
本文来自“2023新型算力中心调研报告(2023)”。更多内容参考“《海光CPU+DCU技术研究报告合集(上)》 ”,“《海光CPU+DCU技术研究报告合集(下)》 ”和“龙芯CPU技术研究报告合集”。
积极引入新制程生产 CCD 的 AMD 对 SRAM 成本的感受显然比较深刻,在基 于台积电 5nm 制程的 Zen 4 架构 CCD 中,L2、L3 Cache 占用的面积已经达到整体的约一半比例。

△ Zen4 CCD 的布局,请感受一下 L3 Cache 的面积
向上堆叠,翻越内存墙
AMD 当前架构面临内存性能落后的问题,其原因包括核心数量较多导致的平均每核心的内存带宽偏小、核心与内存的“距离”较远导致延迟偏大、跨 CCD 的带宽过小等。这就促使 AMD 需要用较大规模的 L3 Cache 来弥补访问内存的劣势。而从 Zen 2 到 Zen 4 架构,AMD 每个 CCD 的 L3 Cache 都为 32MB,并没有“与时俱进”。为了解决 SRAM 规模拖后腿的问题,AMD 决定将 SRAM 扩容的机会独立于 CPU 之外。
AMD 在代号 Milan-X 的 EPYC 7003X 系列处理器上应用了第一代 3D V-Cache 技术。这些处理器采用 Zen 3 架构核心,每片 Cache(L3 Cache Die,简称 L3D)为 64MB 容量,面积约 41mm²,采用 7nm 工艺制造——回顾 ISSCC2020 的论文,7nm 恰恰是 SRAM 的微缩之路遇挫的拐点。
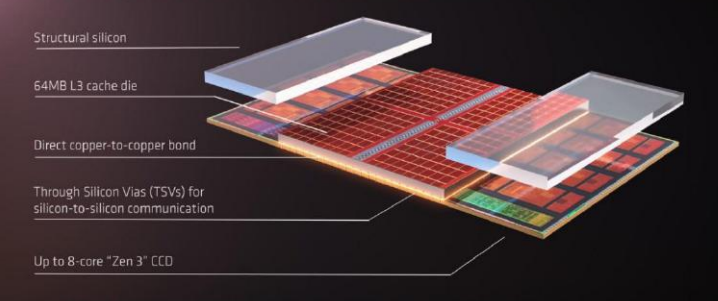
缓存芯片通过混合键合、TSV(Through Silicon Vias,硅通孔)工艺与 CCD(背面)垂直连接,该单元包含 4 个组成部分:最下层的 CCD、上层中间部分 L3D,以及上层两侧的支撑结构——采用硅材质,将整组结构在垂直方向找平,并将下方 CCX(Core Complex,核心复合体)部分的热量传导到顶盖。
AMD 在 Zen3 架构核心设计之初就备了这一手,预留了必要的逻辑电路以及 TSV 电路,相关部分大约使 CCD 增加了 4% 的面积。L3D 堆叠的位置正好位于 CCD 的 L2/L3 Cache区域上方,这一方面匹配了双向环形总线的 CCD 内的 Cache 居中、CPU 核心分居两侧的布局,另一方面是考虑到(L3)Cache的功率密度相对低于CPU核心,有利于控制整个 Cache 区域的发热量。

△ 3D V-Cache 结构示意图
Zen3 的 L3 Cache 为 8 个切片(Slice),每片4MB;L3D 也设计为 8 个切片,每片 8MB。两组 Cache 的每个切片之间是 1024 个 TSV 连接,总共 8192 个连接。AMD 宣称这外加的L3 Cache 只增加 4 个周期的时延。
随着 Zen4 架构处理器进入市场,第二代 3D V-Cache 也粉墨登场,其带宽从上一代的 2TB/s 提升到 2.5TB/s,容量依旧为 64MB,制程依旧为 7nm,但面积缩减为 36mm²。缩减的面积主要是来自 TSV 部分,AMD 宣称基于上一代积累的经验和改进,在 TSV 最小间距没有缩小的情况下,相关区域的面积缩小了 50%。代号 Genoa-X 的 EPYC 系列产品预计在 2023 年中发布。
SRAM 容量增加可以大幅提高 Cache 命中率,减少内存延迟对性能的拖累。AMD 3D V-Cache 以比较合理的成本,实现了 Cache 容量的巨大提升(在CCD 内 L3 Cache 基础上增加 2 倍),对性能的改进也确实是相当明显。代价方面,3D V-Cache 限制了处理器整体功耗和核心频率的提升,在丰富了产品矩阵的同时,用户需要根据自己的实际应用特点进行抉择。
那么,堆叠 SRAM 会是 Chiplet 大潮中的主流吗?

