
在之前的文章里,我们讨论了关于 MySQL 的许多问题,包括:
在这些文章中,我们大致了解了一些加锁的情况。但实际上 MySQL 的加锁规则是怎样的,我还不是特别清楚。所以今天我们就来深入了解下 MySQL 的加锁规则。
为了弄清楚这些加锁规则,我查阅了许多资料。但在这些资料中,我觉得比较有质量的只有两个:一个是极客时间《MySQL 45 讲》第 20/21 节讲得内容,另一个是一篇从源码角度解析加锁规则的文章。
《MySQL 45 讲》是丁奇老师出的一个专栏,现在是腾讯云数据库负责人。在该专栏的第 21、22 节中讲到了具体的加锁规则,并且也举了非常多的例子。本文也将摘取其中一些内容,来跟大家讨论学习。
另一篇从源码角度讲加锁规则的,是网名为「小孩子」的网友写得一篇文章,其后续出了一本书叫《从根上了解 MySQL》,内容非常多并且很详细。这篇文章从源码角度从头到尾分析了整个加锁规则,讲得还是比较详细。
在看着两份资料之前,我总是尝试去找到一个简单好记的加锁规律,但看完之后觉得:这或许不太可能。丁奇大神在其专栏也提到他是怎么去分析加锁规则的。
首先说明一下,这些加锁规则我没在别的地方看到过有类似的总结,以前我自己判断的时候都是想着代码里面的实现来脑补的。这次为了总结成不看代码的同学也能理解的规则,是我又重新刷了代码临时总结出来的。
可以看到,就连大神也是想着代码脑补加锁规律的。再结合「小孩子」从源码角度去分析加锁规则,我一下子就觉得:或许还是该深入到源码角度,才能一窥真相。
即使后面丁奇老师为了方便我们理解,也总结出了一些加锁(如下图所示)。但实际上这些加锁规则也没啥规律,只能是记着就好。此外,他也提出:我们需要用动态的眼光去看加锁。言外之意就是,这些规则可能都是变化的,也不一定是完全正确的。

看到这里,我会想:那我们应该怎么学习 MySQL 的加锁规则呢?
我思考了片刻,给出的答案是:我们可以按照丁奇老师总结出的加锁规则先行学习,后续再深入源码层面不断地补足一些细节。
在讲一些具体加锁规则之前,我觉得有必要先给大家一个 MySQL 加锁的全局视角。这个是丁奇老师在文章中没讲到的,但我觉得如果不知道全局视角,那么会影响到对一些规则的理解。
我们知道 MySQL 分成了 Server 层和存储引擎两部分,每当执行一个查询时,Server 层负责生成执行计划,然后交给存储引擎去执行。其整个过程可以这样描述:
通过上面这个过程,我想让大家明白两个重要的认识:
