

昨晚手机大厂新机发布会,提到对存储这块创新了一个功能,作为存储行业的搬运工总觉得哪里有问题。我们先看下原文。
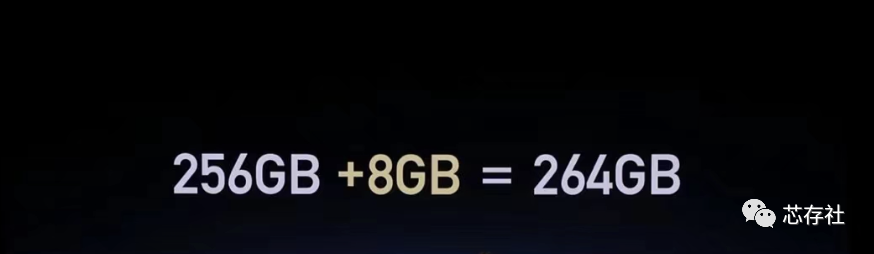
Ultra Space
文中也提到了是将存储芯片中预留的额外空间,选取部分空间给用户,那么我们现在就来了解下预留空间。
在了解预留空间前我们先普及下目前手机存储里面的主流芯片eMMC和UFS。
此前也有写文章介绍不同存储芯片的区别:一文看懂NAND、eMMC、UFS、eMCP、uMCP、DDR、LPDDR及存储器和内存区别
eMMC ( Embedded Multi Media Card) 采用统一的MMC标准接口, 把高密度NAND Flash以及MMC Controller封装在一颗BGA芯片中。针对Flash的特性,产品内部已经包含了Flash管理技术,包括错误探测和纠正,flash平均擦写,坏块管理,掉电保护等技术。用户无需担心产品内部flash晶圆制程和工艺的变化。同时eMMC单颗芯片为主板内部节省更多的空间。
简单地说,eMMC=Nand Flash+控制器+标准封装
eMMC的整体架构如下图片所示:
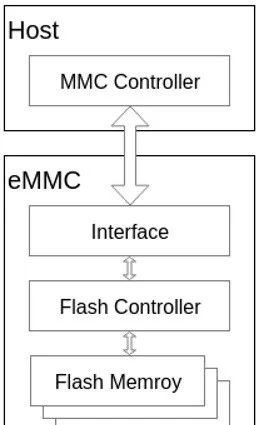
eMMC 则在其内部集成了 Flash Controller,用于完成擦写均衡、坏块理、ECC校验等功能,让 Host 端专注于上层业务,省去对 NAND Flash 进行特殊的处理。
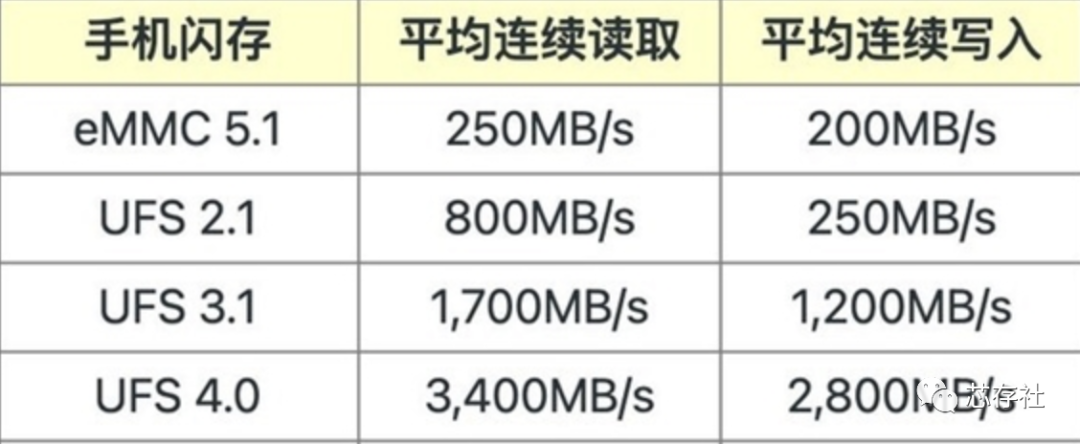
UFS:Univeral Flash Storage,我们可以将它视为eMMC的进阶版,是由多个闪存芯片、主控、缓存组成的阵列式存储模块。UFS弥补了eMMC仅支持半双工运行(读写必须分开执行)的缺陷,可以实现全双工运行,所以性能得以翻番。
