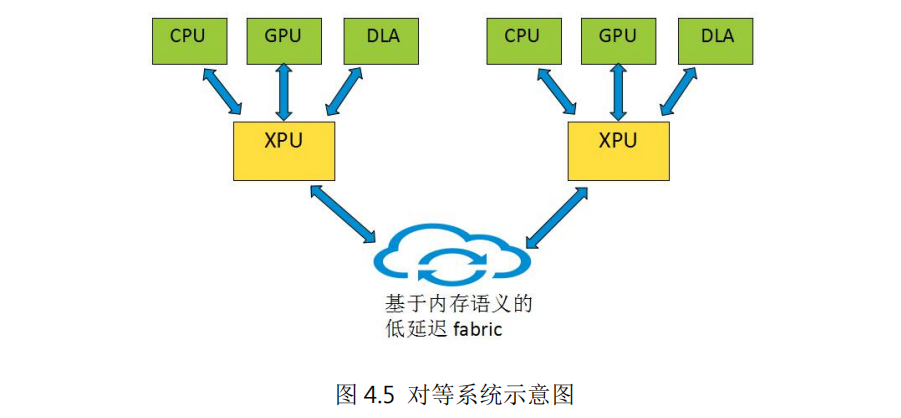
基于对等系统架构的服务器可以看成一个“分布式计算系统”,有利于产业链上各节点独立规划开发,发挥各自优势。比如 xPU 卸载 + 库/外 OS 演进 + APP direct 模式解决公共能力(存储、网络),整体性能的提升不再依赖于先进工艺;基于对等内存语义互联实现系统平滑扩展,将庞大分布式算力视为一台单一的“计算机”。
支撑算网融合的 IP 网络技术实现算力资源高效调度
算网深度融合有两大驱动力,一是需求侧,实现算力和网络的协同调度,满足业务对算力资源和网络连接的一体化需求。比如,高分辨率的 VR 云游戏,既需要专用图形处理器(GPU)计算资源完成渲染,又需要确定性的网络连接来满足 10 ms 以内的端到端时延要求。二是供给侧,借助于网络设施天生的无处不在的分布式特点,算网深度融合可以助力算力资源也实现分布化部署,满足各类应用对于时延、能耗、安全的多样化需求。
算网融合给 IP 网络技术提出了挑战。在互联网整个技术架构中,通常来说算对应着上层的应用,网对应着底层的连接,IP 技术作为中间层,起到承上启下的枢纽作用。传统的IP 网络遵循的端到端和分层解耦的架构设计,使得业务可以脱离网络而独立发展,极大降低了互联网业务的创新门槛,增加了业务部署的便利。但是在这样的设计架构之下,业务和网络处于“去耦合“的状态,最终绝大多数业务只能按照“尽力而为”的模式运行。
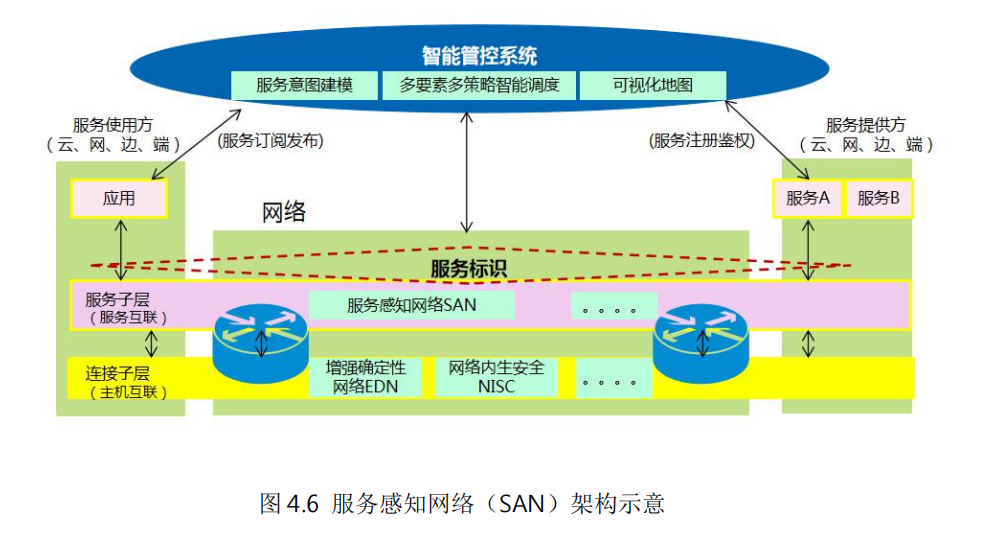
如何建立业务和网络之间的桥梁,实现算力资源、网络资源的协同和精细化管理,是未来 IP 网络面临的一大挑战。中兴通讯提出的“服务感知网络(SAN,Service AwarenessNetwork)”是在这个方面的创新尝试
下载链接:
硬件RAID与软件RAID:哪一种最适合?
AI产业人士看大模型发展趋势(2023)
深度报告:从Rambus看内存接口芯片机会
电子行业报告:顺复苏之势,乘AI之风(2023)
“九州”算力光网目标架构白皮书
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


