
Hot Chips上的重要技术信息
芝能智芯出品
AMD的Phoenix SoC在移动和小型化领域取得了重要突破,这将改变很多东西。

●AMD的Ryzen 7040
AMD的移动和小型化之路曾一度艰辛。早在2010年代初期,英特尔在能效方面取得了巨大的进步,而AMD的基于Bulldozer的CPU核心在这方面没有机会。Zen架构缩小了差距,但AMD仍然需要付出大量努力。空闲功耗仍然不及英特尔。GPU方面,由于AMD收购了ATI,所以它在这方面更强大,但AMD的集成GPU常常使用过时的图形架构。即使在独立的GCN GPU上市后,APU上仍然使用Terascale 3架构。2021年,AMD推出了搭载Vega(改进的GCN)显卡的Ryzen 7 5800H,但当时桌面GPU已经过渡到使用RDNA 2。
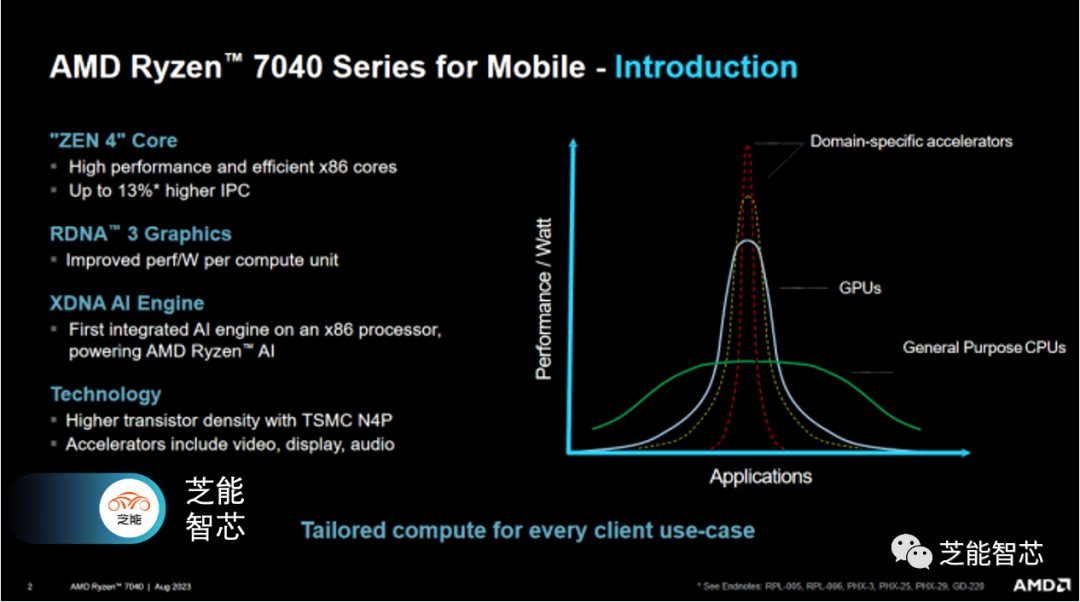
AMD的产品已经扭转了这一局面。Van Gogh(Steam Deck APU)和Rembrandt终于将RDNA 2引入了集成GPU中。而Phoenix则迈出了正确方向的又一步,将当前一代的Zen 4核心和RDNA 3显卡整合到了一个强大的芯片中。除了使用最新架构的重要CPU和GPU之外,Phoenix还集成了各种加速器,以提高特定应用程序的能效。英特尔早已整合了像GNA AI加速器这样的加速器,而AMD则希望迎头赶上。XDNA加速器有助于机器学习推理,音频控制器则可以卸载CPU的信号处理。对于移动SoC来说,Phoenix还配备了强大的视频引擎。

