酷渲科技成立于2017年,是一家致力于用科技推动组织能力提升的互联网企业服务公司,旗下有多款产品应用,如门店智能运营平台,目前已在零售、餐饮、鞋服、药店连锁、母婴快消、超市便利店、汽车养护、美妆护肤等10+行业领域积累4000+客户。此外,酷渲科技旗下还有多款科技创新应用。酷渲科技基于云器Lakehouse升级了数据基础设施为Single-Engine的一体化湖仓平台,已在多产品板块规模投产。新平台性能大幅提升,实现千万级数据表全域实时,并基于一体化引擎消除冗余数据,减轻数据治理负担,进一步结合按量计费模式大幅降低计算资源成本。本文作者:杨杰 酷渲科技研发总监
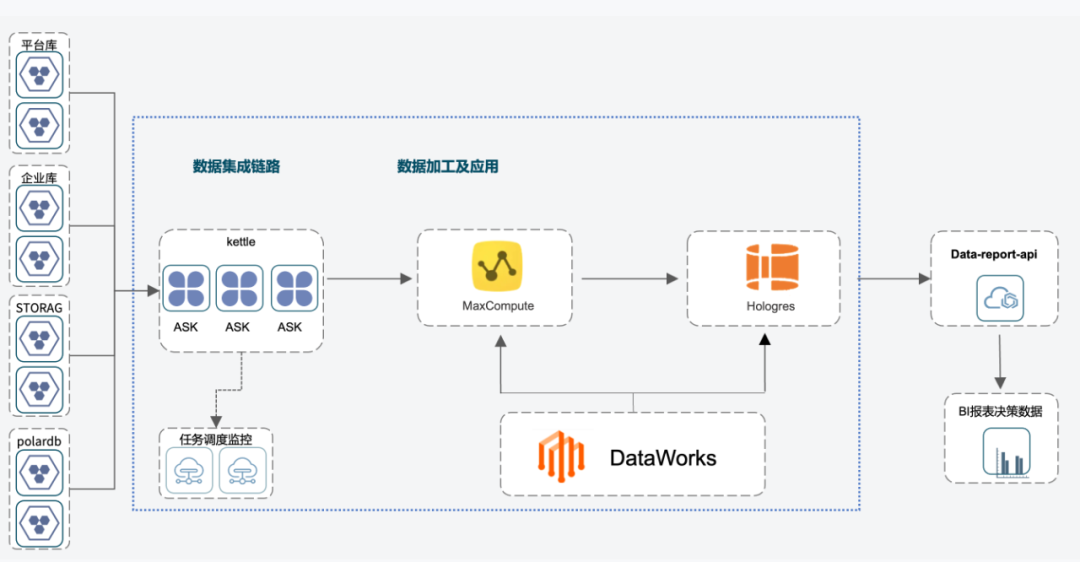
我们原有的数据平台,基于云服务组合构建,采用的是常见的lambda架构承载业务数据。但随着服务的企业客户规模增长,发现原有数据平台逐渐不能满足业务发展,主要的挑战是:1) 客户需要小时或分钟级数据。原有架构使用的是Kettle加MaxCompute,是专为大规模离线任务设计的数据链路,链路的更新周期是“T+1”——即今天的业务报表呈现的是截止到昨天的数据。而客户需要更高新鲜度的数据。2) 多客户分表造成数据库表膨胀问题。我们为每个客户配置独立的一套数据库,以实现业务侧数据相互隔离。每个数据库有几千到万级别的表。随着客户数量增长和新数据链路的开发,物理表数量很快膨胀到千万级,对数据集成、加工处理和升级改造带来了很大挑战。3) 架构导致数据冗余和高成本。数据在处理链路中被强制复制了多份,例如数据经由Kettle调度,进入MaxCompute,之后再将数据搬运到Hologres引擎进行一次加速计算。数据每经过一个独立的开源组件,就要存储一份,而一旦有处理逻辑需要调整,就有可能要在两个或者多个数据引擎上修改。数据治理的复杂度高,存储和计算资源消耗大。4) 任务存在高峰低谷,常驻数据资源浪费问题。我们数据加工的时间段,以及企业报表查询的时间段,都具有明显的高峰期和空闲期的特点,之前采用包年的形式,并按高峰期需求量预先购买一定的资源和服务,导致其在业务空闲期资源上的浪费。这种计费模式带来的高成本及资源浪费也让我们对成本压缩诉求越来越强烈。图1:原有数据平台架构
