
----与智者为伍 为创新赋能----
一个优秀的数据分析师不仅要掌握基本的统计、数据库、数据分析方法、思维、数据分析工具和技能,还要掌握一些数据挖掘的思路,帮助我们挖掘出有价值的数据,这也是数据分析专家和一般数据分析师的差距之一。
数据挖掘主要分为三类:分类算法、聚类算法和相关规则,基本涵盖了当前商业市场对算法的所有需求。这三类包含了许多经典算法。市面上很多关于数据挖掘算法的介绍都是深奥难懂的。今天我就用我的理解给大家介绍一下数据挖掘十大经典算法的原理,帮助大家快速理解。
数据挖掘算法分类
1、连接分析:PageRank。
2、相关分析:Apriori。
3、分类算法:C4.5,简单的贝叶斯,SVM,KNN,Adaboost,CART。
4、聚类算法:K-Means,EM。
论文被引用的次数越多,其影响就越大。
网页入口越多,入链质量越高,网页质量越高。
PageRank原理
网页的影响=阻尼影响+所有入链集合页面的加权影响之和。
一个网页的影响:所有进入链的页面的加权影响之和。
一个网页对其他网页的影响是:自身影响/链接数量。
并非所有用户都是通过跳转链接来上网的,还有其他方式,比如直接输入网站访问。
因此需要设置阻尼因子,代表用户根据跳转链接上网的概率。
PageRank比喻说明
1、微博
一个人的微博粉丝数量不一定等于他的实际影响力,还要看粉丝的质量。
如果是僵尸粉没用,但是如果是很多大V或者明星关注的话,影响力很大。
2、店铺经营
顾客较多的店铺质量较好,但要看顾客是否是托。
3、兴趣
对感兴趣的人或事投入相对较多的时间,对其相关的人和事也投入一定的时间。被关注的人或事越多,其影响力/受众就越大。
关于阻尼因子
1、通过邻居的影响来判断你的影响,但是如果你不能通过邻居来访问你,并不意味着你没有影响力,因为可以直接访问你,所以引入了阻尼因子的概念。
2、海洋除了河流流经外,还有雨水,但下雨是随机的。
3、提出阻尼系数,或者解决一些网站显然有大量的链(链),但影响很大。
出链例子:hao123导航网页,出链多,入链少。
入链例子:百度谷歌等搜索引擎,入链很多,出链很少。
关联挖掘关系,从消费者交易记录中发现商品之间的关系。
Apriori原理
1、支持度
商品组合出现的次数与总次数之比。
五次购买,四次购买牛奶,牛奶支持度为4/5=0.8。
五次购买,三次购买牛奶+面包,牛奶+面包支持3/5=0.6。
2、置信度
购买商品A,购买商品B的概率有多大,发生A时发生B的概率有多大。
买了四次牛奶,其中两次买了啤酒,(牛奶->啤酒)的可信度是2/4=0.5。
三次买啤酒,其中两次买牛奶,(啤酒->牛奶)的可信度为2/3-0.67。
3、提升度
衡量商品A的出现,提高商品B出现概率的程度。
提升度(A->B)=置信度(A->B)/支持度(B)。
提升度>1,有提升;提升度=1,无变化;提升度1,下降。
4、项集频繁
项集:可以是单一商品,也可以是商品组合。
频繁的项集是支持度大于最小支持度的项集(MinSupport)。
计算过程
(1)从K=1开始,经常筛选项集。
(2)在结果中,组合K+1项集,重新筛选。
(3)循环1,2步。K-1项集的结果是最终结果,直到找不到结果。
扩展:FP-Growth算法。
Apriori算法需要多次扫描数据库,性能低,不适合大数据量。
FP-growth算法,通过构建FP树的数据结构,将数据存储在FP树中,只需在构建FP树时扫描数据库两次,后续处理就不需要再访问数据库。
比喻:啤酒和纸尿裤一起卖。
沃尔玛通过数据分析发现,在美国有婴儿的家庭中,母亲通常在家照顾孩子,父亲去超市买尿布。
父亲在买纸尿裤的时候,经常会搭配几瓶啤酒来奖励自己。因此,超市试图推出一种将啤酒和纸尿裤放在一起的促销手段,这实际上大大增加了纸尿裤和啤酒的销量。
AdaBoost原理
简单来说,多个弱分类器训练成强分类器。
将一系列弱分类器作为不同权重比组合的最终分类选择。
计算过程
1、基本权重初始化。
2、奖励权重矩阵,通过现有的分类器计算错误率,选择错误率最低的分类器。
3、通过分类器权重公式,减少正确的样本分布,增加错误的样本分布,获得新的权重矩阵和当前k轮的分类器权重。
4、将新的权重矩阵带入上述步骤2和3,重新计算权重矩阵。
5、迭代N轮,记录每轮最终分类器的权重,获得强分类器。
AdaBoost算法比喻说明
1、利用错题提高学习效率
做对的题,下次少做点,反正都会。
下次多做错题,集中在错题上。
随着学习的深入,错题会越来越少。
2、合理跨境提高利润
苹果公司,软硬件结合,占据了手机市场的大部分利润,两个领域的知识结合产生了新的收益。
决策就是对一个问题有多个答案,选择答案的过程就是决策。
C4.5算法用于产生决策树,主要用于分类。
C4.5计算信息增益率(ID3算法计算信息增益)。
C4.5算法原理
C4.5算法选择最有效的方法对样本集进行分裂,分裂规则是分析所有属性的信息增益率。
信息增益率越大,意味着这个特征分类的能力越强,我们应该优先选择这个特征进行分类。
比喻说明:挑西瓜。
拿到一个西瓜,先判断它的线条。如果很模糊,就觉得不是好瓜。如果很清楚,就觉得是好瓜。如果稍微模糊一点,就考虑它的密度。如果密度大于一定值,就认为是好瓜,否则就是坏瓜。
CART:Clasification And Regresion Tree,中文叫分类回归树,可以分类也可以回归。
什么是分类树?回归树?