Phoenix采用了TSMC的N4工艺制造,占据了178平方毫米的面积。芯片拥有254亿个晶体管,将Zen 4核心与RDNA 3图形整合在一起。除了重要的CPU和GPU之外,AMD还添加了一些支持性的IP块,用于加速机器学习推理和信号处理。Phoenix的芯片尺寸比AMD之前的Rembrandt要小,可以容纳在相同的25x35毫米BGA封装中。

●CPU方面
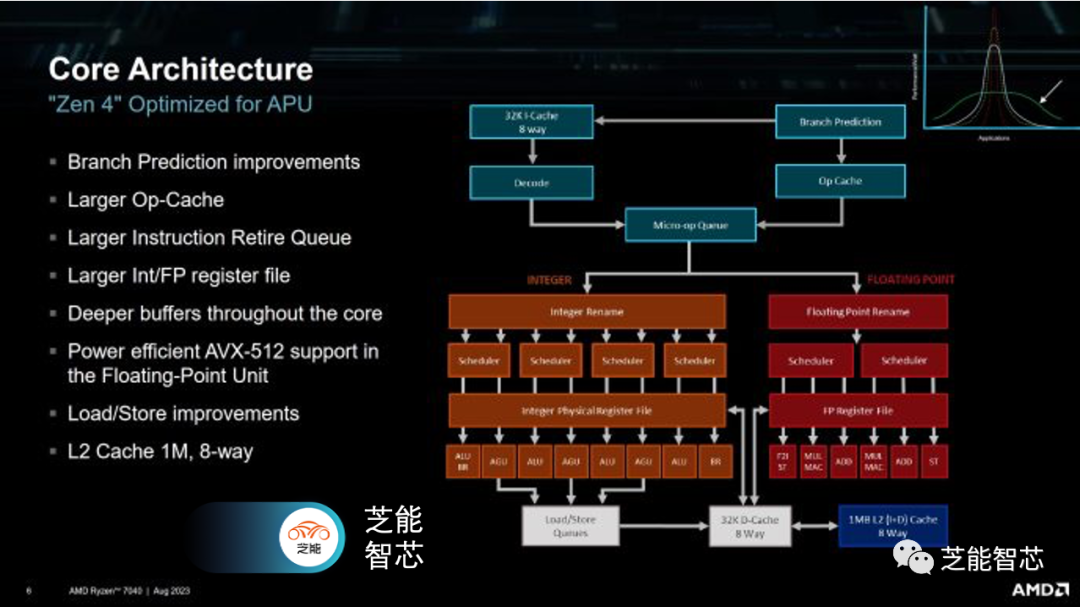
Phoenix拥有8个Zen 4核心的集群,Phoenix采用了不同的高速缓存设置,只有16MB的L3缓存(而不是通常的32MB)。AMD可能将L3切片缩小到每个核心2MB,以减少芯片面积的使用。
根据测试,延迟与台式机上的Zen 4相同。实际的延迟可能会稍微差一些,因为台式机上的Zen 4频率更高。例如,Ryzen 9 7950X3D的非VCache芯片在16MB的测试大小下延迟为8.85纳秒。而Ryzen 7 7840HS在10MB的测试大小下延迟为10.92纳秒。部分差距是因为HP坚持将时钟速度限制在4.5 GHz,尽管7840HS应该能够提升至5.1 GHz。
Phoenix的内存控制器支持DDR5和LPDDR5。对于功耗至关重要的手持设备来说,LPDDR5尤其有用。与LPDDR5一起的内存延迟更高,为119.81纳秒。然而,与Van Gogh相比,AMD已经大幅改进了LPDDR5的延迟,Van Gogh在CPU核心访问DRAM时延迟很高。