UFS早前被细分为UFS 2.0和UFS 2.1,它们在读写速度上的强制标准都为HS-G2(High speed GEAR2),可选HS-G3标准。而两套标准又都能运行在1Lane(单通道)或2Lane(双通道)模式上,一款手机能取得多少读写速度,就取决于UFS闪存标准和通道数,以及处理器对UFS闪存的总线接口支持情况。
UFS 3.0引入了HS-G4规范,单通道带宽提升到11.6Gbps,是HS-G3(UFS 2.1)性能的2倍。而由于UFS支持双通道双向读写,所以UFS 3.0的接口带宽最高可达23.2Gbps,也就是2.9GB/s。此外,UFS 3.0支持的分区增多(UFS 2.1是8个),纠错性能提升且支持最新的NAND Flash闪存介质。
为了满足 5G 设备的需求,UFS 3.1 的写入速度是上一代通用闪存存储的 3 倍。此驱动器的 1,200 百万字节/秒 (MB/s) 速度可增强高性能,有助于防止下载文件时缓冲,从而在连接频繁的世界中享受 5G 的低延迟连接性。
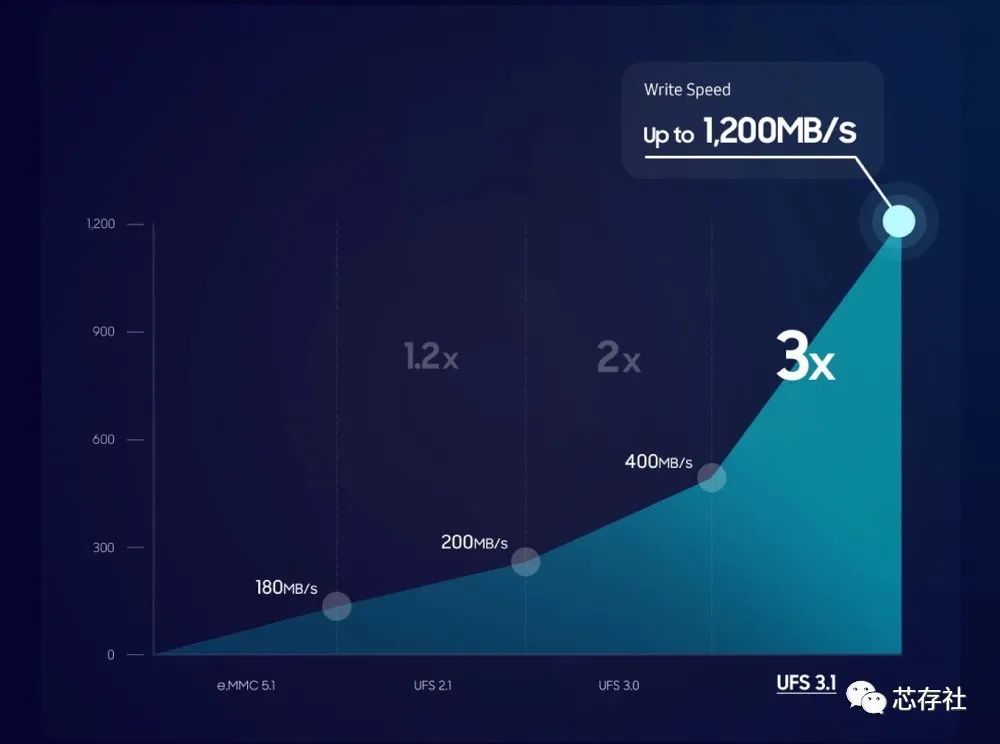
2022年8月JEDEC(固态存储协会)正式公布了JESD220F标准文档,也就是UFS 4.0正式版。
新一代UFS 4.0在互连层上遵循MIPI联盟的通用规范,其中物理层基于M-PHY v5.0、传输层基于UniPro v2.0。由此,接口带宽翻番到23.2Gbps,允许最大4.2GB/s的读写速度。
同时,UFS 4.0引入VCC=2.5V的新电压规范,比之前的3.3V效率更高,也就是更省电。
此外,UFS 4.0标准还在循环队列、数据安全保护、错误记录等多方面有了改进,延迟更低,且向下兼容UFS 3.0/3.1。
UFS的一些关键特点:
高性能:UFS提供了高速的数据传输速度,可达到Gb级别的传输速率。它采用高速串行接口,实现了快速的读写操作,支持多通道操作以提高并发性能。