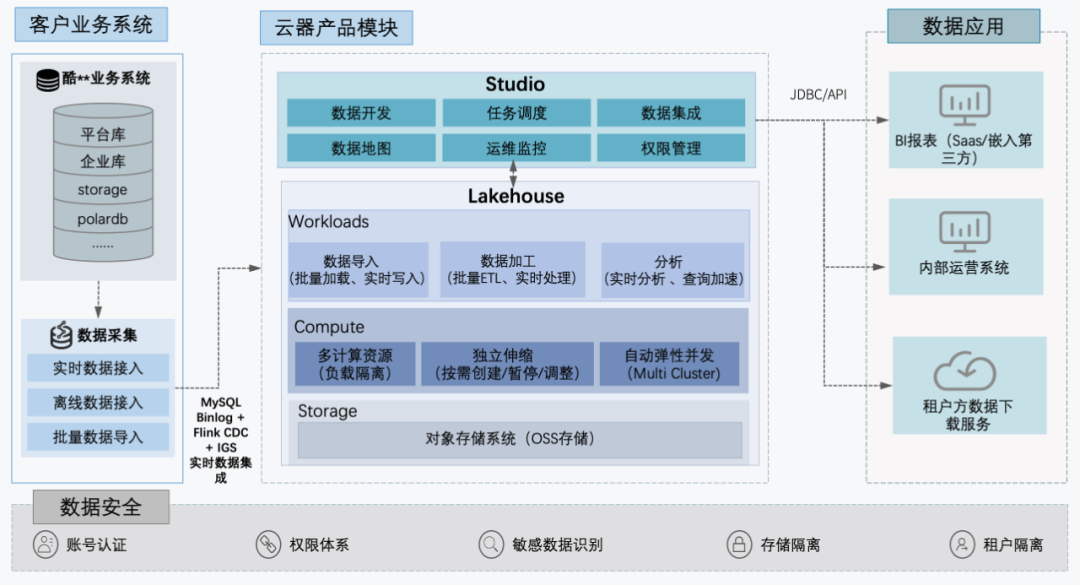
2) 降低资源消耗,保证数据分析查询同时控制计算资源成本;引入“云器Lakehouse”湖仓平台产品,完成平台升级经过多方选型验证,我们决定引入云器Lakehouse湖仓平台。 选择的过程并非一蹴而就,我们在选型阶段曾考虑过采用StarRocks、Doris等支持实时性的数据产品,评估过单产品能力项,结论认为可以将一部分数据分析时效性要求高的部分改造为实时链路;但我们同时也意识到,还需要在数据集成、任务调度和数据地图等琐碎的管理功能上增加系统组件,每增加一个组件都是后期的升级、运维成本。本质上我们升级的诉求是简化结构的同时实现全域实时,而我们发现组装式Lambda架构方案有2个矛盾,实时链路的数据新鲜度和成本是矛盾的,功能的复杂度和成本也是矛盾的。因此我们希望选择架构上更简单的,且能够同时支持实时离线一体化的全托管方案。业界能做到一体化的产品主要是Snowflake、Databricks等,国内能做到多云独立+离线实时一体的产品不多。经过调研,我们也了解到云器科技Lakehouse基于增量计算能力现实的Single-Engine引擎能满足一体化的需求,因此做了接触和尝试。经过技术评估、PoC测试和上线,验证发现能满足我们的需求。图2:基于云器科技产品升级后的数据平台架构
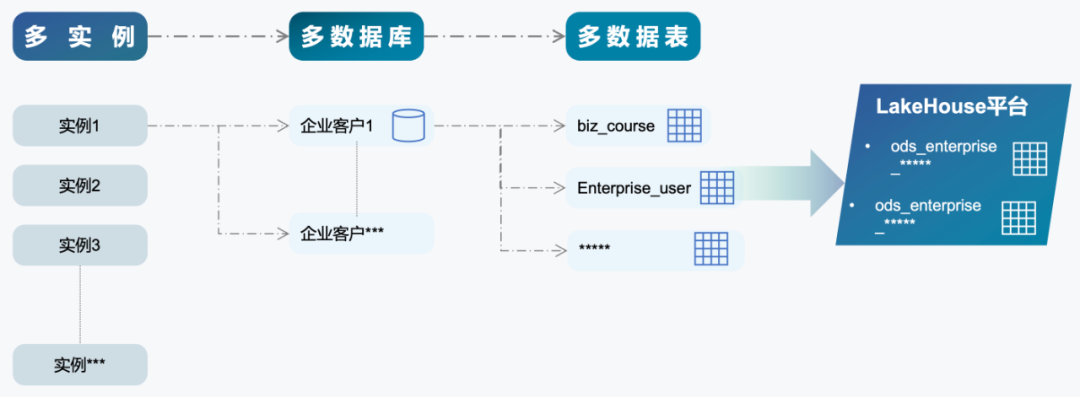
1) 实现千万级业务表的全量数据实时集成。原本成本是我们实现全量数据实时集成主要的顾虑,而新数据平台通过增量计算的方式实现流批一体,这种实现方式仅使用相对较小的资源就支撑起了千万级业务表规模的、全量的实时数据同步。增量计算实现实时的数据处理方式区别于传统流计算常驻资源,它将所有计算抽象成增量的形态,实现数据的一次计算、累次使用,所以可以节省计算资源;同时,能提供灵活调整的“增量时间间隔”,达成批处理或者流处理效果。图3:新的数据平台实现了千万级业务表的实时写入