分类树:处理离散数据,即数据类型有限的数据,输出样本类别。
回归树:可以预测连续值,输出一个值,值可以在一定范围内获得。
回归问题和分类问题的本质是一样的,就是对一个输入做一个输出预测,其区别在于输出变量的类型。
CART算法原理
CART分类树
类似于C4.5算法,但属性选择的指标是基尼系数。
基尼系数反映了样本的不确定性。基尼系数越小,样本之间的差异越小,不确定性越低。
分类是一个降低不确定性的过程。CART在构建分类树时,会选择基尼系数最小的属性作为属性划分。
回归树的CART
以均方误差或绝对值误差为标准,选择均方误差或绝对值误差最小的特征。
分类和回归数的比喻说明
分类:预测明天是阴、晴还是雨。
回归:预测明天的温度。
简单贝叶斯是一种简单有效的常用分类算法,在未知物体出现的情况下,计算各类出现的概率,取概率最大的分类。
算法原理
假设输入的不同特征是独立的,基于概率论原理,通过先验概率P(A)、P(B)和条件概率计算出P(A|B)。
P(A):先验概率,即在B事件发生前判断A事件概率。
P(B|A):条件概率,事件B在另一个事件A已经发生的条件下发生的概率。
P(A|B):后验概率,即B事件发生后重新评估A事件概率。
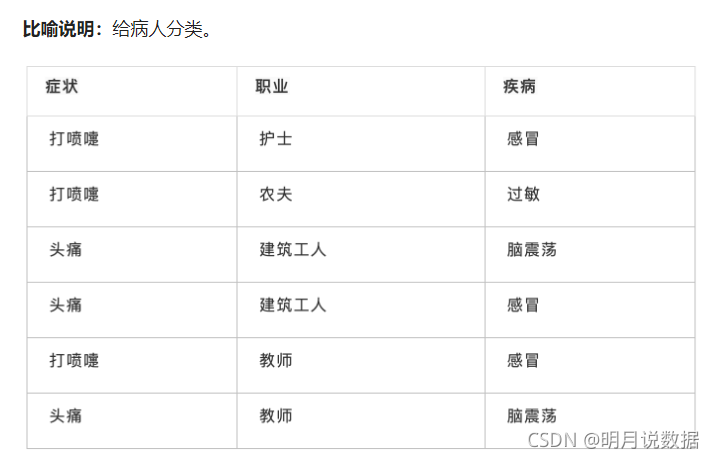
比喻说明:对患者进行分类
给定一个新病人,一个打喷嚏的建筑工人,计算他感冒的概率。
SVM:SupportVectorMachine,中文名为支持向量机,是一种常见的分类方法,最初是为二分类问题设计的,在机器学习中,SVM是一种有监督的学习模式。
什么是监督学习和无监督学习?