2.大容量:UFS支持多个存储芯片的并行操作,从而实现了高容量的存储解决方案。它的容量范围从几十GB到几TB不等。
3.低功耗:UFS在设计上考虑了低功耗,以满足移动设备等电池供电应用的需求。它支持快速进入和退出休眠状态,以降低待机功耗,并优化了数据传输算法以降低活动功耗。
4.可靠性:UFS提供了高度可靠的数据完整性保护和错误检测与纠正(ECC)功能,以确保存储数据的可靠性。它还支持高级闪存管理功能,如坏块管理和写入放大抑制,以延长存储器寿命并提高可靠性。
5.兼容性:UFS具有较高的兼容性,可以与现有的存储接口标准(如eMMC)和文件系统兼容。这意味着现有的设备可以通过简单的硬件和软件更新来支持UFS存储。
总的来说,UFS是一种高性能、高容量和低功耗的闪存存储器解决方案,适用于移动设备和消费电子产品。
所以不管是eMMC还是UFS最重要的存储单元的还是NAND Flash芯片。
NAND Flash是一种非易失存储介质(掉电后数据不会丢失),常见的手机平板存储、U盘、TF卡/SD卡,以及大部分SSD都是由它组成的。
一、Flash基本组成单元:SLC/MLC/TLC
Flash的基本组成单元是浮栅晶体管,其状态可以用来指示二进制的0或1。写操作就是往晶体管中注入电子,使之充电;擦除操作则是把晶体管中的电子排出,使之放电。由于这是个模拟系统,晶体管并不存在绝对的空和满状态,其中的电子数目可以处于空和满之间的任一个状态。
也就是说,量化等级越高,一个晶体管可以表示的状态越多,存储密度就越大,同等数量的存储单元组成的存储介质,存储容量也越大。
 NAND Flash的寿命在很大程度上受所用存储单元类型影响,单个晶体管中存放的状态越多,容错性越差,寿命越短。
NAND Flash的寿命在很大程度上受所用存储单元类型影响,单个晶体管中存放的状态越多,容错性越差,寿命越短。
不同组成单元对Flash性能和寿命的影响
从上面的原理可以看出,SLC、MLC、TLC的性能和寿命是递减的,存储密度是递增的。 下面是一组具体的数据:
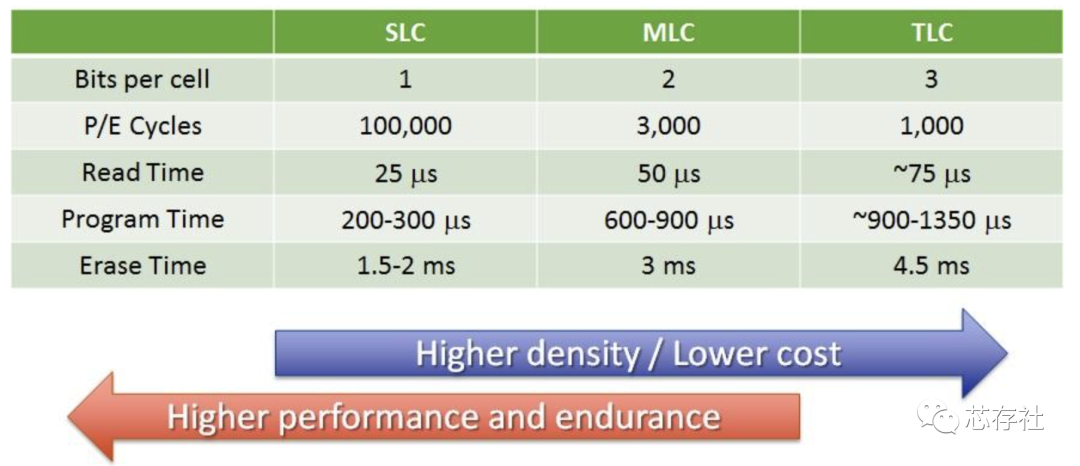
从上图可以看出:
随着每个单元代表的比特数增加,读、写、擦除耗时也在增加
无论是SLC还是MCL、TLC,擦除耗时(ms数量级)都远高于读写耗时(us数量级)
SLC的擦写次数远大于MLC、TLC,也就是说寿命长。
SLC每个晶体管只能代表一个比特,从存储密度看,是最低的,TLC存储密度最高,MLC次之。
总的来看,SLC的性能、寿命、稳定性是优于MLC的,当然价格也更贵,MCL次之,TLC最次。
二、Flash的结构及特点
Flash的结构
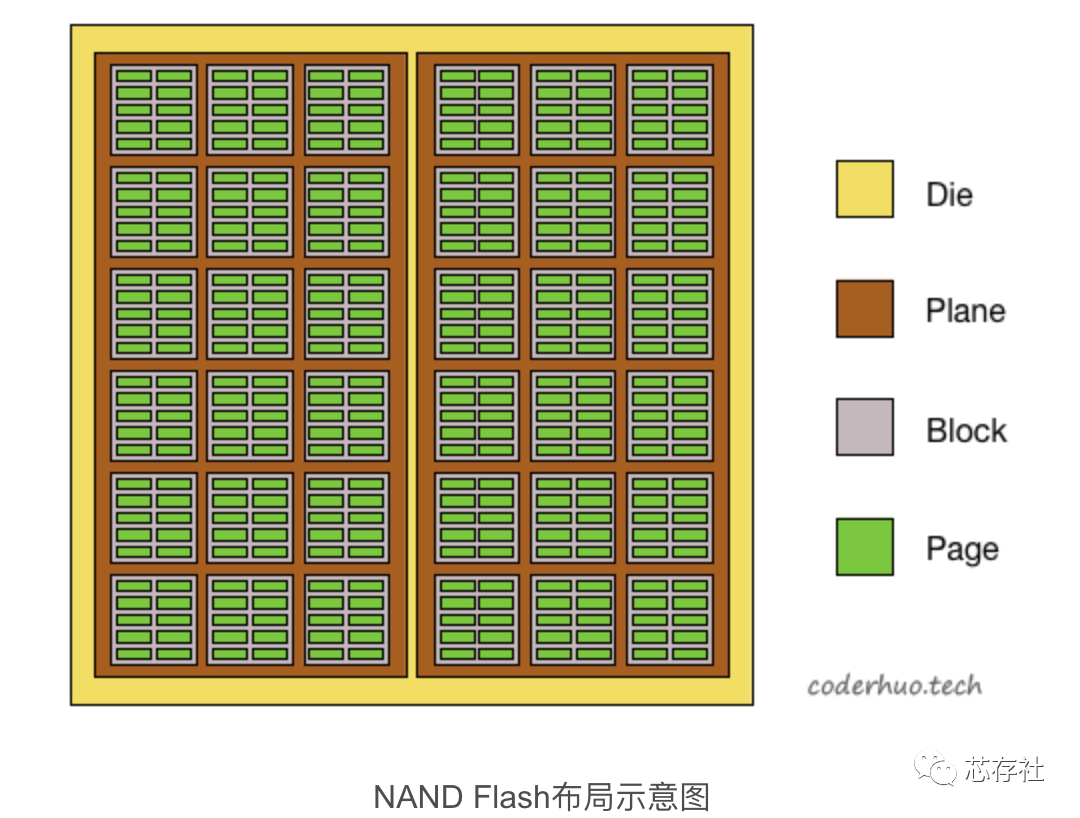
Flash中存在下面几个基本概念:package、die、plane、block、page(page对应于普通硬盘HDD中的sector,即常说的扇区)。 下面是一个示意图,我们由大到小拆解下:
package是存储芯片,即拆解固态硬盘或者SD卡后看到的NAND Flash颗粒。
每个package包含一个或多个die。die是可以独立执行命令并上报状态的最小单元。
每个die包含一个或多个plane(通常是1个或2个)。不同的plane间可以并发操作,不过有一些限制。
每个plane包含多block*,block是最小擦除单元。
每个block包含多个page, page是最小的读写单元。
这里我们需要重点关注的是:
读写的操作对象是page,通常是512字节或者2KB
擦除的对象是block,通常包含32或64个page(16KB或64KB)
每个block在写入前需要先擦除
block擦除前,需要保证本block上所有page中都不包含有效数据(如果有些page包含有效数据,需要先搬移到其他地方)