Infinity Fabric 带宽
CPU集群通过每个时钟周期32字节的Infinity Fabric链路与系统的其余部分进行通信。与台式机设计不同,其中写路径是宽度的一半,CPU到Fabric的写路径也可以处理每个周期32字节。这在实际工作负载中几乎不太可能影响性能,因为我没有看到任何单个核心需要超过30 GB/s的写入带宽的工作负载。多线程的工作负载可能需要更多的带宽,但也可以分配到不同的CCX。
AMD已经实现了写入优化,以减少Infinity Fabric的流量。通过使用CLZERO清零缓存行时,单个7950X3D CCD的写入带宽可以超过68 GB/s。清零内存是相当常见的,因为程序将初始化内存以确保新分配的内存处于已知状态。操作系统通常也会这样做。如果应用程序使用已识别的方法清零内存,可以看到比通用测试所建议的更高的有效写入带宽。
Infinity Fabric 优化
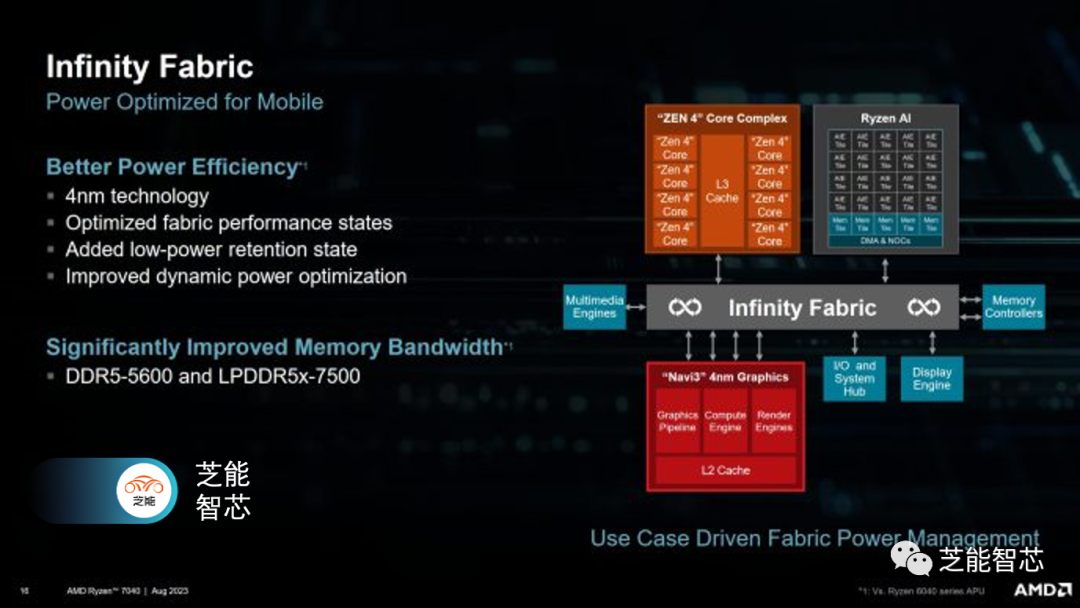
Infinity Fabric是AMD的一种一致性互连。在功耗方面,它至关重要,因为互连功耗可能占芯片功耗的相当大一部分,特别是在不是完全推动计算的工作负载中。AMD对各种工作负载进行了分析,并根据工作负载是否受到计算限制、IO限制或具有非常特定的特征(如视频会议)来设置Phoenix的Infinity Fabric,使其进入不同的操作模式。
