



Google在高性能处理器与AI芯片主要有两个系列:1)针对服务器端AI模型训练和推理的TPU系列,主要用于Goggle云计算和数据中心;2)针对手机端AI模型推理的Tensor系列,主要用于Pixel智能手机。
结合最近几年Google在HotChips、ISCA、ISSCC发布的论文和报告,总结了Google的TPU芯片的发展历史和硬件架构,可作为学习、研发高性能处理器与AI芯片的参考资料。
2022 OCP全球峰会:服务器系列(4)
Google第一代TPU芯片,服务器端推理芯片。
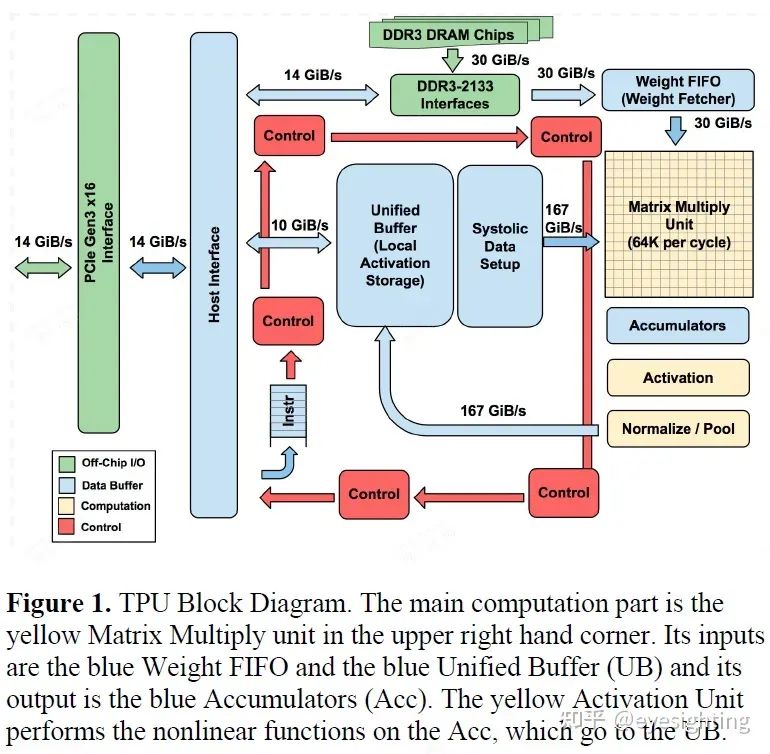
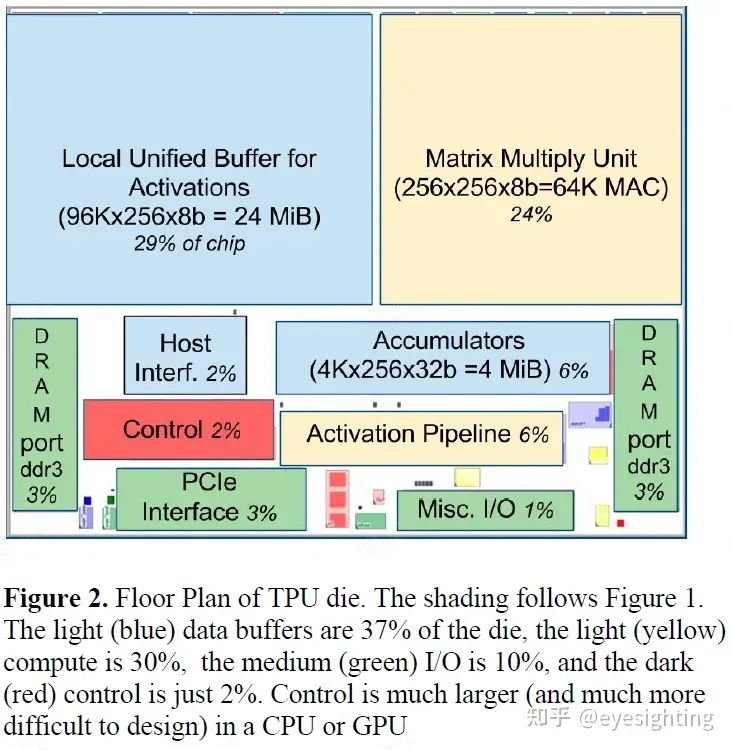
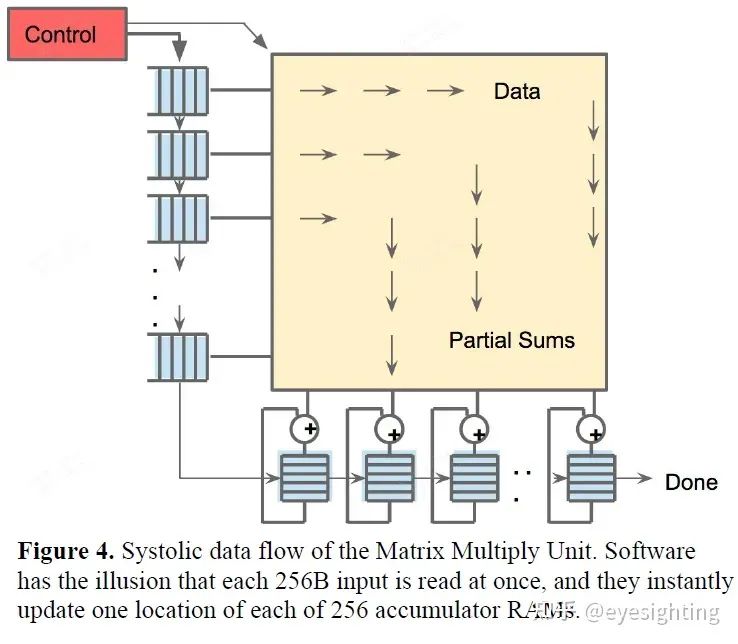

1).TPU指令通过PCIe Gen3 x16总线从主机发送到指令缓冲区。矩阵乘法单元是TPU的核心,包含256x256个MAC,可以对有符号或无符号整数执行8位乘法和加法。16位乘积被收集在矩阵单元下方的32位累加器的4 MiB中。4MiB表示4096256个元素的32位累加器。矩阵单元在每个时钟周期产生一个256元素的部分和。