 Flash还有一个重要特性:Flash不支持更新操作,严格说应该是不支持原址更新。 如果我们已经往某个page中写入了数据,想修改这个page中的内容,只能通过下面的方法:
Flash还有一个重要特性:Flash不支持更新操作,严格说应该是不支持原址更新。 如果我们已经往某个page中写入了数据,想修改这个page中的内容,只能通过下面的方法:
先把本page所属block的数据全部读出来,比如先读到内存DRAM
然后修改对应page的内容
接下来擦除整个block
最后把修改后的block数据回写到Flash
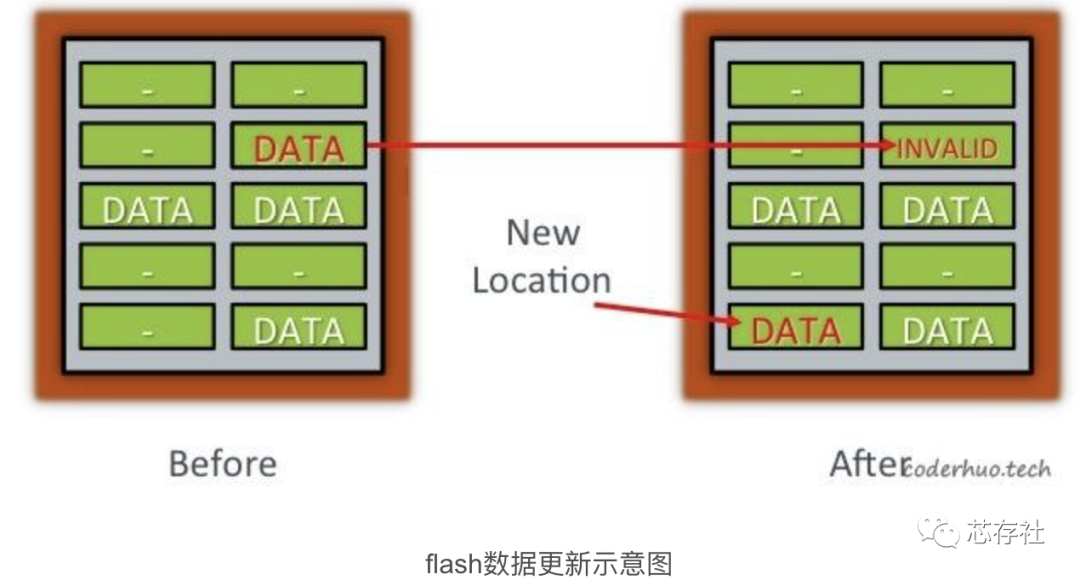
Flash芯片上block的擦写次数是有限的,最大擦写次数称为PE Cycles(Program erase cycles, 往Flash写入的过程又称为编程过程,即program)。如果采用上面的方法进行原址更新,Flash很容易就会被用坏的。一个折中的方法是:将新数据写到一个新的page中,并将原来的page标记为无效,如下图所示:
说明:新的page和老的page可以位于同一个block,也可以位于不同的block,甚至位于不同的die。
 磨损均衡
磨损均衡
每个block的最大擦写次数(P/E Cycles)基本上是一样的,磨损均衡(Wear Levelling)的作用是保证所有block被擦写的次数基本相同。这就要求磨损均衡算法要把擦写操作均摊在所有的block上。
如果所有block上的数据都经常更新,磨损均衡算法执行起来问题不大。如果有些block上存在冷数据(写入之后就很少更改的数据),我们必须根据一定的策略强制搬移这些数据并擦写对应的block,否则这些block就永远不会被擦除。当然这种操作会增加系统负载,同时也加大了整个系统的磨损(产生了不必要的擦写)。
实际上,磨损均衡算法越激进,系统的磨损越严重;但是如果磨损均衡算法太消极,会导致两极分化,部分block被擦除次数较多,部分block被擦除次数较少。