这些优化避免了Van Gogh的问题,因为它在CPU侧带宽上限制在约25 GB/s,这要归功于一个在有限的功耗预算内高度优化用于游戏的Infinity Fabric实现。在Cheese的HP笔记本上,根据工作负载不同,Infinity Fabric时钟也会有所变化:

AMD在GPU拉取大量带宽时使用低速Fabric时钟以提高能效。GPU具有四个32B/周期的端口与Fabric相连,即使在低速Fabric时钟下,也可以获得足够的内存带宽。由于客户程序通常对延迟比带宽更敏感,因此CPU工作负载获得了更高的Fabric时钟,从而改善了延迟。与Renoir不同,Phoenix的可变Infinity Fabric时钟与生成内存流量的组件无关时都会降至1.6 GHz。
为了进一步节省功耗,AMD积极追求功耗和时钟门控的机会。新的Z8睡眠状态允许在短暂的闲置期间进行功耗和时钟门控,例如在按键之间,而不会感知到唤醒时间。在视频播放期间,Phoenix可以实现较高的Z8状态停留,这表明媒体引擎的缓冲区和高速缓存足够大,可以允许它进行短暂的内存访问。

来自优化各种物理接口也带来了额外的节能。内存控制器可以根据需要动态更改时钟和电压状态。多年来一直在使用的USB 2.0接口竟然具有许多功耗优化机会,因此AMD也进行了调整。
GPU方面
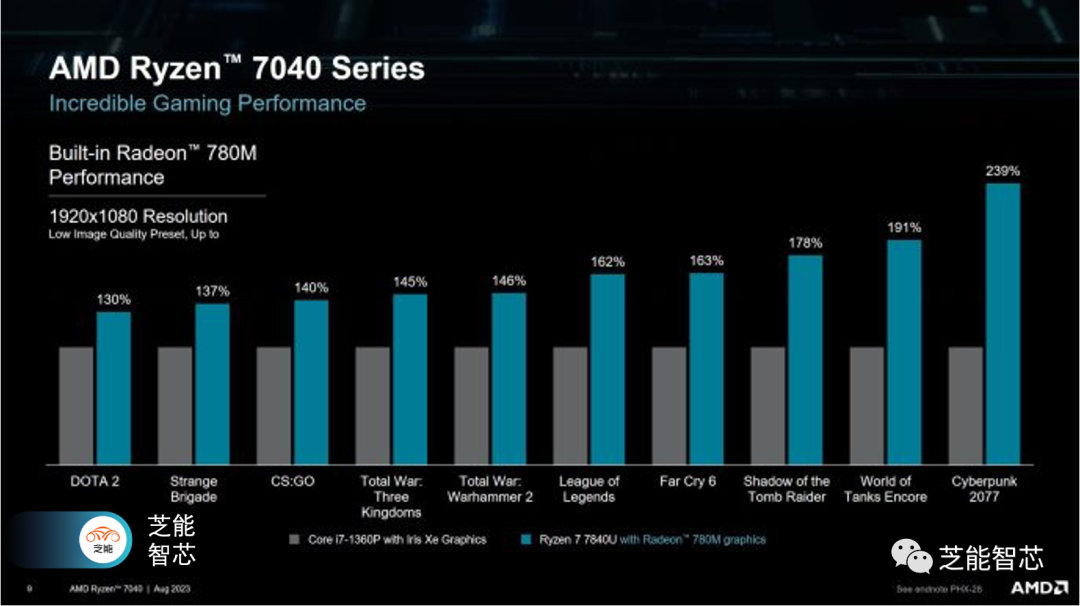
Phoenix的GPU基于AMD当前一代的RDNA 3架构,获得了合适的“Radeon 780M”名称,而不仅仅是被称为Vega或gfx90c。它具有六个WGPs,总共有768个SIMD单元,每个周期能够执行1536个FP32操作。