弄懂了上面两个认识,会对后续大家理解有很大帮助。例如:对于 select * from user where id >= 5 进行分析的时候,为什么会出现说第一次加锁是精确查询?它明明是范围查询呀!这是因为第一次是要寻找到 id = 5 的记录,对于 Innodb 来说,它就是精确查找,不是范围查找。随后找到 id = 5 的记录之后,就要找 id > 5 的记录了,此时就变成了范围查找了。
这里的加锁规则,我直接引用丁奇老师的总结:两个原则、两个优化、一个 bug。
对于原则 1 说的:加锁的基本单位是 Next-Key 锁,意思是默认都是先加上 Next-Key,之后根据 2 个优化点选择性退化为行锁或间隙锁。
对于原则 2 说的:访问到的对象才会加锁,意思是如果直接索引覆盖到了,不需要回表,那么就不会对聚簇索引加锁。这样的话,其他事务就可以对聚簇索引进行操作,而不会阻塞。
为了解释这些规则,建立表 t 并插入一些数据。
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
如下图所示的例子,是一个等值条件加间隙锁的例子。

在事务 A 中,要查找 id = 7 的记录,其查找过程为:从左到右查找 id 聚簇索引,依次对比 0、5 两个索引,发现不对。接着,对比 10 这个索引,发现 7 <10,于是停止搜索。根据原则 1 默认给其加上一个 Next-Key 锁,即 (5, 10]。根据优化 2 退化为间隙锁,即 (5,10)。
所以,session B 要插入 id=8 的记录会被锁住,而 session 修改 id=10 这行是可以的。
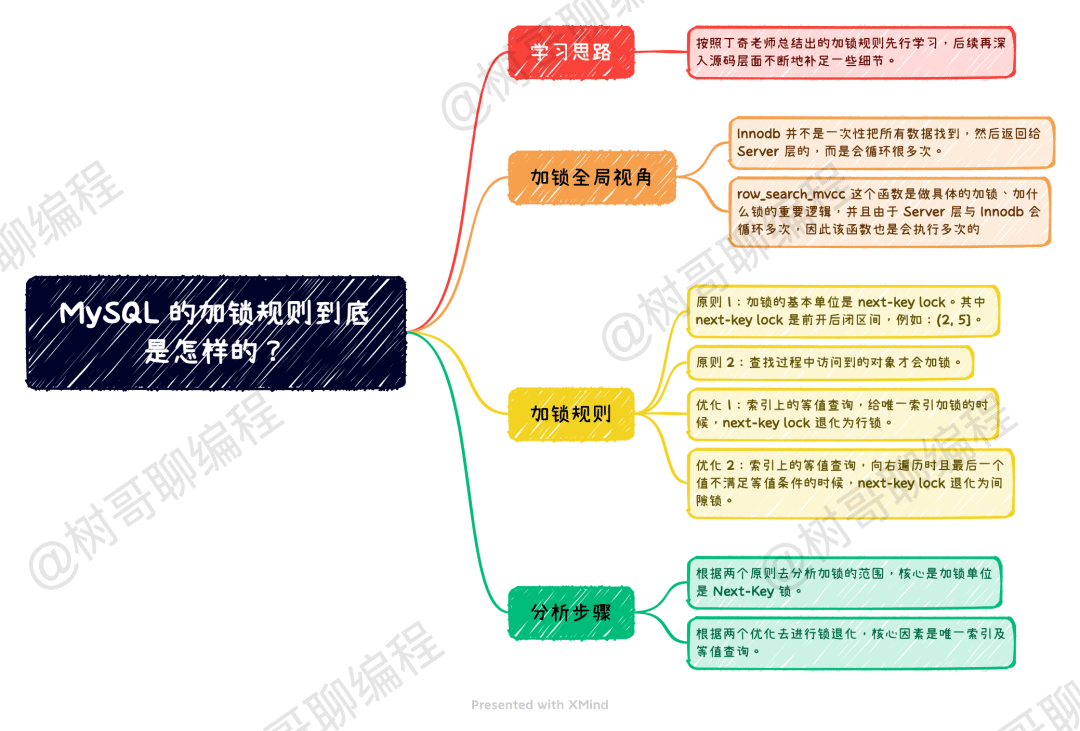
在事务 A 中,要查找 c=5 的记录,其中 c 是非唯一索引。其查找过程为:从左到右查找 c 索引,找到了 c=5 的索引,根据原则 1 对其加 Next-Key 锁,即 (0,5]。
由于普通索引可能重复,因此其还会继续往后搜索,接着搜索到 10,根据原则 2,访问到的都要加锁,因此再给其加 Next-Key 锁,即 (5,10]。由于这个还负责优化 2:等值判断,向右遍历,最后一个不满足等值条件,因此退化为间隙锁 (5,10)。
此外,根据原则 2,只有访问到的对象才会加锁。这个查询使用查询覆盖索引,并不需要访问主键索引,所以主键索引上没有加任何锁。也就是说 (0,5] 和 (5,10) 这两个锁,只在索引 c 上加锁,并不在主键索引上加锁,因此 session B 可以执行。
session C 中插入一个 c 为 7 的值,c 为 7 的值在 (5,10) 之间,因此会被锁住。
对于我们这个表 t,下面这两条查询语句,加锁范围相同吗?