2).当混合使用 8 位权重和 16 位激活时(反之亦然),矩阵单元以半速计算,而当两者都是 16 位时,它以四分之一速度计算。
3).省略了稀疏架构支持。稀疏性将在未来的设计中占据高度优先地位。
4).TPU 指令遵循 CISC 传统,包括重复字段。这些 CISC 指令的平均每条指令时钟周期 (CPI) 通常为 10 到 20。总共约有 12 条指令,但以下 5 条是关键指令:Read_Host_Memory、Read_Weights、MatrixMultiply/Convolve、Activate、Write_Host_Memory。其他指令是备用主机内存读/写、设置配置、两个版本的同步、中断主机、调试标记、nop 和暂停。
Google的第二代TPU,定位是服务端AI推理和训练芯片。
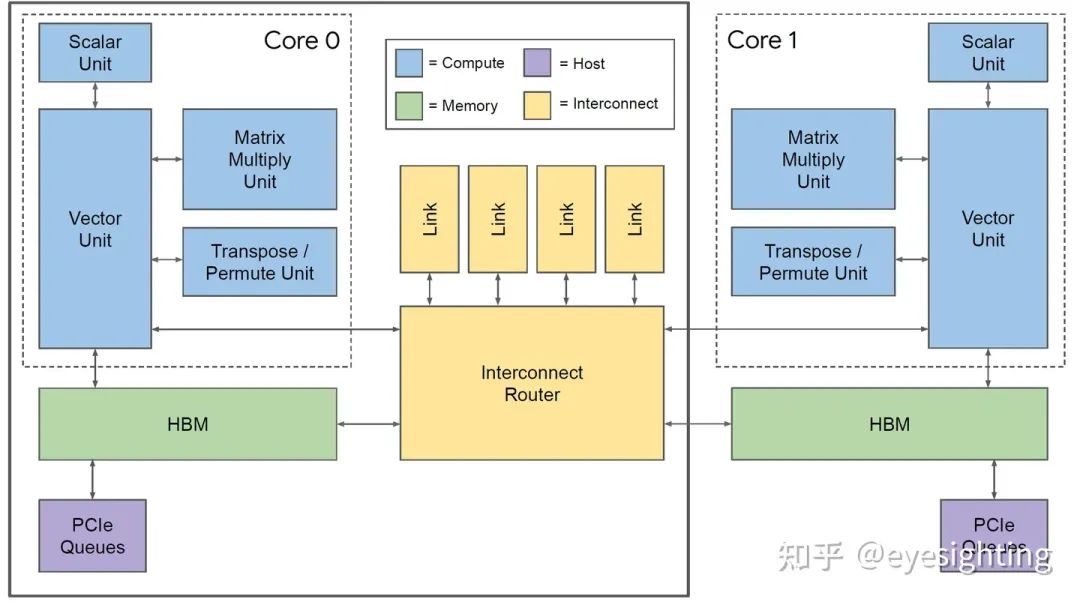

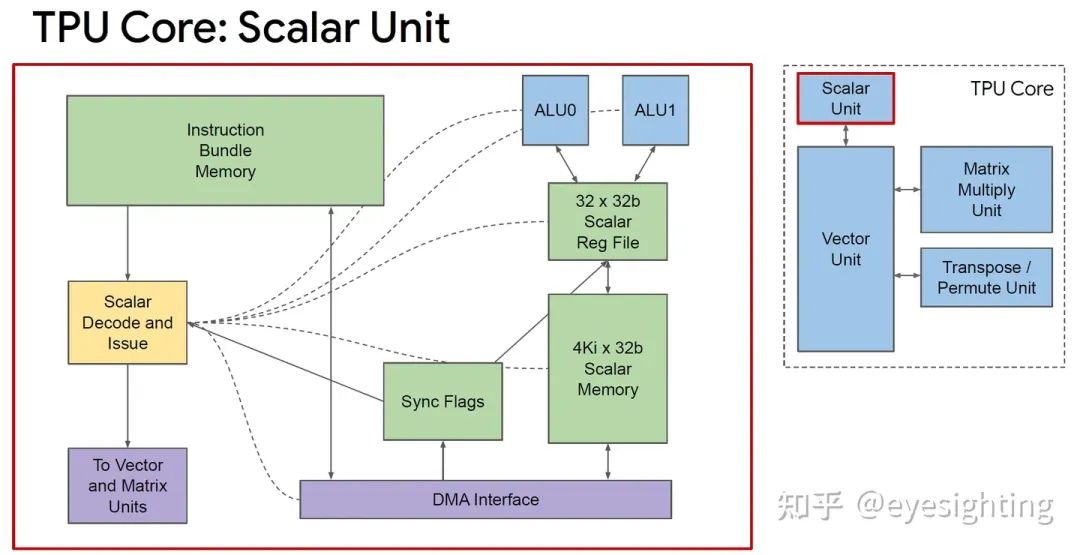
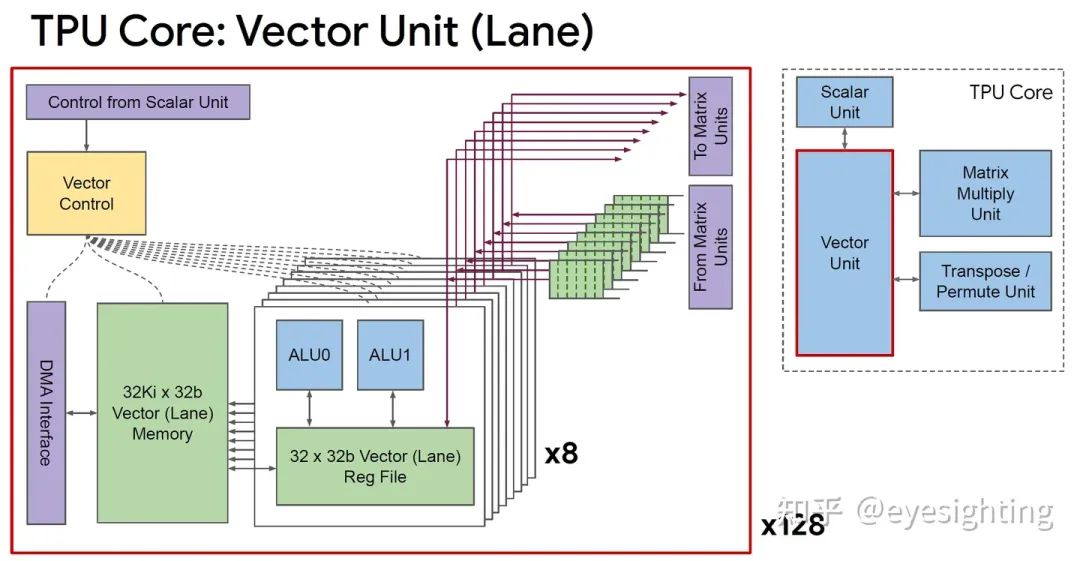


