

前天有个新闻上了头条,讲AMD最近拿到几个大单,包括Oracle、IBM。Oracle计划在云服务中采用AMD Instinct MI300X AI芯片,以及HPC用GPU;IBM预计将采用AMD的Xilinx FPGA解决方案,用于人工智能工作负载。

英伟达GPU供不应求,导致了大量需求溢出,以至于Oracle成为了首批部署MI300X的公司之一。这就像是我们去吃饭,想去的网红餐厅排队人山人海,但吃饭总得要吃,不行就另找一家好吃的。
MI300X尚处于“襁褓之中”,将于第四季度推出,目前还在提供样品阶段。AMD的软件生态也没有英伟达那么完善。训练和运行AI大模型不仅仅取决于GPU性能,系统设计也尤为重要。
IBM却不太一样,IBM的AI推理平台使用了NeuReality的NR1芯片,而AMD(Xilinx)的FPGA加速产品在其中发挥了关键作用。
NeuReality 是一家于 2019 年在以色列成立的初创公司,2021年2月,NeuReality推出了 NR1-P,这是一个以AI为中心的推理平台。2021年11月,NeuReality 宣布与IBM建立合作伙伴关系,其中包括许可IBM的低精度AI内核来构建 NR1。

NR1是NeuReality NAPU系列中基于FPGA的芯片,这是一种具有嵌入式AI推理加速器以及网络和虚拟化功能的SoC。据NeuReality透露,与其他深度学习芯片供应商的GPU和ASIC方案相比,NR1的每美元性能将提高15倍。
按照我的理解,NeuReality可以算是Xilinx FPGA在AI领域的方案商,在其基础上提供基于FPGA的AI推理加速平台。
在芯片或者人工智能领域,新闻传播讨论最多的是台积电,英特尔,英伟达,AMD等著名公司,大家好像已经听不到IBM的声音了,低调的蓝色巨人似乎已经退居幕后。
然而,IBM仍然是大佬中的大佬,在芯片和人工智能领域无法忽视的存在。10月25日IBM发布了第三季度财报,季度收入达到147.5亿美元,营业利润率从11.4%扩大至14.8%。
在IBM的历史上,在芯片和人工智能非常辉煌。
1960年,IBM开发出倒装芯片封装技术,提高组件可靠性。
1966年,IBM提出了单晶体管DRAM的想法。
1974年,IBM研究院设计了采用精简指令集计算机 (RISC) 架构计算机原型,该架构沿用至今。
在芯片领域的贡献,IBM还包括CMP、SiGe stress、ArF光刻、计算机化光刻技术、化学增量光刻及绝缘层上硅(SOI)技术、Power处理器、AI芯片、量子芯片等。
2020年,IBM研发出一种基于相变存储器(PCM)的非·冯诺依曼架构芯片技术,能像人脑一样在存储中执行计算任务,以超低功耗实现复杂且准确的深度神经网络推理。

2022年10月,IBM发布首款人工智能计算单元(Artificial Intelligent Unit,AIU)片上系统,AIU专为加速深度学习模型使用的矩阵和向量计算而设计和优化,不仅可以解决计算复杂的问题,并以远远超过CPU能力的速度执行数据分析。

在量子计算领域,2020年,IBM发布了65量子位的Quantum Hummingbird。2022年11月10日,IBM发布433个量子比特的Osprey芯片。2023年,IBM将发布1123比特的IBM Quantum Condor。IBM也计划在2025年推出一个超过4000个量子比特的系统。

