滴滴的时序曲线量从 2017 年 到 2023 年增长了几十倍。整个过程中我们不断地调整和改进以应对这样的增长。例如时序数据库的选型从最初的 InfluxDB,到 RRDtool,又开发了内存 TSDB 分担查询压力,再到 2020 年开始使用 VictoriaMetrics。载体也从全公司最高配的物理机型到现在的全容器部署。其中经历了很多的思考和取舍,下文将按时间顺序,为大家讲述这一系列的故事。
时序数据库的一哥 InfluxDB,是我们最初选择的时序数据库。但随着时序曲线的规模变大,InfluxDB 的局限性也开始暴露了出来。同时社区中关于 InfluxDB OOM 的讨论也日益增多,其根本原因就在于热点写入和查询,想象一个命中几百万曲线的查询落在了一个 InfluxDB 实例上,OOM 几乎是必然的。大家也可以在 InfluxDB 社区中搜索 OOM,有 400 多个结果 “InfluxDB OOM” 。
由于这些问题日益突出,我们不得不重新思考时序数据库的选型。下图为当时的可观测系统在 Influxdb 挂掉后,看图功能的表现:
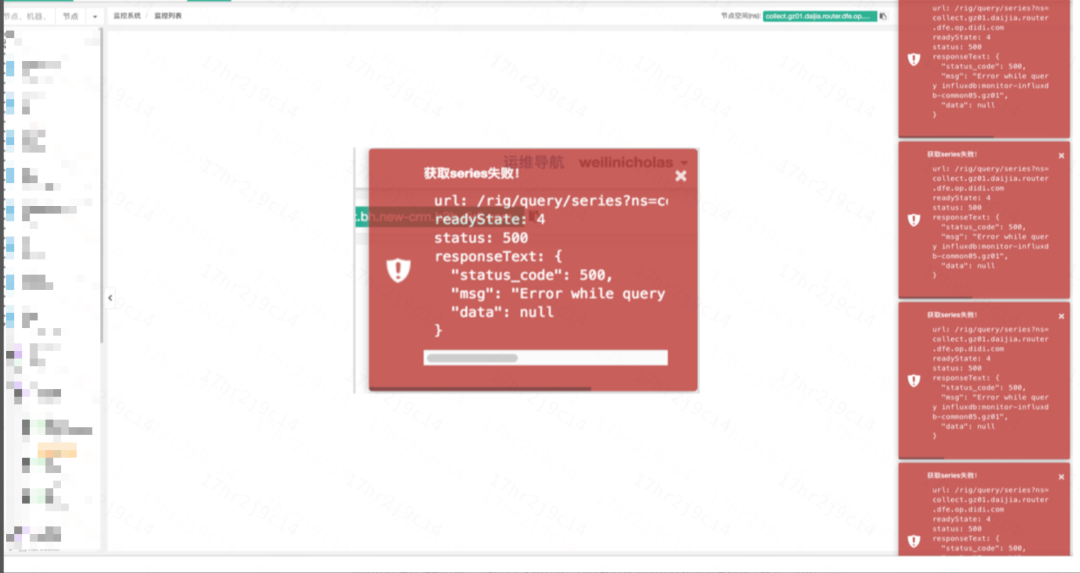
InfluxDB OOM,看图功能的表现
InfluxDB 单机性能有限,集群方案又不开放。尽管我们对 InfluxDB 按照业务线做了拆分,但仍面临着单个服务节点曲线量巨大的情况,对于 InfluxDB 来说难以处理。
在经过深入探索和多次试验后,我们决定采用 Open-Falcon 使用的 RRDtool 存储方案,在存储和查询链路,使用相同的一致性哈希算法,将曲线打散到不同的实例中,从而解决了在 InfluxDB 时代因为热点过高而导致 OOM 的难题。