这些单元分为两个着色器数组,每个着色器数组具有256KB的中级高速缓存。2MB的L2高速缓存有助于隔离iGPU与DRAM,对iGPU的性能非常重要。与Van Gogh相比,Phoenix的L2高速缓存多一倍,内存带宽稍多,并且具有50%更多的SIMD单元。

与RX 7600相比,L0、L1和L2的延迟与RX 7600相比相当相似,尽管由于更高的时钟速度,独立显卡稍微快一些。DDR5使iGPU的每个SIMD操作的带宽比台式机GPU更高,因此无法证明将区域分配给另一级缓存。 DDR5的带宽确实不容忽视。使用DDR5-5600或LPDDR5-5600,Phoenix可以实现比几年前的Nvidia GDDR5配备的GTX 1050 3 GB更高的GPU端DRAM带宽。每个引脚的5.6千兆位也比早期的GDDR5实现更快。
视频引擎
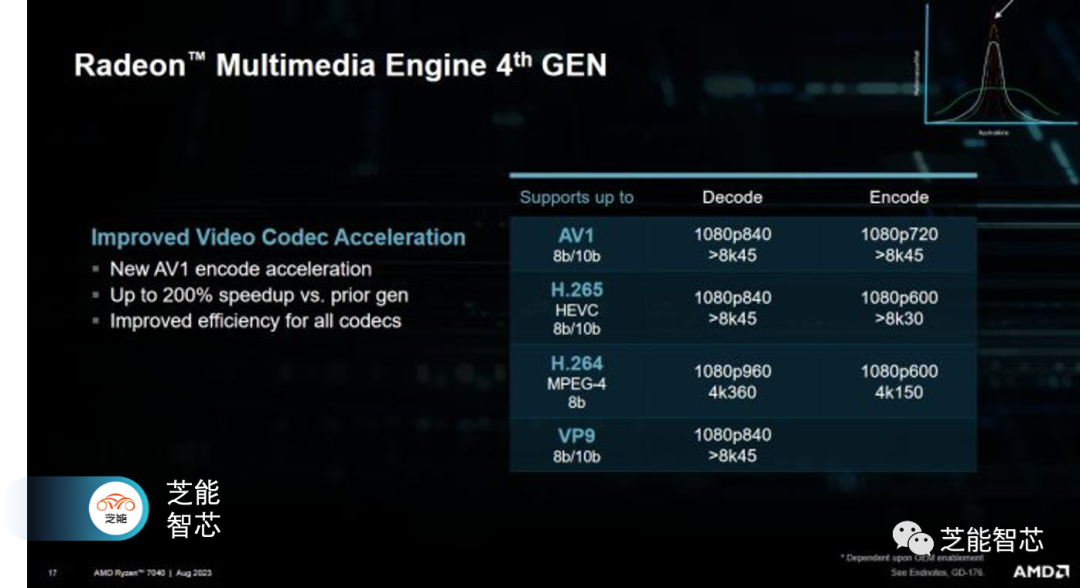
RDNA 3配备了一个支持AV1的视频引擎,这使得Phoenix更加具备未来的可扩展性,因为下一代视频编解码器开始获得广泛应用。虽然该引擎并不是新的,但AMD透露它使用了一种“竞争至空闲”的方案来节省电能。它还具有足够的吞吐量,可以处理多个同时的视频流,这对于视频会议非常重要。
XDNA AI引擎
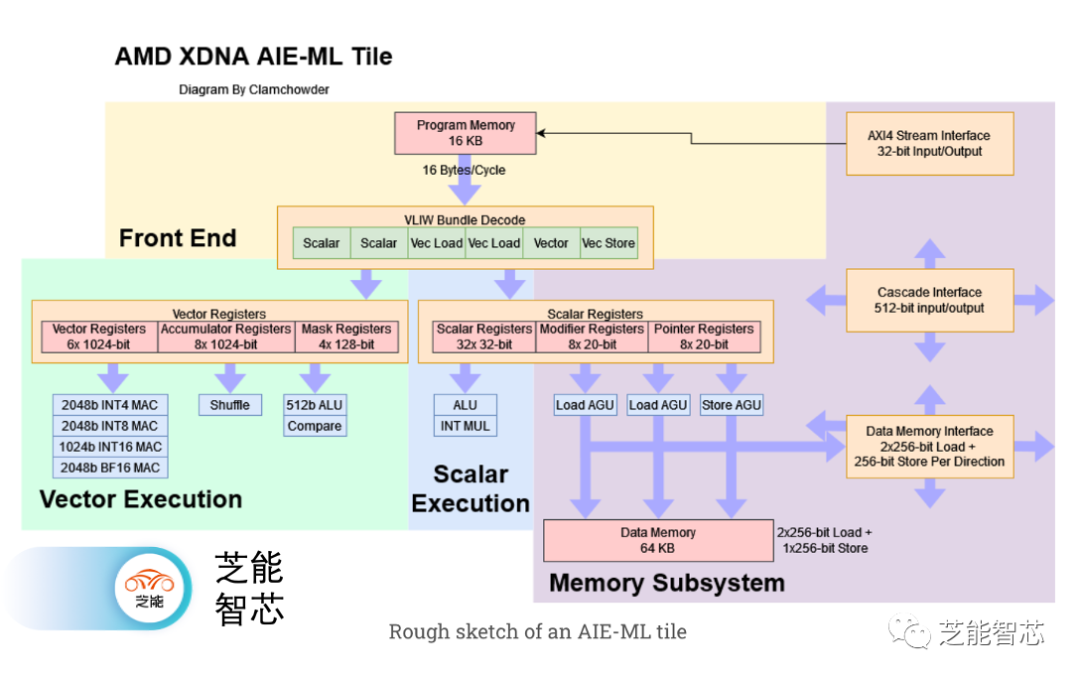
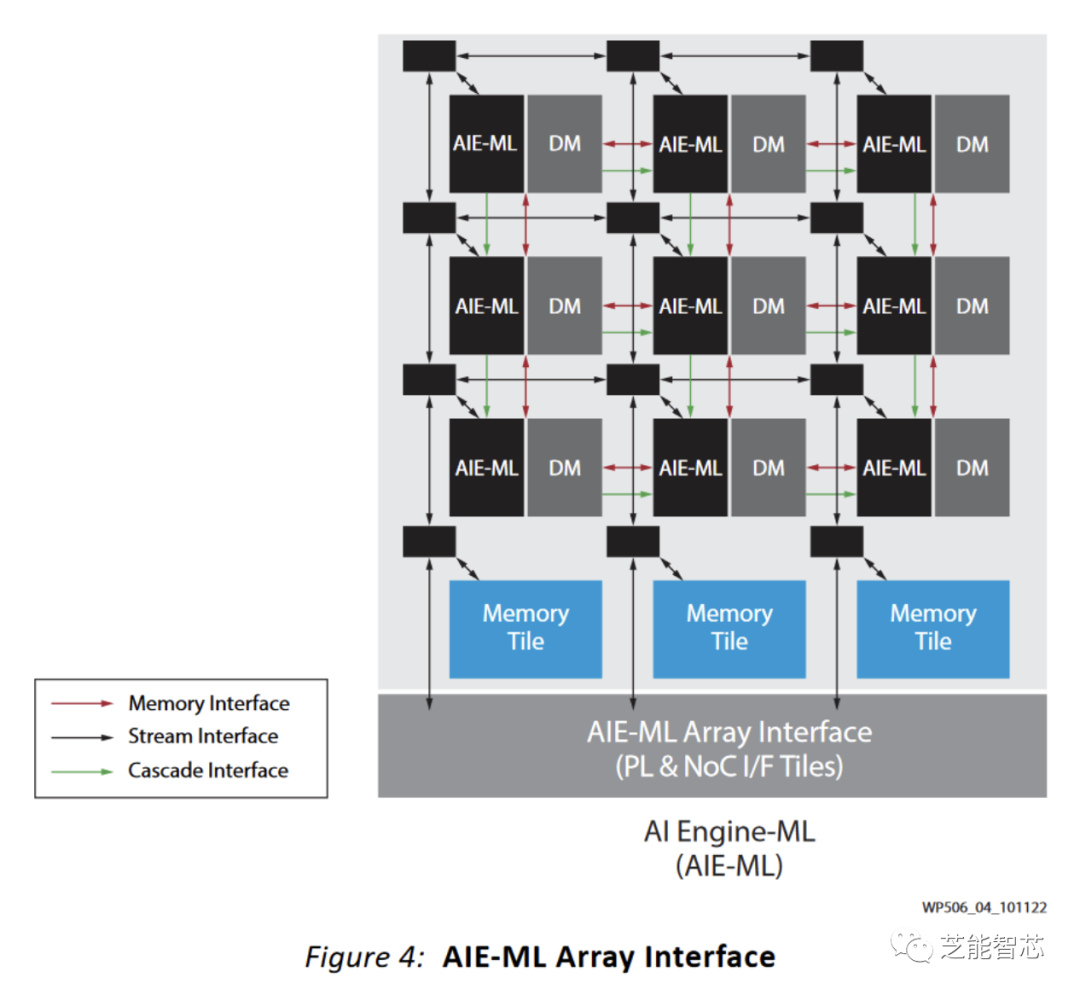