△ 应用 3D V-Cache 的 AMD EPYC 7003X 处理器
说到这里,其实是为了提出一个外部 SRAM 必须考虑的问题:更好的外形兼容性。堆叠于处理器顶部是兼容性最差的形态,堆叠于侧面的性能会有所限制,堆叠于底部则需要 3D 封装的进一步普及。对于第三种情况,使用硅基础层的门槛还是比较高的,可以看作是 Chiplet 的一个重大阶段。以目前 AMD 通过 IC 载板布线水平封装 CCD 和 IOD 的模式,将 SRAM 置于 CCD 底部是不可行的。至于未来 Zen 5、Zen 6 的组织架构何时出现重大变更还暂时未知。
对于数据中心,核数是硬指标。表面上,目前 3D V-Cache 很适合与规模较小的 CCD 匹配,毕竟一片 L3D 只有几十平方毫米(mm²)的大小。但其他高性能处理器的核心尺寸比 CCD 大得多,在垂直方向堆叠 SRAM 似乎不太匹配。但实际上,这个是处理器内部总线的特征决定的问题:垂直堆叠 SRAM,不论其角色是 L2 还是 L3 Cache,都更适合 Cache 集中布置的环形总线架构。
首先,不去 CPU 所在的 die 里抢地盘;
其次,纵向堆叠封装,可通过提升存储密度实现扩容;

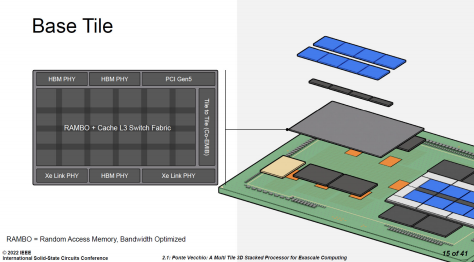
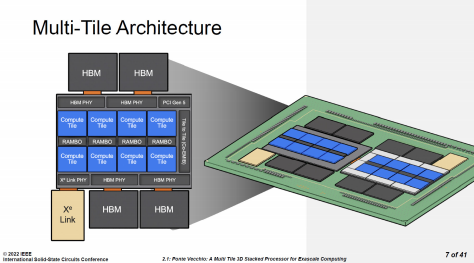

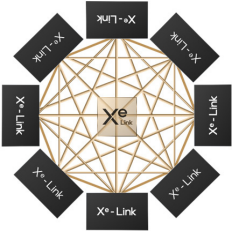


换句话说,对于网格化的处理器,将 L3 Cache 移出到基础芯片是有合理性的。目前已经成熟的 3D 封装技术的凸点间距在 30~50 微米的量级,足够胜任每平方毫米内数百至数千个连接的需要,可以满足当前网格节点带宽的需求。更高密度的连接当然也是可行的,10 微米甚至亚微米的技术正在推进当中,但优先的场景是 HBM、3D NAND 这种高度定制化的内部堆栈的混合键合,未必适合 Chiplet 对灵活性的要求。
《FMS 2023闪存峰会CXL合集(1)》
3、数据中心绿色设计白皮书(2023)
4、新型数据中心高安全技术体系白皮书
数据中心绿色设计白皮书(2023)
存储系统性能和可靠性基础知识
云基建专题:AI驱动下光模块趋势展望及弹性测试
精华:数据库系统的分类和评测研究
可重构计算:软件可定义的计算引擎
近存及存内计算专题简介
集装箱冷板式液冷数据中心技术规范
浸没式液冷发展迅速,“巨芯冷却液”实现国产突破
两相浸没式液冷—系统制造的理想实践
浸没液冷服务器可靠性白皮书
天蝎5.0浸没式液冷整机柜技术规范
AIGC加速芯片级液冷散热市场爆发
某液冷服务器性能测试台的液冷系统设计
《智能存储与磁盘故障预测合集》
《内存技术应用研究及展望合集》
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言删除,谢谢。
温馨提示:扫描二维码关注“全栈云技术架构”公众号,点击阅读原文进入“全栈云技术知识”星球获取10000+技术资料。