直至 2018 年 4月,RRDtool 方案都一直在滴滴运行着。但随着曲线量的迅速增长,我们又面临新的问题——成本问题。成本几乎是每家互联网公司在发展到一定阶段都难以回避的问题。特别是作为非赢利产品的可观测平台,成本问题尤为突出。甚至自 2017 年之后的三年里,尽管我们的存储集群内存使用率曾高达 90% 以上,仍无法获取新机器的支援。其中一个原因是,我们需要的机器配置过高,甚至连当时配备的 NVMe 磁盘这种顶配机型的 IO 使用率也超过了 90%。预算委员会完全不相信会有一种服务同时对 CPU、内存和 IO 都有如此高的需求。
面对这种困境,我们陷入了两难境地。一方面是用户源源不断的压力,另一方面是无法满足存储所需求机型的要求。
在经过一段时间的思考与调研,我们发现 80% 以上的查询请求都集中在最新的 2 个小时内。因此,我们尝试将存储进行冷热分层,建设一个新服务来分担存储的压力,正好在这个时候,我们了解到了 Facebook Gorilla 的论文,于是一个名为 Cacheserver 服务应运而生。
Cacheserver 的设计灵感来源于 Facebook Gorilla 论文,旨在与原有存储服务共同承担请求,只针对最新 2 小时数据的查询请求,大大减轻了 RRDtool 服务集群的压力。这种冷热分层的架构不仅缓解了存储成本问题,还提升了整体性能和查询效率。
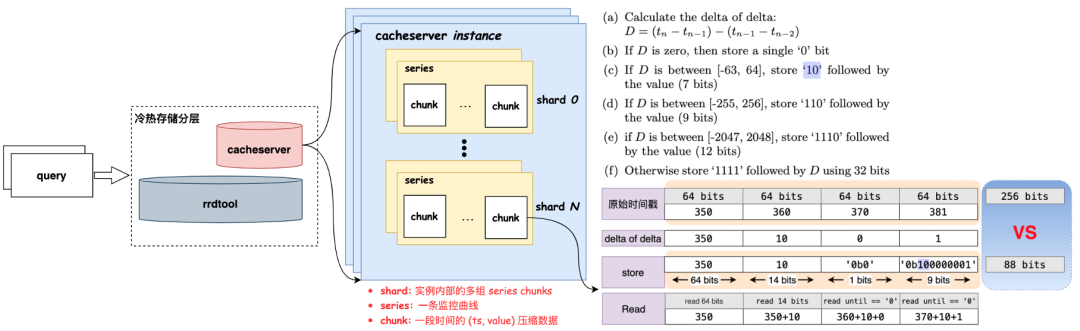
Cacheserver 架构
随着滴滴容器时代的到来,我们面临着更加艰巨的情况。