机器学习已经取得了很大的进展,AMD在Phoenix上加入了一个AI引擎(XDNA)来加速推断。XDNA是使用Xilinx开发的架构构建的AIE-ML瓦片构建而成。Phoenix的XDNA实现具有16个AIE-ML瓦片,并且可以在空间上分区,以让多个应用程序共享AI引擎。

XDNA的目标是实现足够的吞吐量,以处理小型ML负载,同时实现非常高的能效。它以非常低的时钟频率运行,并使用非常宽的矢量执行。文档表明,它的时钟频率为1 GHz,但Phoenix的XDNA可能以1.25 GHz运行,因为AMD表示支持BF16,具有5 TFLOPS的吞吐量。为了驱动非常宽的矢量单元,XDNA具有两个矢量寄存器文件。
一个6KB的寄存器文件集提供乘法器输入。单独的8KB寄存器文件保存累加器值,并在乘加流水线的较后阶段访问。两个寄存器文件可以以1024位、512位或256位的模式寻址,连续的256位寄存器形成512位或1024位的寄存器。
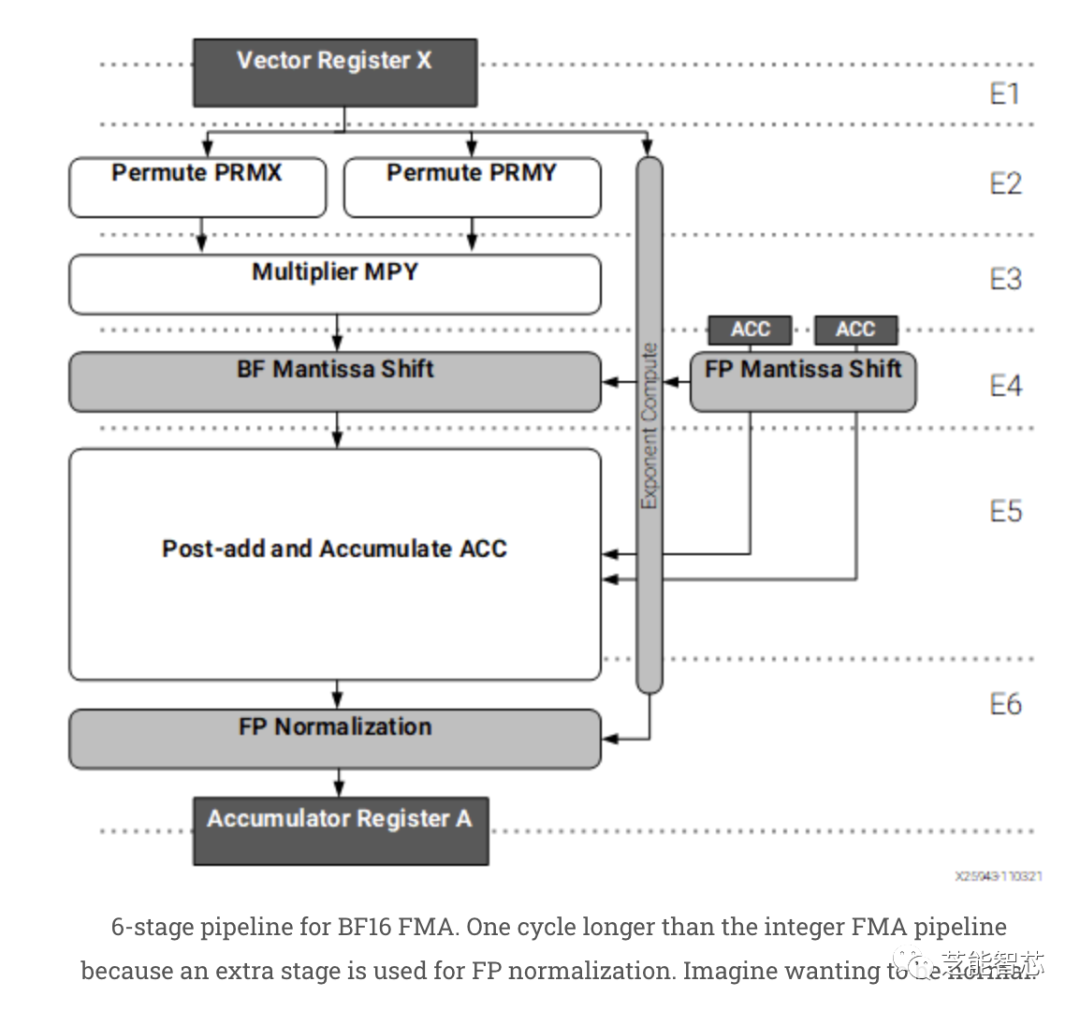
BF16 FMA的6级流水线。比整数FMA流水线多一个周期,因为多了一个阶段用于FP规范化。乘加操作似乎具有5-6个周期的延迟,具体取决于是否需要FP规范化。对于以大约1 GHz运行的东西来说,这有点长,但XDNA会在其中提供排列。较简单的512位加法和洗牌享有更快的3个周期延迟。
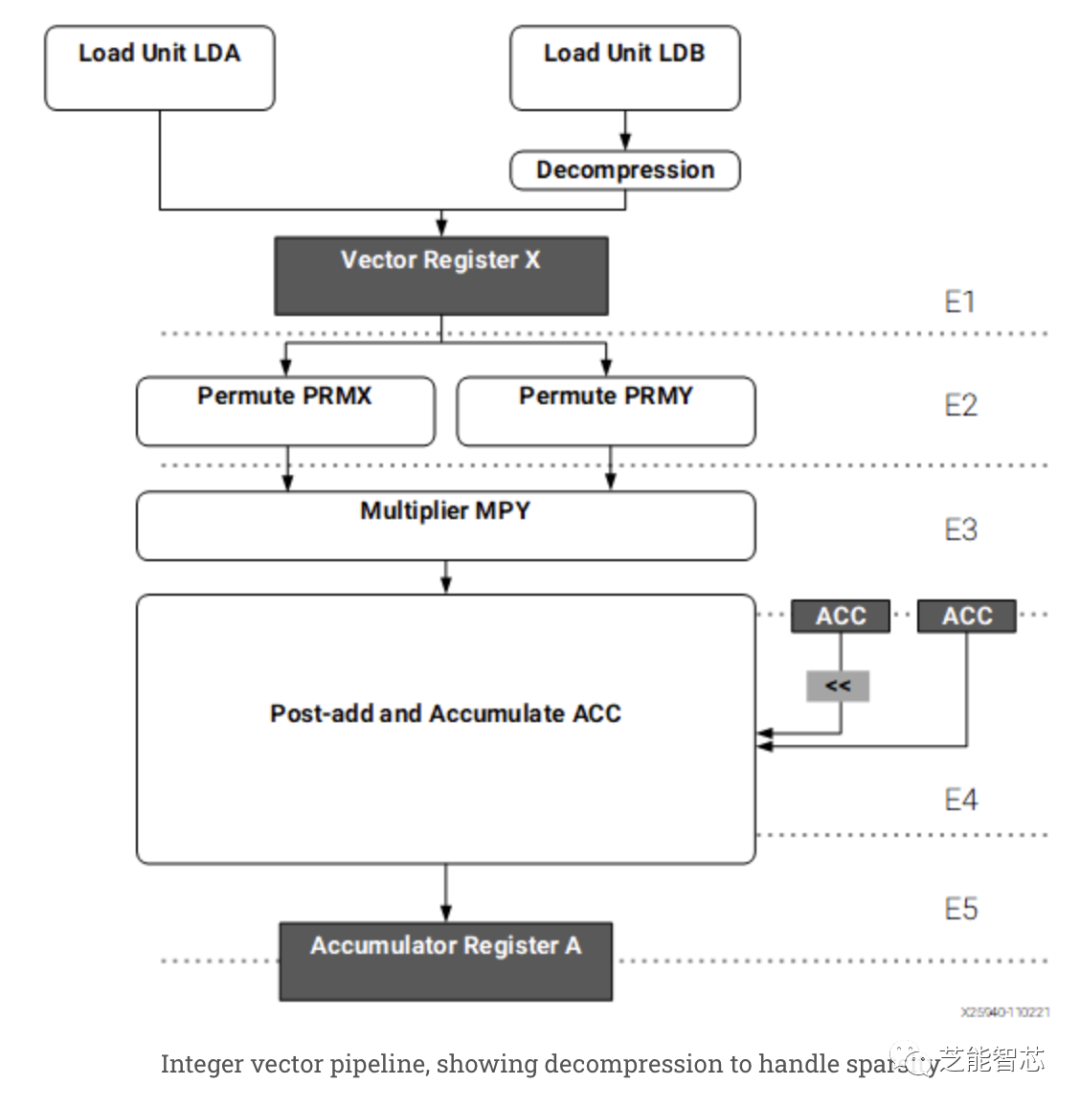