监督学习:即在现有类别标签的情况下,对样本数据进行分类。
无监督学习:即在没有类别标签的情况下,样本数据按照一定的方法进行分类,即聚类。分类好的类别需要进一步分析,才能知道每个类别的特点。
SVM算法原理
找到间隔最小的样本点,然后拟合到这些样本点的距离和最大的线段/平面。
硬间隔:数据线性分布,直接给出分类。
软间隔:允许一定量的样本分类错误。
核函数:非线性分布的数据映射为线性分布的数据。
SVM算法比喻说明
1、分隔桌上的一堆红球和篮球。
桌上的红球和蓝球用一根线分成两部分。
2、分隔盒子里的一堆红球和篮球。
盒子里的红球和蓝球用平面分成两部分。
机器学习算法中最基本、最简单的算法之一,可以通过测量不同特征值之间的距离来分类。
KNN算法原理
计算待分类物体与其他物体之间的距离,预测K最近邻居数量最多的类别是该分类物体的类别。
计算步骤。
1.根据场景选择距离计算方法,计算待分类物体与其他物体之间的距离。
2.统计最近的K邻居。
3.对于K最近的邻居,最多的类别被预测为分类对象的类别。
KNN算法比喻:近朱者赤,近墨者黑。
K-means是一种无监督学习、生成指定K类的聚类算法,将每个对象分配到最近的聚类中心。
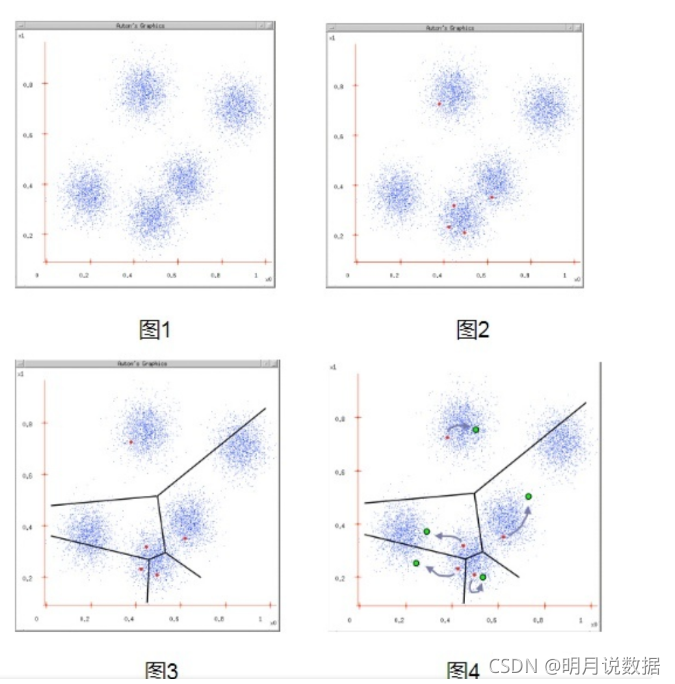
K-Means算法原理
1.随机选择K点作为分类中心点。
2.将每个点分配到最近的类,从而形成K类。
3.重新计算每个类别的中心点。比如同一类别有10个点,那么新的中心点就是这10个点的中心点,一个简单的方法就是取平均值。
K-Means算法比喻说明
1、选组长
每个人都随机选择K个组长,谁离得近,就是那个队列的人(计算距离,近的人聚在一起)。
随着时间的推移,组长的位置在变化(根据算法重新计算中心点),直到选择真正的中心组长(重复,直到准确率最高)。
2、Kmeans和Knn的区别
Kmeans开班选组长,风水轮流转,直到选出最佳中心组长。
Knn小弟加队,离那个班比较近,就是那个班。
EM的英语是ExpectationMaximization,因此EM算法又称最大期望算法,也是一种聚类算法。
EM和K-Means的区别:
EM是计算概率,KMeans是计算距离。
EM属于软聚类,同一样本可能属于多个类别;K-Means属于硬聚类,一个样本只能属于一个类别。因此,前者可以发现一些隐藏的数据。
EM算法原理
先估计一个大概率的可能参数,然后根据数据不断调整,直到找到最终确认参数。
EM算法比喻说明:菜称重
很少有人用称重菜肴,然后计算一半的重量来平分。
大多数人的方法是:
1、先把一部分分成菜A,然后把剩下的分成菜B。
2、观察菜A和B里的菜是否一样多,哪个多就匀一点到少。
3、然后观察碟子里的A和B是否一样多,重复,直到重量没有变化。
其中,数据挖掘之后就需要把收集的有用的数据进行可视化处理方便人们直观感受数据的变化和重要性,通常数据分析师都会选择一些可视化辅助工具帮助自己更好的完成数据分析工作,比如基础的可视化工具有Excel、PPT和Xmind,但是对于企业来说,这些可视化工具提供的功能都太单一了,不能很好的满足可视化效果,很多数据分析师会选择Smartbi这款可视化工具,集齐数据挖掘、数据分析、数据可视化功能于一体的数据可视化工具,有着更方便的拖拉拽操作,能处理亿级的数据量,还有着可视化效果更好的自助仪表盘,能更好的满足现代企业报表需求。
到这里十大算法已经简单介绍完成了。事实上,一般来说,常用算法已经被封装到仓库中,只要new生成相应的模型。数据分析师不仅要学会怎么收集有用的数据,也要对数据进行深度分析做出对企业更有利的决策,选择可视化工具Smartbi能有效的提升数据分析师的生产力。这些是一些结合个人经验和网上资料的心得体会,希望能对你学习数据挖掘有帮助。
来源:新机器视觉
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