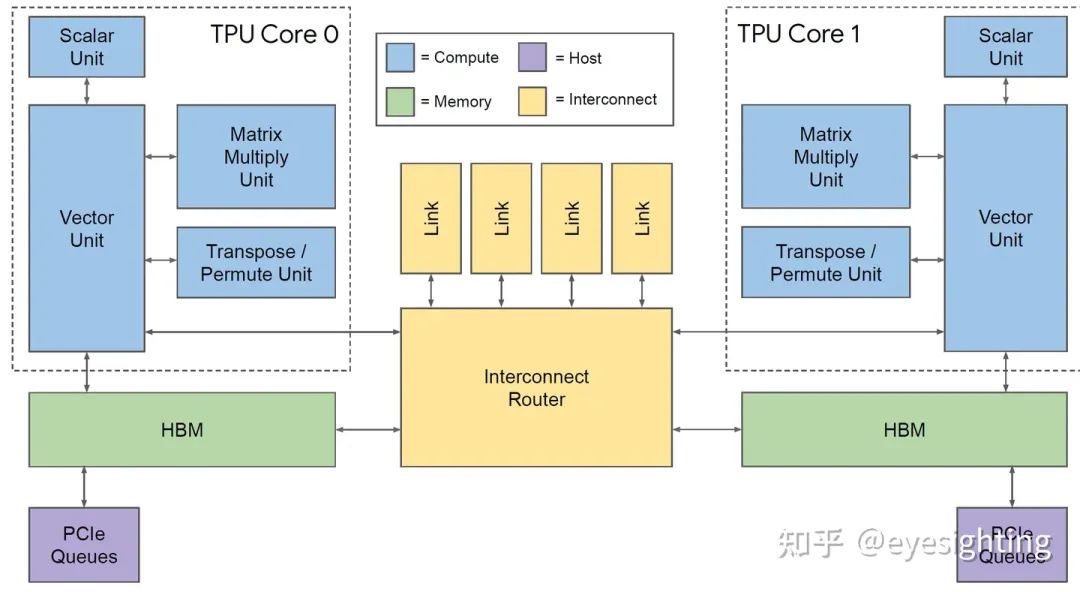
单个向量存储器,而不是固定功能单元之间的缓冲区。
通用向量单元,而不是固定功能激活管道。
连接矩阵单元作为向量单元的卸载。
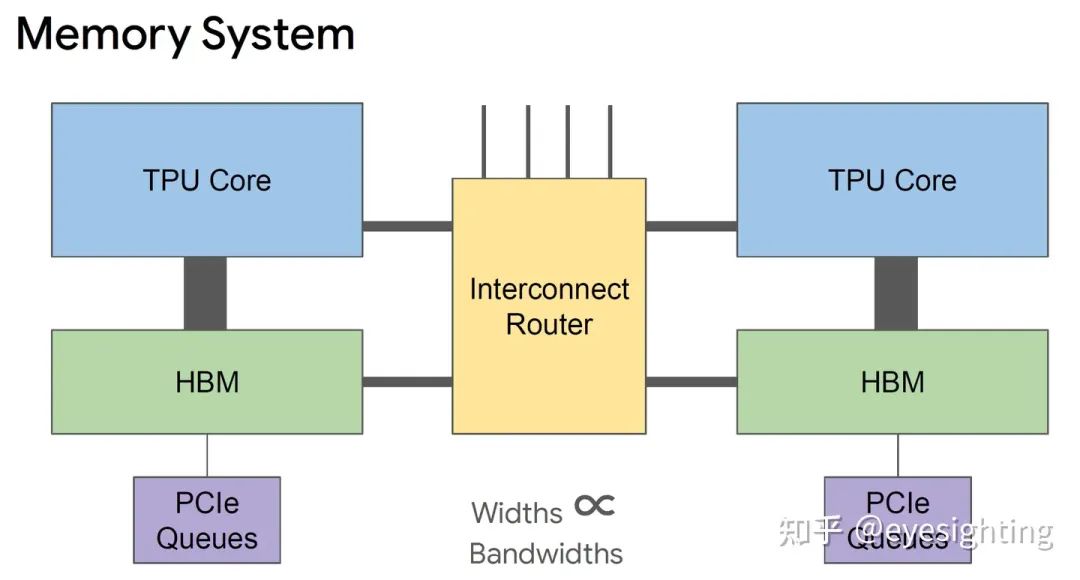
将 DRAM 连接到内存系统而不是直接连接到矩阵单元。
转向 HBM 以获得带宽。
超长指令字架构:利用已知的编译器技术。
2 个标量槽
4 个向量槽(2 个用于加载/存储)
2 个矩阵插槽(推入、弹出)、