每个XDNA瓦片使用64 KB的直接寻址数据存储器为其庞大的矢量单元提供数据存储器。数据存储器不是高速缓存,因此无需标签检查,可以节省功率。使用20位寻址进一步节省了电源,这对任何人来说都应该足够。地址由三个AGU生成,它们在20位指针和修饰符寄存器上运行。在地址上使用单独的寄存器并不是什么新鲜事(6502具有两个索引寄存器),并且避免了主要标量寄存器文件上的六个额外端口。
整数矢量流水线,显示处理稀疏性的解码器步骤,64KB数据存储器,指针寄存器,大数据运算单元Ryzen 7 7840HS以65W TDP运行,不过Phoenix设计的TDP范围可能从35W到60W不等。默认配置下,Phoenix的XDNA瓦片可以实现4 TFLOPS的吞吐量,功耗仅为13W。如果整个芯片被配置为65W,则XDNA可以实现10 TFLOPS的吞吐量。
通过减小核心计数并提高XDNA时钟,TDP可以进一步减少到35W。这将限制XDNA到2 TFLOPS,但在大多数笔记本中,可能不会发生这种情况。
Phoenix还有多个标量ALU,每个瓦片的流水线中有两个整数算术单元,以及单个浮点乘法器和浮点加法器。流水线提供多达256位的宽度,并且为低延迟而优化。尽管AMD没有详细介绍流水线的结构,但它们似乎包括大量的特化逻辑,以加速整数算术。例如,一个6级流水线的int->int复制将会非常快。XDNA流水线还支持超标量整数操作,可以在多个流水线中同时执行。
除了标量整数,XDNA流水线还可以执行标量逻辑和标量访存。整数指令和逻辑指令可以同时执行,从而实现更高的吞吐量。 Phoenix的XDNA实现似乎没有指令级并行性问题,可以以每个周期4条指令的吞吐量运行。这是因为乘加和逻辑单元是相互独立的。