首先,随着容器覆盖率的不断提高,时序曲线量疯狂增长。而 2020 年随着容器覆盖率继续提升,曲线增长预计会超过 100%。
此外,成本压力继续增大。尽管 RRDtool 架构可以横向扩展,但可观测自身的成本无法再随业务增长而线性增长。
当前 RRDtool 架构高需低产,必须使用 SSD/NVMe 机型,使用普通磁盘在落盘时会直接 hang 死。而且功能上也仅支持 sum、avg、max、min 等有限的几个函数,无法满足用户日趋丰富的需求。
为节省存储空间,当时仅保留 2 小时原始数据。而用户需要更长时间(例如 15天)的原始数据进行查看和分析,然而,更改降采策略会带来 2 个问题:一是 RRDtool 的降采修改会导致所有数据丢失。二是存储 15 天的原始点会使每条曲线存储空间变为原来的 8.5 倍(120KB → 1MB)。
因此从 2020 年初开始,我们开始着手调研新的方案。需要更高效、灵活的存储架构以应对以上种种问题。
在选择新的存储方案时,我们考虑了多个备选方案,包括:
Druid
Prometheus
Thanos/Cortex
M3
VictoriaMetrics
Druid 是滴滴另一套系统 Woater 的时序存储方案,由大数据团队运维。然而,我们最终不考虑 Druid,主要原因如下:
模型不满足:Woater 的存储模型是预先定义好的 Schema(Dimensions),而我们需要的是动态 Schema,这是 Druid 原生不支持的,虽然大数据团队表示可以开发支持,但有着诸多条件限制。
成本问题:将现有数据存储到 Druid 成本将增长 10 倍。