在芯片制程研发方面,IBM 每次都能抢在传统芯片制造商之前,设计出新制程的原型芯片来。比如说10nm芯片是由他们在2014年研发出来的,到了2017年才量产,5nm 芯片在 2015年提出,到2018年量产。
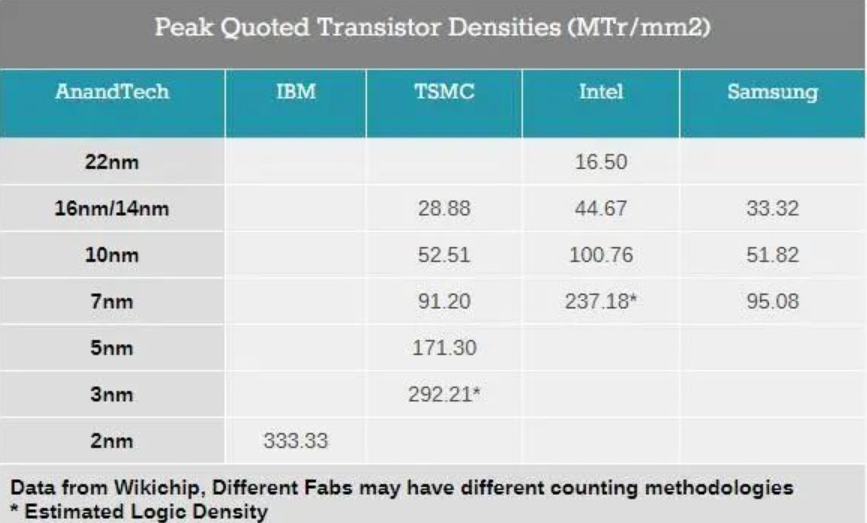
而在2021年,IBM率先推出了全球首个2nm芯片,采用纳米片堆叠的晶体管,也被称为GAA晶体管。

IBM的基础研究实力,是整个世界IT科技树的树根之一,完全不受现有框框的束缚,方向激进而前瞻。
IBM和Xilinx的合作关系,早在AMD进来之前,两家的策略联盟已经持续多年了。
早期Xilinx发布V5系列的FPGA时,就已经将IBM公司的PowerPC硬核集成在其芯片中。
2015年,当微软成功引入Altera FPGA对其Bing搜索引擎数据中心进行加速改造后,IBM当即启动与Xilinx的合作,共同研发FPGA加速平台。
2017年IBM打造的新服务器架构方案,将FPGA和服务器的CPU分离,直接将FPGA连接到数据中心的网络之中。这种解决方案将会使FPGA作为一种单独的计算单元,将多个FPGA单元形成的集群用于新兴的超大规模数据中心中使用的服务器。
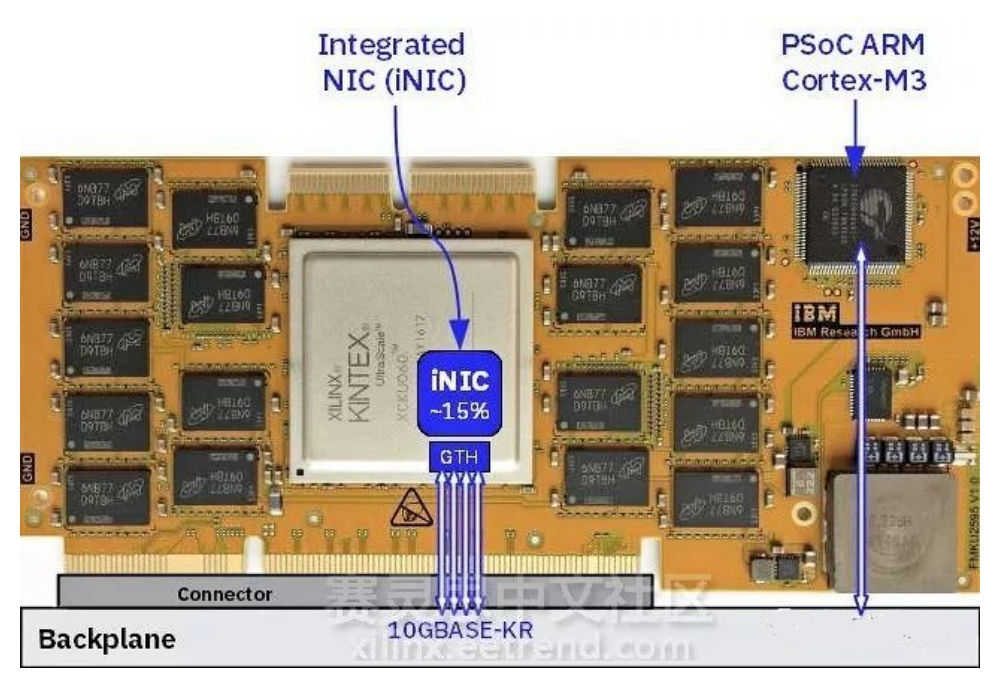
IBM的研究室里,科研人员将64个Xilinx公司的Kintex UltraScale XCKU060 型号的FPGA集成到一起形成一个服务器插片单元,能够达到最大带宽640Gb/s。将16个基本的插片单元集成在一个服务器的柜子上,便形成了一个有着1024个FPGA和16TB的2400Mb/s的DDR4内存的服务器。这个平台充分考虑了成本效率,使用水冷的方式实现了最优的能量效率。