XDNA可以从LPDDR5内存访问数据,与GPU一样,它可以从完全不同的内存访问。但是,GPU和XDNA之间的内存访问共享是不太可能的,因为它们使用不同的地址空间。必须通过主机来传输数据。但是,由于LPDDR5具有足够的带宽,可以将数据传输到XDNA或GPU,而不必禁用着色器或ALU。 Phoenix的内存子系统可以实现与Van Gogh相同的DRAM带宽,同时仍然具有内存访问(可能会增加DRAM的带宽要求)。
音频
Phoenix的音频控制器在一定程度上类似于AMD的CPU核心,它具有8个SIMD单元,可以通过VLIW进行调度。

可以高效地运行不同的声音效果,并具有低时延。AMD还为Phoenix的音频引擎提供了一个编程接口,使它能够轻松支持不同的音频引擎。这使得它可以与不同的操作系统和音频处理软件一起工作,而不必为不同的音频引擎重新编写代码。
音频引擎还支持高质量的音频解码,包括解码压缩的音频格式,如MP3和AAC,还可以支持音频编码,允许用户创建高质量的音频内容。
总结
AMD的Phoenix SoC是一款非常令人印象深刻的移动芯片,将Zen 4 CPU核心和RDNA 3 GPU整合到一个紧凑的封装中,还具有一系列加速器,包括XDNA AI引擎、视频引擎和音频控制器,为多种应用程序提供了高效的处理能力。Phoenix的CPU性能在移动领域应该是一流的,而GPU性能也足以运行现代游戏和图形密集型应用程序。Phoenix的LPDDR5内存支持和高速缓存配置应该进一步提高系统的整体性能。