1 个杂项插槽
6 个立即数
针对 SRAM 暂存器进行加载和存储
在核心内提供可预测的调度
可能会因同步标志而停止
可通过异步 DMA 访问
具有 4 个链路的片上路由器
每个链路 500 Gbps
组装成2D环面
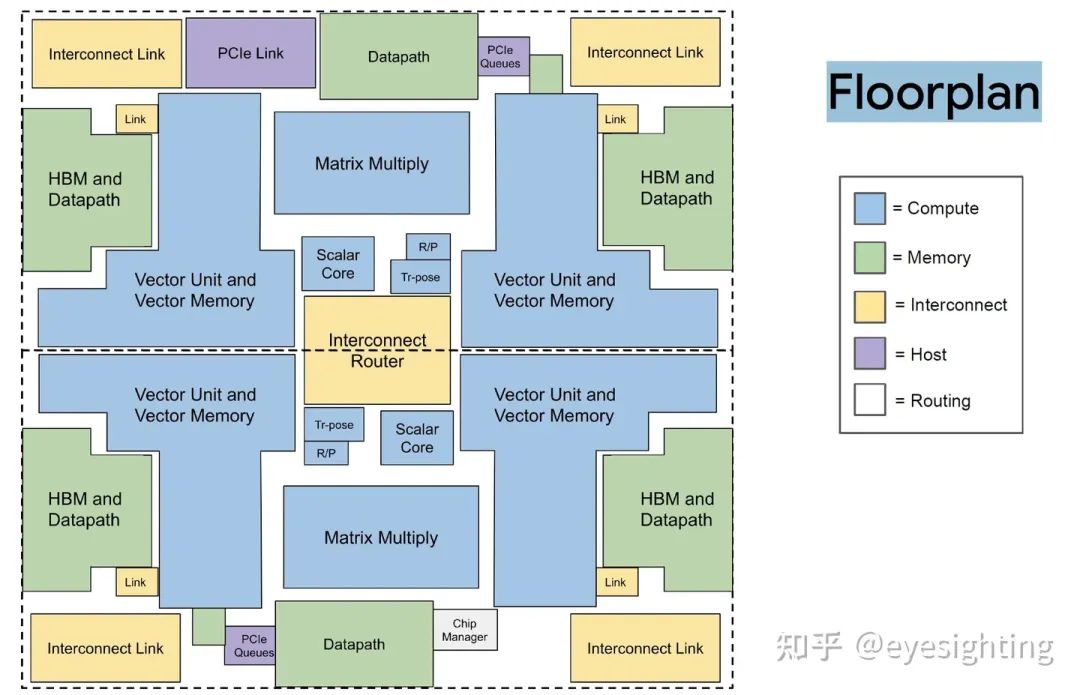
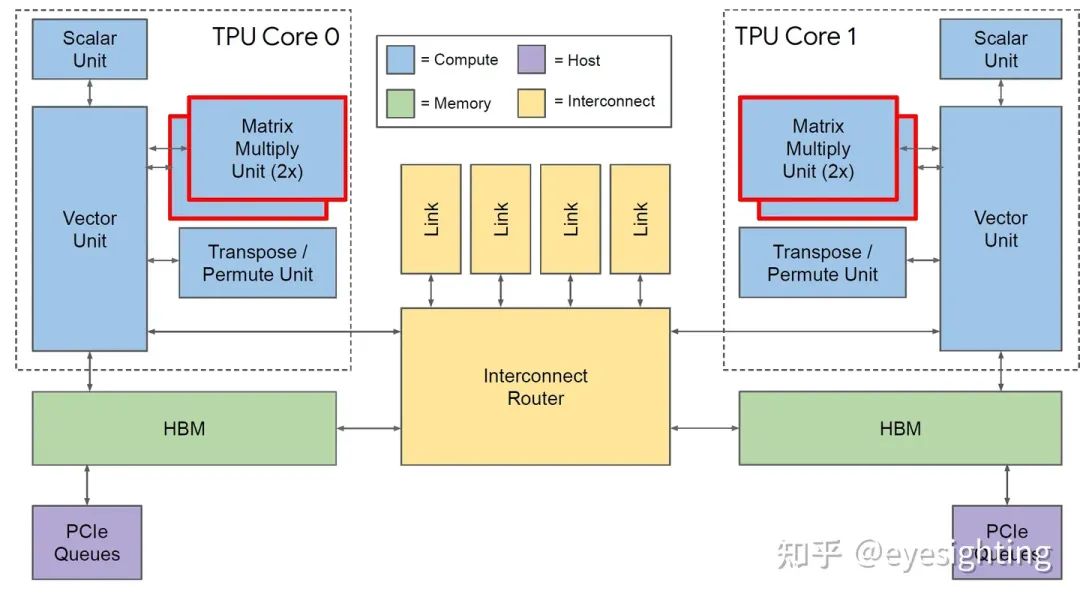
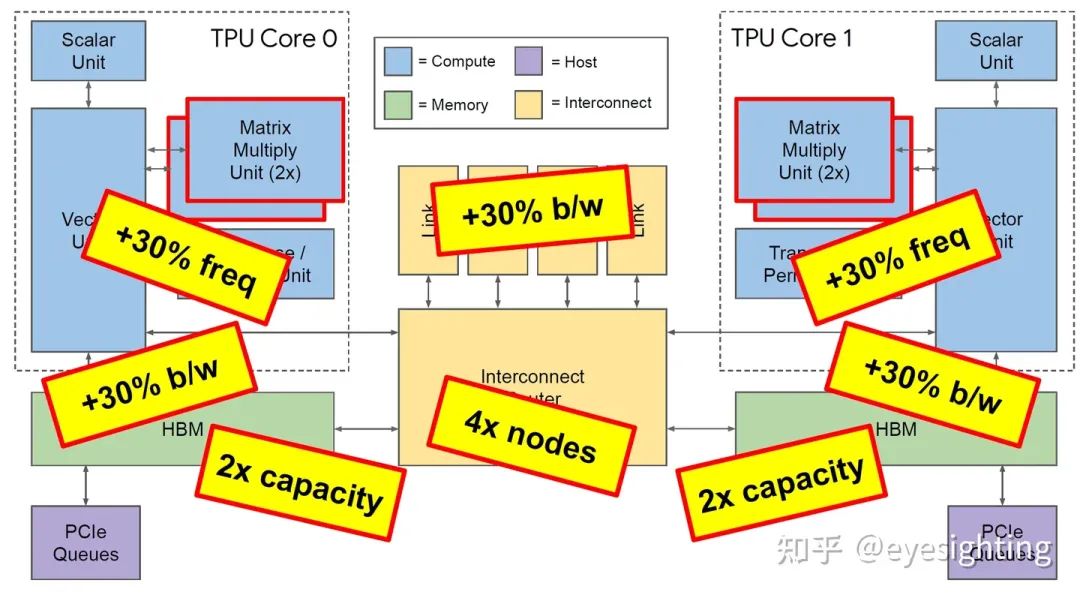