垃圾回收
接下来我们需要处理page的回收问题(Garbage Collection)。Flash的擦除单元是block,这决定了垃圾回收的最小单元也是block。block回收过程中,需要确保待擦除block上无有效数据;如果有的话,需要搬移到其他的block(和磨损均衡一样,这也会增加额外的负担,实际应用中需要找到一个平衡点)。
为什么需要垃圾回收
我们假设一个简单的存储介质只包含5个block,每个block包含10个page。在初始化状态,所有的page都是空的,存储介质的可用空间是100%。
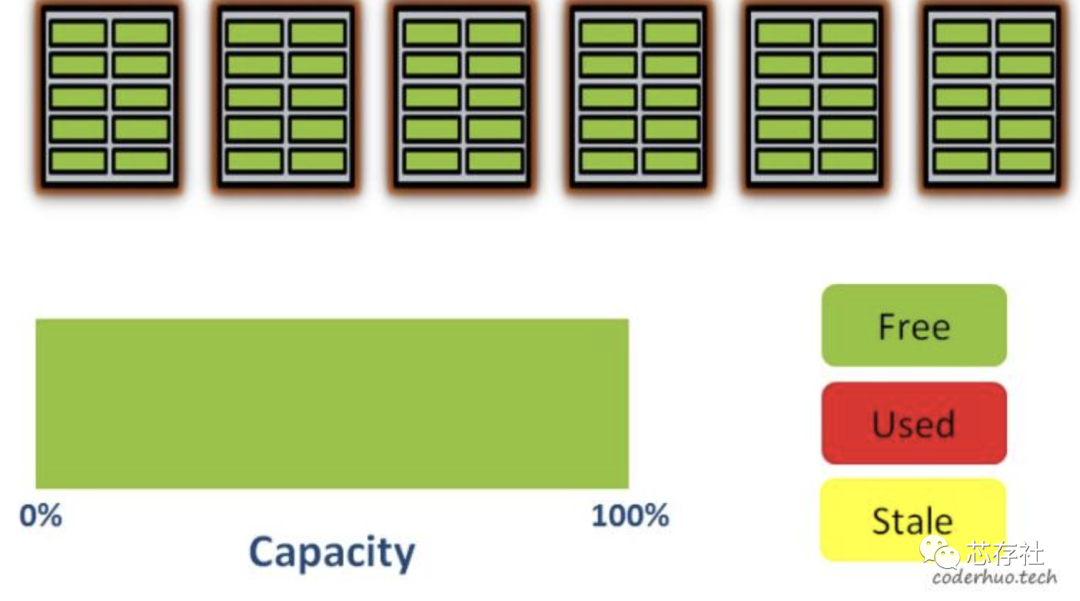 初始化状态
初始化状态
接下来写入一些数据(注意:写入的最小单元是page)。从下图可以看出,有些page已经被占用了,并且由于磨损均衡算法的作用,他们被分散在不同的block上:
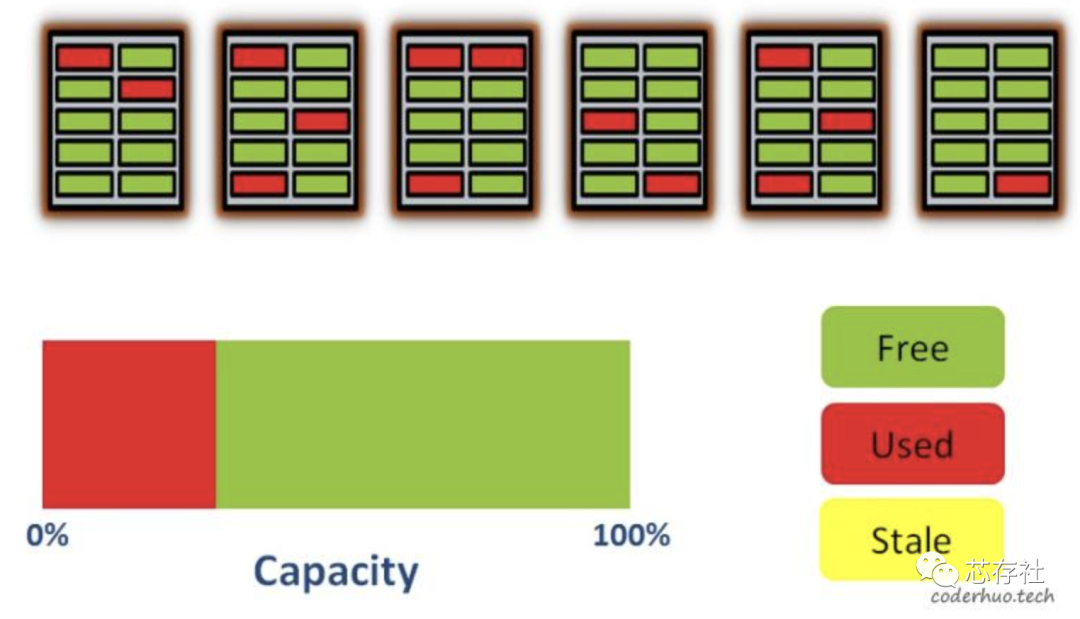 写入数据
写入数据
我们再继续写入一些数据,现在50%的空间被占用了,并且数据分散在各个block上(尽管在物理层面数据是分散在各个block的,FTL对外展现的可能是连续的):
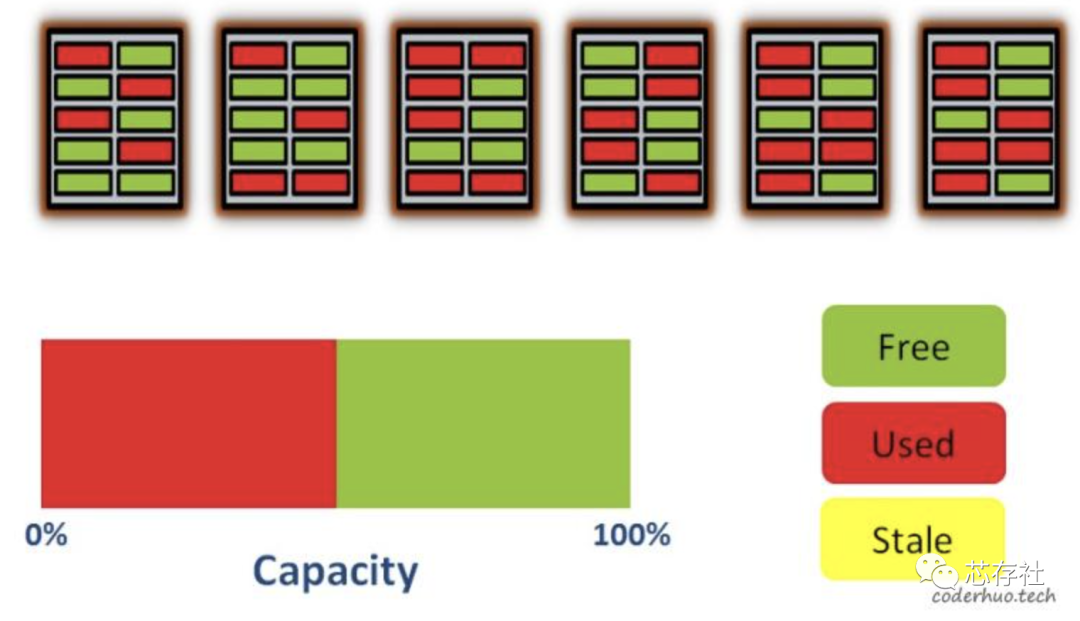 继续写入数据
继续写入数据
如果这时更新数据,FTL会选择一个空的page写入新数据,然后把老的page标记为stale状态(黄色标记块),如下图所示:
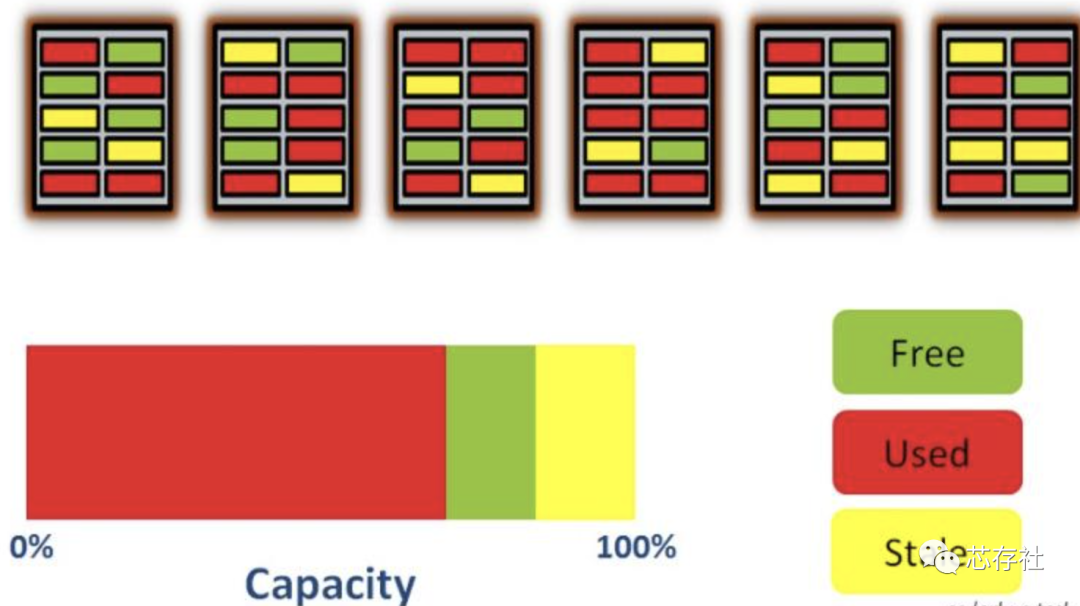 更新数据
更新数据
这时最左边的block包含2个stale状态的page和4个used状态的page,为了回收stale状态的page,必须先把4个used状态的page拷贝到其他的block,然后再把最左边的block整个擦除掉。如果此时不执行该操作,继续写入新数据(或者更新现有数据),会耗尽所有free状态的page,尽管此时还存在stale状态的page,但是已经无法回收了(有效数据没法腾挪了),这时候整个存储介质会进入只读状态。