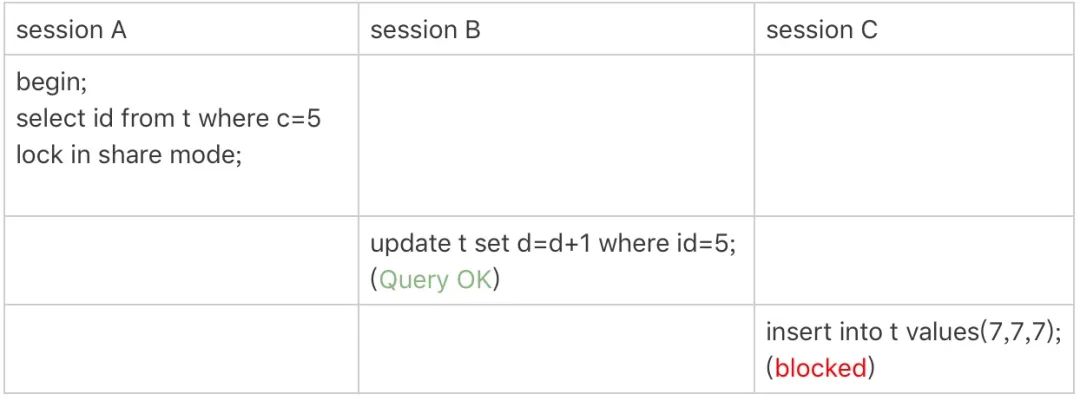
mysql> select * from t where id=10 for update;
mysql> select * from t where id>=10 and id<11 for update;
在逻辑上,这两条查语句肯定是等价的,但是它们的加锁规则不太一样。现在,我们就让 session A 执行第二个查询语句,来看看加锁效果。

我们来分析一下整体的加锁规则吧。
事务 A 开始执行的时候,要找到 id 为 10 的记录,于是从左到右找到了 id 为 10 的索引。根据原则 1 会给其加 Next-Key 锁,即 (5,10]。根据优化 1,id = 10 是等值查询,因此其退化为行锁,即只对 id = 10 这行加了行锁。
接着继续进行范围查找,找到 id=15 这一行,继续加 Next-Key 锁 (10,15]。这时候 id=15 大于 11,因此其不再查找。TODO
下面的 c 字段是非唯一普通索引,使用了范围查询。
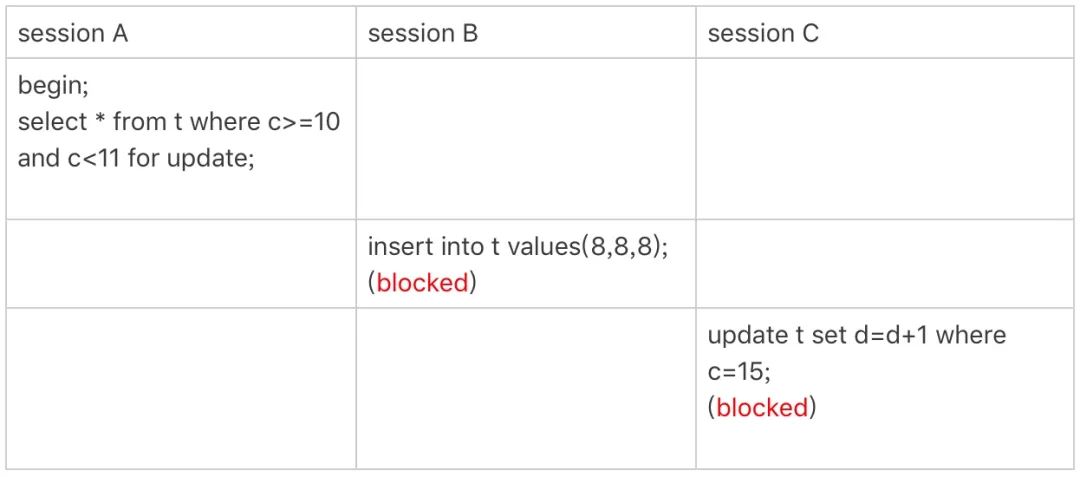
事务 A 开始执行的时候,要找到 id 为 10 的记录,于是根据原则 1 加了 Next-Key 锁,即 (5,10]。由于索引 C 是非唯一索引,没有优化规则,因此不会退化为行锁。因此对于事务 A 来说,索引 C 上加的是 (5,10] 和 (10,15] 两个 Next-Key 锁。
所以当 session B 和 session C 要操作 c 值为 8 和 15 的数据时会被阻塞。
最后我们总结一下 MySQL 的加锁规则:
其中「两个原则、两个优化」是:
通过上面这样的加锁规则,我们就可以有一个大致的分析思路,至少能开始分析加锁规律了。
但要注意的是,实际上的情况非常复杂,例如 limit 参数也会影响加锁的范围,非唯一索引多个值夜会影响锁范围。简单地说,就是有很多特例的情况,我们还需要继续去积累。
20 | 幻读是什么,幻读有什么问题?
21 | 为什么我只改一行的语句,锁这么多?
完整版:Innodb 到底是怎么加锁的