性能问题:Druid 写入性能还不如 RRDtool,写入能力较差,因为 Druid 要做 Rollup,而 RRDtool 是直接 Append 数据。
“无用”的 Rollup:Druid 的亮点功能 Rollup,对于我们的场景并不适用,因为绝大部分查询都是针对原始值而非 Rollup 结果。
Prometheus 是可观测领域的事实标准,其存储模型、DSL 以及生态都吸引着众多用户和企业的关注。但在滴滴的场景下,我们也没有选择 Prometheus,主要原因在于:
没有长期存储:Prometheus 主要专注于对短期数据的存储和查询,而我们需要长期保留。
没有集群方案:Prometheus 无内置的集群方案,要实现横向扩展,需要依赖第三方架构如 Thanos、Cortex 等,这无疑增加了复杂性。
没有高可用能力。
尽管针对这些问题,社区提供了一些解决方案,但在滴滴的体量下,这些解决方案都无法满足我们的生产化需求。
Thanos 和 Cortex 可以说是 Prometheus 当时唯二的,集群化和长期存储方案。它们的设计目标都是要解决如下问题:
Global View:可以跨多个 Prometheus 实例进行查询以实现全局视图。
Long Term Storage:实现长期存储以满足长期分析和回溯的需求。
High Availability。
这些特性使得 Thanos 和 Cortex 成为 Prometheus 生态中重要的补充。
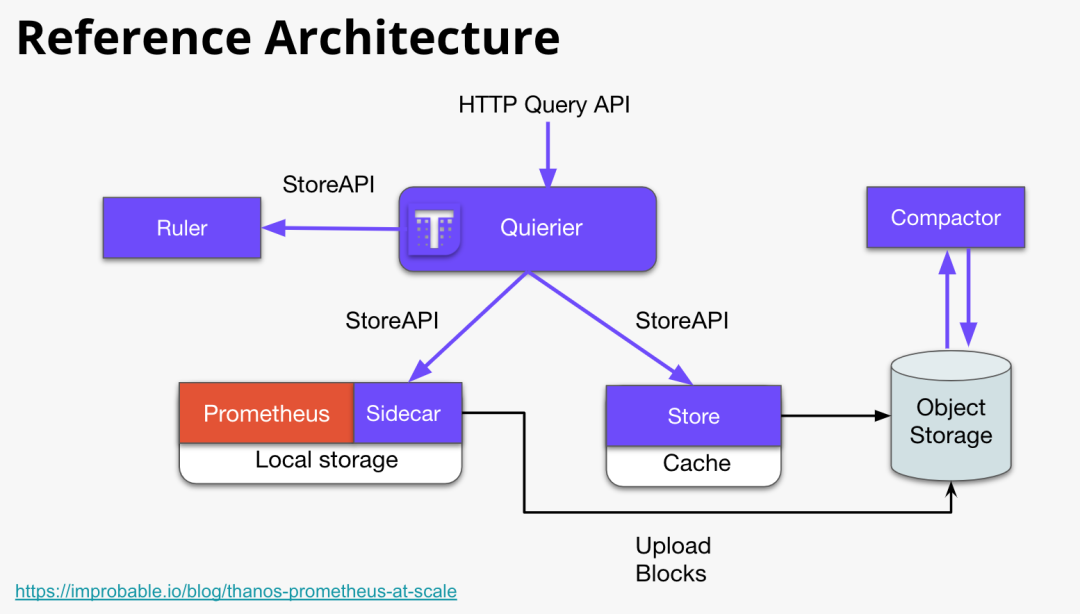
Thanos 架构
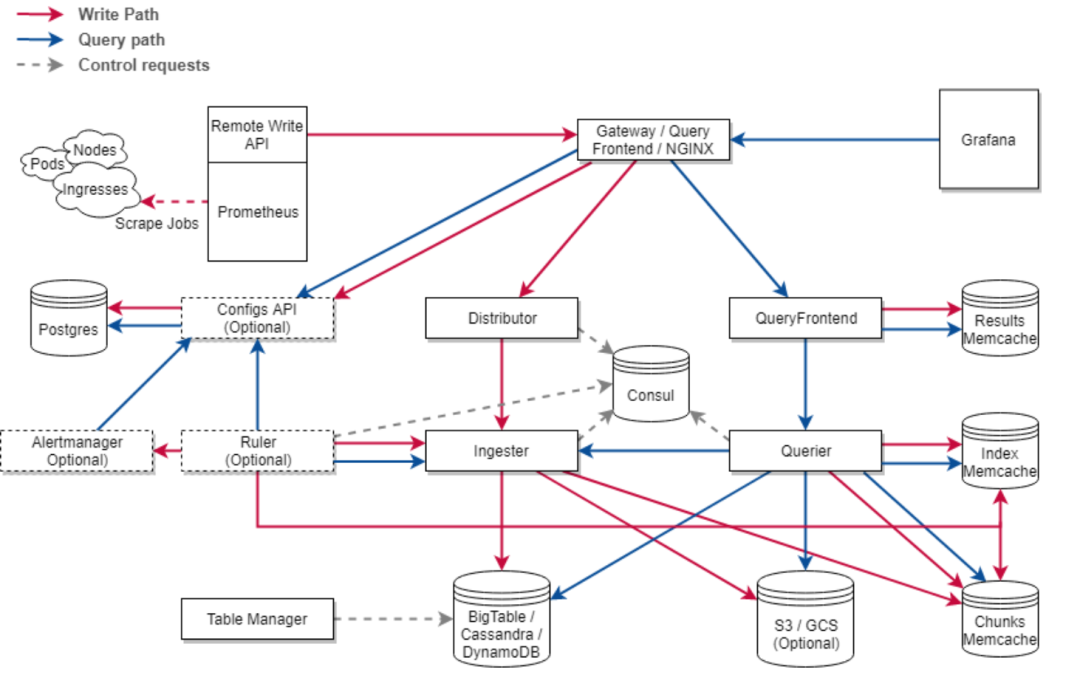
Cortex 架构
但 Thanos/Cortex 也存在一些问题:
Cortex 的存储结构,其内部仍在探索当中,还不够稳定,Blocks 在当时还处于 Experimental 状态。
Thanos 和 Cortex 均需要引入对象存储,可能带来一些额外的管理成本,性能上也要画一个问号。
Thanos Remote Read 内存开销太多,例如当时有人提出如下图所示的问题:
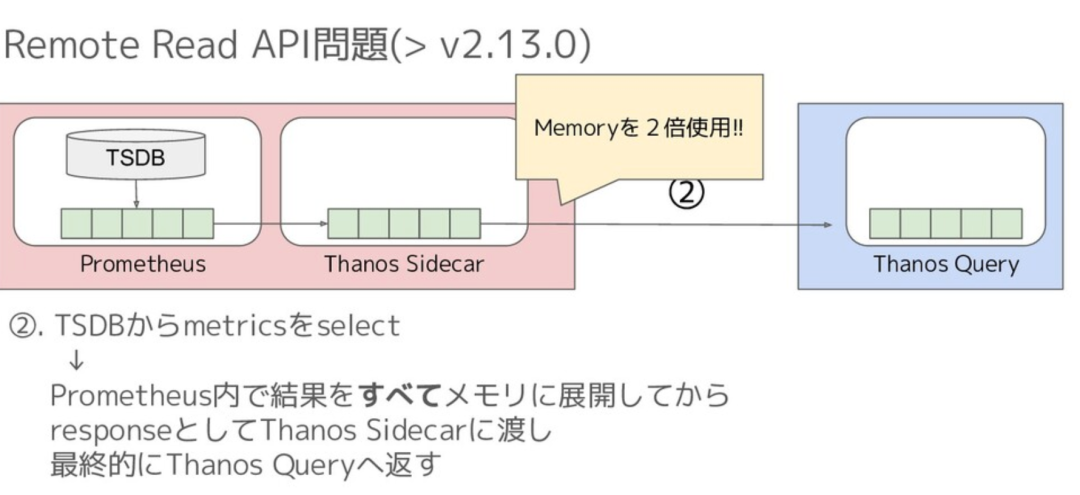
Thanos 内存问题
缺乏大规模生产环境的洗礼:Thanos 和 Cortex,这两个看似美好的解决方案,都有他们的硬伤。也缺乏大规模生产环境的实际验证,可靠性和稳定性可能还需更多的验证和优化。
M3 是 Uber 开源的 TSDB 解决方案,尽管有一些优势,但也存在一些缺点,包括管理成本高(例如引入 etcd)和机器成本没有优势(仍需要高配 SSD)。
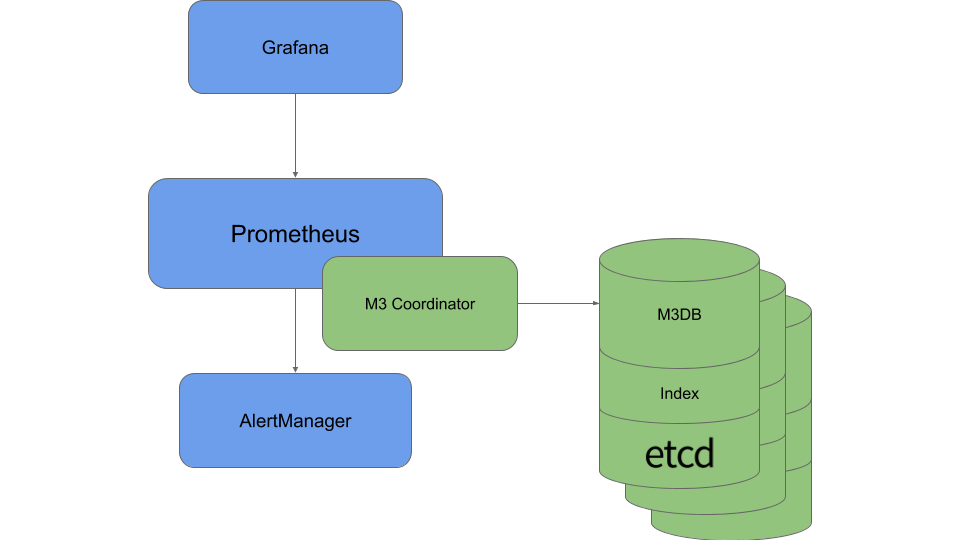
M3 架构
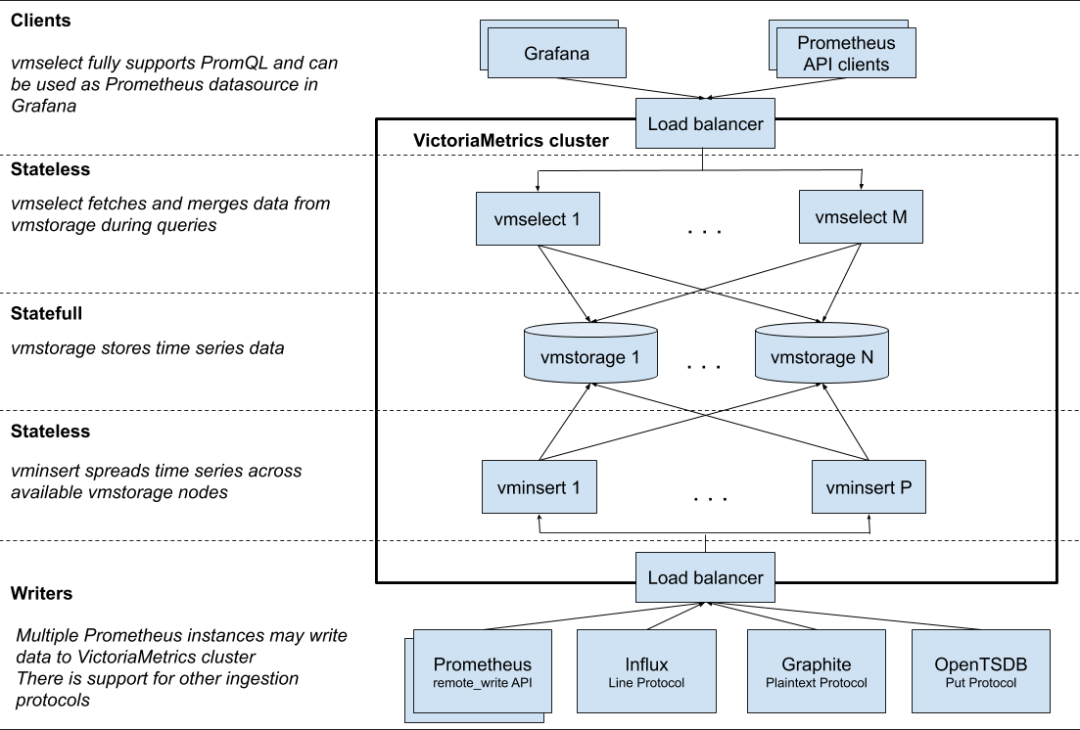
Victoriametrics 架构
VictoriaMetrics 是一个性能高、资源要求和运维成本都比较时序数据库,其主要特色和原理包括:
要求资源低:VictoriaMetrics 可以在普通机型上运行,不需要使用 SSD/NVMe 等高性能硬件。
核心存储模型:基于 LSM,类似 Clickhouse。它将数据缓冲在内存中,并每秒钟将其刷写到磁盘上的分区目录中。较小的分区会在后台逐渐合并成更大的分区。
列式存储:VictoriaMetrics 采用列式存储,使得读写性能非常高,1个CPU核心可以扫描 30M points/s。