所以,Flash的FTL层需要执行垃圾回收策略,释放stale状态的page。
写放大因子
从上面的介绍我们了解到,磨损均衡和垃圾回收在一定程度上都会触发后台数据搬运。这些操作是在Flash内部进行的,外部通过任何方法都监控不到,外部唯一能感受到的就是性能受到影响,比如某次写很耗时。
这种现象叫做写放大(Write Amplification),可以通过下面的公式衡量。该值越大说明效率越低,会对存储介质的性能和寿命造成不良影响:
 写放大因子定义
写放大因子定义
公式的分子是实际写入到Flash的数据量,分母是有效数据量。比如一次写入5KB数据,但是由于磨损均衡或者垃圾回收导致后台产生了数据搬运,实际写入数据量是10KB,那么,写放大因子就是2。
预留空间
一般情况下,存储介质的实际存储空间都大于标称空间(一般多7%左右,具体根据各家芯片厂商而定),多出来的存储空间被称为预留空间(Over-Provisioning),这部分空间用户是无法使用的。它可以被用来进行数据腾挪,保证垃圾回收、擦写均衡的正常进行,如果有坏块产生,还可以作为替补block顶上去(在一定程度上,让用户感知不到坏块的存在)。
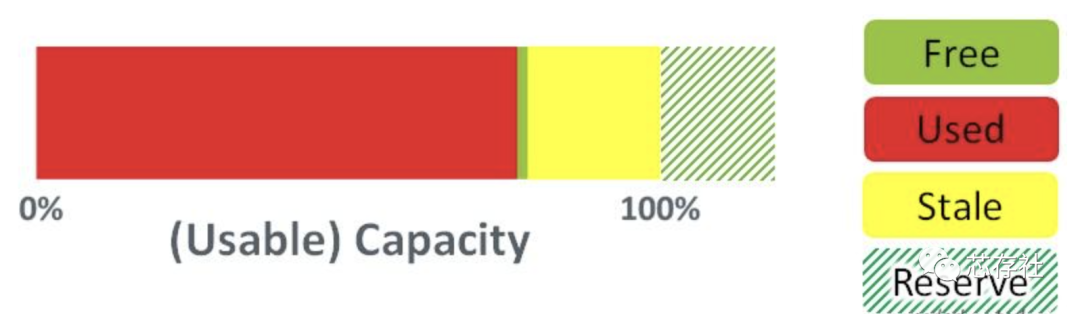
所以综上根据NAND Flash的结构和特性。在重度数据随机写入应用中,如果追求一定的性能的话,各家厂商还是倾向于增加一些NAND的OP。
所以如果是用牺牲存储预留空间去当做卖点,研发真的是遇到技术创新的瓶颈了吗?
以上仅个人拙见,或许真的是技术突破,各位如何看待,欢迎留言或者扫码添加微信进群讨论。
