
来源 | 半导体行业观察
众所周知,随着生成式AI的大热,英伟达正在数据中心领域大杀四方,这也帮助他们实现了更好的业绩。根据公司公布的数据,截至 2023 年 7 月 30 日的第二季度,英伟达收入为 135.1 亿美元,较上一季度增长 88%,较去年同期增长 101%。
不过,英伟达目前的业绩预期很多都是基于当前的芯片和硬件所做的。但有分析人士预计,如果包含企业 AI 及其 DGX 云产品,该数据中心的市场规模将至少是游戏市场的 3 倍,甚至是 4.5 倍。
瑞银分析师Timothy Arcuri也表示,英伟达目前在DGX云计算方面的收入约为10亿美元。但在与客户交谈后,他认为,该公司每年可能从该部门获得高达100亿美元的收入。他给出的理由是Nvidia仍然可以在DGX云上添加额外的产品,包括预先训练的模型,访问H100 GPU等等。他说,现在这些领先GPU仍然“非常难”获得访问,能够根据需要扩大和缩小规模,并与现有的云或内部部署基础设施“基本上无缝集成”。
因此,英伟达在最近公布了一个包括H200、B100、X100、B40、X40、GB200、GX200、GB200NVL、GX200NVL 等新部件在内的产品路线图,这对英伟达未来的发展非常重要。
01
数据中心路线图
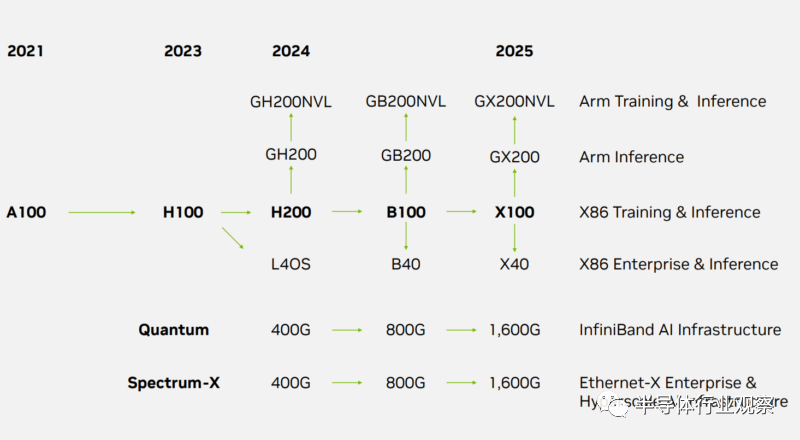


02
精准的供应链控制

03
精明的商业计划
END
美股研究社(meigushe)所发布文章不具有投资建议,请各位投资者自行判断。



听说好看的人都点赞了~