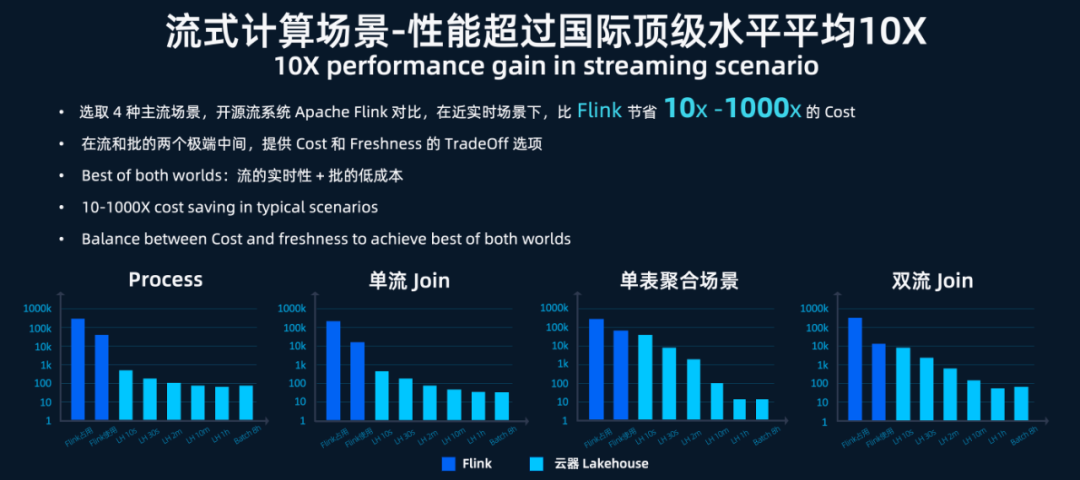
根据云器最近的测试,增量计算在近实时(小时级)的资源节省相对于流计算引擎有10倍的提升(详见下表)。图4:增量计算相对于流计算引擎的资源节省对比图
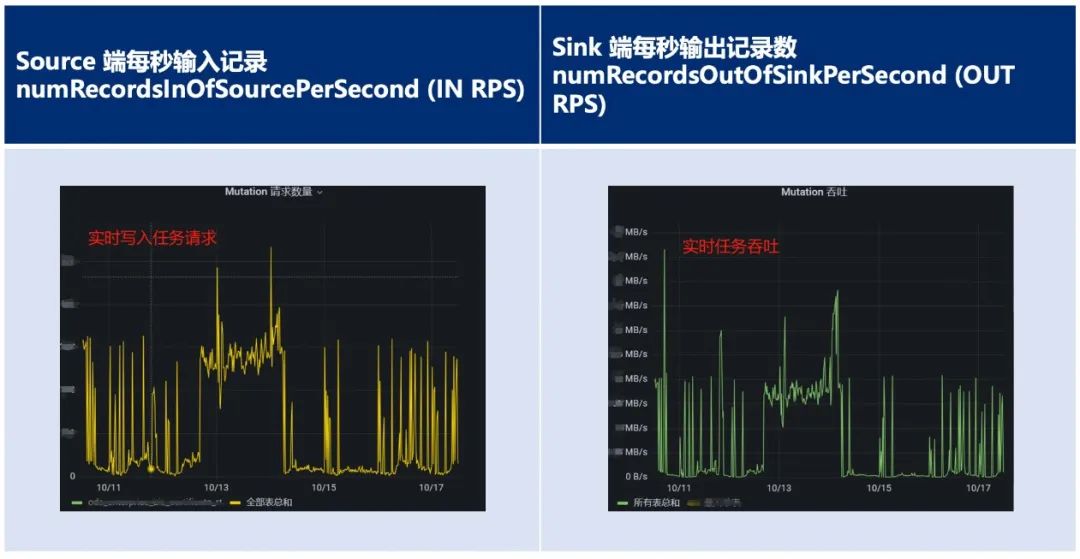
针对实时链路的压测,直接按生产环境要求,针对业务侧千万张表,单表字段在50~100个的上游业务库进行同步,单表单次写入规格在上百条左右,可以看出source侧和sink侧每秒数据吞吐服务运行平稳,,参考指标如下(7天):图5:Source端每秒输入记录和Sink端每秒输出记录数
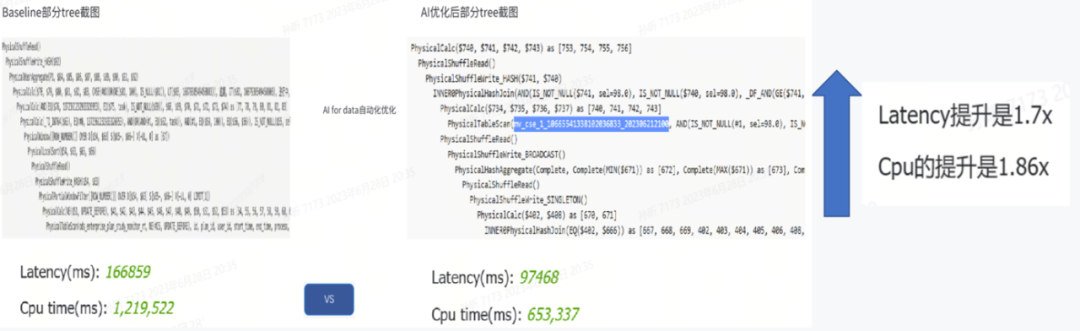
2) AI4D让数据任务执行性能提升2倍以上。我们业务代码中用了大量的virtual view;很多相同的virtual view会在不同的query间被使用到,仅靠数据工程师人工调优,效率很低。AI4D是指通过平台自主学习数据和负载的特性,做基于算法和 AI 的自动化调整,从大量任务中识别、抽取出重复计算的部分加以利用,这样不仅降低了计算消耗,而且提升了数据工程师的工作效率。图6:某段SQL经过AI4D优化后的执行效率对比
图7:新旧数据平台的任务执行时长对比
3) 消除数据冗余,离线实时一体。前面提到Lambda架构有数据冗余存储的问题,本次升级后,基于Single-Engine理念的一体化平台让数据从加工到调度、运维都简单很多。以下图为例,数据工程师只需一次对任务代码进行修改,数仓中贴源层数据与业务侧数据会始终一致,没有数据冗余和指标冗余的顾虑。此外,Single-Engine的离线和实时融合统一,只需调整调度就可切换,精益平衡数据新鲜度与成本。图8:一体化架构上数据加工处理链路