TPU3是是对TPU2的温和重新设计,采用相同的技术,MXU和HBM容量增加了两倍,时钟速率、内存带宽和ICI带宽增加了1.3倍。TPU3超级计算机还可以扩展到1024个芯片。
协同设计:具有软件可预测性的简化硬件(例如,VLIW、暂存器)。
使用 bfloat16 脉动阵列计算密度:HBM 为计算提供支持,XLA编译器。
Google发布的嵌入式TPU芯片,用于在边缘设备上运行推理。
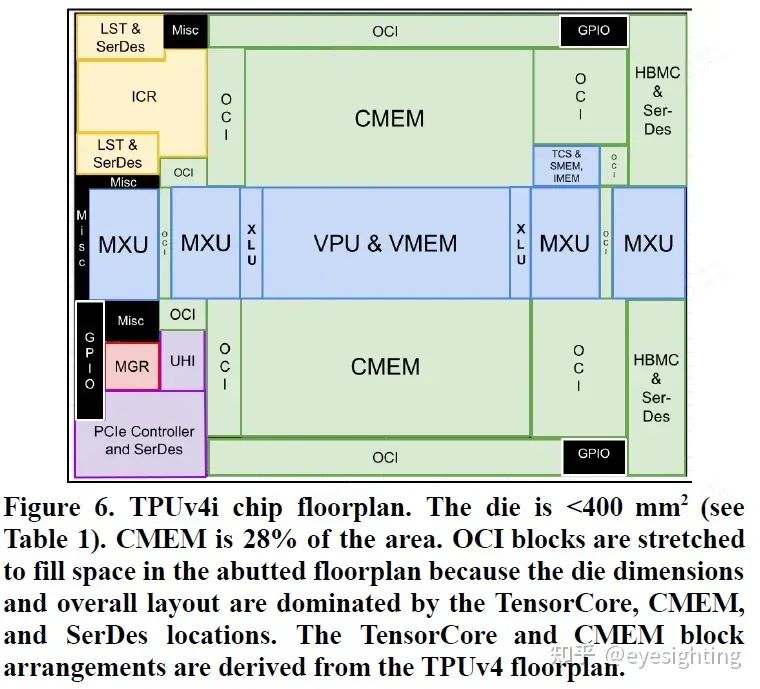
TPUv4i:Google于2020年发布,定位是服务器端推理芯片.