写入速度强:单实例 760K point/s 的写能力(vs RRDtool 210~260K point/s)。
压缩:采用改进版 Gorilla 结合通用压缩算法(Facebook zstd),平均仅需 1.2~1.5 bytes/point,压缩比达 13%。
集群容易扩展:采用 Share Nothing 设计。扩缩容机器方便。机器损坏时还可以自动 Rerouting。
无降采样:不降采的设计,使得原始数据得以保留。
兼容 Prometheus:在写入、写入方式等都兼容 Prometheues。并针对 PromQL 做了增强(MetricsQL)
乱序时间戳的弱支持。
容量可计算:VictoriaMetrics 的容量是可计算的,我们可以更直观和方便的预估存储需求。

VictoriaMetrics Capacity Planning
如上所述,因为 VictoriaMetrics 在性能、压缩率、查询速度和扩展性等方面表现出色。在综合考虑了各个方面的需求和考虑后,我们认为 VictoriaMetrics 是适合我们的时序数据存储方案,能够满足我们的需求。
VictoriaMetrics 的问题及解决方案
尽管 VictoriaMetrics 作为时序数据库解决方案有许多优势,但也存在一些潜在问题,这里列举几点并简要地给出了我们的解决方案:
资源占用问题:磁盘空间占用量与存储点数成正比,存储越多越长的数据,磁盘空间需求越多。为解决这个问题,我们针对不同的业务线,设置了不同的保留时长。