4) 按量计费节省,计算成本降低50%。新平台采用按使用量计费的模式,即最终的费用是根据对计算、存储、网络等资源的实际使用量进行计算。其中的计算资源,则是按计算集群的实际运行时间进行计算,当计算集群停止后,即不再计费。并且,很重要的一点是,由于新平台在计算性能上相比以往有了大幅提升,因此同等规模的计算资源下,在新的数据平台执行计算任务会大幅节省时间,从而可以进一步降低使用成本。新平台上线生产环境后,我们也总结的效果和价值,因为PoC的过程相对完备,生产上线效果比较一致,在此概略总结:图9:一体化平台数据平台架构运行示意图
1) 各类指标、报表和大屏提供了高效的数据服务。数据新鲜度从“T+1”到“H+1”的升级,让我们的客户可以及时查看了解业务的进展和效果,提升了产品及服务体验。2) 全托管的数据服务模式,让我们的数据人员可以更专注于数据价值开发,扩展数据分析和洞察能力。不用自己搭建或购买各种组件来进行开发、维护,同时平台中的弹性扩展和AI优化能力对性能也提供很好的SLA保障。3) 达到降本增效的升级目标。一方面,新的数据平台采用按量计费的模式,从根本上解决了以往空闲期资源浪费的问题。另一方面,新的平台在大部分任务上,可以在同等规模的计算资源下节省50%以上的时间。对SaaS型的数字原生企业在数据平台选型和升级上的再思考通过采用云器科技的产品升级原有数据平台的实践,可为同类企业在数据平台选型时提供以下参考经验:第一, 数字原生企业往往在一定阶段会出现终端用户快速增长的情况,这就要求数据平台具备海量数据表的处理能力、资源弹性伸缩能力、特别是要具备可调成本的实时能力。因此在前期进行数据平台选型时,要充分考虑这些因素,并尽量选择精简的一体化/Single-Engine平台架构,一方面降低开发和运维复杂度,另一方面也便于在后续业务需求发生变化时,可以对平台功能进行灵活扩展。第二, SaaS企业对于成本较敏感,因此在数据平台的计费模式上,需要优先考虑按量计费的模式,避免空闲期的资源浪费。而这种计费模式的成本优势会随着用户规模的增长变得更加显著。第三, 数字原生企业的数据运维管理复杂,考虑具备AI4D功能的工具平台,用AI做任务的自动优化调整,可以降低数据平台的使用门槛。注:点击左下角“阅读原文”,前往爱分析官网了解更多内容。