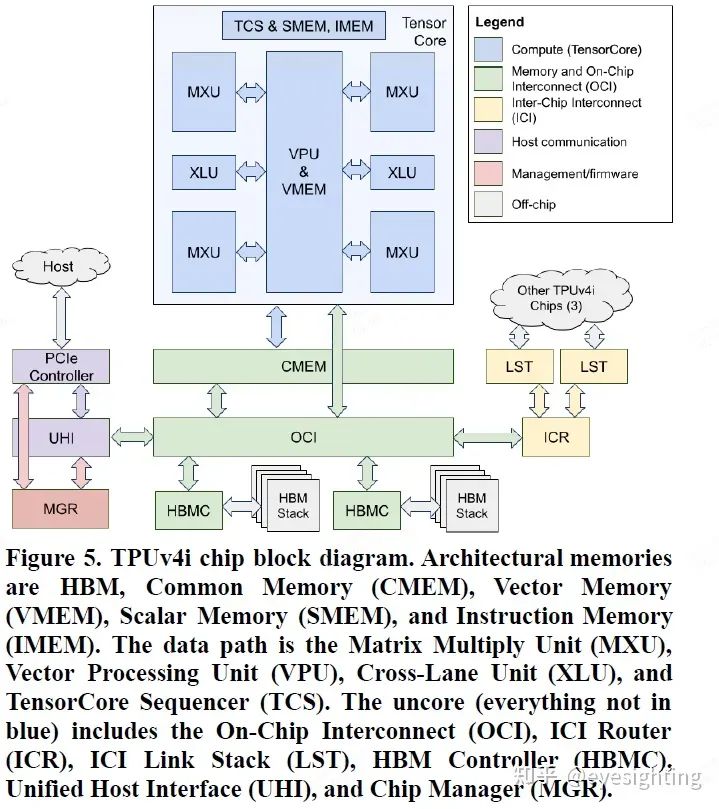

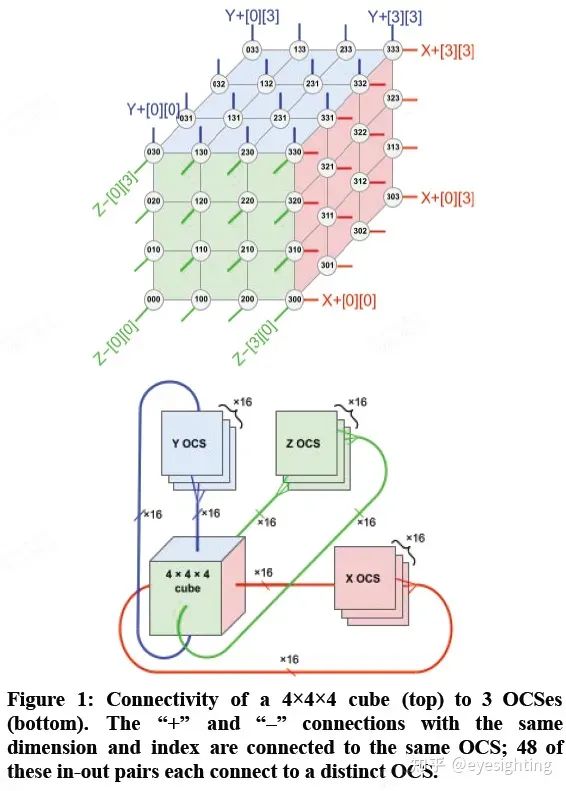
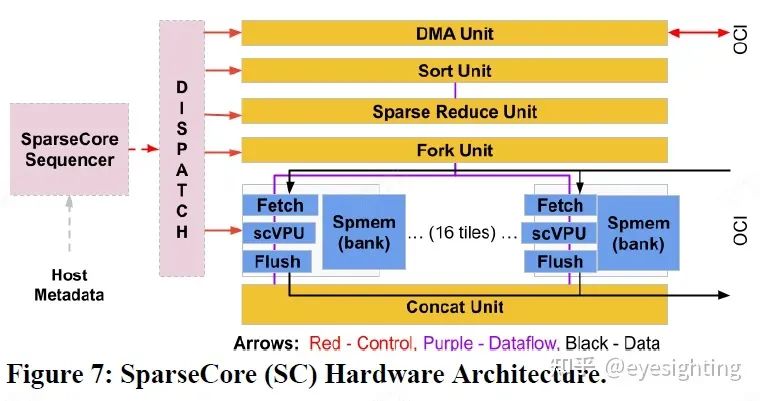
谷歌2020年发布,服务器推理和训练芯片,芯片数量是TPUv3的四倍。


《AIGC行业深度报告系列合集》
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