无降采样:VictoriaMetrics 不支持数据降采样,即不会自动对数据进行聚合或丢弃,而是保留原始数据。这在某些场景下可能会导致数据存储需求较高,特别是在存储长期数据时。不过,由于 VictoriaMetrics 查询速度快且压缩率较高,这个问题并没有对成本和系统性能造成显著影响。
活跃度有限、不够主流:相对于其他一些主流的时序存储方案,当时 VictoriaMetrics 的活跃度可能还不够高。然而,通过对代码的深入了解和与作者的多次交流,我们对VictoriaMetrics 的质量和性能表现逐渐建立信心。
多集群 VictoriaMetrics 设计
我们基于 VictoriaMetrics 设计并实现了一个多集群方案,旨在提高系统的可扩展性和可用性。例如下图我们在 region 1 搭建了多套集群,分别处理不同业务线的数据,隔离了各业务线的资源竞争和影响,也缩小了故障域。多个 region 之间也可以选择 mixer 来实现跨区域的数据读取和合并。
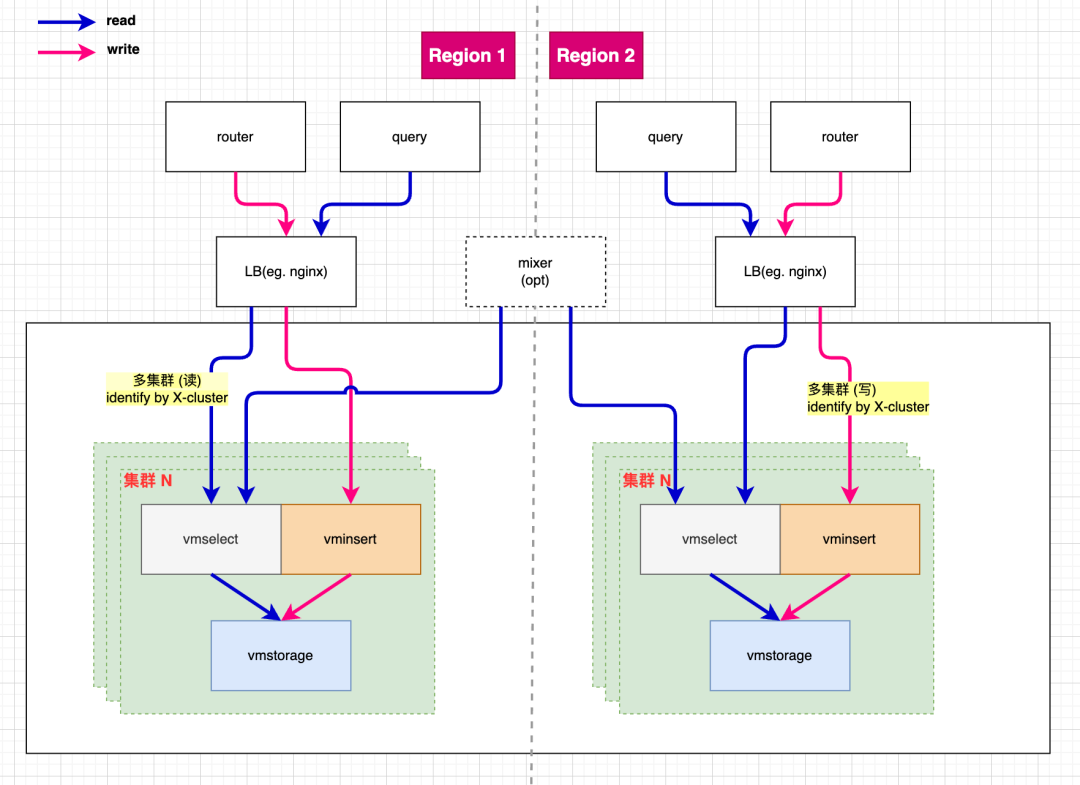
VictoriaMetrics 多集群设计
结尾
以上介绍了滴滴可观测的时序存储解决方案的发展历程。希望通过这个分享,能够为其他团队和开发者提供一些有益的经验和启示,也欢迎一起交流和探讨。
限于文章篇幅,无法在这里展开更多。例如 VictoriaMetrics 的容器化部署,故障管理,复制,数据迁移等。这些内容将在后续的文章中为大家介绍,敬请期待!
云原生夜话
聊聊看,你们公司是如何做可观测数据存储的,又是如何应对大量的查询请求的?如需与我们进一步交流探讨,也可直接私信后台。
作者将选取1则最有意义的留言,送出滴滴200元打车券,祝您十一无忧出行。10月7日晚9点开奖。