性能的计算公式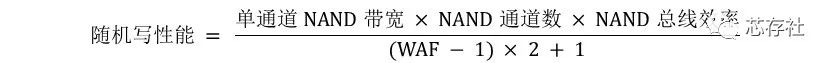 这个公式是基于一些极端的假设,包括NAND足够优秀、固件足够优秀、测试软件足够“聪明且恶意”等等。实际应用中,控制器、闪存、固件的匹配未必能这么完美,当然用户数据的写入也不会那么“恶意”。从定性的角度来说,存储性能与所有这些参数之间的关系,是不会变的。
这个公式是基于一些极端的假设,包括NAND足够优秀、固件足够优秀、测试软件足够“聪明且恶意”等等。实际应用中,控制器、闪存、固件的匹配未必能这么完美,当然用户数据的写入也不会那么“恶意”。从定性的角度来说,存储性能与所有这些参数之间的关系,是不会变的。
推荐阅读
MTK、高通、紫光展锐手机SOC平台型号对比汇总(含详细参数,更新至2023年2月份)
33家国产嵌入式存储器厂商汇总丨含产品介绍
全球前五大存储厂商产品介绍Roadmap及代理商信息
消费级、工业级、汽车级、军工级、航天级芯片区别对比
科普;设计一颗芯片有多难,芯片是如何制造的,一片晶圆能切割多少片芯片?
一文看懂NAND、eMMC、UFS、eMCP、uMCP、DDR、LPDDR及存储器和内存区别
SK hynix海力士DDR、LPDDR、UFS、eMMC、eMCP、uMCP规格型号参数对照表
三星内存eMCP、UMCP、eMMC、LPDDR、DDR型号参数对照表
KIOXIA 铠侠UFS、eMMC、NAND型号参数对照表
什么是集成电路、工艺、CPU、GPU、NPU、ISP、DSP ?存储器和内存的区别是什么
全面分析显示驱动芯片vs.晶圆代工厂制程节点和应用(专业收藏版)
WiFi发展史丨什么是WiFi6、WiFi6E和WiFi7以及参数对比
三星、苹果手机处理器参数及代表机型
一文看懂智能手机常用传感器
全球80家无线通信模组企业汇总及介绍
一个亿的融资在一家芯片初创公司可以烧多久?
全球移动通信射频前端厂商汇总(含晶圆、封测)
PCB板的价格是怎么算出来的(详解)
MCU最强科普总结(收藏版)
揭秘手机二手芯片内幕,展锐郑重声明
天然砂是什么?