将FPGA从传统的通过总线链接到CPU的方法中解放出来,使FPGA在数据中心的大规模部署成为可能。将传统的机架式服务器和刀片式服务器变成了许多微服务器节点的集合体,通过共享例如电源供给、PCB背板、网络链接等服务器资源来提高服务器的集成度,从而大大提高服务器的单位价格的性能参数(performance-per-dollar)。详细内容见IBM的论文,“An FPGA Platform for Hyperscalers,”发表在2017年8月的IEEE Hot Interconnects Conference上。
今年,IBM又宣布其协同加速处理器接口(CAPI)全面支持Xilinx FPGA和Power处理器,IBM将开发并验证装置于IBM Power Systems服务器的赛灵思加速板,赛灵思正着手开发并将推出软件定义SDAccel开发环境POWER专属版本,以及专为OpenPOWER开发者社群提供的的函数库。
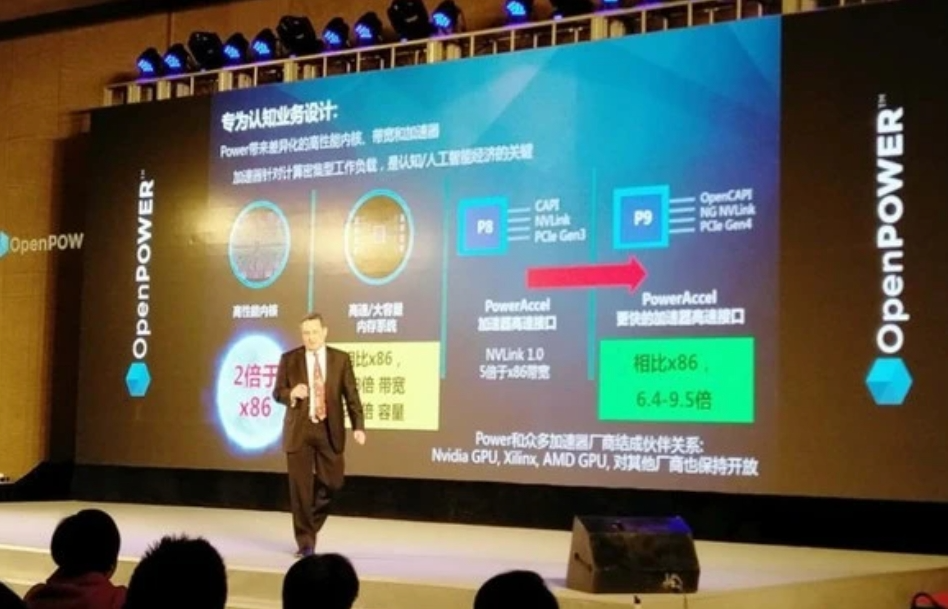
对比GPU,FPGA的优势在于更低的功耗和时延。GPU无法很好地利用片上内存,需要频繁读取片外的DRAM,因此功耗非常高。FPGA可以灵活运用片上存储,因此功耗远低于GPU。另外,FPGA的架构,使其在AI推理中相比GPU具有非常强的时延优势。
FPGA加速板卡在2018年只有10亿美元的市场规模,Semicon研究报告预计今年将超过50亿美元。
数据中心的AI算力市场上,目前英伟达的GPU是如日中天,在AI芯片市场中占比最高,达91.9%。NPU、ASIC、FPGA市场占比分别为6.3%、1.5%、0.3%。
英伟达成功的主要原因,我认为还是CuDA的生态比较好,程序员覆盖面广,开源资源和成熟方案应有尽有,国内大模型技术大多由海外开源搬运而来,因此绝大多数都会采用现成的英伟达方案。
但是仅就AI算力前沿技术的高速发展来看,国外仍然会呈现百花齐放互相追赶的态势,无论是谷歌的TPU,还是IBM的Power架构,抑或是Intel/AMD的异构加速芯片,都将长期角逐市场。这么大的一块肉,没有大佬会放弃。
AI算力的中场战事才刚刚开始。
文章来源于土人观芯,作者
AMD FPGA/SoC 技术盛会!
报名开启,坐席有限!
【11月28日 北京】

